
本頁說明可用於監控 Google Kubernetes Engine (GKE) 工作負載啟動延遲時間和基礎叢集節點的指標和資訊主頁。您可以使用這些指標追蹤、排解及縮短啟動延遲時間。
本頁面適用於需要監控及最佳化工作負載啟動延遲的平台管理員和運算子。如要進一步瞭解 Cloud de Confiance by S3NS 內容中提及的常見角色,請參閱「常見的 GKE 使用者角色和工作」。
總覽
啟動延遲時間會顯著影響應用程式對流量尖峰的回應方式、副本從中斷狀態復原的速度,以及叢集和工作負載的作業成本效率。監控工作負載的啟動延遲時間,有助於偵測延遲時間是否變長,並追蹤工作負載和基礎架構更新對啟動延遲時間的影響。
最佳化工作負載啟動延遲情形有下列優點:
- 在流量高峰期間,降低服務對使用者的回應延遲時間。
- 減少吸收需求尖峰所需的過多服務容量,同時建立新的副本。
- 減少已部署資源的閒置時間,這些資源會在批次運算期間等待其餘資源啟動。
事前準備
開始之前,請確認您已完成下列工作:
- 啟用 Google Kubernetes Engine API。 啟用 Google Kubernetes Engine API
- 如要使用 Google Cloud CLI 執行這項工作,請安裝並初始化 gcloud CLI。如果您先前已安裝 gcloud CLI,請執行
gcloud components update指令,取得最新版本。較舊的 gcloud CLI 版本可能不支援執行本文件中的指令。
啟用 Cloud Logging 和 Cloud Monitoring API。
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
需求條件
如要查看工作負載啟動延遲時間的指標和資訊主頁,GKE 叢集必須符合下列條件:
- 您必須使用 GKE 1.31.1-gke.1678000 以上版本。
- 您必須設定系統指標的收集作業。
- 您必須設定系統記錄的收集作業。
- 在叢集上啟用
POD元件的 kube 狀態指標,即可查看 Pod 和容器指標。
必要角色和權限
如要取得啟用記錄檔產生功能,以及存取和處理記錄檔所需的權限,請要求管理員授予下列 IAM 角色:
-
查看 GKE 叢集、節點和工作負載:
專案的 Kubernetes Engine 檢視者 (
roles/container.viewer) -
存取啟動延遲指標並查看資訊主頁:
監控檢視者 (
roles/monitoring.viewer) 專案 -
存取含有延遲資訊的記錄檔 (例如 Kubelet 映像檔提取事件),並在記錄檔探索工具和記錄檔分析中查看:
專案中的記錄檢視器 (
roles/logging.viewer)
如要進一步瞭解如何授予角色,請參閱「管理專案、資料夾和機構的存取權」。
啟動延遲指標
啟動延遲指標包含在 GKE 系統指標中,並匯出至與 GKE 叢集相同的專案中的 Cloud Monitoring。
這個表格中的 Cloud Monitoring 指標名稱必須加上 kubernetes.io/ 前置字元。表格中的項目已省略該前置字串。
| 指標類型 (資源階層層級) 顯示名稱 |
|
|---|---|
|
種類、類型、單位
受監控資源 |
說明 標籤 |
pod/latencies/pod_first_ready
(專案)
Pod 首次就緒延遲 |
|
GAUGE、Double、s
k8s_pod |
Pod 端對端啟動延遲 (從 Pod Created 到 Ready),包括映像檔提取作業。每 60 秒取樣一次。 |
node/latencies/startup
(project)
節點啟動延遲 |
|
GAUGE、INT64、s
k8s_node |
