
GKE Standard 클러스터에서만 데이터 캐시를 사용할 수 있습니다. 이 가이드에서는 새 GKE Standard 클러스터 또는 노드 풀을 만들 때 GKE 데이터 캐시를 사용 설정하고 데이터 캐시 가속을 사용하여 GKE 연결 디스크를 프로비저닝하는 방법을 설명합니다.
GKE 데이터 캐시 정보
GKE 데이터 캐시를 사용하면 GKE 노드에서 로컬 SSD를 Persistent Disk 또는 Hyperdisk와 같은 영구 스토리지의 캐시 레이어로 사용할 수 있습니다. 로컬 SSD를 사용하면 디스크 읽기 지연 시간이 줄어들고 스테이트풀(Stateful) 워크로드의 초당 쿼리 수 (QPS)가 증가하는 동시에 메모리 요구사항이 최소화됩니다. GKE 데이터 캐시는 모든 유형의 Persistent Disk 또는 Hyperdisk를 백업 디스크로 지원합니다.
애플리케이션에 GKE 데이터 캐시를 사용하려면 연결된 로컬 SSD를 사용하여 GKE 노드 풀을 구성합니다. GKE 데이터 캐시에서 연결된 로컬 SSD의 전부 또는 일부를 사용하도록 구성할 수 있습니다. GKE 데이터 캐시 솔루션에서 사용하는 로컬 SSD는 표준 Cloud de Confiance by S3NS 암호화를 사용하여 저장 데이터를 암호화합니다.
이점
GKE 데이터 캐시는 다음과 같은 이점을 제공합니다.
- MySQL 또는 Postgres와 같은 기존 데이터베이스 및 벡터 데이터베이스의 초당 쿼리 처리 속도가 빨라졌습니다.
- 디스크 지연 시간을 최소화하여 스테이트풀(Stateful) 애플리케이션의 읽기 성능이 향상되었습니다.
- SSD가 노드에 로컬이므로 데이터 하이드레이션 및 재하이드레이션이 더 빠릅니다. 데이터 하이드레이션은 영구 스토리지에서 로컬 SSD로 필요한 데이터를 로드하는 초기 프로세스를 의미합니다. 데이터 재하이드레이션은 노드가 재활용된 후 로컬 SSD의 데이터를 복원하는 프로세스를 의미합니다.
배포 아키텍처
다음 다이어그램에서는 각각 앱을 실행하는 포드 2개가 있는 GKE 데이터 캐시 구성의 예시를 보여줍니다. 포드는 같은 GKE 노드에서 실행됩니다. 각 포드는 별도의 로컬 SSD와 백업 영구 디스크를 사용합니다.
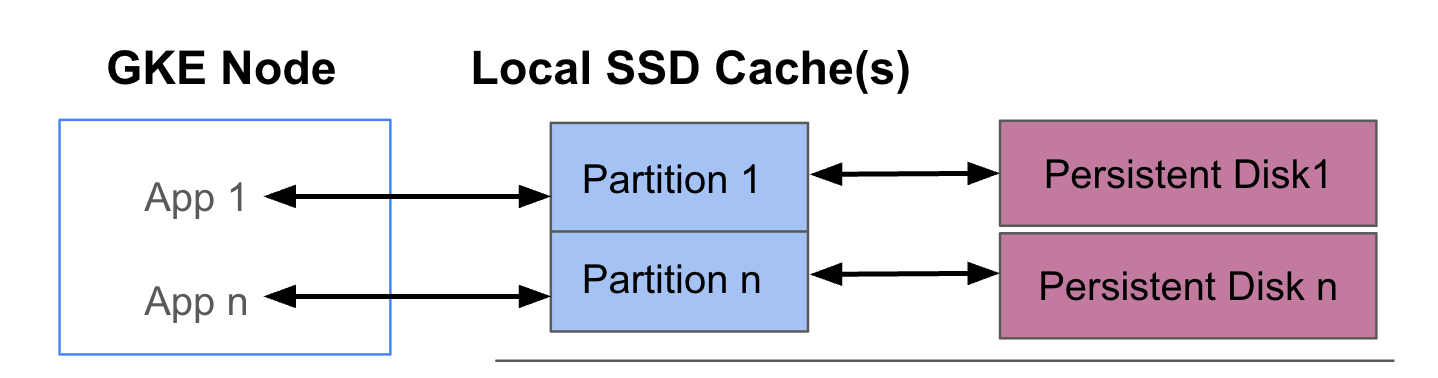
배포 모드
GKE 데이터 캐시를 다음 두 가지 모드 중 하나로 설정할 수 있습니다.
