
בדף הזה מובאת סקירה כללית על הגדרת זמינות גבוהה (HA) למופעי Cloud SQL. כדי להגדיר מכונה חדשה לזמינות גבוהה או להפעיל זמינות גבוהה במכונה קיימת, אפשר לעיין במאמר הפעלה והשבתה של זמינות גבוהה במכונה.
סקירה כללית של הגדרת HA
המטרה של הגדרת זמינות גבוהה היא לצמצם את זמן ההשבתה כשאזור או אירוע לא זמינים. זה יכול לקרות במהלך הפסקת חשמל אזורית, או כשיש בעיה בחומרה. בעזרת זמינות גבוהה, הנתונים שלכם ממשיכים להיות זמינים לאפליקציות לקוח.
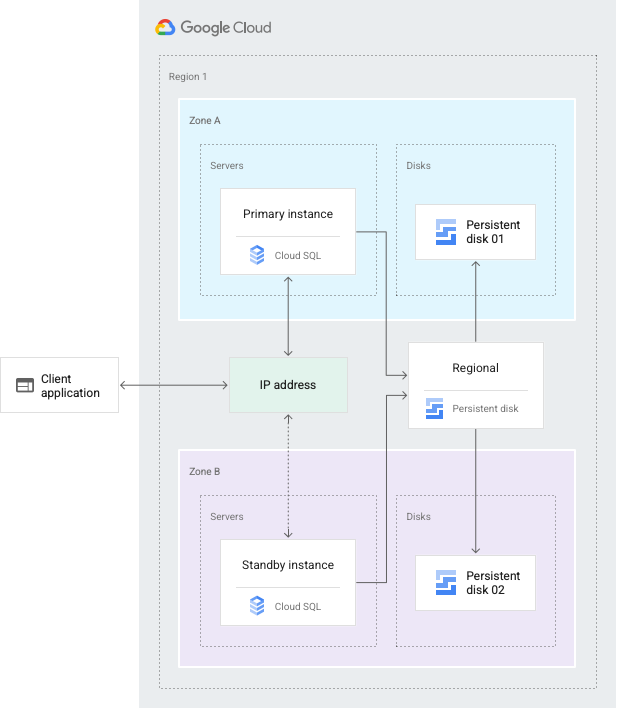
הגדרת HA מספקת יתירות נתונים. מופע Cloud SQL שהוגדר לזמינות גבוהה נקרא גם מופע אזורי, ויש לו אזור ראשי ואזור משני באזור שהוגדר*. בתוך מכונה אזורית, ההגדרה מורכבת ממכונה ראשית וממכונת המתנה. באמצעות שכפול סינכרוני לדיסק אחסון מתמיד (persistent disk) של כל אזור, כל פעולות הכתיבה שמתבצעות במופע הראשי משוכפלות לדיסקים בשני האזורים לפני שמתקבל דיווח על אישור עסקה. במקרה של כשל במופע או באזור, מופע ההמתנה הופך למופע הראשי החדש. לאחר מכן המשתמשים מנותבים מחדש למופע הראשי החדש. התהליך הזה נקרא מעבר לגיבוי.
אחרי מעבר לגיבוי, המופע שקיבל את הגיבוי ממשיך להיות המופע הראשי, גם אחרי שהמופע המקורי חוזר למצב אונליין. אחרי שהאזור או המופע שחוו הפסקה זמנית בשירות חוזרים להיות זמינים, המופע הראשי המקורי מושמד ונוצר מחדש. אחר כך היא הופכת למופע החדש של מצב המתנה. אם בעתיד תתרחש העברה אוטומטית לגיבוי (failover), השרת הראשי החדש יעבור אוטומטית לגיבוי (failover) למופע המקורי באזור המקורי.
אם אתם צריכים שהמופע הראשי יהיה באזור שבו הייתה הפסקה זמנית בשירות, אתם יכולים לבצע מעבר חזרה לאחר כשל. במקרה של חזרה לשגרה, מתבצעים אותם שלבים כמו במעבר לגיבוי, רק בכיוון ההפוך, כדי להפנות מחדש את התנועה בחזרה למופע המקורי. כדי לבצע מעבר חזרה, משתמשים בהליך שמתואר במאמר בנושא הפעלת יתירות כשל.
תמיכה בדיסק אחסון מתמיד (persistent disk) אזורי להגדרת זמינות גבוהה (HA) ב-Cloud SQL עם לפחות מעבד ייעודי אחד, עם כיסוי מלא של הסכם רמת השירות (SLA). מופע עם הגדרת HA עולה פי שניים ממופע עצמאי. המחיר הזה כולל CPU, RAM ואחסון. מידע נוסף זמין בדף המחירים.
* למידע נוסף על שיקולים ספציפיים לאזור, אפשר לעיין במאמר מיקום גיאוגרפי ואזורים.
