
A replicação é a capacidade de criar cópias de uma instância do Cloud SQL ou de uma base de dados no local e transferir o trabalho para as cópias.
Introdução
O motivo principal para usar a replicação é dimensionar a utilização de dados numa base de dados sem degradar o desempenho.
Outros motivos:
- Migrar dados entre regiões
- Migrar dados entre plataformas
- Migrar dados de uma base de dados no local para o Cloud SQL
Além disso, pode ser promovida uma réplica se a instância original ficar danificada.
Quando se refere a uma instância do Cloud SQL, a instância replicada é denominada instância principal e as cópias são denominadas réplicas de leitura. A instância principal e as réplicas de leitura residem no Cloud SQL.
Quando se refere a uma base de dados no local, o cenário de replicação é denominado replicação a partir de um servidor externo. Neste cenário, a base de dados que é replicada é o servidor da base de dados de origem. As cópias que residem no Cloud SQL são denominadas réplicas do Cloud SQL. Também existe uma instância que representa o servidor de base de dados de origem no Cloud SQL denominada instância de representação de origem.
Num cenário de recuperação de desastres, pode promover uma réplica para a converter numa instância principal. Desta forma, pode usá-la em vez de uma instância que esteja numa região com uma indisponibilidade. Também pode promover uma réplica para substituir uma instância danificada.
O Cloud SQL suporta os seguintes tipos de réplicas:
- Ler réplicas
- Réplicas de leitura entre regiões
- Réplicas de leitura em cascata
- Réplicas de leitura externas
- Réplicas do Cloud SQL, quando replicam a partir de um servidor externo
Ao usar a aplicação de conetores, pode aplicar a utilização apenas do proxy Auth do Cloud SQL ou dos conetores de linguagem do Cloud SQL para estabelecer ligação a instâncias do Cloud SQL. Com a aplicação do conetor, o Cloud SQL rejeita ligações diretas à base de dados. Não pode criar réplicas de leitura para uma instância com a aplicação do conector ativada. Da mesma forma, se uma instância tiver réplicas de leitura, não pode ativar a aplicação de conetores para a instância.
Também pode usar o Database Migration Service para a replicação contínua de um servidor de base de dados de origem para o Cloud SQL.O Cloud SQL não suporta a replicação entre dois servidores externos.
No entanto, o Cloud SQL suporta a replicação baseada no identificador de transação global (GTID).
Os GTIDs identificam exclusivamente cada transação no servidor e numa configuração de replicação. Uma vez que cada transação tem um identificador exclusivo, o servidor MySQL pode acompanhar as transações que executou. Um GTID usa coordenadas absolutas, pelo que a réplica de uma instância do Cloud SQL pode apontar para a respetiva instância principal, e não tem de especificar um nome de ficheiro para o registo binário nem uma posição na declaração CHANGE MASTER. Existem menos erros
com réplicas e com a recuperação num ponto específico no tempo. Devido a estas vantagens,
não pode desativar a replicação baseada em GTID no Cloud SQL.
Réplicas de leitura
Usa uma réplica de leitura para descarregar trabalho de uma instância do Cloud SQL. A réplica de leitura é uma cópia exata da instância principal. Os dados e outras alterações na instância principal são atualizados quase em tempo real na réplica de leitura.
As réplicas de leitura são só de leitura; não pode escrever nelas. A réplica de leitura processa consultas, pedidos de leitura e tráfego de estatísticas, reduzindo assim a carga na instância principal.
Estabelece ligação a uma réplica diretamente através do respetivo nome de ligação e endereço IP. Se estiver a estabelecer ligação a uma réplica através de um endereço IP privado, não precisa de criar uma ligação privada de VPC adicional para a réplica, porque a ligação é herdada da instância principal.
Para obter informações sobre como criar uma réplica de leitura, consulte o artigo Criar réplicas de leitura. Para ver informações sobre a gestão de uma réplica de leitura, consulte o artigo Gerir réplicas de leitura.
Como prática recomendada, coloque as réplicas de leitura numa zona diferente da instância principal quando usar a HA na instância principal. Esta prática garante que as réplicas de leitura continuam a funcionar quando a zona que contém a instância principal tem uma indisponibilidade. Consulte a Vista geral da elevada disponibilidade para mais informações.
