
En este documento, se proporciona una descripción general de una suscripción a BigQuery, su flujo de trabajo y las propiedades asociadas.
Una suscripción a BigQuery es un tipo de suscripción de exportación que escribe los mensajes en una tabla de BigQuery existente a medida que se reciben. No necesitas configurar un cliente suscriptor independiente. Usa la consola de Cloud de Confiance , Google Cloud CLI, las bibliotecas cliente o la API de Pub/Sub para crear, actualizar, enumerar, separar o borrar una suscripción de BigQuery.
Sin el tipo de suscripción a BigQuery, necesitas una suscripción de extracción o de envío y un suscriptor (como Dataflow) que lea mensajes y los escriba en una tabla de BigQuery. La sobrecarga de ejecutar un trabajo de Dataflow no es necesaria cuando los mensajes no requieren procesamiento adicional antes de almacenarlos en una tabla de BigQuery; en su lugar, puedes usar una suscripción a BigQuery.
Para realizar modificaciones ligeras en los mensajes, puedes adjuntar una transformación de mensaje único a tu suscripción de BigQuery. Sin embargo, se recomienda una canalización de Dataflow para los sistemas de Pub/Sub en los que se requiere una transformación de datos más compleja antes de que los datos se almacenen en una tabla de BigQuery, en especial si deseas crear ventanas o agregar datos en varios mensajes.
Para aprender a transmitir datos de Pub/Sub a BigQuery con transformación usando Dataflow, consulta Transmite datos de Pub/Sub a BigQuery.
La plantilla de suscripción de Pub/Sub a BigQuery de Dataflow aplica la entrega exactamente una vez de forma predeterminada. Esto se suele lograr a través de mecanismos de anulación de duplicados dentro de la canalización de Dataflow. Sin embargo, la suscripción de BigQuery solo admite la entrega al menos una vez. Si la deduplicación exacta es fundamental para tu caso de uso, considera los procesos posteriores en BigQuery para controlar los posibles duplicados.
Antes de comenzar
Antes de leer este documento, asegúrate de estar familiarizado con lo siguiente:
Cómo funciona Pub/Sub y los diferentes términos de Pub/Sub
Los diferentes tipos de suscripciones que admite Pub/Sub y por qué te convendría usar una suscripción a BigQuery
Cómo funciona BigQuery y cómo configurar y administrar las tablas de BigQuery
Flujo de trabajo de suscripción a BigQuery
En la siguiente imagen, se muestra el flujo de trabajo entre una suscripción a BigQuery y BigQuery.
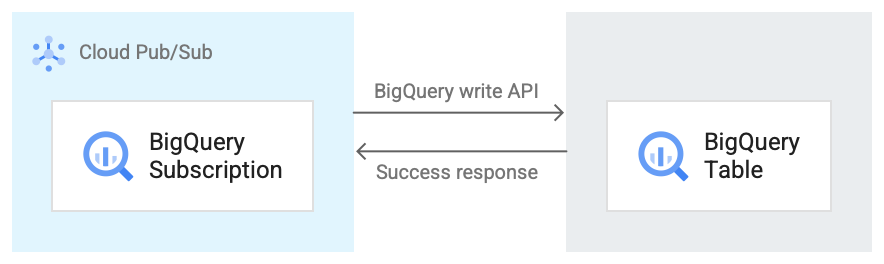
A continuación, se incluye una breve descripción del flujo de trabajo que se menciona en la Figura 1:
- Pub/Sub usa la API de BigQuery Storage Write para enviar datos a la tabla de BigQuery.
- Los mensajes se envían en lotes a la tabla de BigQuery.
- Después de que se completa correctamente una operación de escritura, la API devuelve una respuesta OK.
- Si hay errores en la operación de escritura, se envía una confirmación negativa del mensaje de Pub/Sub. Luego, se vuelve a enviar el mensaje. Si el mensaje falla suficientes veces y hay un tema de mensaje no entregado configurado en la suscripción, el mensaje se mueve a ese tema.
Propiedades de una suscripción a BigQuery
Las propiedades que configuras para una suscripción de BigQuery determinan la tabla de BigQuery en la que Pub/Sub escribe mensajes y el tipo de esquema de esa tabla.
Para obtener más información, consulta Propiedades de BigQuery.
Compatibilidad del esquema
Esta sección solo se aplica si seleccionas la opción Usar el esquema de tema cuando creas una suscripción a BigQuery.
Pub/Sub y BigQuery usan diferentes formas de definir sus esquemas. Los esquemas de Pub/Sub se definen en formato de Apache Avro o búfer de protocolo, mientras que los esquemas de BigQuery se definen con una variedad de formatos.
