
Saiba como usar um acionador de funções do Cloud Run para agir automaticamente em eventos de monitorização da integridade de VMs protegidas.
Vista geral
A monitorização da integridade recolhe medições de instâncias de VMs protegidas e apresenta-as no Cloud Logging. Se as medições de integridade mudarem entre arrancamentos de uma instância de VM protegida, a validação de integridade falha. Esta falha é capturada como um evento registado e também é comunicada no Cloud Monitoring.
Por vezes, as medições de integridade da VM protegida mudam por um motivo legítimo. Por exemplo, uma atualização do sistema pode provocar alterações esperadas ao kernel do sistema operativo. Por este motivo, a monitorização da integridade permite-lhe pedir a uma instância de VM protegida que aprenda uma nova base de referência da política de integridade no caso de uma falha de validação da integridade esperada.
Neste tutorial, vai criar primeiro um sistema automatizado simples que encerra as instâncias de VMs protegidas que falham a validação de integridade:
- Exporte todos os eventos de monitorização da integridade para um tópico do Pub/Sub.
- Crie um acionador de funções do Cloud Run que usa os eventos nesse tópico para identificar e encerrar instâncias de VM protegidas que falham a validação de integridade.
Em seguida, pode expandir opcionalmente o sistema para que solicite às instâncias de VM protegidas que falham na validação de integridade que aprendam a nova base de referência se corresponder a uma medição boa conhecida ou que sejam encerradas caso contrário:
- Crie uma base de dados do Firestore para manter um conjunto de medições de base de referência de integridade conhecidas.
- Atualize o acionador das funções do Cloud Run para que solicite às instâncias de VMs protegidas que falham na validação de integridade que aprendam a nova base de referência se estiver na base de dados ou, caso contrário, que sejam encerradas.
Se optar por implementar a solução expandida, use-a da seguinte forma:
- Sempre que houver uma atualização que se espera que cause uma falha de validação por um motivo legítimo, execute essa atualização numa única instância de VM protegida no grupo de instâncias.
- Usando o evento de arranque tardio da instância de VM atualizada como origem, adicione as medições de base da nova política à base de dados criando um novo documento na coleção known_good_measurements. Consulte o artigo Criar uma base de dados de medições de base conhecidas e válidas para mais informações.
- Atualize as restantes instâncias de VMs protegidas. O acionador pede às instâncias restantes que aprendam a nova base de referência, porque pode ser validado como conhecido como bom. Consulte o artigo Atualizar o acionador das funções do Cloud Run para saber a base de referência conhecida como boa para mais informações.
Pré-requisitos
- Use um projeto que tenha o Firestore no modo nativo selecionado como o serviço de base de dados. Faz esta seleção quando cria o projeto e não pode alterá-la. Se o seu projeto não usar o Firestore no modo nativo, é apresentada a mensagem "Este projeto usa outro serviço de base de dados" quando abre a consola do Firestore.
- Ter uma instância de VM protegida do Compute Engine nesse projeto para servir como origem das medições da base de referência de integridade. A instância de VM protegida tem de ter sido reiniciada, pelo menos, uma vez.
- Ter a
gcloudferramenta de linha de comandos instalada. Ative as APIs Cloud Logging e Cloud Run Functions seguindo estes passos:
Na Cloud de Confiance consola, aceda à página APIs e serviços.
Verifique se a Cloud Functions API e a Stackdriver Logging API aparecem na lista de APIs e serviços ativados.
Se alguma das APIs não for apresentada, clique em Adicionar APIs e serviços.
Pesquise e ative as APIs, conforme necessário.
Exportar entradas do registo de monitorização da integridade para um tópico Pub/Sub
Use o Logging para exportar todas as entradas do registo de monitorização da integridade geradas por instâncias de VMs protegidas para um tópico do Pub/Sub. Usa este tópico como uma origem de dados para um acionador de funções do Cloud Run para automatizar as respostas a eventos de monitorização da integridade.
Logs Explorer
Na Cloud de Confiance consola, aceda à página Explorador de registos.
