
Cette page explique comment personnaliser le déploiement de GKE Inference Gateway.
Cette page s'adresse aux spécialistes de la mise en réseau chargés de gérer l'infrastructure GKE, ainsi qu'aux administrateurs de plate-forme qui gèrent les charges de travail d'IA.
Pour gérer et optimiser les charges de travail d'inférence, vous devez configurer les fonctionnalités avancées de la passerelle d'inférence GKE.
comprendre et configurer les fonctionnalités avancées suivantes ;
- Pour utiliser l'intégration Model Armor, configurez les vérifications de sécurité de l'IA.
- Pour améliorer GKE Inference Gateway avec des fonctionnalités telles que la sécurité des API, la limitation du débit et les analyses, configurez Apigee pour l'authentification et la gestion des API.
- Pour acheminer les requêtes en fonction du nom du modèle dans le corps de la requête, configurez le routage basé sur le corps.
- Pour afficher les métriques et les tableaux de bord pour GKE Inference Gateway et les serveurs de modèles, et pour activer la journalisation des accès HTTP, configurez l'observabilité.
- Pour mettre à l'échelle automatiquement vos déploiements GKE Inference Gateway, configurez l'autoscaling.
Configurer les vérifications de sécurité et de sûreté de l'IA
La passerelle d'inférence GKE s'intègre à Model Armor pour effectuer des vérifications de sécurité sur les requêtes et les réponses des applications qui utilisent des grands modèles de langage (LLM). Cette intégration fournit un niveau supplémentaire d'application des règles de sécurité au niveau de l'infrastructure, qui complète les mesures de sécurité au niveau de l'application. Cela permet d'appliquer des règles de manière centralisée à l'ensemble du trafic LLM.
Le schéma suivant illustre l'intégration de Model Armor à GKE Inference Gateway sur un cluster GKE :
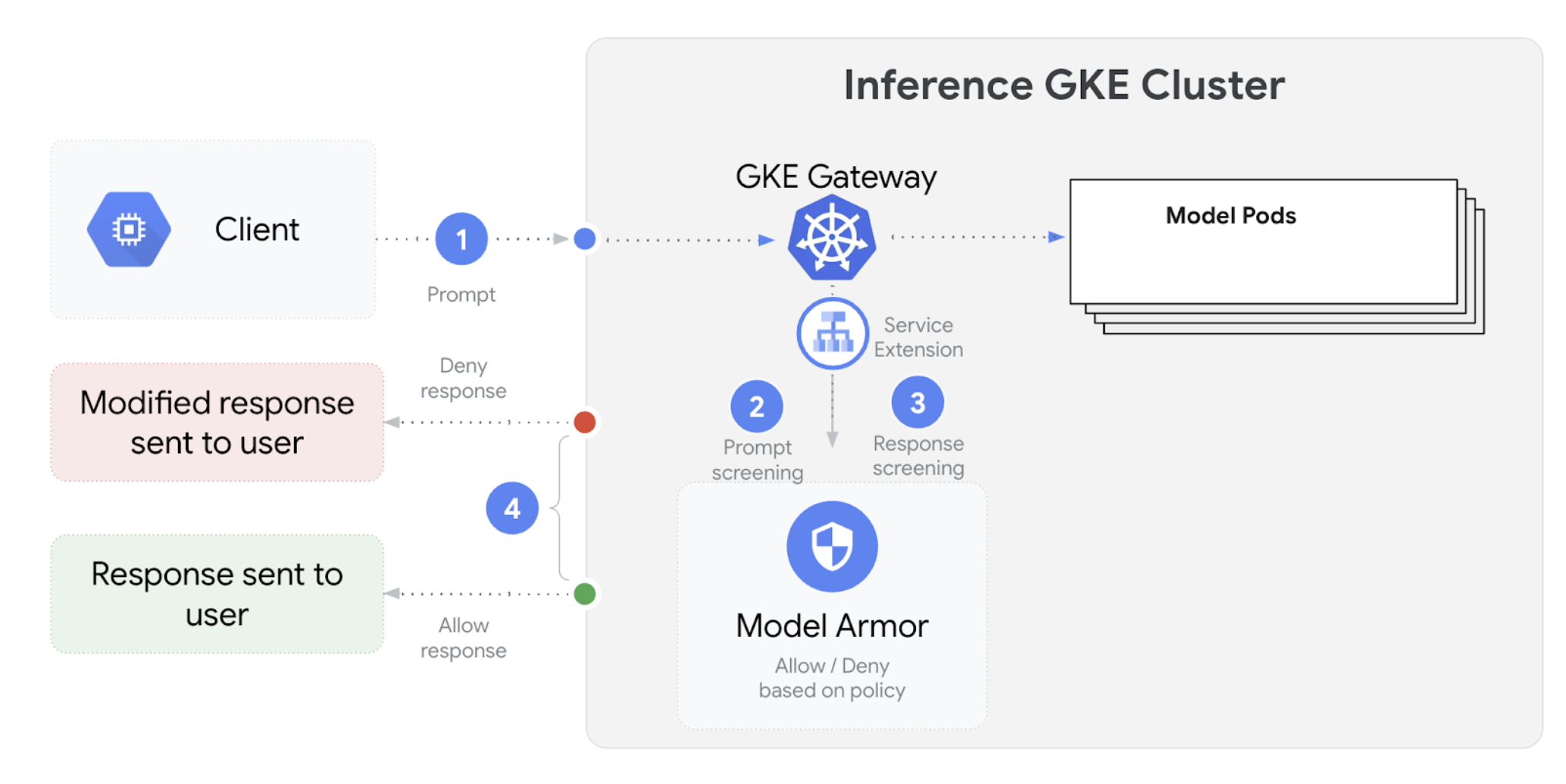
Pour configurer les vérifications de sécurité de l'IA, procédez comme suit :
Prérequis
- Activez le service Model Armor dans votre projet Cloud de Confiance by S3NS .
Créez les modèles Model Armor à l'aide de la console Model Armor, de la Google Cloud CLI ou de l'API. La commande suivante crée un modèle nommé
llmqui enregistre les opérations et filtre le contenu dangereux.# Set environment variables PROJECT_ID=$(gcloud config get-value project) # Replace <var>CLUSTER_LOCATION<var> with the location of your GKE cluster. For example, `us-central1`. LOCATION="CLUSTER_LOCATION" MODEL_ARMOR_TEMPLATE_NAME=llm # Set the regional API endpoint gcloud config set api_endpoint_overrides/modelarmor \ "https://modelarmor.