節點的總啟動延遲時間,從 GCE 執行個體的 CreationTimestamp 到首次 Kubernetes node ready。每 60 秒取樣一次。accelerator_family:根據硬體加速器分類的節點:gpu、tpu、cpu。
kube_control_plane_available:KCP (kube 控制層) 可用時,是否收到節點建立要求。
|
autoscaler/latencies/per_hpa_recommendation_scale_latency_seconds
(專案)
每個 HPA 建議的資源調度延遲時間 |
|
GAUGE、DOUBLE、s
k8s_scale |
水平 Pod 自動調度資源 (HPA) 資源調度建議延遲時間 (從建立指標開始,到將相應的資源調度建議套用至 API 伺服器的時間),適用於 HPA 目標。取樣頻率為每 60 秒一次。取樣完畢後,最多會有 20 秒無法查看資料。metric_type:指標來源類型。應為 "ContainerResource"、"External"、"Object"、"Pods" 或 "Resource"。
|
查看工作負載的啟動延遲時間資訊主頁
工作負載的「啟動延遲」資訊主頁僅適用於部署作業。如要查看 Deployment 的啟動延遲時間指標,請在 Cloud de Confiance 控制台中執行下列步驟:
前往「Workloads」(工作負載) 頁面。
如要開啟「Deployment details」(部署作業詳細資料) 檢視畫面,請按一下要檢查的工作負載名稱。
點選「Observability」(觀測能力) 分頁標籤。
選取左選單中的「啟動延遲」。
查看 Pod 的啟動延遲分布
Pod 的啟動延遲是指總啟動延遲,包括映像檔提取,測量時間從 Pod 的 Created 狀態到 Ready 狀態。您可以使用下列兩張圖表評估 Pod 的啟動延遲時間:
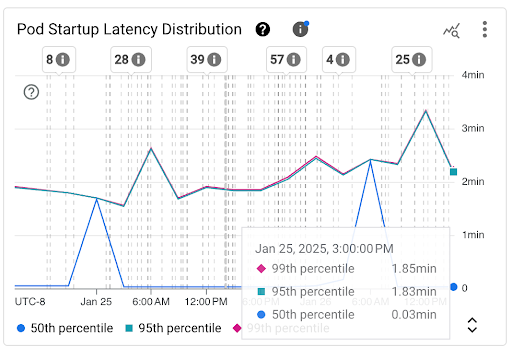
「Pod 啟動延遲時間分布」圖表:這個圖表會顯示 Pod 的啟動延遲時間百分位數 (第 50 個百分位數、第 95 個百分位數和第 99 個百分位數),這些百分位數是根據固定 3 小時時間間隔 (例如凌晨 12:00 至凌晨 3:00,以及凌晨 3:00 至凌晨 6:00) 內觀察到的 Pod 啟動事件計算而得。您可以透過這個圖表達成下列目的:
- 瞭解 Pod 啟動延遲基準。
- 找出 Pod 啟動延遲時間的變化趨勢。
- 找出 Pod 啟動延遲時間的變化與近期事件 (例如工作負載部署或叢集自動配置器事件) 之間的關聯性。您可以在資訊主頁頂端的「註解」清單中選取事件。
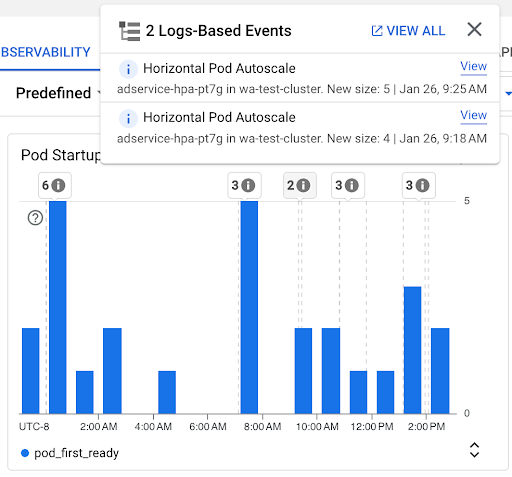
Pod 啟動次數圖表:這個圖表顯示所選時間間隔內啟動的 Pod 數量。您可以使用這張圖表達成下列目的:
- 瞭解用於計算特定時間間隔內 Pod 啟動延遲時間分布百分位數的 Pod 樣本大小。
- 瞭解 Pod 啟動的原因,例如工作負載部署或水平 Pod 自動調度事件。您可以在資訊主頁頂端的「註解」清單中選取事件。
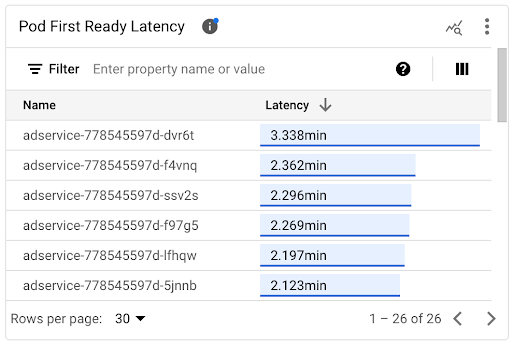
查看個別 Pod 的啟動延遲時間
您可以在「Pod First Ready Latency」(Pod 首次就緒延遲)時間軸圖表和相關聯的清單中,查看個別 Pod 的啟動延遲。
- 使用「Pod 首次就緒延遲」時間軸圖表,找出個別 Pod 啟動與近期事件 (例如水平 Pod 自動配置器或叢集自動配置器事件) 之間的關聯。您可以在資訊主頁頂端的「註解」清單中選取這些事件。這張圖表可協助您找出啟動延遲時間與其他 Pod 相比出現變化的潛在原因。