A continuación, se incluye una lista de información importante sobre la compatibilidad del esquema entre un tema de Pub/Sub y una tabla de BigQuery.
Los mensajes que contienen campos con formato incorrecto no se escriben en BigQuery.
En el esquema de BigQuery,
INT,SMALLINT,INTEGER,BIGINT,TINYINTyBYTEINTson alias deINTEGER;DECIMALes un alias deNUMERIC, yBIGDECIMALes un alias deBIGNUMERIC.Cuando el tipo en el esquema del tema es
stringy el tipo en la tabla de BigQuery esJSON,TIMESTAMP,DATETIME,DATE,TIME,NUMERICoBIGNUMERIC, cualquier valor para este campo en un mensaje de Pub/Sub debe cumplir con el formato especificado para el tipo de datos de BigQuery.Se admiten algunos tipos lógicos de Avro, como se especifica en la siguiente tabla. Los tipos lógicos que no se enumeran solo coinciden con el tipo de Avro equivalente que anotan, como se detalla en la especificación de Avro.
A continuación, se incluye una colección de asignaciones de diferentes formatos de esquema a tipos de datos de BigQuery.
Tipos de Avro
| Tipo de Avro | Tipo de datos de BigQuery |
null |
Any NULLABLE |
boolean |
BOOLEAN |
int |
INTEGER, NUMERIC o
BIGNUMERIC |
long |
INTEGER, NUMERIC o
BIGNUMERIC |
float |
FLOAT64, NUMERIC o
BIGNUMERIC |
double |
FLOAT64, NUMERIC o
BIGNUMERIC |
bytes |
BYTES, NUMERIC o
BIGNUMERIC |
string |
STRING, JSON,
TIMESTAMP, DATETIME,
DATE, TIME,
NUMERIC o BIGNUMERIC |
record |
RECORD/STRUCT |
array de Type |
REPEATED Type |
map con el tipo de valor ValueType
|
REPEATED STRUCT <key STRING, value
ValueType> |
union con dos tipos, uno que es null y el otro Type |
NULLABLE Type |
otros union |
Sin asignar |
fixed |
BYTES, NUMERIC o
BIGNUMERIC |
enum |
INTEGER |
Tipos lógicos de Avro
| Tipo lógico de Avro | Tipo de datos de BigQuery |
timestamp-micros |
TIMESTAMP |
timestamp-millis |
TIMESTAMP |
date |
DATE |
time-micros |
TIME |
time-millis |
TIME |
duration |
INTERVAL |
decimal |
NUMERIC o BIGNUMERIC |
Tipos de búfer de protocolo
| Tipo de búfer de protocolo | Tipo de datos de BigQuery |
double |
FLOAT64, NUMERIC o
BIGNUMERIC |
float |
FLOAT64, NUMERIC o
BIGNUMERIC |
int32 |
INTEGER, NUMERIC, BIGNUMERIC o DATE |
int64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME o TIMESTAMP |
uint32 |
INTEGER, NUMERIC, BIGNUMERIC o DATE |
uint64 |
NUMERIC o BIGNUMERIC |
sint32 |
INTEGER, NUMERIC o
BIGNUMERIC |
sint64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME o TIMESTAMP |
fixed32 |
INTEGER, NUMERIC, BIGNUMERIC o DATE |
fixed64 |
NUMERIC o BIGNUMERIC |
sfixed32 |
INTEGER, NUMERIC, BIGNUMERIC o DATE |
sfixed64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME o TIMESTAMP |
bool |
BOOLEAN |
string |
STRING, JSON,
TIMESTAMP, DATETIME,
DATE, TIME,
NUMERIC o BIGNUMERIC |
bytes |
BYTES, NUMERIC o
BIGNUMERIC |
enum |
INTEGER |
message |
RECORD/STRUCT |
oneof |
Sin asignar |
map<KeyType, ValueType> |
REPEATED RECORD<key KeyType, value
ValueType> |
enum |
INTEGER |
repeated/array of Type |
REPEATED Type |
Representación de números enteros de fecha y hora
Cuando se asigna un número entero a uno de los tipos de fecha o hora, el número debe representar el valor correcto. A continuación, se muestra la asignación de los tipos de datos de BigQuery al número entero que los representa.