No criador de consultas, introduza os seguintes valores.
resource.type="gce_instance" AND logName: "projects/YOUR_PROJECT_ID/logs/compute.googleapis.com/shielded_vm_integrity"
Clique em Executar filtro.
Clique em Mais ações e, de seguida, selecione Criar destino.
Na página Criar destino de encaminhamento de registos:
- Em Detalhes do destino, para Nome do destino, introduza
integrity-monitoringe, em seguida, clique em Seguinte. - Em Destino de sincronização, expanda Serviço de sincronização e, de seguida, selecione Cloud Pub/Sub.
- Expanda Selecionar um tópico do Cloud Pub/Sub e, de seguida, selecione Criar um tópico.
- Na caixa de diálogo Criar um tópico, para ID do tópico, introduza
integrity-monitoringe, de seguida, clique em Criar tópico. - Clique em Seguinte e, de seguida, em Criar destino.
- Em Detalhes do destino, para Nome do destino, introduza
Logs Explorer
Na Cloud de Confiance consola, aceda à página Explorador de registos.
Clique em Opções e, de seguida, selecione Regressar ao Explorador de registos antigo.
Expanda Filtrar por etiqueta ou pesquisa de texto e, de seguida, clique em Converter em filtro avançado.
Introduza o seguinte filtro avançado:
resource.type="gce_instance" AND logName: "projects/YOUR_PROJECT_ID/logs/compute.googleapis.com/shielded_vm_integrity"
logName:.Clique em Enviar filtro.
Clique em Criar exportação.
Em Nome do destino, introduza
integrity-monitoring.Para o Sink Service, selecione Cloud Pub/Sub.
Expanda Destino de sincronização e, de seguida, clique em Criar novo tópico do Cloud Pub/Sub.
Em Nome, introduza
integrity-monitoringe, de seguida, clique em Criar.Clique em Criar destino.
Criar um acionador de funções do Cloud Run para responder a falhas de integridade
Crie um acionador de funções do Cloud Run que leia os dados no tópico do Pub/Sub e que pare qualquer instância de VM protegida que falhe a validação de integridade.
O código seguinte define o acionador de funções do Cloud Run. Copie-o para um ficheiro com o nome
main.py.import base64 import json import googleapiclient.discovery def shutdown_vm(data, context): """A Cloud Function that shuts down a VM on failed integrity check.""" log_entry = json.loads(base64.b64decode(data['data']).decode('utf-8')) payload = log_entry.get('jsonPayload', {}) entry_type = payload.get('@type') if entry_type != 'type.googleapis.com/cloud_integrity.IntegrityEvent': raise TypeError("Unexpected log entry type: %s" % entry_type) report_event = (payload.get('earlyBootReportEvent') or payload.get('lateBootReportEvent')) if report_event is None: # We received a different event type, ignore. return policy_passed = report_event['policyEvaluationPassed'] if not policy_passed: print('Integrity evaluation failed: %s' % report_event) print('Shutting down the VM') instance_id = log_entry['resource']['labels']['instance_id'] project_id = log_entry['resource']['labels']['project_id'] zone = log_entry['resource']['labels']['zone'] # Shut down the instance. compute = googleapiclient.discovery.build( 'compute', 'v1', cache_discovery=False) # Get the instance name from instance id. list_result = compute.instances().list( project=project_id, zone=zone, filter='id eq %s' % instance_id).execute() if len(list_result['items']) != 1: raise KeyError('unexpected number of items: %d' % len(list_result['items'])) instance_name = list_result['items'][0]['name'] result = compute.instances().stop(project=project_id, zone=zone, instance=instance_name).execute() print('Instance %s in project %s has been scheduled for shut down.' % (instance_name, project_id))
Na mesma localização que
main.py, crie um ficheiro denominadorequirements.txte copie as seguintes dependências:google-api-python-client==1.6.6 google-auth==1.4.1 google-auth-httplib2==0.0.3
Abra uma janela de terminal e navegue para o diretório que contém
main.pyerequirements.txt.Execute o comando
gcloud beta functions deploypara implementar o acionador:gcloud beta functions deploy shutdown_vm \ --project PROJECT_ID \ --runtime python37 \ --trigger-resource integrity-monitoring \ --trigger-event google.pubsub.topic.publish
Criar uma base de dados de medições de base conhecidas e válidas
Crie uma base de dados do Firestore para fornecer uma origem de medições de base da política de integridade conhecidas como boas. Tem de adicionar manualmente medições de base para manter esta base de dados atualizada.