Selecionar um tipo de máquina adequado
As réplicas de leitura podem ter um número diferente de vCPUs e memória em relação ao primário. Deve monitorizar as métricas na sua instância, como a utilização de CPU e memória, para garantir que a instância de réplica tem o tamanho correto para a respetiva carga de trabalho, especialmente se for mais pequena do que a instância principal. Uma instância de réplica com tamanho inferior ao necessário é mais propensa a um desempenho fraco, como eventos frequentes de falta de memória (OOM).
Capacidade de armazenamento em réplicas de leitura
Quando uma instância principal é redimensionada, todas as respetivas réplicas de leitura são redimensionadas, se necessário, para terem, pelo menos, a mesma capacidade de armazenamento que a instância principal atualizada.
Réplicas de leitura entre regiões
A replicação entre regiões permite-lhe criar uma réplica de leitura numa região diferente da instância principal. Crie uma réplica de leitura entre regiões da mesma forma que cria uma réplica na região.
Réplicas entre regiões:
- Melhore o desempenho de leitura disponibilizando réplicas mais perto da região da sua aplicação.
- Oferecer capacidade de recuperação de desastres adicional para proteção contra uma falha regional.
- Permitem-lhe migrar dados de uma região para outra.
Consulte o artigo Promover réplicas para migração regional ou recuperação de desastres para mais informações sobre réplicas entre regiões.
Réplicas de leitura em cascata
A replicação em cascata permite-lhe criar uma réplica de leitura sob outra réplica de leitura na mesma região ou numa região diferente. Os seguintes cenários são exemplos de utilização de réplicas em cascata:
- Recuperação de desastres: pode usar uma hierarquia em cascata de réplicas de leitura para simular a topologia da sua instância principal e das respetivas réplicas de leitura. Durante uma interrupção, a réplica de leitura selecionada é promovida a principal e as réplicas de leitura na nova principal continuam a ser replicadas e estão prontas para utilização.
- Melhorias no desempenho: reduza a carga na instância principal transferindo o trabalho de replicação para várias réplicas de leitura.
- Escalar leituras: pode ter mais réplicas para partilhar a carga de leitura.
- Redução de custos: pode reduzir os custos de rede usando uma única réplica em cascata com replicação entre regiões noutras regiões.
Terminologia
- Réplica em cascata: uma réplica de leitura que pode ter a sua própria réplica.
- Níveis: pode criar níveis de réplicas numa hierarquia de réplicas em cascata. Por exemplo, se adicionar quatro réplicas a uma instância, essas quatro réplicas estão ao mesmo nível.
- Instâncias secundárias: várias réplicas que são replicadas a partir da mesma instância principal. Os irmãos estão no mesmo nível na hierarquia da réplica. Uma réplica pode ter oficialmente até oito irmãos.
- Réplica folha: uma réplica de leitura que não tem réplicas próprias. Numa hierarquia de replicação de vários níveis, a réplica de folha é o último nível.
- Promover: uma ação que converte uma réplica, a qualquer nível na hierarquia, numa instância principal. Quando é promovida, a hierarquia de réplicas em cascata da réplica é mantida.
Configure réplicas em cascata
As réplicas em cascata permitem-lhe adicionar réplicas de leitura a quaisquer réplicas existentes. Pode adicionar até quatro níveis de réplicas, incluindo a instância principal. Quando promove a réplica na parte superior de uma hierarquia de réplicas em cascata, esta torna-se uma instância principal e as respetivas réplicas em cascata continuam a ser replicadas.
Para planear a sua configuração, tem de ter um objetivo para o que as réplicas de leitura se destinam a fazer. As duas secções seguintes descrevem as configurações para recuperação de desastres e replicação em várias regiões.
