
Halaman ini menjelaskan cara menyesuaikan deployment GKE Inference Gateway.
Halaman ini ditujukan bagi spesialis Jaringan yang bertanggung jawab mengelola infrastruktur GKE, dan bagi administrator platform yang mengelola workload AI.
Untuk mengelola dan mengoptimalkan workload inferensi, Anda mengonfigurasi fitur lanjutan GKE Inference Gateway.
Pahami dan konfigurasi fitur lanjutan berikut:
- Untuk menggunakan integrasi Model Armor, konfigurasi pemeriksaan keamanan dan keselamatan AI.
- Untuk meningkatkan GKE Inference Gateway dengan fitur seperti keamanan API, pembatasan kapasitas, dan analisis, konfigurasi Apigee untuk autentikasi dan pengelolaan API.
- Untuk merutekan permintaan berdasarkan nama model dalam isi permintaan, konfigurasi Perutean Berbasis Isi.
- Untuk melihat metrik dan dasbor untuk GKE Inference Gateway dan server model, serta untuk mengaktifkan logging akses HTTP, konfigurasi kemampuan observasi.
- Untuk menskalakan deployment GKE Inference Gateway secara otomatis, konfigurasi penskalaan otomatis.
Mengonfigurasi pemeriksaan keamanan dan keselamatan AI
GKE Inference Gateway terintegrasi dengan Model Armor untuk melakukan pemeriksaan keamanan pada perintah dan respons untuk aplikasi yang menggunakan model bahasa besar (LLM). Integrasi ini memberikan lapisan tambahan penegakan keamanan di tingkat infrastruktur yang melengkapi langkah-langkah keamanan tingkat aplikasi. Hal ini memungkinkan penerapan kebijakan terpusat di semua traffic LLM.
Diagram berikut mengilustrasikan integrasi Model Armor dengan GKE Inference Gateway pada cluster GKE:
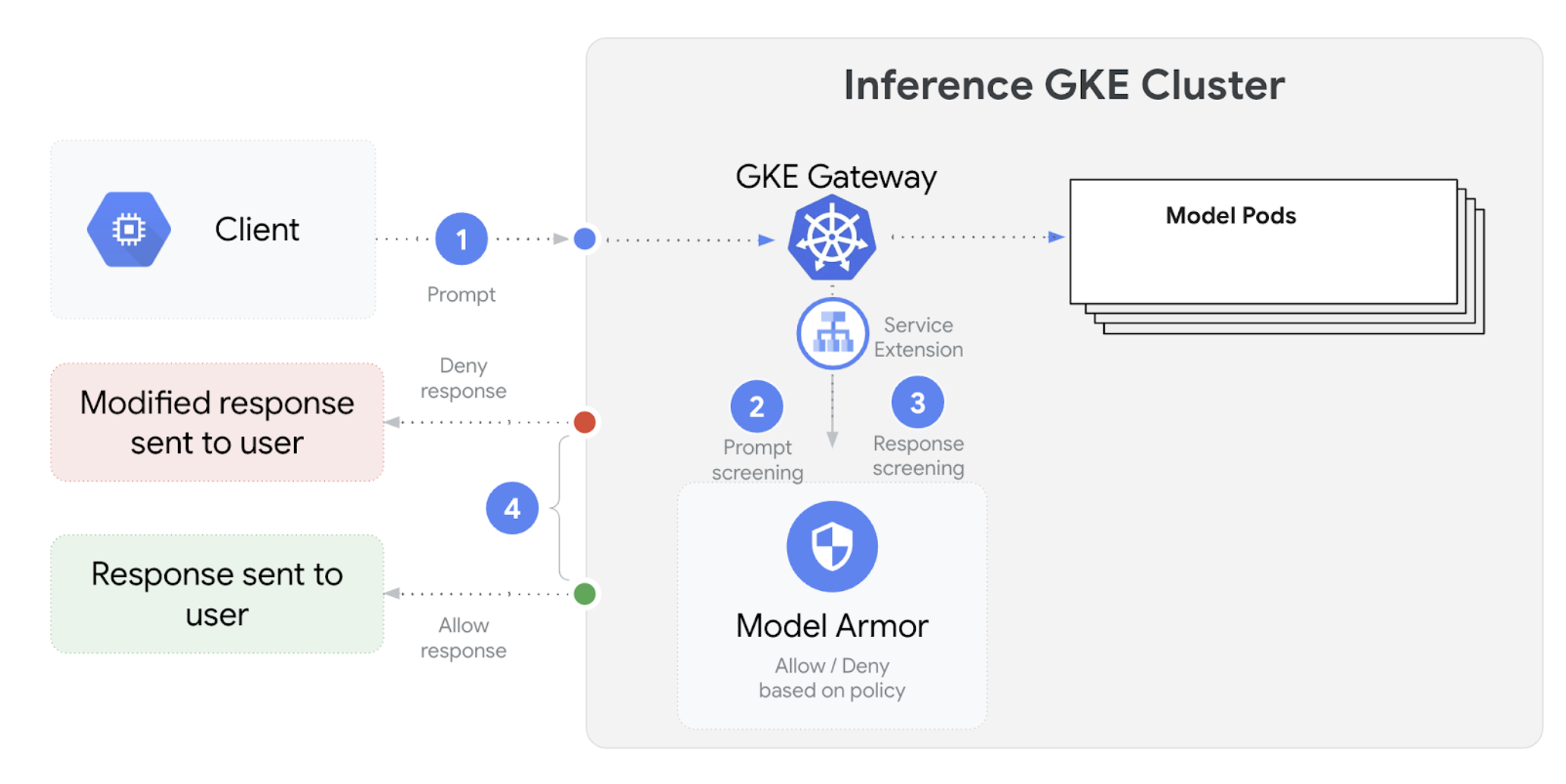
Untuk mengonfigurasi pemeriksaan keamanan AI, lakukan langkah-langkah berikut:
Prasyarat
- Aktifkan layanan Model Armor di project Cloud de Confiance by S3NS Anda.
Buat template Model Armor menggunakan konsol Model Armor, Google Cloud CLI, atau API. Perintah berikut membuat template bernama
llmyang mencatat operasi dan memfilter konten berbahaya.# Set environment variables PROJECT_ID=$(gcloud config get-value project) # Replace <var>CLUSTER_LOCATION<var> with the location of your GKE cluster. For example, `us-central1`. LOCATION="CLUSTER_LOCATION" MODEL_ARMOR_TEMPLATE_NAME=llm # Set the regional API endpoint gcloud config set api_endpoint_overrides/modelarmor \ "https://modelarmor.