רפליקות לקריאה
אם הזמינות חשובה לכם ברפליקות לקריאה, אתם יכולים להפעיל HA ברפליקות. כשמקדמים רפליקה כזו להיות המופע הראשי, היא כבר מוגדרת כמופע עם זמינות גבוהה.
במהלך הפסקה זמנית בשירות בתחום, התנועה נעצרת כדי לקרוא רפליקות באותו תחום. אחרי שהאזור יהיה זמין שוב, כל העותקים לקריאה באזור ימשיכו את הרפליקציה מהמופע הראשי. אם העותקים לקריאה לא נמצאים באזור שבו מתרחשת הפסקת שירות, הם מתחברים למכונת הגיבוי כשהיא הופכת למכונה הראשית.
מומלץ להציב חלק מהרפליקות לקריאה באזור אחר מהאזורים שבהם נמצאים המופעים הראשיים והמוכנים למעבר לשלב הבא. לדוגמה, אם יש לכם מופע ראשי באזור A ומופע בהמתנה באזור B, כדאי להציב העתק לקריאה באזור C כדי לשפר את המהימנות. השיטה הזו מבטיחה שרפליקות קריאה ימשיכו לפעול גם אם האזור של המופע הראשי יושבת. כדאי גם להוסיף לוגיקה עסקית באפליקציית הלקוח כדי לשלוח קריאות למופע הראשי כשאין רפליקות לקריאה.
הערה: אי אפשר להשתמש במופע במצב המתנה לשאילתות קריאה. ההגדרה הזו שונה מההגדרה הקודמת של זמינות גבוהה ב-Cloud SQL ל-MySQL.
סקירה כללית של מעבר לשירות גיבוי (Failover)
אם מכונה שהוגדרה לזמינות גבוהה לא מגיבה, Cloud SQL עובר אוטומטית להצגת נתונים מהמכונה במצב המתנה. כדי לראות אם בוצע מעבר לגיבוי, בודקים את היסטוריית המעברים לגיבוי ביומן הפעולות.
מידע נוסף על יצירת שאילתות ב-Logs Explorer אם אתם צריכים מידע מפורט יותר על פעולה מסוימת, כמו המשתמש שביצע את הפעולה, אתם צריכים להפעיל רישום ביומן ביקורת.
לוחצים על הכרטיסיות כדי לראות איך מעבר לגיבוי משפיע על המופע.
רגילה

מעבר לגיבוי (Failover)

אחרי מעבר לשירות גיבוי

חזרה למצב תקין (Failback)
עיבוד
התהליך הבא מתרחש:
המופע או האזור הראשיים נכשלים.
מערכת הדופק בודקת בכל שנייה אם המופע הראשי תקין. אם לא מזוהות כמה פעימות לב, מתחיל מעבר לגיבוי.
עכשיו, כשמתבצע חיבור מחדש, המופע במצב המתנה מציג נתונים.
באמצעות כתובת IP סטטית משותפת עם המופע הראשי, מופע ההמתנה מציג עכשיו נתונים מהאזור המשני.
דרישות
כדי ש-Cloud SQL יאפשר יתירות כשל, ההגדרה צריכה לעמוד בדרישות הבאות:
- המכונה הראשית צריכה להיות במצב פעולה רגיל (לא מושבתת, לא בתחזוקה ולא מבצעת פעולה ממושכת של מכונת Cloud SQL, כמו גיבוי).
- התחום המשני והמופע במצב המתנה צריכים להיות במצב תקין. כשמופע הגיבוי לא מגיב, פעולות המעבר לגיבוי נחסמות. אחרי ש-Cloud SQL מתקן את מכונת ההמתנה והאזור המשני זמין, Cloud SQL מאפשר מעבר לגיבוי.
גיבוי ושחזור
צריך להפעיל גיבויים אוטומטיים ושחזור מערכת מנקודה מסוימת בזמן (PITR) עבור מופעים של זמינות גבוהה, לא כולל רפליקות לקריאה.
אפשרויות שחזור למופעים עצמאיים
מכונות עצמאיות של Cloud SQL לא משוחזרות אוטומטית אחרי הפסקת חשמל אזורית. כדי להקים מחדש מכונה שלא הוגדרה לזמינות גבוהה באזור תקין, צריך לשחזר באופן ידני את כל המכונות באזור. אפשר לשחזר באופן ידני מופע עצמאי מהפסקת חשמל אזורית באמצעות אחת מהאפשרויות הבאות:
מבצעים שחזור מערכת מנקודה מסוימת בזמן (PITR) במכונה למכונה חדשה שיוצרים. כדי להשתמש באפשרות הזו, צריך להפעיל PITR במופע האזורי לפני ההשבתה האזורית. יומני העסקאות של המופע צריכים להיות מאוחסנים ב-Cloud Storage. אם יומני העסקאות מאוחסנים בדיסק, אפשר להעביר אותם ל-Cloud Storage. כדי להשתמש באפשרות הזו, פועלים לפי השלבים במאמר ביצוע PITR במופע לא זמין.