$LOCATION.rep.googleapis.com/" # Create the template gcloud model-armor templates create $MODEL_ARMOR_TEMPLATE_NAME \ --location $LOCATION \ --pi-and-jailbreak-filter-settings-enforcement=enabled \ --pi-and-jailbreak-filter-settings-confidence-level=MEDIUM_AND_ABOVE \ --rai-settings-filters='[{ "filterType": "HATE_SPEECH", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "DANGEROUS", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "HARASSMENT", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "SEXUALLY_EXPLICIT", "confidenceLevel": "MEDIUM_AND_ABOVE" }]' \ --template-metadata-log-sanitize-operations \ --template-metadata-log-operations
Accorder des autorisations IAM
Le compte de service des extensions de service nécessite des autorisations pour accéder aux ressources nécessaires. Attribuez les rôles requis en exécutant les commandes suivantes :
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format 'get(projectNumber)') gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.s3ns-system.iam.gserviceaccount.com \ --role=roles/container.admin gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.s3ns-system.iam.gserviceaccount.com \ --role=roles/modelarmor.calloutUser gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.s3ns-system.iam.gserviceaccount.com \ --role=roles/serviceusage.serviceUsageConsumer gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.s3ns-system.iam.gserviceaccount.com \ --role=roles/modelarmor.userConfigurer le
GCPTrafficExtensionPour appliquer les règles Model Armor à votre passerelle, créez une ressource
GCPTrafficExtensionavec le format de métadonnées approprié.Enregistrez l'exemple de fichier manifeste suivant sous le nom
gcp-traffic-extension.yaml:kind: GCPTrafficExtension apiVersion: networking.gke.io/v1 metadata: name: my-model-armor-extension spec: targetRefs: - group: "gateway.networking.k8s.io" kind: Gateway name: GATEWAY_NAME extensionChains: - name: my-model-armor-chain1 matchCondition: celExpressions: - celMatcher: request.path.startsWith("/") extensions: - name: my-model-armor-service supportedEvents: - RequestHeaders - RequestBody - RequestTrailers - ResponseHeaders - ResponseBody - ResponseTrailers timeout: 1s failOpen: false googleAPIServiceName: "modelarmor.${LOCATION}.rep.googleapis.com" metadata: model_armor_settings: '[{"model": "${MODEL}","model_response_template_id": "projects/${PROJECT_ID}/locations/${LOCATION}/templates/${MODEL_ARMOR_TEMPLATE_NAME}","user_prompt_template_id": "projects/${PROJECT_ID}/locations/${LOCATION}/templates/${MODEL_ARMOR_TEMPLATE_NAME}"}]'Remplacez les éléments suivants :
GATEWAY_NAME: nom de la passerelle.MODEL_ARMOR_TEMPLATE_NAME: nom de votre modèle Model Armor.