- Writethrough(권장): 애플리케이션에서 데이터를 쓰면 데이터는 캐시와 기본 영구 디스크 모두에 동기적으로 작성됩니다.
writethrough모드는 데이터 손실을 방지하며 대부분의 프로덕션 워크로드에 적합합니다. - Writeback: 애플리케이션에서 데이터를 쓸 때 데이터는 캐시에만 작성됩니다. 그런 다음 데이터가 영구 디스크에 비동기식으로(백그라운드에서) 작성됩니다.
writeback모드는 쓰기 성능을 향상시키며 속도에 의존하는 워크로드에 적합합니다. 그러나 이 모드는 신뢰성에 영향을 미칩니다. 노드가 예기치 않게 종료되면 플러시되지 않은 캐시 데이터가 손실됩니다.
목표
이 가이드에서는 다음을 수행하는 방법을 알아봅니다.
- 기본 GKE 인프라를 만들어 GKE 데이터 캐시를 사용합니다.
- 연결된 로컬 SSD를 사용하여 전용 노드 풀을 만듭니다.
- 포드가 PersistentVolumeClaim(PVC)을 통해 요청할 때 PersistentVolume(PV)이 동적으로 프로비저닝될 수 있도록 StorageClass를 만듭니다.
- PVC를 만들어 PV를 요청합니다.
- PVC를 사용하여 애플리케이션이 포드 재시작 후 및 재예약 중에도 영구 스토리지에 액세스할 수 있도록 배포를 만듭니다.
요구사항 및 계획
GKE 데이터 캐시를 사용하려면 다음 요구사항을 충족해야 합니다.
- GKE 클러스터에서 버전 1.32.3-gke.1440000 이상을 실행해야 합니다.
- 노드 풀에서 로컬 SSD를 지원하는 머신 유형을 사용해야 합니다. 자세한 내용은 머신 시리즈 지원을 참조하세요.
계획
GKE 데이터 캐시의 스토리지 용량을 계획할 때는 다음 사항을 고려하세요.
- GKE 데이터 캐시를 동시에 사용할 노드당 최대 포드 수입니다.
- GKE 데이터 캐시를 사용할 포드의 예상 캐시 크기 요구사항입니다.
- GKE 노드에서 사용할 수 있는 로컬 SSD의 총 용량입니다. 기본적으로 로컬 SSD가 연결된 머신 유형과 로컬 SSD를 연결해야 하는 머신 유형에 대한 자세한 내용은 유효한 로컬 SSD 디스크 수 선택을 참조하세요.
- 기본 수로 로컬 SSD가 연결된 3세대 이상 머신 유형의 경우 데이터 캐시용 로컬 SSD는 해당 머신의 사용 가능한 총 로컬 SSD 중에서 예약됩니다.
- 로컬 SSD의 사용 가능한 공간을 줄일 수 있는 파일 시스템 오버헤드입니다. 예를 들어 총 원시 용량이 750GiB인 로컬 SSD가 2개 있는 노드가 있더라도 파일 시스템 오버헤드로 인해 모든 데이터 캐시 볼륨에 사용할 수 있는 공간이 더 적을 수 있습니다. 일부 로컬 SSD 용량은 시스템용으로 예약되어 있습니다.
