
Só é possível usar o cache de dados com clusters do GKE Standard. Este guia mostra como ativar o GKE Data Cache ao criar um cluster padrão do GKE ou um pool de nós e como provisionar discos anexados do GKE com aceleração do Data Cache.
Sobre o cache de dados do GKE
Com o GKE Data Cache, é possível usar SSDs locais nos nós do GKE como uma camada de cache para seu armazenamento permanente, como discos permanentes ou hiperdiscos. O uso de SSDs locais reduz a latência de leitura do disco e aumenta as consultas por segundo (QPS) para suas cargas de trabalho com estado, minimizando os requisitos de memória. O GKE Data Cache é compatível com todos os tipos de Persistent Disk ou Hyperdisk como discos de apoio.
Para usar o GKE Data Cache no seu aplicativo, configure o pool de nós do GKE com SSDs locais anexados. É possível configurar o GKE Data Cache para usar todo ou parte do SSD local anexado. Os SSDs locais usados pela solução GKE Data Cache são criptografados em repouso usando a criptografia Cloud de Confiance by S3NS padrão.
Vantagens
O GKE Data Cache oferece os seguintes benefícios:
- Aumento da taxa de consultas processadas por segundo para bancos de dados convencionais, como MySQL ou Postgres, e bancos de dados vetoriais.
- Melhoria no desempenho de leitura para aplicativos com estado ao minimizar a latência do disco.
- Hidratação e reidratação de dados mais rápidas porque os SSDs são locais para o nó. A hidratação de dados se refere ao processo inicial de carregamento dos dados necessários do armazenamento permanente para o SSD local. A reidratação de dados se refere ao processo de restaurar os dados nos SSDs locais depois que um nó é reciclado.
Arquitetura de implantação
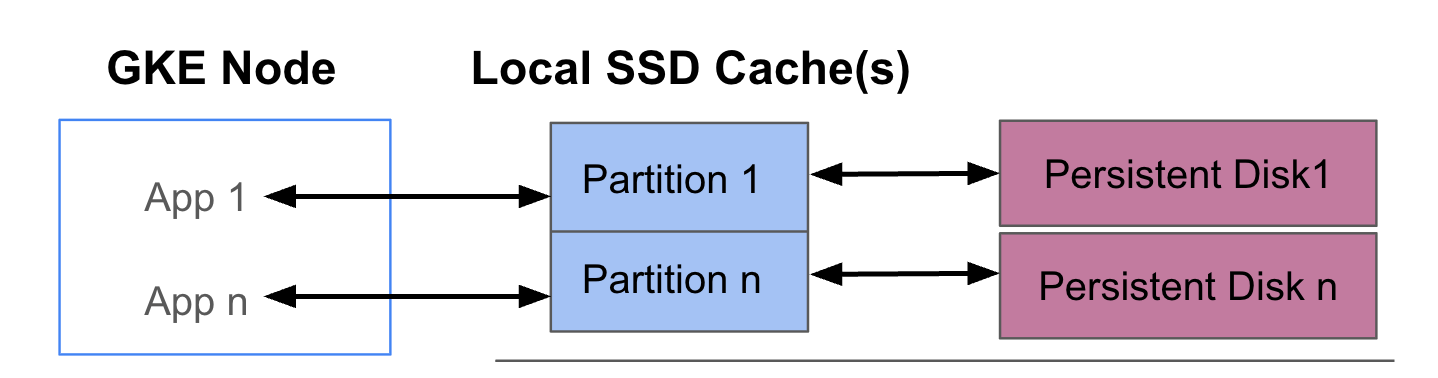
O diagrama a seguir mostra um exemplo de configuração do GKE Data Cache com dois pods que executam um app cada um. Os pods são executados no mesmo nó do GKE. Cada pod usa um SSD local separado e um disco permanente de apoio.
