
Esta página descreve como pode usar o início rápido da inferência do GKE para simplificar a implementação de cargas de trabalho de inferência de IA/ML no Google Kubernetes Engine (GKE). O Inference Quickstart é uma utilidade que lhe permite especificar os requisitos empresariais de inferência e obter configurações do Kubernetes otimizadas com base nas práticas recomendadas e nos testes de referência da Google para modelos, servidores de modelos, aceleradores (GPUs, TPUs), escalabilidade e armazenamento. Isto ajuda a evitar o processo demorado de ajustar e testar manualmente as configurações.
Esta página destina-se a engenheiros de aprendizagem automática (ML), administradores e operadores de plataformas, e especialistas em dados e IA que querem compreender como gerir e otimizar o GKE de forma eficiente para a inferência de IA/ML. Para saber mais sobre as funções comuns e as tarefas de exemplo a que fazemos referência no Cloud de Confiance by S3NS conteúdo, consulte o artigo Funções e tarefas comuns de utilizadores do GKE.
Para saber mais sobre os conceitos e a terminologia de publicação de modelos, e como as capacidades de IA gen do GKE podem melhorar e apoiar o desempenho da publicação de modelos, consulte o artigo Acerca da inferência de modelos no GKE.
Antes de ler esta página, certifique-se de que conhece o Kubernetes, o GKE e o serviço de modelos.
Usar o guia de início rápido da inferência
O Início rápido da inferência permite-lhe analisar o desempenho e a rentabilidade dos seus carregamentos de trabalho de inferência, bem como tomar decisões baseadas em dados sobre a atribuição de recursos e as estratégias de implementação de modelos.
Os passos de nível elevado para usar o Início rápido da inferência são os seguintes:
Analise o desempenho e o custo: explore as configurações disponíveis e filtre-as com base nos seus requisitos de desempenho e custo através do comando
gcloud container ai profiles list. Para ver o conjunto completo de dados de testes de referência para uma configuração específica, use o comandogcloud container ai profiles benchmarks list. Este comando permite-lhe identificar o hardware mais rentável para os seus requisitos de desempenho específicos.Implemente manifestos: após a análise, pode gerar um manifesto do Kubernetes otimizado e implementá-lo. Opcionalmente, pode ativar as otimizações para o armazenamento e o dimensionamento automático. Pode implementar a partir da Cloud de Confiance consola ou através do comando
kubectl apply. Antes da implementação, tem de garantir que tem uma quota de acelerador suficiente para as GPUs ou TPUs selecionadas no seu Cloud de Confiance by S3NS projeto.(Opcional) Execute as suas próprias referências: as configurações e os dados de desempenho fornecidos baseiam-se em referências que usam o conjunto de dados ShareGPT. O desempenho das suas cargas de trabalho pode variar em relação a esta base de referência. Para medir o desempenho do seu modelo em várias condições, pode usar a ferramenta de referência de inferência experimental.
Vantagens
O guia de início rápido da inferência ajuda a poupar tempo e recursos, fornecendo configurações otimizadas. Estas otimizações melhoram o desempenho e reduzem os custos de infraestrutura das seguintes formas:
- Recebe práticas recomendadas detalhadas e personalizadas para definir o acelerador (GPU e TPU), o servidor de modelos e as configurações de escalabilidade. O GKE atualiza rotineiramente o Início rápido de inferência com as correções, as imagens e os testes de desempenho mais recentes.
- Pode especificar os requisitos de latência e débito da sua carga de trabalho através da IU da consola ou de uma interface de linha de comandos, e receber práticas recomendadas detalhadas e personalizadas como manifestos de implementação do Kubernetes.Cloud de Confiance
Como funciona
O Início rápido da inferência oferece práticas recomendadas personalizadas com base nas referências internas exaustivas da Google do desempenho de réplica única para combinações de topologias de modelos, servidores de modelos e aceleradores. Estes testes de referência representam graficamente a latência em função da taxa de transferência, incluindo o tamanho da fila e as métricas da cache KV, que mapeiam as curvas de desempenho para cada combinação.
Como são geradas as práticas recomendadas personalizadas
Medimos a latência no tempo normalizado por token de saída (NTPOT) e no tempo até ao primeiro token (TTFT) em milissegundos, e a taxa de transferência em tokens de saída por segundo, saturando os aceleradores. Para saber mais acerca destas métricas de desempenho, consulte o artigo Acerca da inferência de modelos no GKE.