| Tipo de datos de BigQuery | Representación de números enteros |
DATE |
Cantidad de días transcurridos desde la época Unix, el 1 de enero de 1970 |
DATETIME |
Fecha y hora en microsegundos expresadas como hora civil con CivilTimeEncoder |
TIME |
Hora en microsegundos expresada como hora civil con CivilTimeEncoder |
TIMESTAMP |
Cantidad de microsegundos desde la época Unix, el 1 de enero de 1970 a las 00:00:00 UTC |
Transferencia de captura de datos modificados de BigQuery
Las suscripciones de BigQuery admiten actualizaciones de la transferencia de datos de captura de datos modificados (CDC) cuando use_topic_schema o use_table_schema se configuran como true en las propiedades de la suscripción. Para usar la función con use_topic_schema, establece el esquema del tema con los siguientes campos:
_CHANGE_TYPE(obligatorio): Un campostringestablecido enUPSERToDELETE.Si un mensaje de Pub/Sub escrito en la tabla de BigQuery tiene
_CHANGE_TYPEestablecido enUPSERT, BigQuery actualiza la fila con la misma clave si existe o inserta una fila nueva si no existe.Si un mensaje de Pub/Sub escrito en la tabla de BigQuery tiene
_CHANGE_TYPEestablecido enDELETE, BigQuery borra la fila de la tabla con la misma clave, si existe.
_CHANGE_SEQUENCE_NUMBER(opcional): Es un campostringconfigurado para garantizar que las actualizaciones y los borrados realizados en la tabla de BigQuery se procesen en orden. Los mensajes para la misma clave de fila deben contener un valor monótonamente creciente para_CHANGE_SEQUENCE_NUMBER. Los mensajes con números de secuencia inferiores al número de secuencia más alto procesado para una fila no tienen ningún efecto en la fila de la tabla de BigQuery. El número de secuencia debe seguir el formato_CHANGE_SEQUENCE_NUMBER.
Para usar la función con use_table_schema, incluye los campos anteriores en el mensaje JSON.
Para obtener información sobre los precios, consulta Precios por transferencia de datos de CDC de BigQuery.
Tablas de BigLake para Apache Iceberg en BigQuery
Las suscripciones a BigQuery se pueden usar con tablas de BigLake para Apache Iceberg en BigQuery sin necesidad de realizar cambios adicionales.
Las tablas de BigLake para Apache Iceberg en BigQuery proporcionan la base para compilar lakehouses de formato abierto en Cloud de Confiance by S3NS. Estas tablas ofrecen la misma experiencia completamente administrada que las tablas de BigQuery estándar (integradas), pero almacenan datos en buckets de almacenamiento que pertenecen al cliente con Parquet para ser interoperables con los formatos de tablas abiertas de Iceberg.
Para obtener información sobre cómo crear tablas de BigLake para Apache Iceberg en BigQuery , consulta Crea una tabla de Iceberg.
Cómo controlar los errores en los mensajes
Cuando no se puede escribir un mensaje de Pub/Sub en BigQuery, no se puede confirmar el mensaje. Para reenviar esos mensajes que no se pueden entregar, configura un tema de mensajes no entregados en la suscripción de BigQuery. El mensaje de Pub/Sub reenviado al tema de mensajes no entregados contiene un atributo CloudPubSubDeadLetterSourceDeliveryErrorMessage que indica el motivo por el que no se pudo escribir el mensaje de Pub/Sub en BigQuery.
Si Pub/Sub no puede escribir mensajes en BigQuery, Pub/Sub retrocede en la entrega de mensajes de una manera similar al comportamiento de retroceso de la inserción. Sin embargo, si la suscripción tiene un tema de mensajes no entregados adjunto, Pub/Sub no retrocede en la entrega cuando las fallas de mensajes se deben a errores de compatibilidad del esquema.
Cuotas y límites
Existen limitaciones de cuota en el rendimiento del suscriptor de BigQuery por región. Para obtener más información, consulta Cuotas y límites de Pub/Sub.
Las suscripciones de BigQuery escriben datos con la API de BigQuery Storage Write. Para obtener información sobre las cuotas y los límites de la API de Storage Write, consulta las solicitudes de la API de Storage Write. Las suscripciones a BigQuery solo consumen la cuota de capacidad de procesamiento de la API de Storage Write. En este caso, puedes ignorar las demás consideraciones sobre la cuota de la API de Storage Write.
Precios
Para conocer los precios de las suscripciones a BigQuery, consulta la página de precios de Pub/Sub.
¿Qué sigue?
Crea una suscripción, como una suscripción a BigQuery.
Soluciona problemas de una suscripción a BigQuery.
Obtén más información sobre BigQuery.
Revisa los precios de Pub/Sub, incluidas las suscripciones a BigQuery.
Crea o modifica una suscripción con comandos de la CLI de
gcloud.Crea o modifica una suscripción con las APIs de REST.