- 使用「Pod First Ready Latency」(Pod 首次就緒延遲時間) 清單,找出啟動時間最長或最短的個別 Pod。您可以依「延遲時間」欄排序清單。找出啟動延遲時間最長的 Pod 後,您可以將 Pod 啟動事件與其他近期事件建立關聯,排解延遲時間變長的問題。
如要瞭解個別 Pod 的建立時間,請查看對應 Pod 建立事件中 timestamp 欄位的值。如要查看 timestamp 欄位,請在記錄檔探索工具中執行下列查詢:
log_id("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="io.k8s.core.v1.pods.create" AND
resource.labels.project_id=PROJECT_ID AND
resource.labels.cluster_name=CLUSTER_NAME AND
resource.labels.location=CLUSTER_LOCATION AND
protoPayload.response.metadata.namespace=NAMESPACE AND
protoPayload.response.metadata.name=POD_NAME
如要列出工作負載的所有 Pod 建立事件,請在上述查詢中使用下列篩選器:protoPayload.response.metadata.name=~"POD_NAME_PREFIX-[a-f0-9]{7,10}-[a-z0-9]{5}"
比較個別 Pod 的延遲時間時,您可以測試各種設定對 Pod 啟動延遲時間的影響,並根據需求找出最佳設定。
判斷 Pod 排程延遲時間
Pod 排程延遲時間是指 Pod 建立到排定至節點之間的時間長度。Pod 排程延遲時間會影響 Pod 的端對端啟動時間,計算方式是將 Pod 排程事件的時間戳記減去 Pod 建立要求的時間戳記。
您可以在對應的 Pod 排程事件中,從 jsonPayload.eventTime 欄位找到個別 Pod 排程事件的時間戳記。如要查看 jsonPayload.eventTime 欄位,請在記錄檔探索工具中執行下列查詢:
log_id("events")
jsonPayload.reason="Scheduled"
resource.type="k8s_pod"
resource.labels.project_id=PROJECT_ID
resource.labels.location=CLUSTER_LOCATION
resource.labels.cluster_name=CLUSTER_NAME
resource.labels.namespace_name=NAMESPACE
resource.labels.pod_name=POD_NAME
如要列出工作負載的所有 Pod 排程事件,請在上述查詢中使用下列篩選器:resource.labels.pod_name=~"POD_NAME_PREFIX-[a-f0-9]{7,10}-[a-z0-9]{5}"
查看映像檔提取延遲
如果節點上尚未提供映像檔,或需要重新整理映像檔,容器映像檔提取延遲就會導致 Pod 啟動延遲。最佳化映像檔提取延遲時間後,叢集擴充事件期間的工作負載啟動延遲時間就會縮短。
您可以查看「Kubelet 映像檔提取事件」表格,瞭解工作負載容器映像檔的提取時間,以及提取程序耗費的時間。
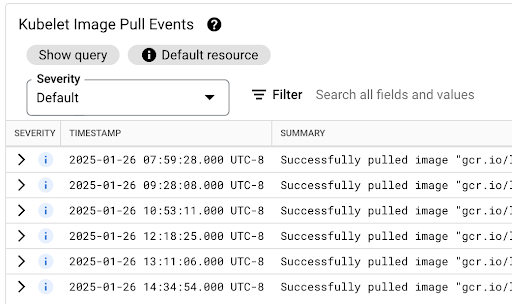
圖片提取延遲時間會顯示在 jsonPayload.message 欄位中,其中包含類似下列內容的訊息:
"Successfully pulled image "gcr.io/example-project/image-name" in 17.093s (33.051s including waiting). Image size: 206980012 bytes."