O seguinte exemplo de perfil de latência ilustra o ponto de inflexão em que o débito estabiliza (verde), o ponto pós-inflexão em que a latência piora (vermelho) e a zona ideal (azul) para um débito ideal no alvo de latência. O Início rápido da inferência fornece dados de desempenho e configurações para esta zona ideal.
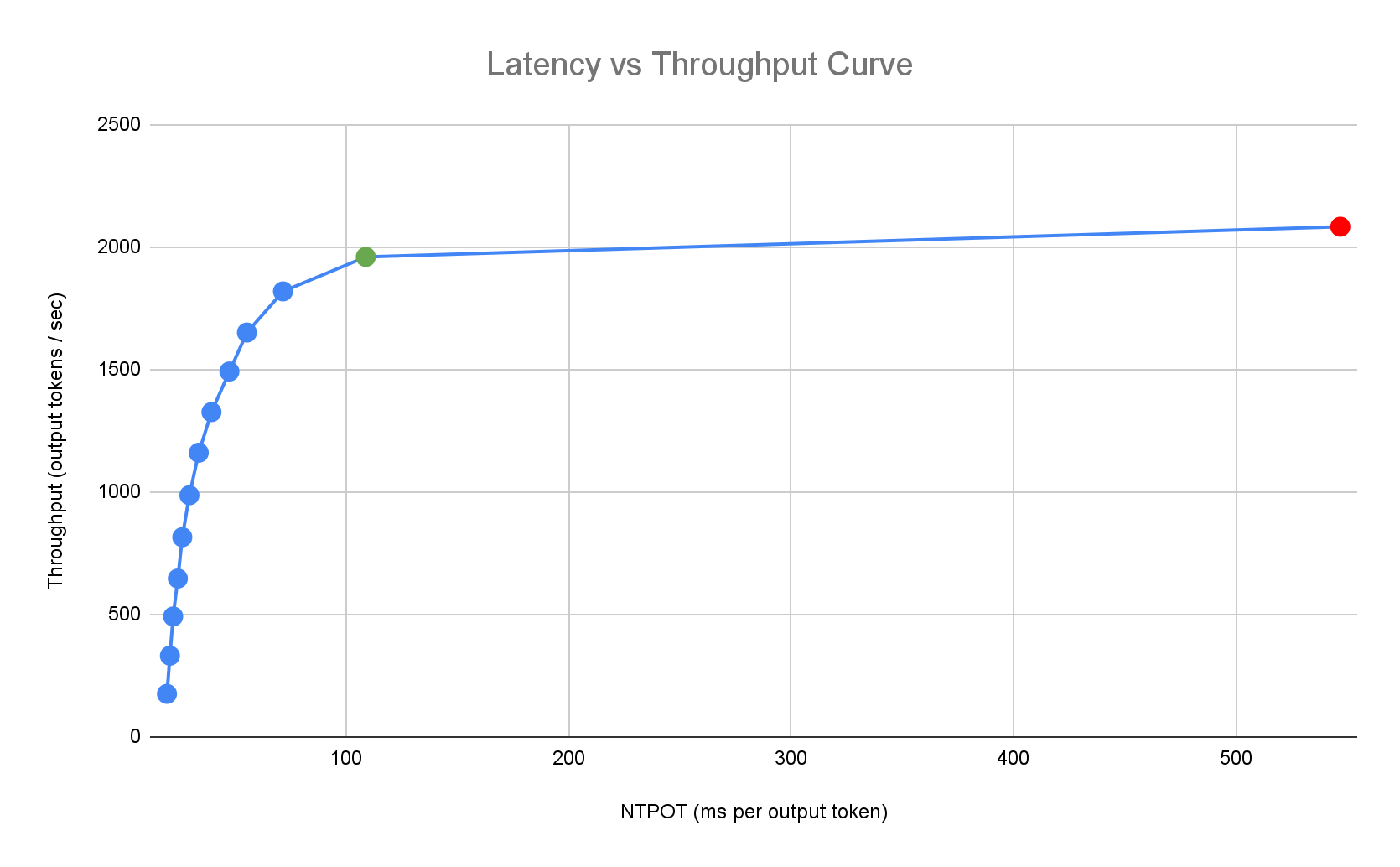
Com base nos requisitos de latência de uma aplicação de inferência, o Início rápido de inferência identifica combinações adequadas e determina o ponto de funcionamento ideal na curva de latência-débito. Este ponto define o limite do Horizontal Pod Autoscaler (HPA), com um buffer para ter em conta a latência de expansão. O limite geral também informa o número inicial de réplicas necessárias, embora o HPA ajuste dinamicamente este número com base na carga de trabalho.