$LOCATION.rep.googleapis.com/" # Create the template gcloud model-armor templates create $MODEL_ARMOR_TEMPLATE_NAME \ --location $LOCATION \ --pi-and-jailbreak-filter-settings-enforcement=enabled \ --pi-and-jailbreak-filter-settings-confidence-level=MEDIUM_AND_ABOVE \ --rai-settings-filters='[{ "filterType": "HATE_SPEECH", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "DANGEROUS", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "HARASSMENT", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "SEXUALLY_EXPLICIT", "confidenceLevel": "MEDIUM_AND_ABOVE" }]' \ --template-metadata-log-sanitize-operations \ --template-metadata-log-operations
Memberikan izin IAM
Akun layanan Ekstensi Layanan memerlukan izin untuk mengakses resource yang diperlukan. Berikan peran yang diperlukan dengan menjalankan perintah berikut:
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format 'get(projectNumber)') gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.s3ns-system.iam.gserviceaccount.com \ --role=roles/container.admin gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.s3ns-system.iam.gserviceaccount.com \ --role=roles/modelarmor.calloutUser gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.s3ns-system.iam.gserviceaccount.com \ --role=roles/serviceusage.serviceUsageConsumer gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.s3ns-system.iam.gserviceaccount.com \ --role=roles/modelarmor.userKonfigurasi
GCPTrafficExtensionUntuk menerapkan kebijakan Model Armor ke Gateway Anda, buat resource
GCPTrafficExtensiondengan format metadata yang benar.Simpan manifes contoh berikut sebagai
gcp-traffic-extension.yaml:kind: GCPTrafficExtension apiVersion: networking.gke.io/v1 metadata: name: my-model-armor-extension spec: targetRefs: - group: "gateway.networking.k8s.io" kind: Gateway name: GATEWAY_NAME extensionChains: - name: my-model-armor-chain1 matchCondition: celExpressions: - celMatcher: request.path.startsWith("/") extensions: - name: my-model-armor-service supportedEvents: - RequestHeaders - RequestBody - RequestTrailers - ResponseHeaders - ResponseBody - ResponseTrailers timeout: 1s failOpen: false googleAPIServiceName: "modelarmor.${LOCATION}.rep.googleapis.com" metadata: model_armor_settings: '[{"model": "${MODEL}","model_response_template_id": "projects/${PROJECT_ID}/locations/${LOCATION}/templates/${MODEL_ARMOR_TEMPLATE_NAME}","user_prompt_template_id": "projects/${PROJECT_ID}/locations/${LOCATION}/templates/${MODEL_ARMOR_TEMPLATE_NAME}"}]'Ganti kode berikut:
GATEWAY_NAME: nama Gateway.MODEL_ARMOR_TEMPLATE_NAME: nama template Model Armor Anda.