查看 HPA 資源調度建議的延遲分布
HPA 目標的水平 Pod 自動調度資源 (HPA) 資源調度建議延遲時間,是指從建立指標開始,到將相應的資源調度建議套用至 API 伺服器的時間。最佳化 HPA 資源調度建議延遲時間,可縮短擴充事件期間的工作負載啟動延遲時間。
您可以在下列兩張圖表中查看 HPA 資源調度:
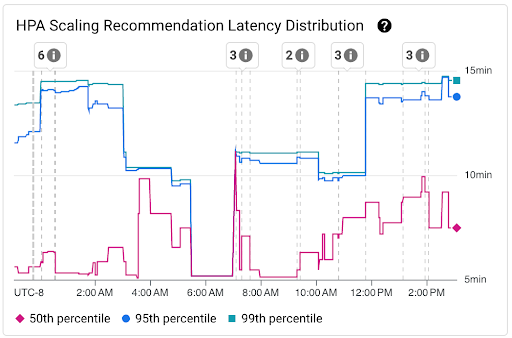
「HPA 資源調度建議延遲分布」圖表:這張圖表會顯示 HPA 資源調度建議延遲的百分位數 (第 50 個百分位數、第 95 個百分位數和第 99 個百分位數),這些百分位數是根據過去 3 小時時間間隔內觀察到的 HPA 資源調度建議計算而得。您可以使用這張圖表執行下列操作:
- 瞭解 HPA 資源調度建議延遲時間基準。
- 找出 HPA 資源調度建議延遲時間的變化趨勢。
- 找出 HPA 資源調度建議延遲時間變化與近期事件之間的關聯。 您可以在資訊主頁頂端的「註解」清單中選取事件。
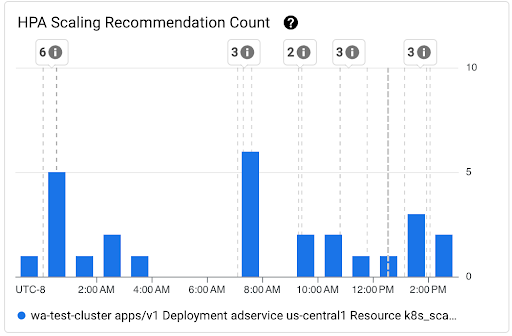
「HPA 資源調度建議數量」圖表:這個圖表會顯示所選時間間隔內觀察到的 HPA 資源調度建議數量。您可以使用圖表執行下列工作:
- 瞭解 HPA 資源調度建議的樣本大小。系統會使用這些樣本,計算特定時間間隔內 HPA 資源調度建議延遲時間分布的百分位數。
- 找出 HPA 資源調度建議與新 Pod 啟動事件和水平 Pod 自動調度資源事件之間的關聯。您可以在資訊主頁頂端的「註解」清單中選取事件。
查看 Pod 的排程問題
Pod 排程問題可能會影響工作負載的端對端啟動延遲時間。如要縮短工作負載的端對端啟動延遲時間,請排解並減少這類問題的數量。
以下是可用於追蹤這類問題的兩張圖表:
- 「無法排程/待處理/失敗的 Pod」圖表會顯示一段時間內無法排程、待處理和失敗的 Pod 數量。
- 「輪詢/等待中/完備性檢查失敗的容器」圖表會顯示一段時間內處於這些狀態的容器數量。
查看節點的啟動延遲時間資訊主頁
如要查看節點的啟動延遲指標,請在Cloud de Confiance 控制台中執行下列步驟:
前往「Kubernetes Clusters」(Kubernetes 叢集) 頁面。
如要開啟「叢集詳細資料」檢視畫面,請按一下要檢查的叢集名稱。
點選「Observability」(觀測能力) 分頁標籤。
選取左側選單中的「啟動延遲」。
查看節點啟動延遲分布
節點的啟動延遲是指總啟動延遲,也就是從節點的 CreationTimestamp 到 Kubernetes node ready 狀態所測量的時間。您可以在下列兩個圖表中查看節點啟動延遲:
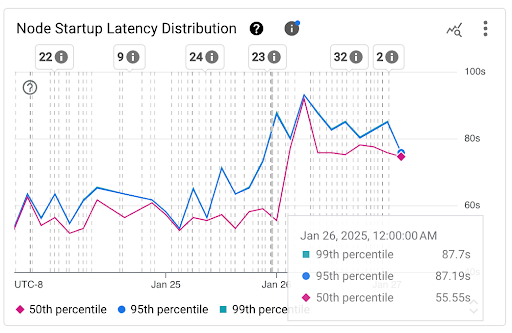
節點啟動延遲時間分布圖表:這張圖表會顯示節點啟動延遲時間的百分位數 (第 50、95 和 99 個百分位數),這些資料是根據固定 3 小時時間間隔 (例如凌晨 12:00 至凌晨 3:00,以及凌晨 3:00 至上午 6:00) 內觀察到的節點啟動事件計算而得。您可以透過這張圖表達成下列目的:
- 瞭解基準節點啟動延遲時間。
- 找出節點啟動延遲時間的變化趨勢。