Recuperação de desastres
Para compreender como as réplicas em cascata ajudam a recuperar rapidamente durante uma indisponibilidade, considere o seguinte cenário de replicação:
Configuração
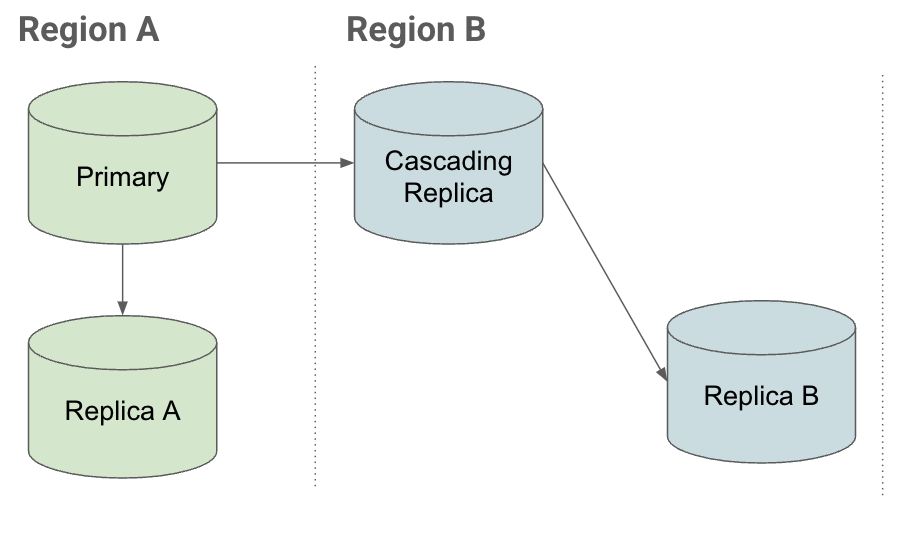
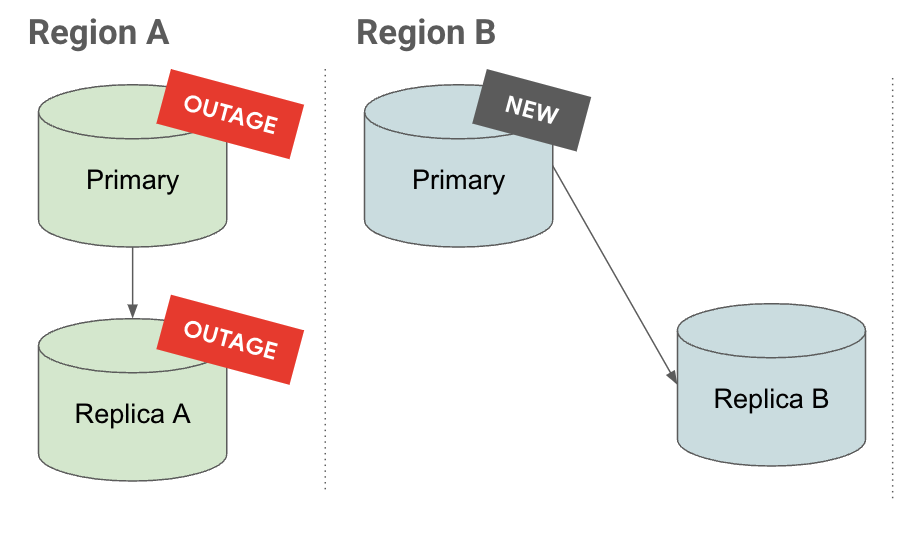
Indisponível
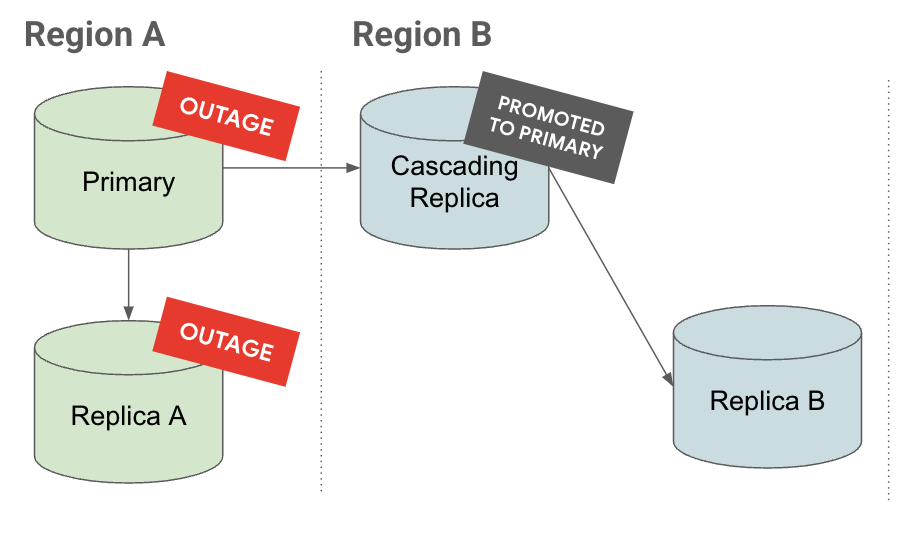
Promoção
Se quiser usar uma instância na região B numa configuração de recuperação de desastres e tiver:
- Réplicas na mesma região anexadas à instância principal (Réplica A)
- Réplicas noutras regiões (réplica em cascata) anexadas à principal.