File
gcp-traffic-extension.yamlmencakup setelan berikut:targetRefs: menentukan Gateway tempat ekstensi ini diterapkan.extensionChains: menentukan rangkaian ekstensi yang akan diterapkan ke traffic.matchCondition: menentukan kondisi penerapan ekstensi.extensions: menentukan ekstensi yang akan diterapkan.supportedEvents: menentukan peristiwa saat ekstensi dipanggil.timeout: menentukan waktu tunggu untuk ekstensi.googleAPIServiceName: menentukan nama layanan untuk ekstensi.metadata: menentukan metadata untuk ekstensi, termasukextensionPolicydan setelan pembersihan perintah atau respons.
Terapkan manifes contoh ke cluster Anda:
export GATEWAY_NAME="your-gateway-name" export MODEL="google/gemma-3-1b-it" # Or your specific model envsubst < gcp-traffic-extension.yaml | kubectl apply -f -
Setelah Anda mengonfigurasi pemeriksaan keamanan AI dan mengintegrasikannya dengan Gateway, Model Armor akan otomatis memfilter perintah dan respons berdasarkan aturan yang ditentukan.
Mengonfigurasi Apigee untuk autentikasi dan pengelolaan API
GKE Inference Gateway terintegrasi dengan Apigee untuk menyediakan autentikasi, otorisasi, dan pengelolaan API untuk workload inferensi Anda. Untuk mempelajari lebih lanjut manfaat penggunaan Apigee, lihat Manfaat utama penggunaan Apigee.
Anda dapat mengintegrasikan GKE Inference Gateway dengan Apigee untuk meningkatkan kualitas GKE Inference Gateway dengan fitur seperti keamanan API, pembatasan kecepatan, kuota, analisis, dan monetisasi.
Prasyarat
Sebelum memulai, pastikan Anda memiliki hal-hal berikut:
- Cluster GKE yang menjalankan versi 1.34.* atau yang lebih baru.
- Cluster GKE dengan GKE Inference Gateway yang di-deploy.
- Instance Apigee yang dibuat di region yang sama dengan cluster GKE Anda.
- Operator APIM Apigee dan CRD-nya diinstal di cluster GKE Anda. Untuk mengetahui petunjuknya, lihat Menginstal operator APIM Apigee.
kubectldikonfigurasi untuk terhubung ke cluster GKE Anda.Google Cloud CLIdiinstal dan diautentikasi.
Membuat ApigeeBackendService
Pertama, buat resource ApigeeBackendService. GKE Inference Gateway menggunakan ini
untuk membuat Apigee Extension Processor.
Simpan manifes berikut sebagai
my-apigee-backend-service.yaml:apiVersion: apim.googleapis.com/v1 kind: ApigeeBackendService metadata: name: my-apigee-backend-service spec: apigeeEnv: "APIGEE_ENVIRONMENT_NAME" # optional field defaultSecurityEnabled: true # optional field locations: name: "LOCATION" network: "CLUSTER_NETWORK" subnetwork: "CLUSTER_SUBNETWORK"Ganti kode berikut:
APIGEE_ENVIRONMENT_NAME: Nama lingkungan Apigee Anda. Catatan: Anda tidak perlu menetapkan kolom ini jikaapigee-apim-operatordiinstal dengan flaggenerateEnv=TRUE. Jika belum, buat lingkungan Apigee dengan mengikuti petunjuk di Membuat lingkungan.LOCATION: Lokasi instance Apigee Anda.CLUSTER_NETWORK: Jaringan cluster GKE Anda.CLUSTER_SUBNETWORK: Subnetwork cluster GKE Anda.
