
Nesta página, mostramos como realizar operações de lançamento incremental que implantam gradualmente novas versões da sua infraestrutura de inferência para o GKE Inference Gateway. Com ele, é possível fazer atualizações seguras e controladas na sua infraestrutura de inferência. É possível atualizar nós, modelos de base e adaptadores LoRA com interrupção mínima do serviço. Esta página também oferece orientações sobre divisão de tráfego e rollbacks para garantir implantações confiáveis.
Esta página é destinada a administradores de identidade e conta do GKE e desenvolvedores que querem realizar operações de lançamento para o GKE Inference Gateway.
Os seguintes casos de uso são compatíveis:
- Implantação da atualização de nós (computação, acelerador)
- Lançamento da atualização do modelo de base
Atualizar um lançamento de nós
As atualizações de nós migram com segurança as cargas de trabalho de inferência para novas configurações de hardware ou acelerador de nós. Esse processo ocorre de maneira controlada, sem interromper o serviço do modelo. Use as atualizações de nós para minimizar a interrupção do serviço durante upgrades de hardware, atualizações de drivers ou resolução de problemas de segurança.
Crie um novo
InferencePool: implante umInferencePoolconfigurado com o nó ou as especificações de hardware atualizadas.Divida o tráfego usando um
HTTPRoute: configure umHTTPRoutepara distribuir o tráfego entre os recursosInferencePoolatuais e novos. Use o campoweightembackendRefspara gerenciar a porcentagem de tráfego direcionada aos novos nós.Mantenha um
InferenceObjectiveconsistente: retenha a configuraçãoInferenceObjectiveatual para garantir um comportamento uniforme do modelo nas duas configurações de nó.Reter recursos originais: mantenha os
InferencePoole nós originais ativos durante o lançamento para permitir rollbacks, se necessário.
Por exemplo, você pode criar um novo InferencePool chamado llm-new. Configure
esse pool com a mesma configuração de modelo do seu llm
InferencePool atual. Implante o pool em um novo conjunto de nós no cluster. Use um objeto HTTPRoute para dividir o tráfego entre o llm original e o novo llm-new InferencePool. Com essa técnica, é possível atualizar os nós do modelo de forma incremental.
O diagrama a seguir ilustra como o GKE Inference Gateway realiza um lançamento de atualização de nó.
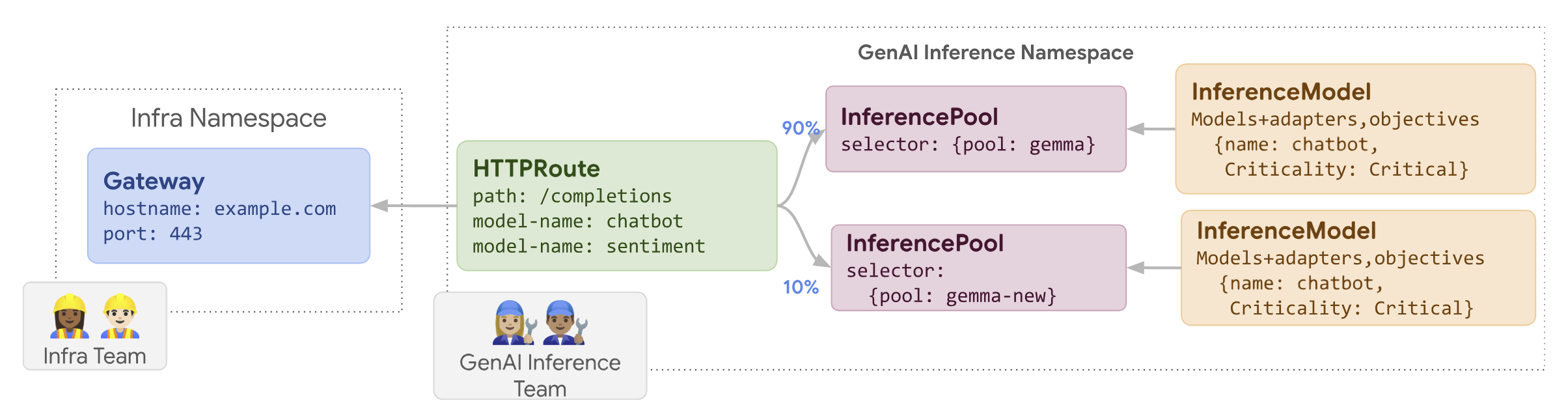
Para fazer o lançamento de uma atualização de nó, siga estas etapas:
Salve o seguinte manifesto de amostra como
routes-to-llm.yaml:apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-new group: inference.networking.k8s.io kind: InferencePool weight: 10Aplique o manifesto de amostra ao cluster:
kubectl apply -f routes-to-llm.yaml
O llm InferencePool original recebe a maior parte do tráfego, enquanto o
llm-new InferencePool recebe o restante. Aumente gradualmente a ponderação de tráfego para o llm-new InferencePool concluir o lançamento da atualização do nó.
Lançar um modelo de base
As atualizações do modelo de base são lançadas em fases para um novo LLM de base, mantendo a compatibilidade com os adaptadores LoRA atuais. É possível usar os lançamentos de atualizações do modelo de base para fazer upgrade para arquiteturas de modelo aprimoradas ou para resolver problemas específicos do modelo.
Para lançar uma atualização do modelo de base:
- Implantar nova infraestrutura: crie novos nós e um novo
InferencePoolconfigurado com o novo modelo de base escolhido. - Configurar a distribuição de tráfego: use um
HTTPRoutepara dividir o tráfego entre oInferencePoolatual (que usa o modelo de base antigo) e o novoInferencePool(usando o novo modelo de base). O campobackendRefs weightcontrola a porcentagem de tráfego alocada para cada pool. - Manter a integridade do
InferenceObjective: mantenha a configuração doInferenceObjectiveinalterada. Isso garante que o sistema aplique os mesmos adaptadores LoRA de maneira consistente nas duas versões do modelo de base. - Preserve a capacidade de reversão: mantenha os nós e o
InferencePooloriginais durante o lançamento para facilitar uma reversão, se necessário.
Você cria um novo InferencePool chamado llm-pool-version-2. Esse pool implanta
uma nova versão do modelo de base em um novo conjunto de nós. Ao
configurar um HTTPRoute, como mostrado no exemplo fornecido, é possível
dividir o tráfego de forma incremental entre o llm-pool original e
llm-pool-version-2. Isso permite controlar as atualizações do modelo de base no seu cluster.
Para fazer o lançamento de uma atualização do modelo de base, siga estas etapas:
Salve o seguinte manifesto de amostra como
routes-to-llm.yaml:apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm-pool group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-pool-version-2 group: inference.networking.k8s.io kind: InferencePool weight: 10Aplique o manifesto de amostra ao cluster:
kubectl apply -f routes-to-llm.yaml
O llm-pool InferencePool original recebe a maior parte do tráfego, enquanto o
llm-pool-version-2 InferencePool recebe o restante. Aumente gradualmente o peso do tráfego para o llm-pool-version-2 InferencePool e conclua o lançamento da atualização do modelo de base.
A seguir
- Personalizar a configuração do GKE Inference Gateway
- Disponibilizar um LLM com o gateway de inferência do GKE