Le fichier
gcp-traffic-extension.yamlinclut les paramètres suivants :targetRefs: spécifie la passerelle à laquelle s'applique cette extension.extensionChains: définit une chaîne d'extensions à appliquer au trafic.matchCondition: définit les conditions dans lesquelles les extensions sont appliquées.extensions: définit les extensions à appliquer.supportedEvents: spécifie les événements au cours desquels l'extension est appelée.timeout: spécifie le délai avant expiration de l'extension.googleAPIServiceName: spécifie le nom du service pour l'extension.metadata: spécifie les métadonnées de l'extension, y compris les paramètres deextensionPolicyet de désinfection des requêtes ou des réponses.
Appliquez l'exemple de fichier manifeste à votre cluster :
export GATEWAY_NAME="your-gateway-name" export MODEL="google/gemma-3-1b-it" # Or your specific model envsubst < gcp-traffic-extension.yaml | kubectl apply -f -
Une fois que vous avez configuré les vérifications de sécurité de l'IA et que vous les avez intégrées à votre passerelle, Model Armor filtre automatiquement les requêtes et les réponses en fonction des règles définies.
Configurer Apigee pour l'authentification et la gestion des API
GKE Inference Gateway s'intègre à Apigee pour fournir l'authentification, l'autorisation et la gestion des API pour vos charges de travail d'inférence. Pour en savoir plus sur les avantages d'Apigee, consultez Principaux avantages d'Apigee.
Vous pouvez intégrer GKE Inference Gateway à Apigee pour améliorer votre passerelle avec des fonctionnalités telles que la sécurité des API, la limitation du débit, les quotas, les analyses et la monétisation.
Prérequis
Avant de commencer, assurez-vous de disposer des éléments suivants :
- Un cluster GKE exécutant la version 1.34.* ou ultérieure.
- Un cluster GKE avec GKE Inference Gateway déployé.
- Une instance Apigee créée dans la même région que votre cluster GKE.
- L'opérateur Apigee APIM et ses CRD installés dans votre cluster GKE. Pour obtenir des instructions, consultez Installer l'opérateur Apigee APIM.
kubectlconfiguré pour se connecter à votre cluster GKE.Google Cloud CLIinstallé et authentifié.
Créer un ApigeeBackendService
Commencez par créer une ressource ApigeeBackendService. GKE Inference Gateway l'utilise pour créer un processeur d'extension Apigee.
Enregistrez le manifeste suivant sous le nom
my-apigee-backend-service.yaml:apiVersion: apim.googleapis.com/v1 kind: ApigeeBackendService metadata: name: my-apigee-backend-service spec: apigeeEnv: "APIGEE_ENVIRONMENT_NAME" # optional field defaultSecurityEnabled: true # optional field locations: name: "LOCATION" network: "CLUSTER_NETWORK" subnetwork: "CLUSTER_SUBNETWORK"Remplacez les éléments suivants :
APIGEE_ENVIRONMENT_NAME: nom de votre environnement Apigee. Remarque : Vous n'avez pas besoin de définir ce champ siapigee-apim-operatorest installé avec l'indicateurgenerateEnv=TRUE. Sinon, créez un environnement Apigee en suivant les instructions de la section Créer un environnement.LOCATION: emplacement de votre instance Apigee.CLUSTER_NETWORK: réseau de votre cluster GKE.CLUSTER_SUBNETWORK: sous-réseau de votre cluster GKE.
