
Este documento apresenta uma vista geral de uma subscrição do BigQuery, do respetivo fluxo de trabalho e das propriedades associadas.
Uma subscrição do BigQuery é um tipo de subscrição de exportação que escreve mensagens numa tabela do BigQuery existente à medida que são recebidas. Não precisa de configurar um cliente subscritor separado. Use a Cloud de Confiance consola, a CLI Google Cloud, as bibliotecas cliente ou a API Pub/Sub para criar, atualizar, listar, desanexar ou eliminar uma subscrição do BigQuery.
Sem o tipo de subscrição do BigQuery, precisa de uma subscrição de obtenção ou envio e um subscritor (como o Dataflow) que leia as mensagens e as escreva numa tabela do BigQuery. A sobrecarga da execução de uma tarefa do Dataflow não é necessária quando as mensagens não requerem processamento adicional antes de serem armazenadas numa tabela do BigQuery. Em alternativa, pode usar uma subscrição do BigQuery.
No entanto, continua a ser recomendada uma pipeline do Dataflow para sistemas Pub/Sub em que é necessária alguma transformação de dados antes de os dados serem armazenados numa tabela do BigQuery. Para saber como fazer stream de dados do Pub/Sub para o BigQuery com transformação através do Dataflow, consulte o artigo Fazer stream do Pub/Sub para o BigQuery.
O modelo de subscrição do Pub/Sub para o BigQuery do Dataflow aplica a entrega exatamente uma vez por predefinição. Normalmente, isto é conseguido através de mecanismos de remoção de duplicados no pipeline do Dataflow. No entanto, a subscrição do BigQuery só suporta a entrega pelo menos uma vez. Se a eliminação de duplicações exata for fundamental para o seu exemplo de utilização, considere processos posteriores no BigQuery para processar potenciais duplicados.
Antes de começar
Antes de ler este documento, certifique-se de que conhece o seguinte:
Como funciona o Pub/Sub e os diferentes termos do Pub/Sub.
Os diferentes tipos de subscrições que o Pub/Sub suporta e o motivo pelo qual pode querer usar uma subscrição do BigQuery.
Como o BigQuery funciona e como configurar e gerir tabelas do BigQuery.
Fluxo de trabalho de subscrição do BigQuery
A imagem seguinte mostra o fluxo de trabalho entre uma subscrição do BigQuery e o BigQuery.
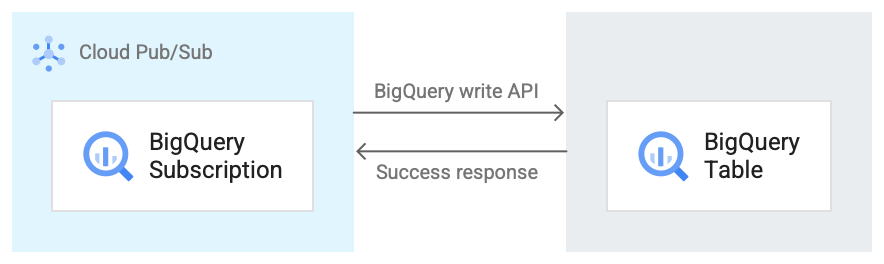
Segue-se uma breve descrição do fluxo de trabalho que faz referência à Figura 1:
- O Pub/Sub usa a API BigQuery Storage Writepara enviar dados para a tabela do BigQuery.
- As mensagens são enviadas em lotes para a tabela do BigQuery.
- Após a conclusão bem-sucedida de uma operação de escrita, a API devolve uma resposta OK.
- Se existirem falhas na operação de escrita, a própria mensagem do Pub/Sub é reconhecida negativamente. A mensagem é, em seguida, reenviada. Se a mensagem falhar vezes suficientes e existir um tópico de mensagens não entregues configurado na subscrição, a mensagem é movida para o tópico de mensagens não entregues.
Propriedades de uma subscrição do BigQuery
As propriedades que configurar para uma subscrição do BigQuery determinam a tabela do BigQuery na qual o Pub/Sub escreve mensagens e o tipo de esquema dessa tabela.
Para mais informações, consulte as propriedades do BigQuery.
Compatibilidade do esquema
Esta secção só é aplicável se selecionar a opção Usar esquema de tópicos quando cria uma subscrição do BigQuery.
O Pub/Sub e o BigQuery usam formas diferentes para definir os respetivos esquemas. Os esquemas do Pub/Sub são definidos no formato Apache Avro ou Protocol Buffer, enquanto os esquemas do BigQuery são definidos através de uma variedade de formatos.