Estimativa de custos
Para estimar os custos por token das suas VMs do acelerador, o Início rápido da inferência usa uma relação custo de saída/entrada configurável. Por exemplo, se esta proporção estiver definida como 4, assume-se que cada token de saída custa quatro vezes mais do que um token de entrada. As seguintes equações são usadas para calcular as métricas de custo por token:
\[ \$/\text{output token} = \frac{\text{GPU \$/s}}{(\frac{1}{\text{output-to-input-cost-ratio}} \cdot \text{input tokens/s} + \text{output tokens/s})} \]
onde
\[ \$/\text{input token} = \frac{\text{\$/output token}}{\text{output-to-input-cost-ratio}} \]
Testes de referência
As configurações e os dados de desempenho fornecidos baseiam-se em testes de referência que usam o conjunto de dados ShareGPT para enviar tráfego com a seguinte distribuição de entradas e saídas.
| Símbolos de entrada | Símbolos de saída | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mín. | Mediana | Média | P90 | P99 | Máx. | Mín. | Mediana | Média | P90 | P99 | Máx. |
| 4 | 108 | 226 | 635 | 887 | 1024 | 1 | 132 | 195 | 488 | 778 | 1024 |
Antes de começar
Antes de começar, certifique-se de que realizou as seguintes tarefas:
- Ative a API Google Kubernetes Engine. Ative a API Google Kubernetes Engine
- Se quiser usar a CLI gcloud para esta tarefa,
instale-a e, em seguida,
inicialize a
CLI gcloud. Se instalou anteriormente a CLI gcloud, execute o comando
gcloud components updatepara obter a versão mais recente. As versões anteriores da CLI gcloud podem não suportar a execução dos comandos neste documento.
Na Cloud de Confiance consola, na página do seletor de projetos, selecione ou crie um Cloud de Confiance by S3NS projeto.
Certifique-se de que a faturação está ativada para o seu Cloud de Confiance by S3NS projeto.
Certifique-se de que tem capacidade de acelerador suficiente para o seu projeto:
- Se usar GPUs: verifique a página Quotas.
- Se usar TPUs: consulte o artigo Garanta a quota para TPUs e outros recursos do GKE.
Prepare-se para usar a interface do utilizador de IA/ML do GKE
Se usar a Cloud de Confiance consola, também tem de criar um cluster do Autopilot, se ainda não tiver sido criado um no seu projeto. Siga as instruções em Crie um cluster do Autopilot.
Prepare-se para usar a interface de linhas de comando
Se usar a CLI gcloud para executar o Início rápido da inferência, também tem de executar estes comandos adicionais:
Ative a API
gkerecommender.googleapis.com:gcloud services enable gkerecommender.googleapis.comDefina o projeto de quota de faturação que usa para chamadas API:
gcloud config set billing/quota_project PROJECT_IDVerifique se a versão da CLI gcloud é, pelo menos, 536.0.1. Caso contrário, execute o seguinte:
gcloud components update
Limitações
Tenha em atenção as seguintes limitações antes de começar a usar o Início rápido da inferência:
- A implementação de modelos da consolaCloud de Confiance só suporta a implementação em clusters do Autopilot.
- O Início rápido da inferência não fornece perfis para todos os modelos suportados por um determinado servidor de modelos.
- Se não definir a variável de ambiente
HF_HOMEquando usar um manifesto gerado para um modelo grande (90 GiB ou mais) do Hugging Face, tem de usar um cluster com discos de arranque maiores do que os predefinidos ou modificar o manifesto para definirHF_HOMEcomo/dev/shm/hf_cache. Esta opção usa a RAM para a cache em vez do disco de arranque do nó. Para mais informações, consulte a secção Resolução de problemas. - O carregamento de modelos do Cloud Storage só suporta a implementação em clusters com o controlador CSI FUSE do Cloud Storage e a Workload Identity Federation para o GKE ativada, que estão ambos ativados por predefinição em clusters do Autopilot. Para mais detalhes, consulte o artigo Configure o controlador CSI FUSE do Cloud Storage para o GKE.