Terapkan manifes ke cluster Anda:
kubectl apply -f my-apigee-backend-service.yamlVerifikasi bahwa status telah menjadi
CREATED:kubectl wait --for=jsonpath='{.status.currentState}'="CREATED" -f my-apigee-backend-service.yaml --timeout=5m
Mengonfigurasi GKE Inference Gateway
Konfigurasi GKE Inference Gateway untuk mengaktifkan Apigee Extension Processor sebagai ekstensi traffic load balancer.
Simpan manifes berikut sebagai
my-apigee-traffic-extension.yaml:kind: GCPTrafficExtension apiVersion: networking.gke.io/v1 metadata: name: my-apigee-traffic-extension spec: targetRefs: - group: "gateway.networking.k8s.io" kind: Gateway name: GATEWAY_NAME extensionChains: - name: my-traffic-extension-chain matchCondition: celExpressions: - celMatcher: request.path.startsWith("/") extensions: - name: my-apigee-extension metadata: # The value for `apigee-extension-processor` must match the name of the `ApigeeBackendService` resource that was applied earlier. apigee-extension-processor: my-apigee-backend-service failOpen: false timeout: 1s supportedEvents: - RequestHeaders - ResponseHeaders - ResponseBody backendRef: group: apim.googleapis.com kind: ApigeeBackendService name: my-apigee-backend-service port: 443Ganti
GATEWAY_NAMEdengan nama Gateway Anda.Terapkan manifes ke cluster Anda:
kubectl apply -f my-apigee-traffic-extension.yamlTunggu hingga status
GCPTrafficExtensionmenjadiProgrammed:kubectl wait --for=jsonpath='{.status.ancestors[0].conditions[?(@.type=="Programmed")].status}'=True -f my-apigee-traffic-extension.yaml --timeout=5m
Mengirim Permintaan yang Diautentikasi menggunakan kunci API
Untuk menemukan alamat IP GKE Inference Gateway, periksa status Gateway:
GW_IP=$(kubectl get gateway/GATEWAY_NAME -o jsonpath='{.status.addresses[0].value}')Ganti
GATEWAY_NAMEdengan nama Gateway Anda.Uji permintaan tanpa autentikasi. Permintaan ini harus ditolak:
curl -i ${GW_IP}/v1/completions -H 'Content-Type: application/json' -d '{ "model": "food-review", "prompt": "Write as if you were a critic: San Francisco", "max_tokens": 100, "temperature": 0 }'Anda akan melihat respons yang mirip dengan berikut, yang menunjukkan bahwa ekstensi Apigee berfungsi:
{"fault":{"faultstring":"Raising fault. Fault name : RF-insufficient-request-raise-fault","detail":{"errorcode":"steps.raisefault.RaiseFault"}}}Akses UI Apigee dan buat kunci API. Untuk mengetahui petunjuknya, lihat Membuat kunci API.
Kirim Kunci API di header permintaan HTTP:
curl -i ${GW_IP}/v1/completions -H 'Content-Type: application/json' -H 'x-api-key: API_KEY' -d '{ "model": "food-review", "prompt": "Write as if you were a critic: San Francisco", "max_tokens": 100, "temperature": 0 }'Ganti
API_KEYdengan kunci API Anda.
Untuk informasi yang lebih mendetail tentang cara mengonfigurasi kebijakan Apigee, lihat Menggunakan kebijakan pengelolaan API dengan Operator APIM Apigee untuk Kubernetes.
Mengonfigurasi kemampuan observasi
Gateway Inferensi GKE memberikan insight tentang kondisi, performa, dan perilaku workload inferensi Anda. Hal ini membantu Anda mengidentifikasi dan menyelesaikan masalah, mengoptimalkan pemanfaatan resource, dan memastikan keandalan aplikasi Anda.
Cloud de Confiance by S3NS menyediakan dasbor Cloud Monitoring berikut yang menawarkan kemampuan observasi inferensi untuk GKE Inference Gateway:
- Dasbor GKE Inference Gateway:
menyediakan metrik penting untuk penayangan LLM, seperti throughput permintaan
dan token, latensi, error, dan pemanfaatan cache untuk
InferencePool. Untuk melihat daftar lengkap metrik GKE Inference Gateway yang tersedia, lihat Metrik yang diekspos. - Dasbor kemampuan observasi AI/ML: menyediakan dasbor untuk penggunaan infrastruktur, metrik DCGM, dan metrik performa model vLLM.