Na Cloud de Confiance consola, aceda à página Instâncias de VM.
Clique no ID da instância de VM protegida para abrir a página Detalhes da instância de VM.
Em Registos, clique em Stackdriver Logging.
Localize a entrada de registo do
lateBootReportEventmais recente.Expanda a entrada do registo >
jsonPayload>lateBootReportEvent>policyMeasurements.Tenha em atenção os valores dos elementos contidos em
lateBootReportEvent>policyMeasurements.Na Cloud de Confiance consola, aceda à página Firestore.
Escolha Iniciar recolha.
Para o ID da recolha, escreva known_good_measurements.
Para ID do documento, escreva baseline1.
Para Nome do campo, introduza o valor do campo pcrNum do elemento
0emlateBootReportEvent>policyMeasurements.Para Tipo de campo, selecione mapa.
Adicione três campos de string ao campo do mapa, denominados hashAlgo, pcrNum e value, respetivamente. Faça com que os respetivos valores sejam os valores dos campos do elemento
0emlateBootReportEvent>policyMeasurements.Crie mais campos de mapa, um para cada elemento adicional em
lateBootReportEvent>policyMeasurements. Dê-lhes os mesmos subcampos que o primeiro campo de mapeamento. Os valores desses subcampos devem ser mapeados para os de cada um dos elementos adicionais.Por exemplo, se estiver a usar uma VM do Linux, a recolha deve ter um aspeto semelhante ao seguinte quando terminar:
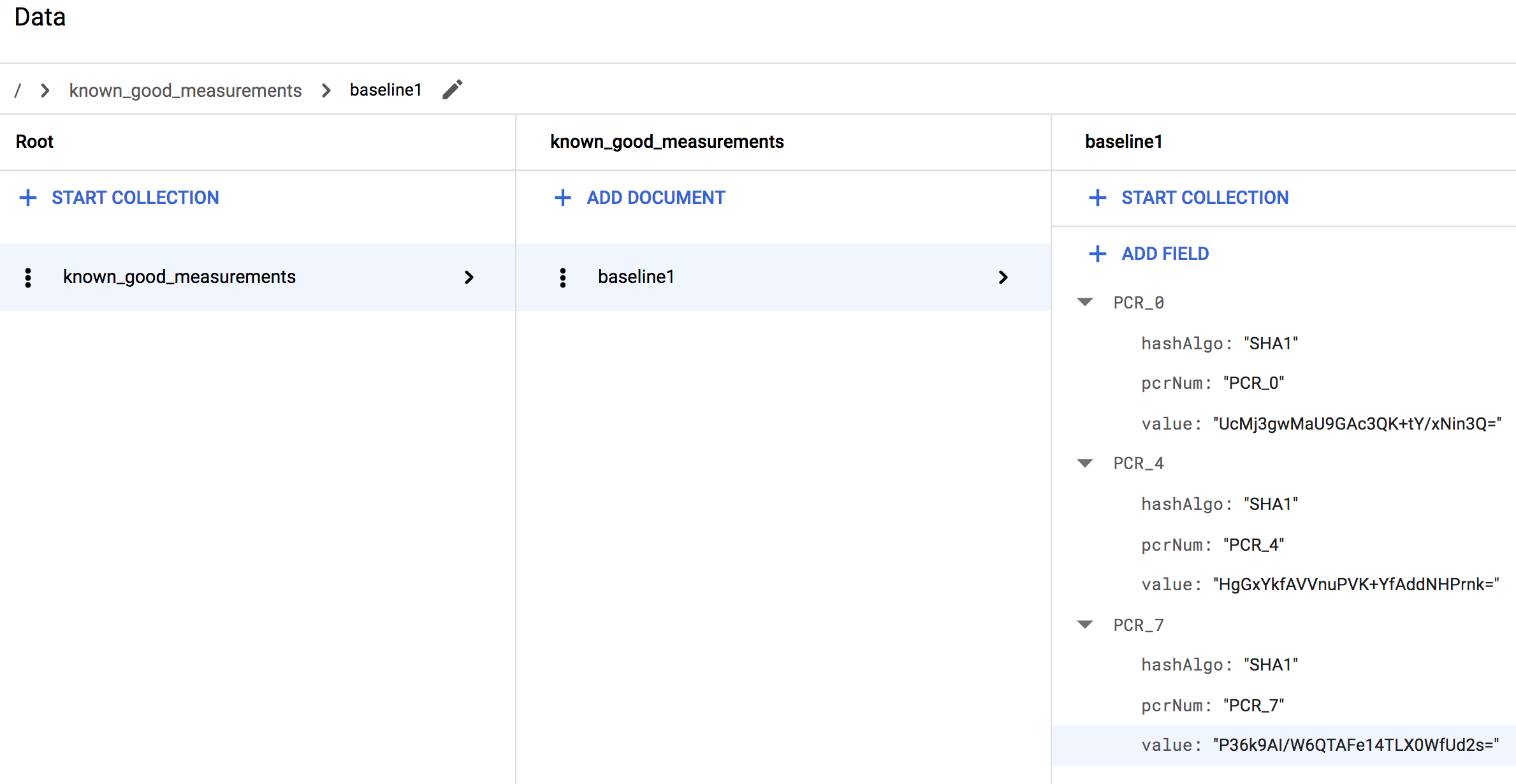
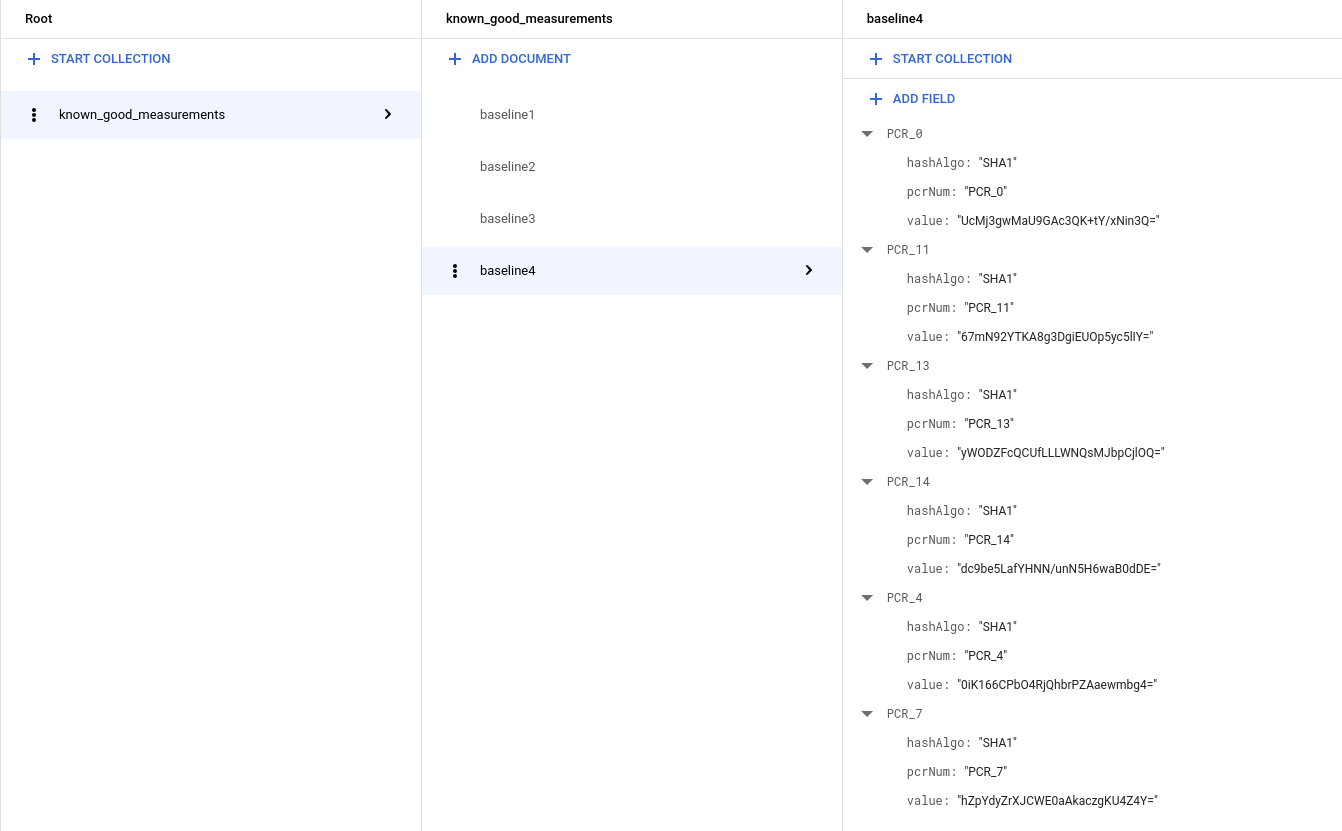
Se estiver a usar uma VM do Windows, vai ver mais medições. Por isso, a recolha deve ter um aspeto semelhante ao seguinte:
Atualizar o acionador de funções do Cloud Run para aprender a base de referência conhecida como boa
O código seguinte cria um acionador de funções do Cloud Run que faz com que qualquer instância de VM protegida que falhe a validação de integridade aprenda a nova base de referência se estiver na base de dados de boas medições conhecidas ou, caso contrário, seja encerrada. Copie este código e use-o para substituir o código existente em