Appliquez le fichier manifeste à votre cluster :
kubectl apply -f my-apigee-backend-service.yamlVérifiez que l'état est devenu
CREATED:kubectl wait --for=jsonpath='{.status.currentState}'="CREATED" -f my-apigee-backend-service.yaml --timeout=5m
Configurer GKE Inference Gateway
Configurez la passerelle GKE Inference pour activer le processeur d'extension Apigee en tant qu'extension de trafic d'équilibreur de charge.
Enregistrez le manifeste suivant sous le nom
my-apigee-traffic-extension.yaml:kind: GCPTrafficExtension apiVersion: networking.gke.io/v1 metadata: name: my-apigee-traffic-extension spec: targetRefs: - group: "gateway.networking.k8s.io" kind: Gateway name: GATEWAY_NAME extensionChains: - name: my-traffic-extension-chain matchCondition: celExpressions: - celMatcher: request.path.startsWith("/") extensions: - name: my-apigee-extension metadata: # The value for `apigee-extension-processor` must match the name of the `ApigeeBackendService` resource that was applied earlier. apigee-extension-processor: my-apigee-backend-service failOpen: false timeout: 1s supportedEvents: - RequestHeaders - ResponseHeaders - ResponseBody backendRef: group: apim.googleapis.com kind: ApigeeBackendService name: my-apigee-backend-service port: 443Remplacez
GATEWAY_NAMEpar le nom de votre passerelle.Appliquez le fichier manifeste à votre cluster :
kubectl apply -f my-apigee-traffic-extension.yamlAttendez que l'état
GCPTrafficExtensiondevienneProgrammed:kubectl wait --for=jsonpath='{.status.ancestors[0].conditions[?(@.type=="Programmed")].status}'=True -f my-apigee-traffic-extension.yaml --timeout=5m
Envoyer des requêtes authentifiées à l'aide de clés API
Pour trouver l'adresse IP de votre passerelle GKE Inference, inspectez l'état de la passerelle :
GW_IP=$(kubectl get gateway/GATEWAY_NAME -o jsonpath='{.status.addresses[0].value}')Remplacez
GATEWAY_NAMEpar le nom de votre passerelle.Tester une requête sans authentification Cette demande doit être refusée :
curl -i ${GW_IP}/v1/completions -H 'Content-Type: application/json' -d '{ "model": "food-review", "prompt": "Write as if you were a critic: San Francisco", "max_tokens": 100, "temperature": 0 }'Une réponse semblable à celle-ci s'affiche, indiquant que l'extension Apigee fonctionne :
{"fault":{"faultstring":"Raising fault. Fault name : RF-insufficient-request-raise-fault","detail":{"errorcode":"steps.raisefault.RaiseFault"}}}Accédez à l'interface utilisateur Apigee et créez une clé API. Pour obtenir des instructions, consultez Créer une clé API.
Envoyez la clé API dans l'en-tête de requête HTTP :
curl -i ${GW_IP}/v1/completions -H 'Content-Type: application/json' -H 'x-api-key: API_KEY' -d '{ "model": "food-review", "prompt": "Write as if you were a critic: San Francisco", "max_tokens": 100, "temperature": 0 }'Remplacez
API_KEYpar votre clé API.
Pour en savoir plus sur la configuration des règles Apigee, consultez Utiliser des règles de gestion des API avec l'opérateur Apigee APIM pour Kubernetes.
Configurer l'observabilité
GKE Inference Gateway fournit des insights sur l'état, les performances et le comportement de vos charges de travail d'inférence. Cela vous aide à identifier et à résoudre les problèmes, à optimiser l'utilisation des ressources et à assurer la fiabilité de vos applications.
Cloud de Confiance by S3NS fournit les tableaux de bord Cloud Monitoring suivants, qui offrent une observabilité de l'inférence pour GKE Inference Gateway :
- Tableau de bord de la passerelle d'inférence GKE : fournit des métriques clés pour le traitement des LLM, telles que le débit de requêtes et de jetons, la latence, les erreurs et l'utilisation du cache pour
InferencePool. Pour obtenir la liste complète des métriques GKE Inference Gateway disponibles, consultez Métriques exposées. - Tableaux de bord d'observabilité de l'IA/du ML : fournissent des tableaux de bord pour l'utilisation de l'infrastructure, les métriques DCGM et les métriques de performances du modèle vLLM.