Analise e veja configurações otimizadas para a inferência de modelos
Esta secção descreve como explorar e analisar as recomendações de configuração através da CLI do Google Cloud.
Use o comando gcloud container ai profiles
para explorar e analisar perfis otimizados (combinações de modelo, servidor de modelos,
versão do servidor de modelos e aceleradores):
Modelos
Para explorar e selecionar um modelo, use a opção models.
gcloud container ai profiles models list
Perfis
Use o comando list
para explorar os perfis gerados e filtrá-los com base nos seus requisitos de
desempenho e custo. Por exemplo:
gcloud container ai profiles list \
--model=openai/gpt-oss-20b \
--pricing-model=on-demand \
--target-ttft-milliseconds=300
O resultado mostra os perfis suportados com métricas de desempenho, como débito, latência e custo por milhão de tokens no ponto de inflexão. Tem um aspeto semelhante ao seguinte:
Instance Type Accelerator Cost/M Input Tokens Cost/M Output Tokens Output Tokens/s NTPOT(ms) TTFT(ms) Model Server Model Server Version Model
a3-highgpu-1g nvidia-h100-80gb 0.009 0.035 13335 67 297 vllm gptoss openai/gpt-oss-20b
Os valores representam o desempenho observado no ponto em que o débito deixa de aumentar e a latência começa a aumentar drasticamente (ou seja, o ponto de inflexão ou saturação) para um determinado perfil com este tipo de acelerador. Para saber mais acerca destas métricas de desempenho, consulte o artigo Acerca da inferência de modelos no GKE.
Para ver a lista completa de flags que pode definir, consulte a documentação do comando list.
Todas as informações de preços estão disponíveis apenas na moeda USD e são predefinidas para a região us-east5, exceto para as configurações que usam máquinas A3, que são predefinidas para a região us-central1.
Referências
Para obter todos os dados de testes de referência de um perfil específico, use o comando
benchmarks list.
Por exemplo:
gcloud container ai profiles benchmarks list \
--model=deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--model-server=vllm
O resultado contém uma lista de métricas de desempenho de testes de referência executados a diferentes taxas de pedidos.
O comando apresenta o resultado no formato CSV. Para armazenar o resultado como um ficheiro, use o redirecionamento de saída. Por exemplo:
gcloud container ai profiles benchmarks list > profiles.csv.
Para ver a lista completa de flags que pode definir, consulte a documentação do comando benchmarks list.
Depois de escolher um modelo, um servidor de modelos, uma versão do servidor de modelos e um acelerador, pode avançar para a criação de um manifesto de implementação.
Implemente configurações recomendadas
Esta secção descreve como gerar e implementar recomendações de configuração através da Cloud de Confiance consola ou da linha de comandos.
Consola
- Na Cloud de Confiance consola, aceda à página de IA/ML do GKE.
- Clique em Implementar modelos.
Selecione um modelo que quer implementar. Os modelos suportados pelo Inference Quickstart são apresentados com a etiqueta Otimizado.
- Se selecionou um modelo base, é aberta uma página do modelo. Clique em Implementar. Ainda pode modificar a configuração antes da implementação real.
- É-lhe pedido que crie um cluster do Autopilot se não existir nenhum no seu projeto. Siga as instruções em Crie um cluster do Autopilot. Depois de criar o cluster, regresse à página de IA/ML do GKE na Cloud de Confiance consola para selecionar um modelo.
A página de implementação do modelo é pré-preenchida com o modelo selecionado, bem como com o servidor de modelos e o acelerador recomendados. Também pode configurar definições como a latência máxima e a origem do modelo.
(Opcional) Para ver o manifesto com a configuração recomendada, clique em Ver YAML.
Para implementar o manifesto com a configuração recomendada, clique em Implementar. A operação de implementação pode demorar vários minutos a ser concluída.
Para ver a sua implementação, aceda à página Kubernetes Engine > Cargas de trabalho.
gcloud
Prepare-se para carregar modelos a partir do seu registo de modelos: o início rápido da inferência suporta o carregamento de modelos a partir do Hugging Face ou do Cloud Storage.