- Dasbor server model: menyediakan dasbor untuk sinyal utama server model. Hal ini memungkinkan Anda memantau beban dan performa server model, seperti
KVCache UtilizationdanQueue length. - Dasbor load balancer: melaporkan metrik dari load balancer, seperti permintaan per detik, latensi penayangan permintaan end-to-end, dan kode status permintaan-respons. Metrik ini membantu Anda memahami performa penayangan permintaan end-to-end dan mengidentifikasi error.
- Metrik Data Center GPU Manager (DCGM): menyediakan metrik DCGM, seperti performa dan penggunaan GPU NVIDIA. Anda dapat mengonfigurasi metrik DCGM di Cloud Monitoring. Untuk informasi selengkapnya, lihat Mengumpulkan dan melihat metrik DCGM.
Melihat dasbor GKE Inference Gateway
Untuk melihat dasbor GKE Inference Gateway, lakukan langkah-langkah berikut:
Di konsol Cloud de Confiance , buka halaman Monitoring.
Di panel navigasi, pilih Dashboards.
Di bagian Integrasi, pilih GMP.
Di halaman Cloud Monitoring Dashboard Templates, telusuri "Gateway".
Lihat dasbor GKE Inference Gateway.
Atau, Anda dapat mengikuti petunjuk di Dasbor pemantauan.
Melihat dasbor kemampuan observasi model AI/ML
Untuk melihat model dan dasbor yang di-deploy untuk metrik kemampuan observasi model, ikuti langkah-langkah berikut:
Di konsol Cloud de Confiance , buka halaman Deployed Models.
Untuk melihat detail tentang deployment tertentu, termasuk metrik, log, dan dasbornya, klik nama model dalam daftar.
Di halaman detail model, klik tab Observability untuk melihat dasbor berikut. Jika diminta, klik Enable untuk mengaktifkan dasbor.
- Dasbor Penggunaan infrastruktur menampilkan metrik penggunaan.
- Dasbor DCGM menampilkan metrik DCGM.
- Jika Anda menggunakan vLLM, dasbor Performa model akan tersedia dan menampilkan metrik untuk performa model vLLM.
Mengonfigurasi dasbor kemampuan observasi server model
Untuk mengumpulkan sinyal penting dari setiap server model dan memahami apa yang berkontribusi pada performa GKE Inference Gateway, Anda dapat mengonfigurasi pemantauan otomatis untuk server model. Hal ini mencakup server model seperti berikut:
Untuk melihat dasbor integrasi, pastikan terlebih dahulu Anda mengumpulkan metrik dari server model. Kemudian, lakukan langkah-langkah berikut:
Di konsol Cloud de Confiance , buka halaman Monitoring.
Di panel navigasi, pilih Dashboards.
Di bagian Integrations, pilih GMP. Dasbor integrasi yang sesuai akan ditampilkan.
Gambar: Dasbor integrasi
Untuk informasi selengkapnya, lihat Menyesuaikan pemantauan untuk aplikasi.