- Tableau de bord du serveur de modèles : fournit un tableau de bord pour les signaux clés du serveur de modèles. Cela vous permet de surveiller la charge et les performances des serveurs de modèles, comme
KVCache UtilizationetQueue length. - Tableau de bord de l'équilibreur de charge : il fournit des métriques de l'équilibreur de charge, telles que les requêtes par seconde, la latence de traitement des requêtes de bout en bout et les codes d'état des requêtes et des réponses. Ces métriques vous aident à comprendre les performances de la diffusion des requêtes de bout en bout et à identifier les erreurs.
- Métriques du gestionnaire GPU de centre de données (DCGM) : fournit des métriques DCGM, telles que les performances et l'utilisation des GPU NVIDIA. Vous pouvez configurer les métriques DCGM dans Cloud Monitoring. Pour en savoir plus, consultez Collecter et afficher les métriques DCGM.
Afficher le tableau de bord GKE Inference Gateway
Pour afficher le tableau de bord GKE Inference Gateway, procédez comme suit :
Dans la console Cloud de Confiance , accédez à la page Monitoring.
Dans le volet de navigation, sélectionnez Tableaux de bord.
Dans la section Intégrations, sélectionnez GMP.
Sur la page Modèles de tableaux de bord Cloud Monitoring, recherchez "Gateway".
Affichez le tableau de bord GKE Inference Gateway.
Vous pouvez également suivre les instructions de la section Tableau de bord de surveillance.
Afficher les tableaux de bord d'observabilité des modèles d'IA/de ML
Pour afficher vos modèles déployés et les tableaux de bord des métriques d'observabilité d'un modèle, procédez comme suit :
Dans la console Cloud de Confiance , accédez à la page Modèles déployés.
Pour afficher des informations sur un déploiement spécifique, y compris ses métriques, ses journaux et ses tableaux de bord, cliquez sur le nom du modèle dans la liste.
Sur la page d'informations sur le modèle, cliquez sur l'onglet Observabilité pour afficher les tableaux de bord suivants. Si vous y êtes invité, cliquez sur Activer pour activer le tableau de bord.
- Le tableau de bord Utilisation de l'infrastructure affiche les métriques d'utilisation.
- Le tableau de bord DCGM affiche les métriques DCGM.
- Si vous utilisez vLLM, le tableau de bord Performances du modèle est disponible et affiche les métriques de performances du modèle vLLM.
Configurer le tableau de bord d'observabilité du serveur de modèles
Pour collecter des signaux d'or à partir de chaque serveur de modèle et comprendre ce qui contribue aux performances de la passerelle d'inférence GKE, vous pouvez configurer la surveillance automatique de vos serveurs de modèle. Cela inclut les serveurs de modèles suivants :
Pour afficher les tableaux de bord d'intégration, assurez-vous d'abord de collecter les métriques de votre serveur de modèle. Ensuite, exécutez les étapes suivantes :
Dans la console Cloud de Confiance , accédez à la page Monitoring.
Dans le volet de navigation, sélectionnez Tableaux de bord.
Sous Integrations (Intégrations), sélectionnez GMP. Les tableaux de bord d'intégration correspondants s'affichent.
Figure : Tableaux de bord d'intégration
Pour en savoir plus, consultez Personnaliser la surveillance des applications.
Configurer les alertes Cloud Monitoring
Pour configurer des alertes Cloud Monitoring pour GKE Inference Gateway, procédez comme suit :
Enregistrez l'exemple de fichier manifeste suivant sous le nom
alerts.yamlet modifiez les seuils si nécessaire :groups: - name: gateway-api-inference-extension rules: - alert: HighInferenceRequestLatencyP99 annotations: title: 'High latency (P99) for model {{ $labels.model_name }}' description: 'The 99th percentile request duration for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 10.0 seconds for 5 minutes.' expr: histogram_quantile(0.99, rate(inference_model_request_duration_seconds_bucket[5m])) > 10.0 for: 5m labels: severity: 'warning' - alert: HighInferenceErrorRate annotations: title: 'High error rate for model {{ $labels.model_name }}' description: 'The error rate for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 5% for 5 minutes.' expr: sum by (model_name) (rate(inference_model_request_error_total[5m])) / sum by (model_name) (rate(inference_model_request_total[5m])) > 0.05 for: 5m labels: severity: 'critical' impact: 'availability' - alert: HighInferencePoolAvgQueueSize annotations: title: 'High average queue size for inference pool {{ $labels.name }}' description: 'The average number of requests pending in the queue for inference pool {{ $labels.name }} has been consistently above 50 for 5 minutes.' expr: inference_pool_average_queue_size > 50 for: 5m labels: severity: 'critical' impact: 'performance' - alert: HighInferencePoolAvgKVCacheUtilization annotations: title: 'High KV cache utilization for inference pool {{ $labels.name }}' description: 'The average KV cache utilization for inference pool {{ $labels.name }} has been consistently above 90% for 5 minutes, indicating potential resource exhaustion.' expr: inference_pool_average_kv_cache_utilization > 0.9 for: 5m labels: severity: 'critical' impact: 'resource_exhaustion'Pour créer des règles d'alerte, exécutez la commande suivante :
gcloud alpha monitoring policies migrate --policies-from-prometheus-alert-rules-yaml=alerts.yamlDe nouvelles règles d'alerte s'affichent sur la page Alertes.