Hugging Face
Se ainda não tiver um, gere um token de acesso da Hugging Face e um segredo do Kubernetes correspondente.
Para criar um segredo do Kubernetes que contenha o token do Hugging Face, execute o seguinte comando:
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=HUGGING_FACE_TOKEN \ --namespace=NAMESPACESubstitua os seguintes valores:
- HUGGING_FACE_TOKEN: o token da Hugging Face que criou anteriormente.
- NAMESPACE: o namespace do Kubernetes onde quer implementar o servidor de modelos.
Alguns modelos também podem exigir que aceite e assine o respetivo contrato de licença de consentimento.
Cloud Storage
Pode carregar modelos suportados do Cloud Storage com uma configuração do FUSE do Cloud Storage otimizada. Para tal, primeiro tem de carregar o modelo do Hugging Face para o seu contentor do Cloud Storage.
Pode implementar este trabalho do Kubernetes para transferir o modelo, alterando
MODEL_IDpara o modelo suportado do Início rápido de inferência.Gerar manifestos: tem estas opções para gerar manifestos:
- Configuração base: gera os manifestos padrão de implementação, serviço e monitorização de pods do Kubernetes para implementar um servidor de inferência de réplica única.
- (Opcional) Configuração otimizada para armazenamento: gera um manifesto com uma configuração do FUSE do Cloud Storage ajustada para carregar modelos a partir de um contentor do Cloud Storage. Ativa esta configuração através da flag
--model-bucket-uri. Uma configuração do FUSE do Cloud Storage otimizada pode melhorar o tempo de arranque do pod do MDG mais de 7 vezes. (Opcional) Configuração otimizada para a escala automática: gera um manifesto com um Horizontal Pod Autoscaler (HPA) para ajustar automaticamente o número de réplicas do servidor de modelos com base no tráfego. Ativa esta configuração especificando um objetivo de latência com flags como
--target-ntpot-milliseconds.
Configuração base
No terminal, use a opção
manifestspara gerar manifestos de implementação, serviço e PodMonitoring:gcloud container ai profiles manifests createUse os parâmetros obrigatórios
--model,--model-servere--accelerator-typepara personalizar o manifesto.Opcionalmente, pode definir estes parâmetros:
--target-ntpot-milliseconds: defina este parâmetro para especificar o limite do HPA. Este parâmetro permite-lhe definir um limite de dimensionamento para manter a latência do tempo normalizado por token de saída (NTPOT) P50, que é medida no 50.º percentil, abaixo do valor especificado. Escolha um valor acima da latência mínima do acelerador. O HPA está configurado para o débito máximo se especificar um valor NTPOT acima da latência máxima do acelerador. Por exemplo:gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --model-server=vllm \ --model-server-version=v0.7.2 \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=200--target-ttft-milliseconds: filtra os perfis que excedem o objetivo de latência TTFT.--output-path: se especificado, o resultado é guardado no caminho indicado, em vez de ser impresso no terminal, para que possa editar o resultado antes de o implementar. Por exemplo, pode usar esta opção com a opção--output=manifestse quiser guardar o manifesto num ficheiro YAML. Por exemplo:gcloud container ai profiles manifests create \ --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \ --model-server vllm \ --accelerator-type=nvidia-tesla-a100 \ --output=manifest \ --output-path /tmp/manifests.yaml
Para ver a lista completa de flags que pode definir, consulte a documentação de comandos
manifests create.Otimizada para armazenamento
Pode melhorar o tempo de arranque do pod carregando modelos do Cloud Storage através de uma configuração do Cloud Storage FUSE otimizada. O carregamento do Google Cloud Storage requer as versões 1.29.6-gke.1254000, 1.30.2-gke.1394000 ou posteriores do GKE
Para o fazer, siga estes passos:
- Carregue o modelo do repositório do Hugging Face para o seu contentor do Cloud Storage.