אם למופע יש רפליקה לקריאה באזור אחר, אפשר להעלות את הרפליקה הזו בדרגה כדי להחליף את המופע העצמאי שחווה את ההפסקה זמנית בשירות באזור. כדי להשתמש באפשרות הזו, פועלים לפי השלבים במאמר קידום של העתק.
לגבי שתי האפשרויות, חשוב להתייחס לנקודות הבאות:
יכול להיות שחלק מהעסקאות האחרונות שבוצעו במופע הראשי לא יופיעו במופע החדש ששוחזר. המרווח שבו יכול להיות שעסקאות אבדו הוא היעד להתאוששות מאסון (RPO).
- במקרה של שחזור PITR, ה-RPO הוא בדרך כלל חמש דקות או פחות.
- בקידום של רפליקה לקריאה, ה-RPO משתנה בהתאם לעומס העבודה של מסד הנתונים. מידע נוסף על מעקב אחרי השהיית השכפול ועל צמצום שלה זמין במאמר השהיית שכפול.
אחרי שמבצעים את אחת מאפשרויות השחזור, צריך להגדיר מחדש את כל הלקוחות של המכונות שחוו את ההפסקה הזמנית בשירות האזורית, כי למכונות המשוחזרות יהיו כתובות IP ושמות חיבור שונים.
אפליקציות ומופעים
אין הבדל בין עבודה עם מופעים שאינם HA לבין מופעים מסוג HA, ולכן אין צורך להגדיר את האפליקציה בצורה מסוימת. כשמתרחש יתירות כשל, כל החיבורים הקיימים למופע הראשי ולרפליקות קריאה נסגרים, ויחלפו כ-60 שניות עד שהחיבורים למופע הראשי יתחדשו. האפליקציה מתחברת מחדש באמצעות אותו מחרוזת חיבור או כתובת IP, כך שלא צריך לעדכן את האפליקציה אחרי יתירות כשל.
כדי לראות בדיוק איך היישומים שלכם מושפעים ממעבר לגיבוי, מפעילים מעבר לגיבוי באופן ידני.
זמן השבתה לצורך תחזוקה
אירועי תחזוקה משפיעים על מופעים ראשיים שהוגדרה להם זמינות גבוהה באותו אופן כמו על מופעים אחרים. יכול להיות שהמופעים הראשיים לא יהיו זמינים לפרק זמן קצר. מידע נוסף על ההשפעה של תחזוקה על מופעי HA זמין במאמר איך תחזוקה עובדת. כדי למזער את ההשפעה על השירות, אפשר לשנות את הגדרות התחזוקה כדי לשלוט במועד ההשבתה.
ביצועים
הביצועים של דיסקים לאחסון מתמיד אזורי תלויים בהרבה גורמים. יכול להיות שמספר פעולות הקלט/פלט לשנייה (IOPS) יהיה נמוך יותר בדיסק אחסון מתמיד אזורי בהשוואה לדיסק אחסון מתמיד אזורי. בודקים את הגודל של סוג מכונת ה-VM ואת הקלט והפלט של עומס העבודה. מדד נוסף שכדאי לשים לב אליו הוא זמן האחזור של דיסק אחסון מתמיד אזורי עם כונני SSD, שהוא גבוה יותר מזמן האחזור של דיסק אחסון מתמיד אזורי עם SSD. המשמעות היא שאם עומס העבודה שלכם לא כולל סטרימינג והוא רגיש לזמן אחזור, הוא לא יכול להגיע למגבלת ה-IOPS, כי לדיסק אחסון מתמיד (persistent disk) אזורי עם SSD יש זמן אחזור גבוה יותר מאשר לדיסק אחסון מתמיד (persistent disk) אזורי עם SSD. הסיבה לכך היא הרפליקציה הסינכרונית של הנתונים בכמה אזורים שמעורבים בדיסק אחסון מתמיד אזורי, כדי לספק כמה עותקים של נתונים באזורים באזור מסוים.
אפשרות לזמינות גבוהה ב-MySQL מדור קודם
התהליך הקודם להוספת זמינות גבוהה למופעי MySQL משתמש ברפליקה ליתירות כשל. הפונקציונליות מדור קודם לא זמינה במסוף Cloud de Confiance . אפשר לעיין במאמרים הגדרה בגרסה הקודמת: יצירת מכונה חדשה שמוגדרת לזמינות גבוהה או הגדרה בגרסה הקודמת: הגדרת מכונה קיימת לזמינות גבוהה.
המאמרים הבאים
- הפעלה והשבתה של זמינות גבוהה במופע.
- הפעלת מעבר לגיבוי בעת כשל.
- מידע נוסף על ניהול חיבורים למסדי נתונים
- מידע נוסף על אזורים ותחומים ב-Cloud SQL