Mengonfigurasi pemberitahuan Cloud Monitoring
Untuk mengonfigurasi pemberitahuan Cloud Monitoring untuk GKE Inference Gateway, lakukan langkah-langkah berikut:
Simpan manifes contoh berikut sebagai
alerts.yamldan ubah nilai minimum sesuai kebutuhan:groups: - name: gateway-api-inference-extension rules: - alert: HighInferenceRequestLatencyP99 annotations: title: 'High latency (P99) for model {{ $labels.model_name }}' description: 'The 99th percentile request duration for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 10.0 seconds for 5 minutes.' expr: histogram_quantile(0.99, rate(inference_model_request_duration_seconds_bucket[5m])) > 10.0 for: 5m labels: severity: 'warning' - alert: HighInferenceErrorRate annotations: title: 'High error rate for model {{ $labels.model_name }}' description: 'The error rate for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 5% for 5 minutes.' expr: sum by (model_name) (rate(inference_model_request_error_total[5m])) / sum by (model_name) (rate(inference_model_request_total[5m])) > 0.05 for: 5m labels: severity: 'critical' impact: 'availability' - alert: HighInferencePoolAvgQueueSize annotations: title: 'High average queue size for inference pool {{ $labels.name }}' description: 'The average number of requests pending in the queue for inference pool {{ $labels.name }} has been consistently above 50 for 5 minutes.' expr: inference_pool_average_queue_size > 50 for: 5m labels: severity: 'critical' impact: 'performance' - alert: HighInferencePoolAvgKVCacheUtilization annotations: title: 'High KV cache utilization for inference pool {{ $labels.name }}' description: 'The average KV cache utilization for inference pool {{ $labels.name }} has been consistently above 90% for 5 minutes, indicating potential resource exhaustion.' expr: inference_pool_average_kv_cache_utilization > 0.9 for: 5m labels: severity: 'critical' impact: 'resource_exhaustion'Untuk membuat kebijakan pemberitahuan, jalankan perintah berikut:
gcloud alpha monitoring policies migrate --policies-from-prometheus-alert-rules-yaml=alerts.yamlAnda akan melihat kebijakan pemberitahuan baru di halaman Pemberitahuan.
Mengubah pemberitahuan
Anda dapat menemukan daftar lengkap metrik terbaru yang tersedia di repositori GitHub kubernetes-sigs/gateway-api-inference-extension, dan Anda dapat menambahkan pemberitahuan baru ke manifes menggunakan metrik lain.
Untuk mengubah contoh pemberitahuan, perhatikan contoh berikut:
- alert: HighInferenceRequestLatencyP99
annotations:
title: 'High latency (P99) for model {{ $labels.model_name }}'
description: 'The 99th percentile request duration for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 10.0 seconds for 5 minutes.'
expr: histogram_quantile(0.99, rate(inference_model_request_duration_seconds_bucket[5m])) > 10.0
for: 5m
labels:
severity: 'warning'
Pemberitahuan ini akan aktif jika persentil ke-99 durasi permintaan selama 5 menit
melebihi 10 detik. Anda dapat mengubah bagian expr dari pemberitahuan untuk menyesuaikan
batas berdasarkan persyaratan Anda.
Mengonfigurasi logging untuk GKE Inference Gateway
Mengonfigurasi logging untuk GKE Inference Gateway memberikan informasi mendetail tentang permintaan dan respons, yang berguna untuk pemecahan masalah, audit, dan analisis performa. Log akses HTTP mencatat setiap permintaan dan respons, termasuk header, kode status, dan stempel waktu. Tingkat detail ini dapat membantu Anda mengidentifikasi masalah, menemukan error, dan memahami perilaku beban kerja inferensi Anda.
Untuk mengonfigurasi logging untuk GKE Inference Gateway, aktifkan logging akses HTTP untuk setiap objek InferencePool Anda.
Simpan manifes contoh berikut sebagai
logging-backend-policy.yaml:apiVersion: networking.gke.io/v1 kind: GCPBackendPolicy metadata: name: logging-backend-policy namespace: NAMESPACE_NAME spec: default: logging: enabled: true sampleRate: 500000 targetRef: group: inference.networking.x-k8s.io kind: InferencePool name: INFERENCE_POOL_NAMEGanti kode berikut:
NAMESPACE_NAME: nama namespace tempatInferencePoolAnda di-deploy.INFERENCE_POOL_NAME: namaInferencePool.
Terapkan manifes contoh ke cluster Anda:
kubectl apply -f logging-backend-policy.yaml
Setelah Anda menerapkan manifes ini, GKE Inference Gateway akan mengaktifkan log akses HTTP untuk InferencePool yang ditentukan. Anda dapat melihat log ini di Cloud Logging. Log mencakup informasi mendetail tentang setiap permintaan dan respons, seperti URL permintaan, header, kode status respons, dan latensi.
Membuat metrik berbasis log untuk melihat detail error
Anda dapat menggunakan metrik berbasis log untuk menganalisis log load balancing dan mengekstrak detail error. Setiap class Gateway GKE, seperti class Gateway
gke-l7-global-external-managed dan gke-l7-regional-internal-managed, didukung oleh load balancer yang berbeda. Untuk mengetahui informasi
selengkapnya, lihat Kemampuan
GatewayClass.