Segue-se uma lista de informações importantes acerca da compatibilidade do esquema entre um tópico do Pub/Sub e uma tabela do BigQuery.
Qualquer mensagem que contenha um campo formatado incorretamente não é escrita no BigQuery.
No esquema do BigQuery,
INT,SMALLINT,INTEGER,BIGINT,TINYINTeBYTEINTsão aliases deINTEGER;DECIMALé um alias deNUMERIC; eBIGDECIMALé um alias deBIGNUMERIC.Quando o tipo no esquema do tópico é
stringe o tipo na tabela do BigQuery éJSON,TIMESTAMP,DATETIME,DATE,TIME,NUMERICouBIGNUMERIC, qualquer valor para este campo numa mensagem do Pub/Sub tem de seguir o formato especificado para o tipo de dados do BigQuery.Alguns tipos lógicos Avro são suportados, conforme especificado na tabela seguinte. Todos os tipos lógicos não listados só correspondem ao tipo Avro equivalente que anotam, conforme detalhado na especificação Avro.
Segue-se uma recolha de mapeamentos de diferentes formatos de esquemas para tipos de dados do BigQuery.
Tipos Avro
| Tipo Avro | Tipo de dados do BigQuery |
null |
Any NULLABLE |
boolean |
BOOLEAN |
int |
INTEGER, NUMERIC ou
BIGNUMERIC |
long |
INTEGER, NUMERIC ou
BIGNUMERIC |
float |
FLOAT64, NUMERIC ou
BIGNUMERIC |
double |
FLOAT64, NUMERIC ou
BIGNUMERIC |
bytes |
BYTES, NUMERIC ou
BIGNUMERIC |
string |
STRING, JSON,
TIMESTAMP, DATETIME,
DATE, TIME,
NUMERIC ou BIGNUMERIC |
record |
RECORD/STRUCT |
array de Type |
REPEATED Type |
map com o tipo de valor ValueType
|
REPEATED STRUCT <key STRING, value
ValueType> |
union com dois tipos, um que é
null e o outro Type |
NULLABLE Type |
outros unions |
Não mapeável |
fixed |
BYTES, NUMERIC ou
BIGNUMERIC |
enum |
INTEGER |
Tipos lógicos Avro
| Tipo lógico Avro | Tipo de dados do BigQuery |
timestamp-micros |
TIMESTAMP |
date |
DATE |
time-micros |
TIME |
duration |
INTERVAL |
decimal |
NUMERIC ou BIGNUMERIC |
Tipos de buffers de protocolo
| Tipo de buffer de protocolo | Tipo de dados do BigQuery |
double |
FLOAT64, NUMERIC ou
BIGNUMERIC |
float |
FLOAT64, NUMERIC ou
BIGNUMERIC |
int32 |
INTEGER, NUMERIC,
BIGNUMERIC ou DATE |
int64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME ou TIMESTAMP |
uint32 |
INTEGER, NUMERIC,
BIGNUMERIC ou DATE |
uint64 |
NUMERIC ou BIGNUMERIC |
sint32 |
INTEGER, NUMERIC ou
BIGNUMERIC |
sint64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME ou TIMESTAMP |
fixed32 |
INTEGER, NUMERIC,
BIGNUMERIC ou DATE |
fixed64 |
NUMERIC ou BIGNUMERIC |
sfixed32 |
INTEGER, NUMERIC,
BIGNUMERIC ou DATE |
sfixed64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME ou TIMESTAMP |
bool |
BOOLEAN |
string |
STRING, JSON,
TIMESTAMP, DATETIME,
DATE, TIME,
NUMERIC ou BIGNUMERIC |
bytes |
BYTES, NUMERIC ou
BIGNUMERIC |
enum |
INTEGER |
message |
RECORD/STRUCT |
oneof |
Não mapeável |
map<KeyType, ValueType> |
REPEATED RECORD<key KeyType, value
ValueType> |
enum |
INTEGER |
repeated/array of Type |
REPEATED Type |
Representação de números inteiros de data e hora
Quando mapeia a partir de um número inteiro para um dos tipos de data ou hora, o número tem de representar o valor correto. Segue-se o mapeamento dos tipos de dados do BigQuery para o número inteiro que os representa.