main.py.import base64 import json import googleapiclient.discovery import firebase_admin from firebase_admin import credentials from firebase_admin import firestore PROJECT_ID = 'PROJECT_ID' firebase_admin.initialize_app(credentials.ApplicationDefault(), { 'projectId': PROJECT_ID, }) def pcr_values_to_dict(pcr_values): """Converts a list of PCR values to a dict, keyed by PCR num""" result = {} for value in pcr_values: result[value['pcrNum']] = value return result def instance_id_to_instance_name(compute, zone, project_id, instance_id): list_result = compute.instances().list( project=project_id, zone=zone, filter='id eq %s' % instance_id).execute() if len(list_result['items']) != 1: raise KeyError('unexpected number of items: %d' % len(list_result['items'])) return list_result['items'][0]['name'] def relearn_if_known_good(data, context): """A Cloud Function that shuts down a VM on failed integrity check. """ log_entry = json.loads(base64.b64decode(data['data']).decode('utf-8')) payload = log_entry.get('jsonPayload', {}) entry_type = payload.get('@type') if entry_type != 'type.googleapis.com/cloud_integrity.IntegrityEvent': raise TypeError("Unexpected log entry type: %s" % entry_type) # We only send relearn signal upon receiving late boot report event: if # early boot measurements are in a known good database, but late boot # measurements aren't, and we send relearn signal upon receiving early boot # report event, the VM will also relearn late boot policy baseline, which we # don't want, because they aren't known good. report_event = payload.get('lateBootReportEvent') if report_event is None: return evaluation_passed = report_event['policyEvaluationPassed'] if evaluation_passed: # Policy evaluation passed, nothing to do. return # See if the new measurement is known good, and if it is, relearn. measurements = pcr_values_to_dict(report_event['actualMeasurements']) db = firestore.Client() kg_ref = db.collection('known_good_measurements') # Check current measurements against known good database. relearn = False for kg in kg_ref.get(): kg_map = kg.to_dict() # Check PCR values for lateBootReportEvent measurements against the known good # measurements stored in the Firestore table if ('PCR_0' in kg_map and kg_map['PCR_0'] == measurements['PCR_0'] and 'PCR_4' in kg_map and kg_map['PCR_4'] == measurements['PCR_4'] and 'PCR_7' in kg_map and kg_map['PCR_7'] == measurements['PCR_7']): # Linux VM (3 measurements), only need to check above 3 measurements if len(kg_map) == 3: relearn = True # Windows VM (6 measurements), need to check 3 additional measurements elif len(kg_map) == 6: if ('PCR_11' in kg_map and kg_map['PCR_11'] == measurements['PCR_11'] and 'PCR_13' in kg_map and kg_map['PCR_13'] == measurements['PCR_13'] and 'PCR_14' in kg_map and kg_map['PCR_14'] == measurements['PCR_14']): relearn = True compute = googleapiclient.discovery.build('compute', 'beta', cache_discovery=False) instance_id = log_entry['resource']['labels']['instance_id'] project_id = log_entry['resource']['labels']['project_id'] zone = log_entry['resource']['labels']['zone'] instance_name = instance_id_to_instance_name(compute, zone, project_id, instance_id) if not relearn: # Issue shutdown API call. print('New measurement is not known good. Shutting down a VM.') result = compute.instances().stop(project=project_id, zone=zone, instance=instance_name).execute() print('Instance %s in project %s has been scheduled for shut down.' % (instance_name, project_id)) else: # Issue relearn API call. print('New measurement is known good. Relearning...') result = compute.instances().setShieldedInstanceIntegrityPolicy( project=project_id, zone=zone, instance=instance_name, body={'updateAutoLearnPolicy':True}).execute() print('Instance %s in project %s has been scheduled for relearning.' % (instance_name, project_id))
Copie as seguintes dependências e use-as para substituir o código existente em
requirements.txt:google-api-python-client==1.6.6 google-auth==1.4.1 google-auth-httplib2==0.0.3 google-cloud-firestore==0.29.0 firebase-admin==2.13.0
Abra uma janela de terminal e navegue para o diretório que contém
main.pyerequirements.txt.Execute o comando