Setiap load balancer memiliki resource yang dipantau berbeda yang harus Anda gunakan saat membuat metrik berbasis log. Untuk mengetahui informasi selengkapnya tentang resource yang dipantau untuk setiap load balancer, lihat artikel berikut:
- Untuk load balancer eksternal regional: Metrik berbasis log untuk load balancer HTTP(S) eksternal
- Untuk load balancer internal: Metrik berbasis log untuk load balancer HTTP(S) internal
Untuk membuat metrik berbasis log guna melihat detail error, lakukan langkah berikut:
Buat file JSON bernama
error_detail_metric.jsondengan definisiLogMetricberikut. Konfigurasi ini membuat metrik yang mengekstrak kolomproxyStatusdari log load balancer Anda.{ "description": "Metric to extract error details from load balancer logs.", "filter": "resource.type=\"MONITORED_RESOURCE\"", "metricDescriptor": { "metricKind": "DELTA", "valueType": "INT64", "labels": [ { "key": "error_detail", "valueType": "STRING", "description": "The detailed error string from the load balancer." } ] }, "labelExtractors": { "error_detail": "EXTRACT(jsonPayload.proxyStatus)" } }Ganti
MONITORED_RESOURCEdengan resource yang dipantau untuk load balancer Anda.Buka Cloud Shell atau terminal lokal tempat gcloud CLI diinstal.
Untuk membuat metrik, jalankan perintah
gcloud logging metrics createdengan flag--config-from-file:gcloud logging metrics create error_detail_metric \ --config-from-file=error_detail_metric.json
Setelah metrik dibuat, Anda dapat menggunakannya di Cloud Monitoring untuk melihat distribusi error yang dilaporkan oleh load balancer. Untuk mengetahui informasi selengkapnya, lihat Membuat metrik berbasis log.
Untuk mengetahui informasi selengkapnya tentang cara membuat pemberitahuan dari metrik berbasis log, lihat Membuat kebijakan pemberitahuan pada metrik penghitung.
Konfigurasi penskalaan otomatis
Penskalaan otomatis menyesuaikan alokasi resource sebagai respons terhadap variasi beban,
mempertahankan performa dan efisiensi resource dengan menambahkan atau
menghapus Pod secara dinamis berdasarkan permintaan. Untuk GKE Inference Gateway, hal ini melibatkan
penskalaan otomatis horizontal Pod di setiap InferencePool. Horizontal Pod Autoscaler (HPA) GKE menskalakan otomatis Pod berdasarkan metrik server model
seperti KVCache Utilization. Hal ini memastikan layanan inferensi menangani
berbagai workload dan volume kueri sekaligus mengelola penggunaan resource secara efisien.
Untuk mengonfigurasi instance InferencePool agar menskalakan otomatis berdasarkan metrik yang dihasilkan oleh GKE Inference Gateway, lakukan langkah-langkah berikut:
Deploy objek
PodMonitoringdi cluster untuk mengumpulkan metrik yang dihasilkan oleh GKE Inference Gateway. Untuk mengetahui informasi selengkapnya, lihat Mengonfigurasi kemampuan pengamatan.Deploy Custom Metrics Stackdriver Adapter untuk memberi HPA akses ke metrik:
Simpan manifes contoh berikut sebagai
adapter_new_resource_model.yaml:apiVersion: v1 kind: Namespace metadata: name: custom-metrics --- apiVersion: v1 kind: ServiceAccount metadata: name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: custom-metrics:system:auth-delegator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:auth-delegator subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: custom-metrics-auth-reader namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: extension-apiserver-authentication-reader subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: custom-metrics-resource-reader rules: - apiGroups: - "" resources: - pods - nodes - nodes/stats verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: custom-metrics-resource-reader roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: custom-metrics-resource-reader subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: apps/v1 kind: Deployment metadata: name: custom-metrics-stackdriver-adapter labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter spec: replicas: 1 selector: matchLabels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter template: metadata: labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter kubernetes.io/cluster-service: "true" spec: serviceAccountName: custom-metrics-stackdriver-adapter containers: - image: gcr.io/gke-release/custom-metrics-stackdriver-adapter:v0.15.2-gke.1 imagePullPolicy: Always name: pod-custom-metrics-stackdriver-adapter command: - /adapter - --use-new-resource-model=true - --fallback-for-container-metrics=true resources: limits: cpu: 250m memory: 200Mi requests: cpu: 250m memory: 200Mi --- apiVersion: v1 kind: Service metadata: labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter kubernetes.io/cluster-service: 'true' kubernetes.io/name: Adapter name: custom-metrics-stackdriver-adapter namespace: custom-metrics spec: ports: - port: 443 protocol: TCP targetPort: 443 selector: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter type: ClusterIP --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta1.custom.metrics.k8s.io spec: insecureSkipTLSVerify: true group: custom.