제한사항
Backup for GKE와의 비호환성
재해 복구 또는 애플리케이션 마이그레이션과 같은 시나리오에서 데이터 무결성을 유지하려면 데이터를 백업하고 복원해야 할 수 있습니다. Backup for GKE를 사용하여 데이터 캐시를 사용하도록 구성된 PVC를 복원하면 복원 프로세스가 실패합니다. 이 오류는 복원 프로세스가 원래 StorageClass에서 필요한 데이터 캐시 매개변수를 올바르게 전파하지 않기 때문에 발생합니다.
가격 책정
로컬 SSD 및 연결된 영구 디스크의 프로비저닝된 총 용량에 대한 요금이 청구됩니다. 매월 GiB당 요금이 청구됩니다.
자세한 내용은 Compute Engine 문서에서 디스크 가격 책정을 참조하세요.
시작하기 전에
시작하기 전에 다음 태스크를 수행했는지 확인합니다.
- Google Kubernetes Engine API를 사용 설정합니다. Google Kubernetes Engine API 사용 설정
- 이 태스크에 Google Cloud CLI를 사용하려면 gcloud CLI를 설치한 후 초기화합니다. 이전에 gcloud CLI를 설치했으면
gcloud components update명령어를 실행하여 최신 버전을 가져옵니다. 이전 gcloud CLI 버전에서는 이 문서의 명령어를 실행하지 못할 수 있습니다.
- 노드 풀의 로컬 SSD를 지원하는 머신 유형을 검토합니다.
데이터 캐시를 사용하도록 GKE 노드 구성
가속 스토리지에 GKE 데이터 캐시를 사용하려면 노드에 필요한 로컬 SSD 리소스가 있어야 합니다. 이 섹션에서는 새 GKE 클러스터를 만들거나 기존 클러스터에 새 노드 풀을 추가할 때 로컬 SSD를 프로비저닝하고 GKE 데이터 캐시를 사용 설정하는 명령어를 보여줍니다. 기존 노드 풀을 업데이트하여 데이터 캐시를 사용할 수는 없습니다. 기존 클러스터에서 데이터 캐시를 사용하려면 새 노드 풀을 클러스터에 추가합니다.
새 클러스터
데이터 캐시가 구성된 GKE 클러스터를 만들려면 다음 명령어를 사용합니다.
gcloud container clusters create CLUSTER_NAME \
--location=LOCATION \
--machine-type=MACHINE_TYPE \
--data-cache-count=DATA_CACHE_COUNT \
# Optionally specify additional Local SSDs, or skip this flag
--ephemeral-storage-local-ssd count=LOCAL_SSD_COUNT
다음을 바꿉니다.
CLUSTER_NAME: 클러스터의 이름입니다. 만들려는 GKE 클러스터의 고유한 이름을 입력합니다.LOCATION: 새 클러스터의 Cloud de Confiance by S3NS 리전이나 영역입니다.MACHINE_TYPE: 클러스터에 사용할 2세대, 3세대 또는 그 이후 세대 머신 시리즈의 머신 유형입니다(예:n2-standard-2또는c3-standard-4-lssd). 로컬 SSD를 기본e2-medium유형과 함께 사용할 수 없으므로 이 필드는 필수 항목입니다. 자세한 내용은 사용 가능한 머신 시리즈를 참조하세요.DATA_CACHE_COUNT: 기본 노드 풀의 각 노드에서 데이터 캐시 전용으로 사용할 로컬 SSD 볼륨 수입니다. 이러한 각 로컬 SSD 용량은 375GiB입니다. 최대 볼륨 수는 머신 유형과 리전에 따라 달라집니다. 일부 로컬 SSD 용량은 시스템용으로 예약되어 있습니다.(선택사항)
LOCAL_SSD_COUNT: 다른 임시 스토리지 니즈에 프로비저닝할 로컬 SSD 볼륨 수입니다. 데이터 캐시에 사용되지 않는 로컬 SSD를 추가로 프로비저닝하려면--ephemeral-storage-local-ssd count플래그를 사용합니다.3세대 이후 머신 유형의 경우 다음 사항에 유의하세요.