Modos de implantação
É possível configurar o GKE Data Cache em um destes dois modos:
- Writethrough (recomendado): quando seu aplicativo grava dados, eles são gravados de maneira síncrona no cache e no disco permanente subjacente. O modo
writethroughevita a perda de dados e é adequado para a maioria das cargas de trabalho de produção. - Writeback: quando seu aplicativo grava dados, eles são gravados apenas no cache. Em seguida, os dados são gravados no disco permanente de forma assíncrona (em segundo plano). O modo
writebackmelhora o desempenho de gravação e é adequado para cargas de trabalho que dependem de velocidade. No entanto, esse modo afeta a confiabilidade. Se o nó for desligado de forma inesperada, os dados do cache não liberados serão perdidos.
Objetivos
Neste guia, você vai aprender a:
- Crie uma infraestrutura do GKE para usar o GKE Data Cache.
- Crie um pool de nós dedicado com SSDs locais anexados.
- Crie uma StorageClass para provisionar dinamicamente um PersistentVolume (PV) quando um pod o solicita por um PersistentVolumeClaim (PVC).
- Crie um PVC para solicitar um PV.
- Crie uma implantação que use um PVC para garantir que seu aplicativo tenha acesso ao armazenamento permanente mesmo após a reinicialização de um pod e durante o reagendamento.
Requisitos e planejamento
Verifique se você atende aos seguintes requisitos para usar o GKE Data Cache:
- Seu cluster do GKE precisa estar executando a versão 1.32.3-gke.1440000 ou mais recente.
- Seus pools de nós precisam usar tipos de máquinas que ofereçam suporte a SSDs locais. Para mais informações, consulte Suporte para séries de máquinas.
Planejamento
Considere estes aspectos ao planejar a capacidade de armazenamento do GKE Data Cache:
- O número máximo de pods por nó que usarão o GKE Data Cache simultaneamente.
- Os requisitos de tamanho de cache esperados dos pods que vão usar o cache de dados do GKE.
- A capacidade total de SSDs locais disponíveis nos nós do GKE. Para informações sobre quais tipos de máquinas têm SSDs locais anexados por padrão e quais exigem que você anexe SSDs locais, consulte Escolher um número válido de discos SSD locais.
- Para tipos de máquinas de terceira geração ou mais recentes (que têm um número padrão de SSDs locais anexados), observe que os SSDs locais para cache de dados são reservados do total disponível de SSDs locais nessa máquina.
- A sobrecarga do sistema de arquivos que pode reduzir o espaço utilizável nos SSDs locais. Por exemplo, mesmo que você tenha um nó com dois SSDs locais com 750 GiB de capacidade bruta total, o espaço disponível para todos os volumes de cache de dados pode ser menor devido à sobrecarga do sistema de arquivos. Parte da capacidade do SSD local é reservada para uso do sistema.
Limitações
Incompatibilidade com o Backup para GKE
Para manter a integridade dos dados em cenários como recuperação de desastres ou migração de aplicativos, talvez seja necessário fazer backup e restaurar os dados. Se você usar o Backup para GKE para restaurar um PVC configurado para usar o cache de dados, o processo de restauração vai falhar. Isso acontece porque o processo de restauração não propaga corretamente os parâmetros de cache de dados necessários da StorageClass original.
Preços
A capacidade total provisionada dos SSDs locais e dos discos permanentes anexados será cobrada. A cobrança é feita por GiB mensalmente.
Para mais informações, consulte Preços de disco na documentação do Compute Engine.
Antes de começar
Antes de começar, verifique se você realizou as tarefas a seguir:
- Ativar a API Google Kubernetes Engine. Ativar a API Google Kubernetes Engine
- Se você quiser usar a CLI do Google Cloud para essa tarefa,
instale e inicialize a
gcloud CLI. Se você instalou a CLI gcloud anteriormente, instale a versão
mais recente executando o comando
gcloud components update. Talvez as versões anteriores da CLI gcloud não sejam compatíveis com a execução dos comandos neste documento.
- Revise os tipos de máquina que oferecem suporte a SSDs locais para seu pool de nós.