Modifier les alertes
Vous trouverez la liste complète des dernières métriques disponibles dans le dépôt GitHub kubernetes-sigs/gateway-api-inference-extension. Vous pouvez également ajouter de nouvelles alertes au fichier manifeste à l'aide d'autres métriques.
Pour modifier les exemples d'alertes, prenons l'exemple suivant :
- alert: HighInferenceRequestLatencyP99
annotations:
title: 'High latency (P99) for model {{ $labels.model_name }}'
description: 'The 99th percentile request duration for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 10.0 seconds for 5 minutes.'
expr: histogram_quantile(0.99, rate(inference_model_request_duration_seconds_bucket[5m])) > 10.0
for: 5m
labels:
severity: 'warning'
Cette alerte se déclenche si le 99e centile de la durée des requêtes sur cinq minutes dépasse 10 secondes. Vous pouvez modifier la section expr de l'alerte pour ajuster le seuil en fonction de vos besoins.
Configurer la journalisation pour GKE Inference Gateway
La configuration de la journalisation pour GKE Inference Gateway fournit des informations détaillées sur les requêtes et les réponses, ce qui est utile pour le dépannage, l'audit et l'analyse des performances. Les journaux d'accès HTTP enregistrent chaque requête et réponse, y compris les en-têtes, les codes d'état et les codes temporels. Ce niveau de détail peut vous aider à identifier les problèmes et les erreurs, et à comprendre le comportement de vos charges de travail d'inférence.
Pour configurer la journalisation pour GKE Inference Gateway, activez la journalisation des accès HTTP pour chacun de vos objets InferencePool.
Enregistrez l'exemple de fichier manifeste suivant sous le nom
logging-backend-policy.yaml:apiVersion: networking.gke.io/v1 kind: GCPBackendPolicy metadata: name: logging-backend-policy namespace: NAMESPACE_NAME spec: default: logging: enabled: true sampleRate: 500000 targetRef: group: inference.networking.x-k8s.io kind: InferencePool name: INFERENCE_POOL_NAMERemplacez les éléments suivants :
NAMESPACE_NAME: nom de l'espace de noms dans lequel votreInferencePoolest déployé.INFERENCE_POOL_NAME: le nom duInferencePool.
Appliquez l'exemple de fichier manifeste à votre cluster :
kubectl apply -f logging-backend-policy.yaml
Après avoir appliqué ce fichier manifeste, GKE Inference Gateway active les journaux d'accès HTTP pour le InferencePool spécifié. Vous pouvez consulter ces journaux dans Cloud Logging. Les journaux incluent des informations détaillées sur chaque requête et réponse, telles que l'URL de la requête, les en-têtes, le code d'état de la réponse et la latence.
Créer des métriques basées sur les journaux pour afficher les détails des erreurs
Vous pouvez utiliser des métriques basées sur les journaux pour analyser vos journaux d'équilibrage de charge et extraire les détails des erreurs. Chaque classe Gateway GKE, comme les classes Gateway gke-l7-global-external-managed et gke-l7-regional-internal-managed, est soutenue par un équilibreur de charge différent. Pour en savoir plus, consultez Fonctionnalités de la ressource GatewayClass.