Pode criar réplicas de leitura na réplica em cascata na região B.
No separador Interrupção, se houver uma interrupção na região A, a réplica em cascata é promovida a uma instância principal. Já tem réplicas de leitura abaixo, o que reduz o objetivo de tempo de recuperação (RTO).
No separador Promover, vê que, quando uma réplica em cascata é promovida, as respetivas réplicas também são promovidas e continuam a ser replicadas abaixo da mesma.
Replicação multirregião
Outro exemplo de utilização de réplicas em cascata é distribuir a capacidade de leitura para uma segunda região de forma rentável. É possível criar réplicas em cascata C e D que replicam a partir da réplica B. Os clientes podem distribuir consultas de leitura por réplicas B, C e D para reduzir a carga em cada réplica. O custo do tráfego de rede entre regiões é incorrido apenas uma vez, da instância principal para a réplica B. A replicação de B para C e D usa a transferência de rede na região, que é gratuita.
Pode criar uma hierarquia de até quatro instâncias usando réplicas em cascata para a replicação em várias regiões:
Principal A → Réplica B → Réplica C e Réplica D
Restrições
- Não é possível eliminar uma réplica que tenha réplicas abaixo. Para eliminar a réplica, tem de começar pelas réplicas de folhas e avançar na hierarquia.
- A dependência de regiões circulares não é suportada. Para ter a réplica de uma réplica em cascata na mesma região que a instância principal, a réplica em cascata também tem de estar na mesma região.
Réplicas de leitura externas
As réplicas de leitura externas são instâncias do MySQL externas que são replicadas a partir de uma instância principal do Cloud SQL. Por exemplo, uma instância do MySQL em execução no Compute Engine é considerada uma instância externa.
As réplicas de leitura externas têm as seguintes restrições:
- O servidor principal da réplica externa não pode ser uma réplica de leitura do Cloud SQL.
- A replicação para uma instância do MySQL alojada por outra plataforma na nuvem pode não ser possível. Consulte a documentação do outro fornecedor. Por exemplo, é necessário definir o campo de configuração
replicate-ignore-dbe os fornecedores de nuvem em que isto não é permitido não são suportados. Consulte o artigo Configurar réplicas externas para ver outros campos de configuração necessários. - Se a replicação for interrompida durante algumas horas, por exemplo, devido a uma falha de rede ou do servidor, a réplica fica atrás da principal. A réplica fica atualizada assim que se voltar a ligar ao servidor principal e começar a replicar novamente. No entanto, se a replicação for interrompida durante mais tempo do que os registos de replicação do Cloud SQL são preservados (sete cópias de segurança), tem de eliminar a réplica e criar uma nova.
- Os dados transferidos da réplica principal para a réplica externa são cobrados como transferência de dados de saída. Consulte a página de preços para ver os preços de transferência de dados para o seu tipo de instância do Cloud SQL.
Se criar uma réplica de leitura externa para uma instância e aplicar a utilização apenas do proxy Auth do Cloud SQL ou dos conectores de linguagem do Cloud SQL para estabelecer ligação a uma instância que tenha o acesso privado a serviços configurado, tem de adicionar os intervalos de sub-redes da réplica às redes autorizadas da instância principal. Tem de configurar todos os intervalos como redes autorizadas da instância do Cloud SQL.
gcloud
Para definir a autorização de IP para uma instância de modo a permitir o tráfego de intervalos de endereços IP de uma réplica de leitura externa, use o comando
gcloud sql instances patch:gcloud sql instances patch \ --authorized-networks=IP_ADDRESS_RANGE_1/24,IP_ADDRESS_RANGE_2/24
Substitua IP_ADDRESS_RANGE_1 e IP_ADDRESS_RANGE_2 pelos intervalos de endereços IP da sua réplica de leitura externa.