Configurar nós do GKE para usar o cache de dados
Para começar a usar o GKE Data Cache para armazenamento acelerado, seus nós precisam ter os recursos necessários do SSD local. Esta seção mostra comandos para provisionar SSDs locais e ativar o cache de dados do GKE ao criar um cluster do GKE ou adicionar um pool de nós a um cluster atual. Não é possível atualizar um pool de nós para usar o cache de dados. Se você quiser usar o cache de dados em um cluster atual, adicione um novo pool de nós a ele.
Em um novo cluster
Para criar um cluster do GKE com o cache de dados configurado, use o comando a seguir:
gcloud container clusters create CLUSTER_NAME \
--location=LOCATION \
--machine-type=MACHINE_TYPE \
--data-cache-count=DATA_CACHE_COUNT \
# Optionally specify additional Local SSDs, or skip this flag
--ephemeral-storage-local-ssd count=LOCAL_SSD_COUNT
Substitua:
CLUSTER_NAME: o nome do cluster. Dê um nome exclusivo ao cluster do GKE que você está criando.LOCATION: a Cloud de Confiance by S3NS região ou zona do novo cluster.MACHINE_TYPE: o tipo de máquina a ser usado em uma série de máquinas de segunda, terceira ou gerações posteriores para seu cluster, comon2-standard-2ouc3-standard-4-lssd. Esse campo é obrigatório porque o SSD local não pode ser usado com o tipoe2-mediumpadrão. Para mais informações, consulte as séries de máquinas disponíveis.DATA_CACHE_COUNT: o número de volumes SSD locais a serem dedicados exclusivamente para o cache de dados em cada nó no pool de nós padrão. Cada um desses SSDs locais tem uma capacidade de 375 GiB. O número máximo de volumes varia de acordo com o tipo de máquina e região. Lembre-se que uma parte da capacidade do SSD local é reservada para uso do sistema.(Opcional)
LOCAL_SSD_COUNT: o número de volumes SSD locais a serem provisionados para outras necessidades de armazenamento temporário. Use a flag--ephemeral-storage-local-ssd countse quiser provisionar outros SSDs locais que não são usados para o cache de dados.Observe o seguinte para os tipos de máquina de terceira geração ou mais recentes:
- Os tipos de máquina de terceira geração ou mais recentes têm um número específico de SSDs locais anexados por padrão. O número de SSDs locais anexados a cada nó depende do tipo de máquina especificado.
- Se você planeja usar a flag
--ephemeral-storage-local-ssd countpara armazenamento temporário adicional, defina o valor deDATA_CACHE_COUNTcomo um número menor que o total disponível de discos SSD locais na máquina. A contagem total de SSDs locais disponíveis inclui os discos anexados padrão e todos os novos discos adicionados usando a flag--ephemeral-storage-local-ssd count.
Esse comando cria um cluster do GKE que é executado em um tipo de máquina de segunda, terceira ou geração mais recente para o pool de nós padrão, provisiona SSDs locais para cache de dados e, opcionalmente, provisiona SSDs locais adicionais para outras necessidades de armazenamento temporário, se especificado.
Essas configurações são válidas apenas para o pool de nós padrão.
Em um cluster atual
Para usar o cache de dados em um cluster atual, crie um novo pool de nós com o cache de dados configurado.