gcloud beta functions deploypara implementar o acionador:gcloud beta functions deploy relearn_if_known_good \ --project PROJECT_ID \ --runtime python37 \ --trigger-resource integrity-monitoring \ --trigger-event google.pubsub.topic.publishElimine manualmente a função
shutdown_vmanterior na consola de funções na nuvem.Na Cloud de Confiance consola, aceda à página Cloud Functions.
Selecione a função shutdown_vm e clique em eliminar.
Valide as respostas automáticas a falhas de validação da integridade
- Primeiro, verifique se tem uma instância em execução com o Arranque seguro ativado como uma opção de VM protegida. Caso contrário, pode criar uma nova instância com a imagem de VM protegida (Ubuntu 18.04LTS) e ativar a opção Arranque seguro. Pode ser-lhe cobrado um valor de alguns cêntimos pela instância (este passo pode ser concluído no prazo de uma hora).
- Agora, suponha que, por algum motivo, quer atualizar manualmente o kernel.
Inicie sessão na instância através de SSH e use o seguinte comando para verificar o kernel atual.
uname -srDeve ver algo como
Linux 4.15.0-1028-gcp.Transfira um kernel genérico de https://kernel.ubuntu.com/~kernel-ppa/mainline/
Use o comando para instalar.
sudo dpkg -i *.debReinicie a VM.
Deve reparar que a VM não está a ser iniciada (não é possível executar o SSH na máquina). Isto é o que esperamos, porque a assinatura do novo kernel não está na nossa lista de autorizações de Arranque seguro. Isto também demonstra como o Arranque seguro pode impedir uma modificação não autorizada/maliciosa do kernel.
No entanto, como sabemos que desta vez a atualização do kernel não é maliciosa e é efetivamente feita por nós, podemos desativar o Arranque seguro para arrancar o novo kernel.
Encerre a VM, desmarque a opção Arranque seguro e, em seguida, reinicie a VM.
O arranque da máquina deve falhar novamente! No entanto, desta vez, o sistema está a ser encerrado automaticamente pela função na nuvem que criámos, uma vez que a opção Arranque seguro foi alterada (também devido à nova imagem do kernel) e fez com que a medição fosse diferente da referência. (Podemos verificar isso no registo do Stackdriver da função da nuvem.)