- 找出節點啟動延遲時間的變化與近期事件之間的關聯,例如叢集更新或節點集區更新。您可以在資訊主頁頂端的「註解」清單中選取事件。
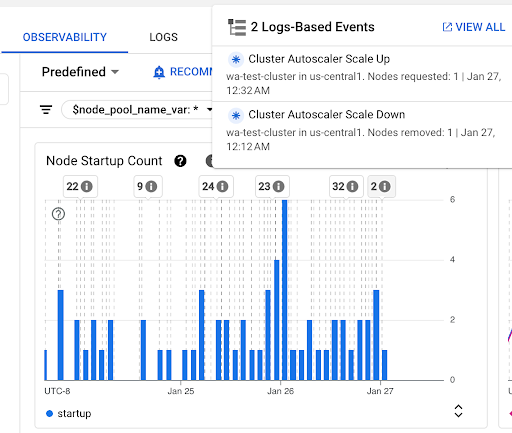
節點啟動次數圖表:這個圖表顯示所選時間間隔內啟動的節點數。您可以將圖表用於下列用途:
- 瞭解節點樣本大小,用於計算指定時間間隔的節點啟動延遲時間分布百分位數。
- 瞭解節點啟動的原因,例如節點集區更新或叢集自動配置器事件。您可以選取資訊主頁頂端的「註解」清單中的事件。
查看個別節點的啟動延遲時間
比較個別節點的延遲時間時,您可以測試各種節點設定對節點啟動延遲時間的影響,並根據需求找出最佳設定。您可以在「節點啟動延遲」時間軸圖表和相關聯的清單中,查看個別節點的啟動延遲。
您可以使用「節點啟動延遲」時間軸圖表,找出個別節點啟動與近期事件 (例如叢集更新或節點集區更新) 之間的關聯。您可以找出與其他節點相比,啟動延遲時間發生變化的潛在原因。您可以選取資訊主頁頂端「註解」清單中的事件。
您可以查看「節點啟動延遲時間」清單,找出啟動時間最長或最短的個別節點。您可以依「延遲時間」欄排序清單。找出啟動延遲時間最長的節點後,您可以將節點啟動事件與其他近期事件建立關聯,排解延遲時間變長的問題。
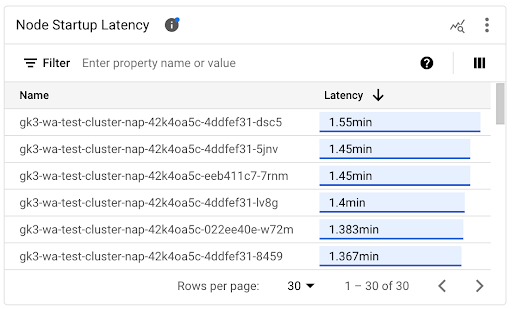
如要瞭解個別節點的建立時間,請查看對應節點建立事件中 protoPayload.metadata.creationTimestamp 欄位的值。如要查看 protoPayload.metadata.creationTimestamp 欄位,請在記錄檔探索工具中執行下列查詢:
log_id("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="io.k8s.core.v1.nodes.create" AND
resource.labels.project_id=PROJECT_ID AND
resource.labels.cluster_name=CLUSTER_NAME AND
resource.labels.location=CLUSTER_LOCATION AND
protoPayload.response.metadata.name=NODE_NAME
查看節點集區的啟動延遲
如果節點集區的設定不同 (例如執行不同的工作負載),您可能需要分別監控各節點集區的節點啟動延遲時間。比較節點集區的節點啟動延遲時間,有助於瞭解節點設定對節點啟動延遲時間的影響,進而最佳化延遲時間。
根據預設,「節點啟動延遲時間」資訊主頁會顯示叢集內所有節點集區的匯總啟動延遲時間分布,以及個別節點的啟動延遲時間。如要查看特定節點集區的節點啟動延遲時間,請使用資訊主頁頂端的 $node_pool_name_var 篩選器,選取節點集區的名稱。
後續步驟
- 瞭解如何根據指標調整 Pod 自動調度資源功能。
- 進一步瞭解如何在 GKE 上縮短冷啟動延遲時間。
- 瞭解如何使用映像檔串流縮短映像檔提取延遲時間。
- 瞭解水平 Pod 自動調度資源調整的驚人經濟效益。
- 使用自動應用程式監控功能監控工作負載。