REST
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
- PROJECT_ID: o ID ou o número do projeto do Cloud de Confiance projeto que contém a instância
- INSTANCE_NAME: o nome da sua instância do Cloud SQL
- IP_ADDRESS_RANGE_1: o primeiro intervalo de endereços IP da sua réplica de leitura externa
- IP_ADDRESS_RANGE_2: o segundo intervalo de endereços IP da sua réplica de leitura externa
Método HTTP e URL:
PATCH https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/instances/INSTANCE_NAME
Corpo JSON do pedido:
{ "kind": "sql#instance", "name": INSTANCE_NAME, "project": PROJECT_ID, "settings": { "ipConfiguration": { "authorizedNetworks": [{"kind": "sql#aclEntry", "value": "IP_ADDRESS_RANGE_1/24"}, {"kind": "sql#aclEntry", "value": "IP_ADDRESS_RANGE_2/24"}]}, "kind": "sql#settings" } }Para enviar o seu pedido, expanda uma destas opções:
Deve receber uma resposta JSON semelhante à seguinte:
{ "kind": "sql#operation", "targetLink": "https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/instances/INSTANCE_NAME", "status": "PENDING", "user": "user@example.com", "insertTime": "2020-01-16T02:32:12.281Z", "operationType": "UPDATE", "name": "OPERATION_ID", "targetId": "INSTANCE_NAME", "selfLink": "https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/operations/OPERATION_ID", "targetProject": "PROJECT_ID" }
Exemplos de utilização de replicação
Os seguintes exemplos de utilização aplicam-se a cada tipo de replicação.
| Nome | Primary | Réplica | Vantagens e exemplos de utilização | Mais informações |
|---|---|---|---|---|
| Ler réplica | Instância do Cloud SQL | Instância do Cloud SQL |
|
|
| Réplica de leitura entre regiões | Instância do Cloud SQL | Instância do Cloud SQL |
|
|
| Réplica de leitura externa | Instância autónoma ou principal do Cloud SQL | Instância do MySQL externa ao Cloud SQL |
|
|
| Replicação a partir de um servidor externo | Instância do MySQL externa ao Cloud SQL | Instância do Cloud SQL para MySQL |
|
Pré-requisitos para criar uma réplica de leitura
Antes de poder criar uma réplica de leitura de uma instância principal do Cloud SQL, a instância tem de cumprir os seguintes requisitos:
- As cópias de segurança automáticas têm de estar ativadas.
- O registo binário tem de estar ativado, o que requer que a recuperação num determinado momento esteja ativada. Saiba mais sobre o impacto destes registos.
- Tem de ter sido criada, pelo menos, uma cópia de segurança depois de o registo binário ter sido ativado.
Requisitos adicionais para a réplica externa:
- A versão do MySQL da réplica tem de ser igual ou superior à versão do MySQL da instância principal. Saiba mais.
- Por motivos de segurança, tem de configurar o SSL/TLS na sua instância principal. Saiba mais.
Impacto da ativação do registo binário
Tem de ativar a recuperação num determinado momento para ativar o registo binário na instância principal para suportar réplicas de leitura. Isto tem os seguintes impactos:
- Sobrecarga de desempenho
O Cloud SQL usa a replicação baseada em linhas com flags do MySQL
sync_binlog=1einnodb_support_xa=true. Por conseguinte, é necessária uma fsync adicional no disco para cada operação de escrita, o que reduz o desempenho. - Sobrecarga de armazenamento
O armazenamento dos registos binários é cobrado à mesma taxa que os dados normais. Os registos binários são automaticamente truncados até à idade da cópia de segurança automatizada mais antiga. O Cloud SQL retém as sete cópias de segurança automáticas mais recentes e todas as cópias de segurança a pedido. O tamanho dos registos binários e, por conseguinte, o valor cobrado, depende da carga de trabalho. Por exemplo, uma carga de trabalho com muitas escritas consome mais espaço do registo binário do que uma carga de trabalho com muitas leituras.
Pode ver o tamanho dos registos binários através do comando MySQL SHOW BINARY LOGS.
Quando são feitas cópias de segurança, os registos são armazenados na cópia de segurança juntamente com os dados.
Registo binário em réplicas de leitura
- O registo binário é suportado em instâncias de réplica de leitura (apenas MySQL 5.7 e 8.0). Ativa o registo binário numa réplica com os mesmos comandos da API que no servidor principal, usando o nome da instância da réplica em vez do nome da instância principal. Tenha em atenção que os termos
enable binary loggingeenable point-in-time recoverysão intermutáveis.A durabilidade do registo binário na instância da réplica (mas não na instância principal) pode ser definida com a flag
sync_binlog, que controla a frequência com que o servidor MySQL sincroniza o registo binário com o disco.O registo binário pode ser ativado numa réplica, mesmo quando a cópia de segurança está desativada no servidor principal.
Se uma réplica que tenha este valor definido for promovida a um servidor autónomo, a definição é reposta para o valor seguro
1no servidor autónomo.