Chaque équilibreur de charge possède une ressource surveillée différente que vous devez utiliser lorsque vous créez une métrique basée sur les journaux. Pour en savoir plus sur la ressource surveillée pour chaque équilibreur de charge, consultez les pages suivantes :
- Pour les équilibreurs de charge externes régionaux : Métriques basées sur les journaux pour les équilibreurs de charge HTTP(S) externes
- Pour les équilibreurs de charge internes : Métriques basées sur les journaux pour les équilibreurs de charge HTTP(S) internes
Pour créer une métrique basée sur les journaux afin d'afficher les détails des erreurs, procédez comme suit :
Créez un fichier JSON nommé
error_detail_metric.jsonavec la définitionLogMetricsuivante. Cette configuration crée une métrique qui extrait le champproxyStatusde vos journaux d'équilibreur de charge.{ "description": "Metric to extract error details from load balancer logs.", "filter": "resource.type=\"MONITORED_RESOURCE\"", "metricDescriptor": { "metricKind": "DELTA", "valueType": "INT64", "labels": [ { "key": "error_detail", "valueType": "STRING", "description": "The detailed error string from the load balancer." } ] }, "labelExtractors": { "error_detail": "EXTRACT(jsonPayload.proxyStatus)" } }Remplacez
MONITORED_RESOURCEpar la ressource surveillée pour votre équilibreur de charge.Ouvrez Cloud Shell ou votre terminal local sur lequel gcloud CLI est installée.
Pour créer la métrique, exécutez la commande
gcloud logging metrics createavec l'indicateur--config-from-file:gcloud logging metrics create error_detail_metric \ --config-from-file=error_detail_metric.json
Une fois la métrique créée, vous pouvez l'utiliser dans Cloud Monitoring pour afficher la distribution des erreurs signalées par l'équilibreur de charge. Pour en savoir plus, consultez Créer une métrique basée sur les journaux.
Pour en savoir plus sur la création d'alertes à partir de métriques basées sur les journaux, consultez Créer une règle d'alerte sur une métrique de compteur.
Configurer l'autoscaling
L'autoscaling ajuste l'allocation des ressources en réponse aux variations de charge, en maintenant les performances et l'efficacité des ressources en ajoutant ou en supprimant dynamiquement des pods en fonction de la demande. Pour GKE Inference Gateway, cela implique l'autoscaling horizontal des pods dans chaque InferencePool. L'autoscaler horizontal de pods (AHP) GKE fait évoluer automatiquement les pods en fonction des métriques du serveur de modèle, telles que KVCache Utilization. Cela garantit que le service d'inférence gère différents volumes de charges de travail et de requêtes tout en gérant efficacement l'utilisation des ressources.
Pour configurer des instances InferencePool afin qu'elles s'adaptent automatiquement en fonction des métriques produites par GKE Inference Gateway, procédez comme suit :
Déployez un objet
PodMonitoringdans le cluster pour collecter les métriques générées par GKE Inference Gateway. Pour en savoir plus, consultez Configurer l'observabilité.Déployez l'adaptateur de métriques personnalisées Stackdriver pour donner à AHP accès aux métriques :
Enregistrez l'exemple de fichier manifeste suivant sous le nom
adapter_new_resource_model.yaml:apiVersion: v1 kind: Namespace metadata: name: custom-metrics --- apiVersion: v1 kind: ServiceAccount metadata: name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: custom-metrics:system:auth-delegator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:auth-delegator subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: custom-metrics-auth-reader namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: extension-apiserver-authentication-reader subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: custom-metrics-resource-reader rules: - apiGroups: - "" resources: - pods - nodes - nodes/stats verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: custom-metrics-resource-reader roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: custom-metrics-resource-reader subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: apps/v1 kind: Deployment metadata: name: custom-metrics-stackdriver-adapter labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter spec: replicas: 1 selector: matchLabels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter template: metadata: labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter kubernetes.io/cluster-service: "true" spec: serviceAccountName: custom-metrics-stackdriver-adapter containers: - image: gcr.io/gke-release/custom-metrics-stackdriver-adapter:v0.15.2-gke.1 imagePullPolicy: Always name: pod-custom-metrics-stackdriver-adapter command: - /adapter - --use-new-resource-model=true - --fallback-for-container-metrics=true resources: limits: cpu: 250m memory: 200Mi requests: cpu: 250m memory: 200Mi --- apiVersion: v1 kind: Service metadata: labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter kubernetes.io/cluster-service: 'true' kubernetes.io/name: Adapter name: custom-metrics-stackdriver-adapter namespace: custom-metrics spec: ports: - port: 443 protocol: TCP targetPort: 443 selector: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter type: ClusterIP --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta1.custom.metrics.k8s.io spec: insecureSkipTLSVerify: true group: custom.