- 3세대 이후 머신 유형에는 기본적으로 로컬 SSD가 특정 수로 연결되어 있습니다. 각 노드에 연결된 로컬 SSD 수는 지정된 머신 유형에 따라 다릅니다.
- 임시 스토리지를 추가하기 위해
--ephemeral-storage-local-ssd count플래그를 사용하려면DATA_CACHE_COUNT값을 머신의 사용 가능한 총 로컬 SSD 디스크보다 작은 숫자로 설정해야 합니다. 사용 가능한 총 로컬 SSD 수는 연결된 기본 디스크와--ephemeral-storage-local-ssd count플래그를 사용하여 추가한 새 디스크를 포함합니다.
이 명령어는 기본 노드 풀의 2세대, 3세대 또는 그 이후 세대 머신 유형에서 실행되는 GKE 클러스터를 만들고 데이터 캐시용 로컬 SSD를 프로비저닝하며 지정된 경우 다른 임시 스토리지 니즈에 맞게 추가 로컬 SSD를 선택적으로 프로비저닝합니다.
이러한 설정은 기본 노드 풀에만 적용됩니다.
기존 클러스터에서
기존 클러스터에서 데이터 캐시를 사용하려면 데이터 캐시가 구성된 새 노드 풀을 만들어야 합니다.
데이터 캐시가 구성된 GKE 노드 풀을 만들려면 다음 명령어를 사용합니다.
gcloud container node-pool create NODE_POOL_NAME \
--cluster=CLUSTER_NAME \
--location=LOCATION \
--machine-type=MACHINE_TYPE \
--data-cache-count=DATA_CACHE_COUNT \
# Optionally specify additional Local SSDs, or skip this flag
--ephemeral-storage-local-ssd count=LOCAL_SSD_COUNT
다음을 바꿉니다.
NODE_POOL_NAME: 노드 풀의 이름입니다. 만들고 있는 노드 풀의 고유한 이름을 입력합니다.CLUSTER_NAME: 노드 풀을 만들려는 기존 GKE 클러스터의 이름입니다.LOCATION: 클러스터와 동일한 Cloud de Confiance by S3NS 리전 또는 영역입니다.MACHINE_TYPE: 클러스터에 사용할 2세대, 3세대 또는 그 이후 세대 머신 시리즈의 머신 유형입니다(예:n2-standard-2또는c3-standard-4-lssd). 로컬 SSD를 기본e2-medium유형과 함께 사용할 수 없으므로 이 필드는 필수 항목입니다. 자세한 내용은 사용 가능한 머신 시리즈를 참조하세요.DATA_CACHE_COUNT: 노드 풀의 각 노드에서 데이터 캐시 전용으로 사용할 로컬 SSD 볼륨 수입니다. 이러한 각 로컬 SSD 용량은 375GiB입니다. 최대 볼륨 수는 머신 유형과 리전에 따라 달라집니다. 일부 로컬 SSD 용량은 시스템용으로 예약되어 있습니다.(선택사항)
LOCAL_SSD_COUNT: 다른 임시 스토리지 니즈에 프로비저닝할 로컬 SSD 볼륨 수입니다. 데이터 캐시에 사용되지 않는 로컬 SSD를 추가로 프로비저닝하려면--ephemeral-storage-local-ssd count플래그를 사용합니다.3세대 이후 머신 유형의 경우 다음 사항에 유의하세요.
- 3세대 이후 머신 유형에는 기본적으로 로컬 SSD가 특정 수로 연결되어 있습니다. 각 노드에 연결된 로컬 SSD 수는 지정된 머신 유형에 따라 다릅니다.
- 임시 스토리지를 추가하기 위해
--ephemeral-storage-local-ssd count플래그를 사용하려면DATA_CACHE_COUNT를 머신의 사용 가능한 총 로컬 SSD 디스크보다 적은 수로 설정해야 합니다. 사용 가능한 총 로컬 SSD 수는 연결된 기본 디스크와--ephemeral-storage-local-ssd count플래그를 사용하여 추가한 새 디스크를 포함합니다.