Para criar um pool de nós do GKE com o cache de dados configurado, use o comando a seguir:
gcloud container node-pool create NODE_POOL_NAME \
--cluster=CLUSTER_NAME \
--location=LOCATION \
--machine-type=MACHINE_TYPE \
--data-cache-count=DATA_CACHE_COUNT \
# Optionally specify additional Local SSDs, or skip this flag
--ephemeral-storage-local-ssd count=LOCAL_SSD_COUNT
Substitua:
NODE_POOL_NAME: o nome do pool de nós. Forneça um nome exclusivo para o pool de nós que você está criando.CLUSTER_NAME: o nome de um cluster do GKE em que você quer criar o pool de nós.LOCATION: a mesma Cloud de Confiance by S3NS região ou zona do cluster.MACHINE_TYPE: o tipo de máquina a ser usado em uma série de máquinas de segunda, terceira ou gerações posteriores para seu cluster, comon2-standard-2ouc3-standard-4-lssd. Esse campo é obrigatório, já que o SSD local não pode ser usado com o tipoe2-mediumpadrão. Para mais informações, consulte as séries de máquinas disponíveis.DATA_CACHE_COUNT: o número de volumes SSD locais a serem dedicados exclusivamente para o cache de dados em cada nó do pool de nós. Cada um desses SSDs locais tem uma capacidade de 375 GiB. O número máximo de volumes varia de acordo com o tipo de máquina e região. Lembre-se que uma parte da capacidade do SSD local é reservada para uso do sistema.(Opcional)
LOCAL_SSD_COUNT: o número de volumes SSD locais a serem provisionados para outras necessidades de armazenamento temporário. Use a flag--ephemeral-storage-local-ssd countse quiser provisionar outros SSDs locais que não são usados para o cache de dados.Observe o seguinte para os tipos de máquina de terceira geração ou mais recentes:
- Os tipos de máquina de terceira geração ou mais recentes têm um número específico de SSDs locais anexados por padrão. O número de SSDs locais anexados a cada nó depende do tipo de máquina especificado.
- Se você planeja usar a flag
--ephemeral-storage-local-ssd countpara armazenamento temporário adicional, definaDATA_CACHE_COUNTcomo menor que o número total disponível de discos SSD locais na máquina. A contagem total de SSDs locais disponíveis inclui os discos anexados padrão e todos os novos discos adicionados usando a flag--ephemeral-storage-local-ssd count.
Esse comando cria um pool de nós do GKE que é executado em um tipo de máquina de segunda, terceira ou geração mais recente, provisiona SSDs locais para cache de dados e, opcionalmente, provisiona SSDs locais adicionais para outras necessidades de armazenamento temporário, se especificado.
Provisionar o cache de dados para armazenamento permanente no GKE
Nesta seção, você encontra um exemplo de como ativar os benefícios de desempenho do cache de dados do GKE para seus aplicativos com estado.
Criar um pool de nós com SSDs locais para cache de dados
Comece criando um pool de nós com SSDs locais anexados no cluster do GKE. O cache de dados do GKE usa os SSDs locais para acelerar o desempenho dos discos permanentes anexados.
O comando a seguir cria um pool de nós que usa uma máquina de segunda geração, n2-standard-2:
gcloud container node-pools create datacache-node-pool \
--cluster=CLUSTER_NAME \
--location=LOCATION \
--num-nodes=2 \
--data-cache-count=1 \
--machine-type=n2-standard-2
Substitua:
CLUSTER_NAME: o nome do cluster. Especifique o cluster do GKE em que você está criando o novo pool de nós.LOCATION: a mesma região ou zona Cloud de Confiance by S3NS do cluster.
Esse comando cria um pool de nós com as seguintes especificações:
--num-nodes=2: define o número inicial de nós neste pool como dois.--data-cache-count=1: especifica um SSD local por nó dedicado ao GKE Data Cache.
O número total de SSDs locais provisionados para esse pool de nós é dois, porque cada nó é provisionado com um SSD local.
Criar um StorageClass de cache de dados
Crie um StorageClass do Kubernetes
que informe ao GKE como provisionar dinamicamente um volume permanente
que usa o cache de dados.
Use o seguinte manifesto para criar e aplicar um StorageClass chamado pd-balanced-data-cache-sc:
kubectl apply -f - <<EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: pd-balanced-data-cache-sc
provisioner: pd.csi.storage.gke.io
parameters:
type: pd-balanced
data-cache-mode: writethrough
data-cache-size: "100Gi"
volumeBindingMode: WaitForFirstConsumer
allowVolumeExpansion: true
EOF
Os parâmetros StorageClass para o cache de dados incluem o seguinte:
type: especifica o tipo de disco subjacente para o volume permanente. Para mais opções, consulte os tipos de disco permanente ou Hyperdisk compatíveis.data-cache-mode: usa o modowritethroughrecomendado. Para mais informações, consulte Modos de implantação.data-cache-size: define a capacidade do SSD local como 100 GiB, que é usada como um cache de leitura para cada PVC.