| Tipo de dados do BigQuery | Representação de números inteiros |
DATE |
O número de dias desde a época Unix, 1 de janeiro de 1970 |
DATETIME |
A data e a hora em microssegundos expressas como hora civil através do CivilTimeEncoder |
TIME |
A hora em microssegundos expressa como hora civil através do CivilTimeEncoder |
TIMESTAMP |
O número de microssegundos desde a época Unix, 1 de janeiro de 1970 às 00:00:00 UTC |
Captura de dados de alterações do BigQuery
As subscrições do BigQuery suportam atualizações de captura de dados de alterações (CDC) quando
use_topic_schema ou
use_table_schema
está definido como true nas propriedades da subscrição. Para usar a funcionalidade com o
use_topic_schema, defina o esquema do tópico com os
seguintes campos:
_CHANGE_TYPE(obrigatório): um campostringdefinido comoUPSERTouDELETE.Se uma mensagem do Pub/Sub escrita na tabela do BigQuery tiver
_CHANGE_TYPEdefinido comoUPSERT, o BigQuery atualiza a linha com a mesma chave, se existir, ou insere uma nova linha, se não existir.Se uma mensagem do Pub/Sub escrita na tabela do BigQuery tiver
_CHANGE_TYPEdefinido comoDELETE, o BigQuery elimina a linha na tabela com a mesma chave, se existir.
_CHANGE_SEQUENCE_NUMBER(opcional): um campostringdefinido para garantir que as atualizações e as eliminações feitas à tabela do BigQuery são processadas por ordem. As mensagens para a mesma chave de linha têm de conter um valor monotonicamente crescente para_CHANGE_SEQUENCE_NUMBER. As mensagens com números de sequência inferiores ao número de sequência mais elevado processado para uma linha não têm qualquer efeito na linha da tabela do BigQuery. O número de sequência tem de seguir o formato_CHANGE_SEQUENCE_NUMBER.
Para usar a funcionalidade com use_table_schema, inclua os campos anteriores na mensagem JSON.
Para informações sobre os preços do CDC, consulte a secção Preços do CDC.
Tabelas do BigLake para o Apache Iceberg no BigQuery
As subscrições do BigQuery podem ser usadas com tabelas do BigLake para Apache Iceberg no BigQuery sem necessidade de alterações adicionais.
As tabelas do BigLake para o Apache Iceberg no BigQuery fornecem a base para criar lakehouses de formato aberto no Cloud de Confiance by S3NS. Estas tabelas oferecem a mesma experiência totalmente gerida que as tabelas do BigQuery padrão (incorporadas), mas armazenam dados em contentores de armazenamento pertencentes ao cliente através do formato Parquet para serem interoperáveis com os formatos de tabelas abertas do Iceberg.
Para obter informações sobre como criar tabelas do BigLake para o Apache Iceberg no BigQuery , consulte o artigo Crie uma tabela do Iceberg.
Resolva falhas de mensagens
Quando não é possível escrever uma mensagem do Pub/Sub no BigQuery, não é possível acusar a receção da mensagem. Para encaminhar essas mensagens não entregues, configure um tópico de mensagens não entregues na subscrição do BigQuery. A mensagem do Pub/Sub encaminhada para o tópico de mensagens rejeitadas contém um atributo CloudPubSubDeadLetterSourceDeliveryErrorMessage que indica o motivo pelo qual não foi possível escrever a mensagem do Pub/Sub no BigQuery.
Se o Pub/Sub não conseguir escrever mensagens no BigQuery, o Pub/Sub recua na entrega de mensagens de forma semelhante ao comportamento de recuo de envio. No entanto, se a subscrição tiver um tópico de mensagens não entregues anexado, o Pub/Sub não recua na entrega quando as falhas de mensagens se devem a erros de compatibilidade de esquemas.
Quotas e limites
Existem limitações de quota na taxa de transferência do subscritor do BigQuery por região. Para mais informações, consulte as quotas e os limites do Pub/Sub.
As subscrições do BigQuery escrevem dados através da API Storage Write do BigQuery. Para informações sobre as quotas e os limites da API Storage Write, consulte os pedidos da API Storage Write do BigQuery. As subscrições do BigQuery apenas consomem a quota de débito da API Storage Write. Pode ignorar as outras considerações sobre a quota da API Storage Write neste caso.
Preços
Para ver os preços das subscrições do BigQuery, consulte a página de preços do Pub/Sub.
O que se segue?
Crie uma subscrição, como uma subscrição do BigQuery.
Resolva problemas de uma subscrição do BigQuery.
Leia acerca do BigQuery.
Reveja os preços do Pub/Sub, incluindo as subscrições do BigQuery.
Crie ou modifique uma subscrição com comandos da
gcloudCLI.Crie ou modifique uma subscrição com APIs REST.