이 명령어는 2세대, 3세대 또는 그 이후 세대 머신 유형에서 실행되는 GKE 노드 풀을 만들고 데이터 캐시용 로컬 SSD를 프로비저닝하며 지정된 경우 다른 임시 스토리지 니즈에 맞게 추가 로컬 SSD를 선택적으로 프로비저닝합니다.
GKE의 영구 스토리지용 데이터 캐시 프로비저닝
이 섹션에서는 스테이트풀(Stateful) 애플리케이션에 GKE 데이터 캐시의 성능 이점을 사용 설정하는 방법의 예시를 제공합니다.
데이터 캐시용 로컬 SSD로 노드 풀 만들기
먼저 연결된 로컬 SSD를 사용하여 GKE 클러스터에 새 노드 풀을 만듭니다. GKE 데이터 캐시는 로컬 SSD를 사용하여 연결된 영구 디스크의 성능을 가속화합니다.
다음 명령어는 2세대 머신 n2-standard-2를 사용하는 노드 풀을 만듭니다.
gcloud container node-pools create datacache-node-pool \
--cluster=CLUSTER_NAME \
--location=LOCATION \
--num-nodes=2 \
--data-cache-count=1 \
--machine-type=n2-standard-2
다음을 바꿉니다.
CLUSTER_NAME: 클러스터의 이름입니다. 새 노드 풀을 만들 GKE 클러스터를 지정합니다.LOCATION: 클러스터와 동일한 Cloud de Confiance by S3NS 리전 또는 영역입니다.
이 명령어는 다음 사양을 사용하여 노드 풀을 만듭니다.
--num-nodes=2: 이 풀의 초기 노드 수를 2로 설정합니다.--data-cache-count=1: GKE 데이터 캐시 전용으로 노드당 로컬 SSD 하나를 지정합니다.
각 노드에 로컬 SSD 하나가 프로비저닝되므로 이 노드 풀에 프로비저닝된 로컬 SSD 총개수는 2개입니다.
데이터 캐시 StorageClass 만들기
데이터 캐시를 사용하는 영구 볼륨을 동적으로 프로비저닝하는 방법을 GKE에 알려주는 Kubernetes StorageClass를 만듭니다.
다음 매니페스트를 사용하여 pd-balanced-data-cache-sc라는 StorageClass를 만들고 적용합니다.
kubectl apply -f - <<EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: pd-balanced-data-cache-sc
provisioner: pd.csi.storage.gke.io
parameters:
type: pd-balanced
data-cache-mode: writethrough
data-cache-size: "100Gi"
volumeBindingMode: WaitForFirstConsumer
allowVolumeExpansion: true
EOF
데이터 캐시의 StorageClass 파라미터에는 다음이 포함됩니다.
type: 영구 볼륨의 기본 디스크 유형을 지정합니다. 자세한 옵션은 지원되는 Persistent Disk 유형 또는 Hyperdisk 유형을 참조하세요.data-cache-mode: 권장되는writethrough모드를 사용합니다. 자세한 내용은 배포 모드를 참조하세요.data-cache-size: 로컬 SSD 용량을 100GiB로 설정합니다. 이 용량은 각 PVC의 읽기 캐시로 사용됩니다.
PersistentVolumeClaim(PVC)으로 스토리지 요청
이전에 만든 pd-balanced-data-cache-sc StorageClass를 참조하는 PVC를 만듭니다. PVC에서 데이터 캐시가 사용 설정된 영구 볼륨을 요청합니다.