Defina a flag
--model-bucket-uriquando gerar o manifesto. Isto configura o modelo para carregar a partir de um contentor do Cloud Storage através do controlador CSI do FUSE do Cloud Storage. O URI tem de apontar para o caminho que contém o ficheiroconfig.jsone as ponderações do modelo. Pode especificar um caminho para um diretório no contentor anexando-o ao URI do contentor.Por exemplo:
gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --model-server=vllm \ --accelerator-type=nvidia-l4 \ --model-bucket-uri=gs://BUCKET_NAME \ --output-path=manifests.yamlSubstitua
BUCKET_NAMEpelo nome do seu contentor do Cloud Storage.Antes de aplicar o manifesto, tem de executar o comando
gcloud storage buckets add-iam-policy-bindingencontrado nos comentários do manifesto. Este comando é necessário para conceder autorização à conta de serviço do GKE para aceder ao contentor do Cloud Storage através da Workload Identity Federation para o GKE.Se pretender dimensionar a sua implementação para mais do que uma réplica, tem de escolher uma das seguintes opções para evitar erros de escrita concorrentes no caminho da cache XLA (
VLLM_XLA_CACHE_PATH):- Opção 1 (recomendada): primeiro, ajuste a escala da implementação para 1 réplica. Aguarde que o pod fique pronto, o que lhe permite escrever na cache XLA. Em seguida, aumente a escala até ao número de réplicas pretendido. As réplicas subsequentes vão ler a partir da cache preenchida sem conflitos de escrita.
- Opção 2: remova completamente a variável de ambiente
VLLM_XLA_CACHE_PATHdo manifesto. Esta abordagem é mais simples, mas desativa o armazenamento em cache para todas as réplicas.
Nos tipos de aceleradores de TPU, este caminho da cache é usado para armazenar a cache de compilação XLA, que acelera a preparação do modelo para implementações repetidas.
Para mais sugestões sobre como melhorar o desempenho, consulte o artigo Otimize o controlador CSI FUSE do Cloud Storage para o desempenho do GKE.
Otimizado para a escala automática
Pode configurar o Horizontal Pod Autoscaler (HPA) para ajustar automaticamente o número de réplicas do servidor de modelos com base na carga. Isto ajuda os servidores de modelos a processar de forma eficiente cargas variáveis, aumentando ou diminuindo a escala conforme necessário. A configuração do HPA segue as práticas recomendadas de dimensionamento automático para os guias de GPUs e TPUs.
Para incluir configurações de HPA ao gerar manifestos, use um ou ambos os flags
--target-ntpot-millisecondse--target-ttft-milliseconds. Estes parâmetros definem um limite de escalabilidade para o HPA manter a latência do P50 para o NTPOT ou o TTFT abaixo do valor especificado. Se definir apenas um destes indicadores, apenas essa métrica é tida em conta para o dimensionamento.Escolha um valor acima da latência mínima do seu acelerador. O HPA está configurado para o débito máximo se especificar um valor acima da latência máxima do acelerador.
Por exemplo:
gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=250Crie um cluster: pode publicar o seu modelo em clusters do GKE Autopilot ou Standard. Recomendamos que use um cluster do Autopilot para uma experiência do Kubernetes totalmente gerida. Para escolher o modo de funcionamento do GKE mais adequado às suas cargas de trabalho, consulte o artigo Escolha um modo de funcionamento do GKE.
Se não tiver um cluster existente, siga estes passos:
Piloto automático
Siga estas instruções para criar um cluster do Autopilot. O GKE processa o aprovisionamento dos nós com capacidade de GPU ou TPU com base nos manifestos de implementação, se tiver a quota necessária no seu projeto.
Standard
- Crie um cluster zonal ou regional.
Crie um node pool com os aceleradores adequados. Siga estes passos com base no tipo de acelerador escolhido:
- GPUs: primeiro, verifique a página Quotas na Cloud de Confiance consola para garantir que tem capacidade de GPU suficiente. Em seguida, siga as instruções em Crie um conjunto de nós de GPU.
- TPUs: primeiro, certifique-se de que tem TPUs suficientes seguindo as instruções em Certifique-se de que tem quota para TPUs e outros recursos do GKE. Em seguida, avance para Criar um node pool de TPU.
(Opcional, mas recomendado) Ative as funcionalidades de observabilidade: na secção de comentários do manifesto gerado, são fornecidos comandos adicionais para ativar as funcionalidades de observabilidade sugeridas. A ativação destas funcionalidades fornece mais estatísticas para ajudar a monitorizar o desempenho e o estado das cargas de trabalho e da infraestrutura subjacente.