Como sabemos que não se trata de uma modificação maliciosa e conhecemos a causa principal, podemos adicionar a medição atual em
lateBootReportEventà tabela do Firebase de medições válidas conhecidas. (Lembre-se de que há duas coisas a serem alteradas: 1. Arranque seguro opção 2. Imagem do kernel.)Siga o passo anterior Criar uma base de dados de medições de base conhecidas e boas para anexar uma nova base de referência à base de dados do Firestore usando a medição real no
lateBootReportEventmais recente.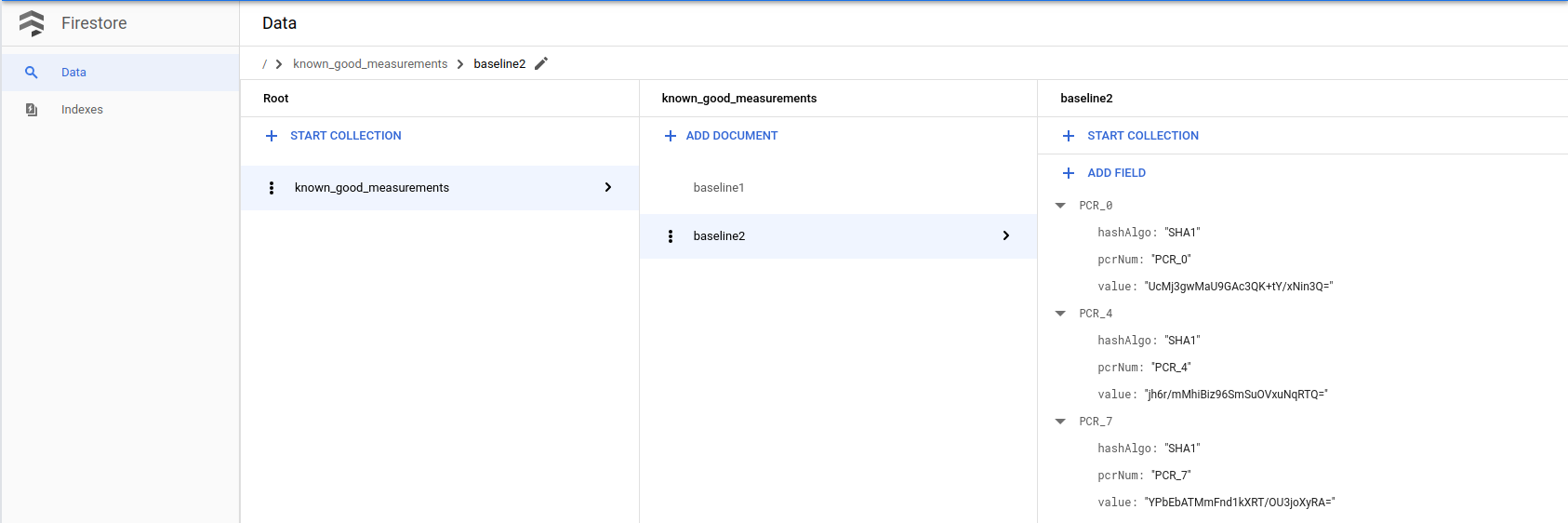
Agora, reinicie o computador. Quando verifica o registo do Stackdriver, vê que o
lateBootReportEventcontinua a apresentar o valor falso, mas a máquina já deve arrancar com êxito, porque a função na nuvem confiou e voltou a aprender a nova medição. Podemos verificá-lo consultando o Stackdriver da função de nuvem.Com o arranque seguro desativado, já podemos arrancar para o kernel. Aceda à máquina através de SSH e verifique novamente o kernel. Vai ver a nova versão do kernel.
uname -srPor último, vamos limpar os recursos e os dados usados neste passo.
Encerre a VM se tiver criado uma para este passo para evitar custos adicionais.
Na Cloud de Confiance consola, aceda à página Instâncias de VM.
Remova as medições válidas conhecidas que adicionou neste passo.
Na Cloud de Confiance consola, aceda à página Firestore.