Solicitar armazenamento com um PersistentVolumeClaim (PVC)
Crie um PVC que faça referência à StorageClass pd-balanced-data-cache-sc que você criou. O PVC solicita um volume permanente com o cache de dados ativado.
Use o manifesto a seguir para criar um PVC chamado pvc-data-cache que solicita
um volume permanente de pelo menos 300 GiB com acesso ReadWriteOnce.
kubectl apply -f - <<EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-data-cache
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 300Gi
storageClassName: pd-balanced-data-cache-sc
EOF
Criar uma implantação que use o PVC
Crie uma implantação chamada postgres-data-cache que execute um pod usando o
PVC pvc-data-cache criado anteriormente. O seletor de nós cloud.google.com/gke-data-cache-count
garante que o pod seja programado em um nó com os recursos de SSD local
necessários para usar o GKE Data Cache.
Crie e aplique o manifesto a seguir para configurar um pod que implanta um servidor da Web Postgres usando o PVC:
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-data-cache
labels:
name: database
app: data-cache
spec:
replicas: 1
selector:
matchLabels:
service: postgres
app: data-cache
template:
metadata:
labels:
service: postgres
app: data-cache
spec:
nodeSelector:
cloud.google.com/gke-data-cache-disk: "1"
containers:
- name: postgres
image: postgres:14-alpine
volumeMounts:
- name: pvc-data-cache-vol
mountPath: /var/lib/postgresql/data2
subPath: postgres
env:
- name: POSTGRES_USER
value: admin
- name: POSTGRES_PASSWORD
value: password
restartPolicy: Always
volumes:
- name: pvc-data-cache-vol
persistentVolumeClaim:
claimName: pvc-data-cache
EOF
Confirme se a implantação foi criada:
kubectl get deployment
Pode levar alguns minutos para que o contêiner do Postgres conclua o provisionamento
e mostre um status READY.
Verificar o provisionamento do cache de dados
Depois de criar a implantação, confirme se o armazenamento permanente com o cache de dados foi provisionado corretamente.
Para verificar se o
pvc-data-cachefoi vinculado a um volume permanente, execute o seguinte comando:kubectl get pvc pvc-data-cacheO resultado será assim:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE pvc-data-cache Bound pvc-e9238a16-437e-45d7-ad41-410c400ae018 300Gi RWO pd-balanced-data-cache-sc <unset> 10mPara confirmar se o grupo do Logical Volume Manager (LVM) para o cache de dados foi criado no nó, siga estas etapas:
Consiga o nome do pod do driver PDCSI nesse nó:
NODE_NAME=$(kubectl get pod --output json | jq '.items[0].spec.nodeName' | sed 's/\"//g') kubectl get po -n kube-system -o wide | grep ^pdcsi-node | grep $NODE_NAMENa saída, copie o nome do pod
pdcsi-node.Ver registros do driver PDCSI para criação de grupo LVM:
PDCSI_POD_NAME="PDCSI-NODE_POD_NAME" kubectl logs -n kube-system $PDCSI_POD_NAME gce-pd-driver | grep "Volume group creation"Substitua
PDCSI-NODE_POD_NAMEpelo nome real do pod que você copiou na etapa anterior.O resultado será assim:
Volume group creation succeeded for LVM_GROUP_NAME
Essa mensagem confirma que a configuração do LVM para o cache de dados está configurada corretamente no nó.
Limpar
Para evitar cobranças na sua conta do Cloud de Confiance by S3NS , exclua os recursos de armazenamento criados neste guia.
Exclua a implantação.
kubectl delete deployment postgres-data-cacheExclua o PersistentVolumeClaim.
kubectl delete pvc pvc-data-cacheExclua o pool de nós.
gcloud container node-pools delete datacache-node-pool \ --cluster CLUSTER_NAMESubstitua
CLUSTER_NAMEpelo nome do cluster em que você criou o pool de nós que usa o cache de dados.
A seguir
- Consulte Solução de problemas de armazenamento no GKE.
- Leia mais sobre o driver CSI do Persistent Disk no GitHub.