다음 매니페스트를 사용하여 ReadWriteOnce 액세스 권한이 있는 최소 300GiB 이상의 영구 볼륨을 요청하는 pvc-data-cache PVC를 만듭니다.
kubectl apply -f - <<EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-data-cache
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 300Gi
storageClassName: pd-balanced-data-cache-sc
EOF
PVC를 사용하는 배포 만들기
이전에 만든 pvc-data-cache PVC를 사용하는 포드를 실행하는 postgres-data-cache 배포를 만듭니다. cloud.google.com/gke-data-cache-count 노드 선택기를 사용하면 GKE 데이터 캐시 사용에 필요한 로컬 SSD 리소스가 있는 노드에 포드가 예약됩니다.
다음 매니페스트를 만들고 적용하여 PVC를 사용하여 Postgres 웹 서버를 배포하는 포드를 구성합니다.
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-data-cache
labels:
name: database
app: data-cache
spec:
replicas: 1
selector:
matchLabels:
service: postgres
app: data-cache
template:
metadata:
labels:
service: postgres
app: data-cache
spec:
nodeSelector:
cloud.google.com/gke-data-cache-disk: "1"
containers:
- name: postgres
image: postgres:14-alpine
volumeMounts:
- name: pvc-data-cache-vol
mountPath: /var/lib/postgresql/data2
subPath: postgres
env:
- name: POSTGRES_USER
value: admin
- name: POSTGRES_PASSWORD
value: password
restartPolicy: Always
volumes:
- name: pvc-data-cache-vol
persistentVolumeClaim:
claimName: pvc-data-cache
EOF
배포가 성공적으로 생성되었는지 확인합니다.
kubectl get deployment
Postgres 컨테이너가 프로비저닝을 완료하고 READY 상태를 표시하는 데 몇 분 정도 걸릴 수 있습니다.
데이터 캐시 프로비저닝 확인
배포를 만든 후 데이터 캐시가 있는 영구 스토리지가 올바르게 프로비저닝되었는지 확인합니다.
pvc-data-cache가 영구 볼륨에 성공적으로 바인딩되었는지 확인하려면 다음 명령어를 실행합니다.kubectl get pvc pvc-data-cache출력은 다음과 비슷합니다.
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE pvc-data-cache Bound pvc-e9238a16-437e-45d7-ad41-410c400ae018 300Gi RWO pd-balanced-data-cache-sc <unset> 10m데이터 캐시용 논리 볼륨 관리자(LVM) 그룹이 노드에 생성되었는지 확인하려면 다음 단계를 수행합니다.
해당 노드에서 PDCSI 드라이버의 포드 이름을 가져옵니다.
NODE_NAME=$(kubectl get pod --output json | jq '.items[0].spec.nodeName' | sed 's/\"//g') kubectl get po -n kube-system -o wide | grep ^pdcsi-node | grep $NODE_NAME출력에서
pdcsi-node포드 이름을 복사합니다.LVM 그룹 생성에 대한 PDCSI 드라이버 로그를 봅니다.
PDCSI_POD_NAME="PDCSI-NODE_POD_NAME" kubectl logs -n kube-system $PDCSI_POD_NAME gce-pd-driver | grep "Volume group creation"PDCSI-NODE_POD_NAME을 이전 단계에서 복사한 실제 포드 이름으로 바꿉니다.출력은 다음과 비슷합니다.
Volume group creation succeeded for LVM_GROUP_NAME
이 메시지는 데이터 캐시의 LVM 구성이 노드에 올바르게 설정되었음을 나타냅니다.
삭제
Cloud de Confiance by S3NS 계정에 비용이 청구되지 않게 하려면 이 가이드에서 만든 스토리지 리소스를 삭제합니다.
배포를 삭제합니다.
kubectl delete deployment postgres-data-cachePersistentVolumeClaim을 삭제합니다.
kubectl delete pvc pvc-data-cache노드 풀을 삭제합니다.
gcloud container node-pools delete datacache-node-pool \ --cluster CLUSTER_NAMECLUSTER_NAME을 데이터 캐시를 사용하는 노드 풀을 만든 클러스터의 이름으로 바꿉니다.
다음 단계
- GKE에서 스토리지 문제 해결을 참조하세요.
- GitHub에서 Persistent Disk CSI 드라이버 자세히 알아보기