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 100 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta1 --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta2.custom.metrics.k8s.io spec: insecureSkipTLSVerify: true group: custom.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 200 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta2 --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta1.external.metrics.k8s.io spec: insecureSkipTLSVerify: true group: external.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 100 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta1 --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: external-metrics-reader rules: - apiGroups: - "external.metrics.k8s.io" resources: - "*" verbs: - list - get - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: external-metrics-reader roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: external-metrics-reader subjects: - kind: ServiceAccount name: horizontal-pod-autoscaler namespace: kube-systemAppliquez l'exemple de fichier manifeste à votre cluster :
kubectl apply -f adapter_new_resource_model.yaml
Pour accorder à l'adaptateur l'autorisation de lire les métriques du projet, exécutez la commande suivante :
$ PROJECT_ID=PROJECT_ID $ PROJECT_NUMBER=$(gcloud projects describe PROJECT_ID --format="value(projectNumber)") $ gcloud projects add-iam-policy-binding projects/PROJECT_ID \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.s3ns.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterRemplacez
PROJECT_IDpar l'ID du projet Cloud de Confiance .Pour chaque
InferencePool, déployez un AHP semblable à ce qui suit :apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: INFERENCE_POOL_NAME namespace: INFERENCE_POOL_NAMESPACE spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: INFERENCE_POOL_NAME minReplicas: MIN_REPLICAS maxReplicas: MAX_REPLICAS metrics: - type: External external: metric: name: prometheus.googleapis.com|inference_pool_average_kv_cache_utilization|gauge selector: matchLabels: metric.labels.name: INFERENCE_POOL_NAME resource.labels.cluster: CLUSTER_NAME resource.labels.namespace: INFERENCE_POOL_NAMESPACE target: type: AverageValue averageValue: TARGET_VALUERemplacez les éléments suivants :
INFERENCE_POOL_NAME: le nom duInferencePool.INFERENCE_POOL_NAMESPACE: espace de noms deInferencePool.CLUSTER_NAME: nom du cluster.MIN_REPLICAS: disponibilité minimale deInferencePool(capacité de référence). AHP maintient ce nombre de répliques lorsque l'utilisation est inférieure au seuil cible du AHP. Les charges de travail à haute disponibilité doivent définir cette valeur sur une valeur supérieure à1pour assurer une disponibilité continue en cas de perturbations des pods.MAX_REPLICAS: valeur qui limite le nombre d'accélérateurs à attribuer aux charges de travail hébergées dansInferencePool. AHP n'augmentera pas le nombre d'instances répliquées au-delà de cette valeur. Pendant les périodes de trafic maximal, surveillez le nombre de répliques pour vous assurer que la valeur du champMAX_REPLICASoffre une marge suffisante pour que la charge de travail puisse évoluer et maintenir les caractéristiques de performances choisies.TARGET_VALUE: valeur représentant la cible choisieKV-Cache Utilizationpar serveur de modèle. Il s'agit d'un nombre compris entre 0 et 100, qui dépend fortement du serveur de modèle, du modèle, de l'accélérateur et des caractéristiques du trafic entrant. Vous pouvez déterminer cette valeur cible de manière expérimentale en effectuant des tests de charge et en traçant un graphique du débit par rapport à la latence. Sélectionnez une combinaison de débit et de latence dans le graphique, puis utilisez la valeurKV-Cache Utilizationcorrespondante comme cible AHP. Vous devez ajuster et surveiller attentivement cette valeur pour obtenir les résultats prix/performances souhaités. Vous pouvez utiliser le guide de démarrage rapide de GKE Inference pour déterminer automatiquement cette valeur.
Étapes suivantes
- En savoir plus sur la passerelle d'inférence GKE
- Déployez GKE Inference Gateway.
- Gérez les opérations de déploiement de GKE Inference Gateway.
- Mettre en service avec la passerelle d'inférence GKE