Faturação
- Uma réplica de leitura é cobrada à mesma taxa que uma instância padrão do Cloud SQL. Não existe qualquer custo financeiro para a replicação de dados.
- Para réplicas externas, os dados transferidos da réplica principal para a réplica externa são cobrados como transferência de dados. Consulte a página de preços para ver os preços de transferência de dados para o seu tipo de instância do Cloud SQL.
- O preço de uma réplica de leitura entre regiões é o mesmo que o de criar uma nova instância do Cloud SQL na região. Consulte os preços das instâncias do Cloud SQL e selecione a região adequada. Além do custo normal associado à instância, uma réplica entre regiões incorre em encargos de transferência de dados entre regiões para registos de replicação enviados da instância principal para a instância de réplica, conforme descrito em Preços de saída da rede.
Referência rápida para réplicas de leitura do Cloud SQL
| Tópico | Debate |
|---|---|
| Cópias de segurança | Não pode configurar cópias de segurança na réplica. |
| Núcleos e memória | As réplicas de leitura podem usar um número diferente de núcleos e uma quantidade de memória dos da instância principal. |
| Eliminar a instância principal | Antes de poder eliminar uma instância principal, tem de promover todas as respetivas réplicas de leitura a instâncias autónomas ou eliminar as réplicas de leitura. |
| Eliminar a réplica | Quando elimina uma réplica, não existe qualquer impacto no estado da instância principal. |
| Desativar o registo binário | Antes de poder desativar os registos binários numa instância principal, tem de promover ou eliminar todas as respetivas réplicas de leitura. |
| Failover | Uma instância principal só pode fazer failover para uma réplica se esta for uma réplica de recuperação de desastres. As réplicas de leitura não conseguem fazer failover de forma alguma durante uma indisponibilidade. |
| Alta disponibilidade | As réplicas de leitura permitem-lhe ativar a alta disponibilidade nas réplicas. |
| Balanceamento de carga | O Cloud SQL não oferece equilíbrio de carga entre réplicas. Pode optar por implementar o equilíbrio de carga para a sua instância do Cloud SQL. Também pode usar a agrupamento de ligações para distribuir consultas por réplicas com a configuração de equilíbrio de carga para um melhor desempenho. |
| Períodos de manutenção | As réplicas de leitura partilham os períodos de manutenção com a instância principal. As réplicas seguem as definições de manutenção da instância principal, incluindo o período de manutenção, o reagendamento e o período de manutenção recusado. Durante a manutenção, o Cloud SQL atualiza primeiro todas as réplicas de leitura antes de atualizar a instância principal. |
| Várias réplicas de leitura | O Cloud SQL suporta réplicas em cascata. Como resultado, pode criar até 10 réplicas para uma única instância principal e criar réplicas dessas réplicas, até quatro níveis, incluindo a instância principal. |
| Replicação paralela | Para informações sobre a utilização da replicação paralela para melhorias de desempenho, consulte o artigo Configurar a replicação paralela. |
| IP privado | Se estiver a estabelecer ligação a uma réplica através de um endereço IP privado, não precisa de criar uma ligação privada de VPC adicional para a réplica, uma vez que é herdada da instância principal. |
| Restaurar a instância principal | Não pode restaurar a instância principal de uma réplica enquanto a réplica existir. Antes de restaurar uma instância a partir de uma cópia de segurança ou executar uma recuperação num determinado momento, tem de promover ou eliminar todas as respetivas réplicas. |
| Definições | As definições do MySQL da instância principal são propagadas para a réplica, incluindo a palavra-passe de raiz e as alterações à tabela de utilizadores. As alterações à CPU e à memória não são propagadas para a réplica. |
| Parar uma réplica | Não pode stop uma réplica. Pode restart,
delete ou disable replication, mas não pode
pará-la como faria com uma instância principal. |
| Atualizar uma réplica | As réplicas de leitura podem sofrer uma atualização disruptiva em qualquer altura. |
| Tabelas de utilizadores | Não pode fazer alterações na réplica. Todas as alterações de utilizadores têm de ser feitas na instância principal. |
O que se segue?
- Saiba como criar uma réplica de leitura.
- Saiba como configurar uma configuração de réplica externa.
- Saiba como replicar os seus dados a partir de um servidor externo.
- Saiba como configurar uma configuração de servidor externo.
- Saiba mais sobre a replicação no MySQL.
- Saiba como configurar uma instância para alta disponibilidade.
- Saiba mais sobre a recuperação de desastres (RD) avançada