Segue-se um exemplo de um comando para ativar as funcionalidades de observabilidade:
gcloud container clusters update $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$LOCATION \ --enable-managed-prometheus \ --logging=SYSTEM,WORKLOAD \ --monitoring=SYSTEM,DEPLOYMENT,HPA,POD,DCGM \ --auto-monitoring-scope=ALLPara mais informações, consulte o artigo Monitorize as suas cargas de trabalho de inferência.
(Apenas HPA) Implemente um adaptador de métricas: é necessário um adaptador de métricas, como o adaptador do Stackdriver de métricas personalizadas, se os recursos do HPA tiverem sido gerados nos manifestos de implementação. O adaptador de métricas permite que o HPA aceda às métricas do servidor do modelo que usam a API de métricas externas do kube. Para implementar o adaptador, consulte a documentação do adaptador no GitHub.
Implemente os manifestos: execute o comando
kubectl applye transmita o ficheiro YAML para os seus manifestos. Por exemplo:kubectl apply -f ./manifests.yaml
Teste os seus pontos finais de implementação
Se implementou o manifesto, o serviço implementado é exposto no seguinte ponto final:
http://model-model_server-service:8000/
Normalmente, o servidor de modelos, como o vLLM, escuta na porta 8000.
Para testar a implementação, tem de configurar o encaminhamento de porta. Execute o seguinte comando num terminal separado:
kubectl port-forward service/model-model_server-service 8000:8000
Para ver exemplos de como criar e enviar um pedido para o seu ponto final, consulte a documentação do vLLM.
Controlo de versões do manifesto
O Início rápido da inferência fornece os manifestos mais recentes que foram validados em versões recentes do cluster do GKE. O manifesto devolvido para um perfil pode mudar ao longo do tempo para que receba uma configuração otimizada na implementação. Se precisar de um manifesto estável, guarde-o e armazene-o separadamente.
O manifesto inclui comentários e uma anotação recommender.ai.gke.io/version no seguinte formato:
# Generated on DATE using:
# GKE cluster CLUSTER_VERSION
# GPU_DRIVER_VERSION GPU driver for node version NODE_VERSION
# Model server MODEL_SERVER MODEL_SERVER_VERSION
A anotação anterior tem os seguintes valores:
- DATE: a data em que o manifesto foi gerado.
- CLUSTER_VERSION: a versão do cluster do GKE usada para validação.
- NODE_VERSION: a versão do nó do GKE usada para validação.
- GPU_DRIVER_VERSION: (Apenas GPU) a versão do controlador da GPU usada para validação.
- MODEL_SERVER: o servidor de modelos usado no manifesto.
- MODEL_SERVER_VERSION: a versão do servidor de modelos usada no manifesto.
Monitorize as suas cargas de trabalho de inferência
Para monitorizar as cargas de trabalho de inferência implementadas, aceda ao Explorador de métricas na Cloud de Confiance consola.
Ative a monitorização automática
O GKE inclui uma funcionalidade de monitorização automática que faz parte das funcionalidades de observabilidade mais amplas. Esta funcionalidade procura no cluster cargas de trabalho que são executadas em servidores de modelos suportados e implementa os recursos PodMonitoring que permitem que estas métricas de cargas de trabalho sejam visíveis no Cloud Monitoring. Para mais informações sobre a ativação e a configuração da monitorização automática, consulte o artigo Configure a monitorização automática de aplicações para cargas de trabalho.
Depois de ativar a funcionalidade, o GKE instala painéis de controlo pré-criados para monitorizar aplicações para cargas de trabalho suportadas.
Se implementar a partir da página de IA/ML do GKE na Cloud de Confiance consola,
os recursos PodMonitoring e HPA são criados automaticamente para si através da configuração targetNtpot.
Resolução de problemas
- Se definir a latência como demasiado baixa, o Início rápido da inferência pode não gerar uma recomendação. Para corrigir este problema, selecione um alvo de latência entre a latência mínima e máxima observada para os aceleradores selecionados.
- O Início rápido da inferência existe independentemente dos componentes do GKE, pelo que a versão do cluster não é diretamente relevante para usar o serviço. No entanto, recomendamos que use um cluster novo ou atualizado para evitar discrepâncias no desempenho.