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 100 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta1 --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta2.custom.metrics.k8s.io spec: insecureSkipTLSVerify: true group: custom.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 200 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta2 --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta1.external.metrics.k8s.io spec: insecureSkipTLSVerify: true group: external.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 100 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta1 --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: external-metrics-reader rules: - apiGroups: - "external.metrics.k8s.io" resources: - "*" verbs: - list - get - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: external-metrics-reader roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: external-metrics-reader subjects: - kind: ServiceAccount name: horizontal-pod-autoscaler namespace: kube-systemTerapkan manifes contoh ke cluster Anda:
kubectl apply -f adapter_new_resource_model.yaml
Untuk memberikan izin adapter guna membaca metrik dari project, jalankan perintah berikut:
$ PROJECT_ID=PROJECT_ID $ PROJECT_NUMBER=$(gcloud projects describe PROJECT_ID --format="value(projectNumber)") $ gcloud projects add-iam-policy-binding projects/PROJECT_ID \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.s3ns.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterGanti
PROJECT_IDdengan Cloud de Confiance project ID Anda.Untuk setiap
InferencePool, deploy satu HPA yang mirip dengan berikut ini:apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: INFERENCE_POOL_NAME namespace: INFERENCE_POOL_NAMESPACE spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: INFERENCE_POOL_NAME minReplicas: MIN_REPLICAS maxReplicas: MAX_REPLICAS metrics: - type: External external: metric: name: prometheus.googleapis.com|inference_pool_average_kv_cache_utilization|gauge selector: matchLabels: metric.labels.name: INFERENCE_POOL_NAME resource.labels.cluster: CLUSTER_NAME resource.labels.namespace: INFERENCE_POOL_NAMESPACE target: type: AverageValue averageValue: TARGET_VALUEGanti kode berikut:
INFERENCE_POOL_NAME: namaInferencePool.INFERENCE_POOL_NAMESPACE: namespaceInferencePool.CLUSTER_NAME: nama cluster.MIN_REPLICAS: ketersediaan minimumInferencePool(kapasitas dasar). HPA mempertahankan jumlah replika ini saat penggunaan berada di bawah nilai minimum target HPA. Workload dengan ketersediaan tinggi harus menyetelnya ke nilai yang lebih tinggi dari1untuk memastikan ketersediaan berkelanjutan selama gangguan Pod.MAX_REPLICAS: nilai yang membatasi jumlah akselerator yang harus ditetapkan ke workload yang dihosting diInferencePool. HPA tidak akan meningkatkan jumlah replika di luar nilai ini. Selama waktu traffic puncak, pantau jumlah replika untuk memastikan nilai kolomMAX_REPLICASmemberikan ruang yang cukup sehingga beban kerja dapat di-scale up untuk mempertahankan karakteristik performa beban kerja yang dipilih.TARGET_VALUE: nilai yang merepresentasikan target yang dipilihKV-Cache Utilizationper server model. Nilai ini adalah angka antara 0-100 dan sangat bergantung pada server model, model, akselerator, dan karakteristik traffic masuk. Anda dapat menentukan nilai target ini secara eksperimental melalui pengujian beban dan memetakan grafik throughput versus latensi. Pilih kombinasi throughput dan latensi yang diinginkan dari grafik, dan gunakan nilaiKV-Cache Utilizationyang sesuai sebagai target HPA. Anda harus menyesuaikan dan memantau nilai ini dengan cermat untuk mencapai hasil performa harga yang diinginkan. Anda dapat menggunakan Panduan Memulai Inferensi GKE untuk menentukan nilai ini secara otomatis.
Langkah berikutnya
- Pelajari GKE Inference Gateway.
- Deploy GKE Inference Gateway.
- Mengelola operasi peluncuran GKE Inference Gateway.
- Menayangkan dengan GKE Inference Gateway.