- Se receber um erro
PERMISSION_DENIEDpara comandosgkerecommender.googleapis.comque indica que falta um projeto de quota, tem de o definir manualmente. Executegcloud config set billing/quota_project PROJECT_IDpara corrigir o problema.
O pod foi removido devido ao armazenamento efémero insuficiente
Quando implementa um modelo grande (90 GiB ou mais) do Hugging Face, o seu pod pode ser removido com uma mensagem de erro semelhante a esta:
Fails because inference server consumes too much ephemeral storage, and gets evicted low resources: Warning Evicted 3m24s kubelet The node was low on resource: ephemeral-storage. Threshold quantity: 10120387530, available: 303108Ki. Container inference-server was using 92343412Ki, request is 0, has larger consumption of ephemeral-storage..,
Este erro ocorre porque o modelo está em cache no disco de arranque do nó, uma forma de armazenamento efémero. O disco de arranque é usado para armazenamento efémero quando o manifesto de implementação não define a variável de ambiente HF_HOME para um diretório na RAM do nó.
- Por predefinição, os nós do GKE têm um disco de arranque de 100 GiB.
- O GKE reserva 10% do disco de arranque para sobrecarga do sistema, deixando 90 GiB para as suas cargas de trabalho.
- Se o tamanho do modelo for de 90 GiB ou superior e for executado num disco de arranque de tamanho predefinido, o kubelet despeja o pod para libertar armazenamento efémero.
Para resolver este problema, escolha uma das seguintes opções:
- Use a RAM para o armazenamento em cache de modelos: no manifesto de implementação, defina a variável de ambiente
HF_HOMEcomo/dev/shm/hf_cache. Isto usa a RAM do nó para colocar o modelo em cache em vez do disco de arranque. - Aumente o tamanho do disco de arranque:
- GKE Standard: aumente o tamanho do disco de arranque quando criar um cluster, criar um conjunto de nós ou atualizar um conjunto de nós.
- Autopilot: para pedir um disco de arranque maior, crie uma classe de computação personalizada e defina o campo
bootDiskSizena regramachineType.
O pod entra num ciclo de falhas ao carregar modelos do Cloud Storage
Depois de implementar um manifesto gerado com a flag --model-bucket-uri, a implementação pode ficar bloqueada e o pod entra num estado CrashLoopBackOff.
A verificação dos registos do contentor inference-server pode mostrar um erro
enganador, como huggingface_hub.errors.HFValidationError. Por exemplo:
huggingface_hub.errors.HFValidationError: Repo id must use alphanumeric chars or '-', '_', '.', '--' and '..' are forbidden, '-' and '.' cannot start or end the name, max length is 96: '/data'.
Normalmente, este erro ocorre quando o caminho do Cloud Storage fornecido na flag --model-bucket-uri está incorreto. O servidor de inferência, como o vLLM, não consegue encontrar os ficheiros de modelo necessários (como config.json) no caminho montado.
Quando não consegue encontrar os ficheiros locais, o servidor volta a assumir que o caminho é um ID do repositório do Hugging Face Hub. Uma vez que o caminho não é um ID do repositório válido, o servidor falha com um erro de validação e entra num ciclo de falhas.
Para resolver este problema, verifique se o caminho que indicou para a flag --model-bucket-uri
aponta para o diretório exato no seu contentor do Cloud Storage que
contém o ficheiro config.json do modelo e todos os pesos do modelo associados.
O que se segue?
- Visite o portal de orquestração de IA/aprendizagem automática no GKE para explorar os nossos guias, tutoriais e exemplos de utilização oficiais para executar cargas de trabalho de IA/aprendizagem automática no GKE.
- Para mais informações sobre a otimização da publicação de modelos, consulte o artigo Práticas recomendadas para otimizar a inferência de modelos de linguagem (conteúdo extenso) com GPUs. Abrange as práticas recomendadas para o serviço de MDIs com GPUs no GKE, como a quantização, o paralelismo de tensores e a gestão de memória.
- Para mais informações sobre as práticas recomendadas para o dimensionamento automático, consulte estes guias:
- Para obter informações sobre as práticas recomendadas de armazenamento, consulte o artigo Otimize o controlador CSI FUSE do Cloud Storage para o desempenho do GKE.
- Explore exemplos experimentais para tirar partido do GKE e acelerar as suas iniciativas de IA/ML no GKE AI Labs.