
将 Hive 托管式表迁移到 Cloud de Confiance
本文档介绍了如何将 Hive 托管式表迁移到 Cloud de Confiance。
您可以使用 BigQuery Data Transfer Service 中的 Hive 托管式表迁移连接器,将由 Hive metastore 管理的表从本地环境和云环境无缝迁移到 Cloud de Confiance,支持 Hive 和 Iceberg 格式。我们支持在 HDFS 或 Amazon S3 上存储文件。
借助 Hive 托管式表迁移连接器,您可以向 Dataproc Metastore、BigLake metastore 或 BigLake metastore Iceberg REST 目录注册 Hive 托管式表,同时使用 Cloud Storage 作为文件存储。
下图提供了从 Hadoop 集群迁移表的过程概览。
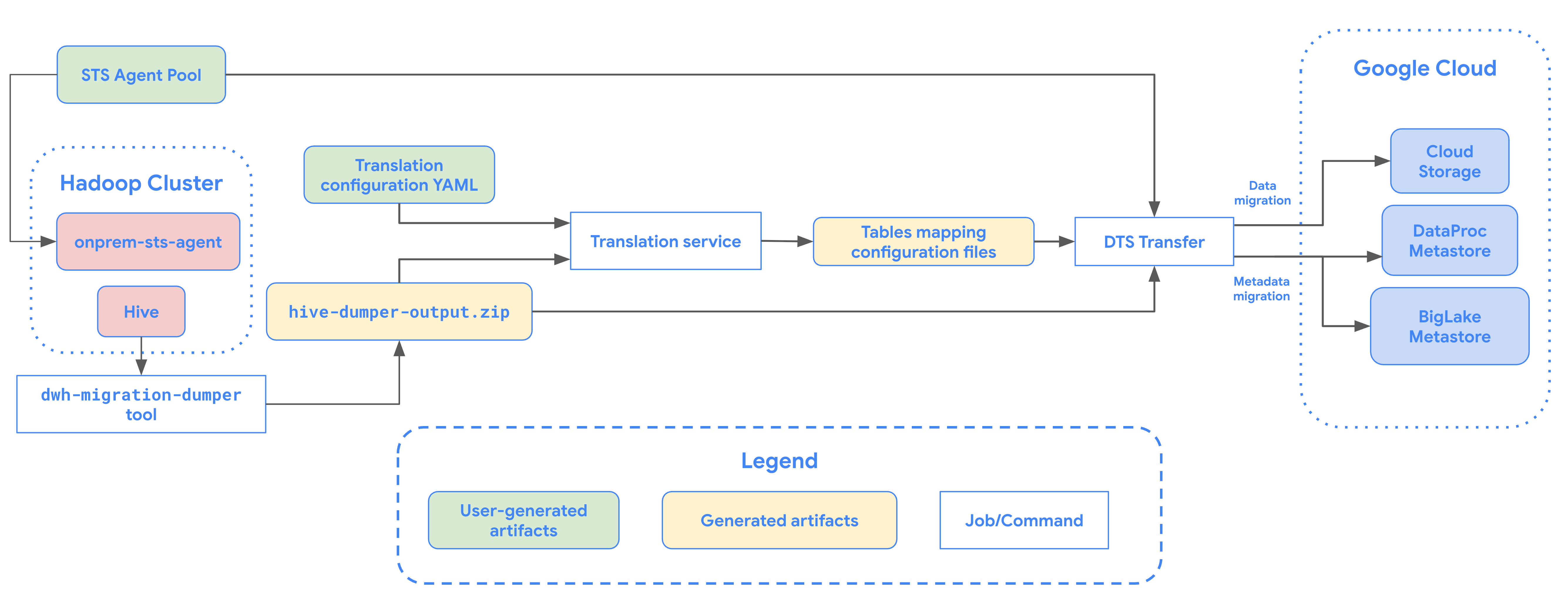
限制
Hive 托管式表转移作业存在以下限制:
- 如需迁移 Apache Iceberg 表,您必须向 BigLake metastore 注册这些表,以允许开源引擎(例如 Apache Spark 或 Flink)进行写入访问,并允许 BigQuery 进行读取访问。
- 如需迁移 Hive 托管式表,您必须向 Dataproc Metastore 注册这些表,以允许开源引擎进行写入访问,并允许 BigQuery 进行读取访问。
- 您必须使用 bq 命令行工具将 Hive 托管式表迁移到 BigQuery。
准备工作
在安排 Hive 托管式表转移作业之前,您必须执行以下操作:
为 Apache Hive 生成元数据文件
运行 dwh-migration-dumper 工具以提取元数据(针对 Apache Hive)。该工具会生成一个名为 hive-dumper-output.zip 的文件,并将其保存到 Cloud Storage 存储桶(在本文档中称为 DUMPER_BUCKET)。
启用 API
在Cloud de Confiance 项目中启用以下 API:
- Data Transfer API
- Storage Transfer API
启用 Data Transfer API 后,系统会创建一个服务代理。
配置权限
- 创建一个服务账号,并向其授予 BigQuery Admin 角色 (
roles/bigquery.admin)。此服务账号用于创建转移作业配置。 启用 Data Transfer API 后,系统会创建一个服务代理 (P4SA)。向其授予以下角色:
roles/metastore.metadataOwnerroles/storagetransfer.adminroles/serviceusage.serviceUsageConsumerroles/storage.objectAdmin- 如果您要迁移 BigLake Iceberg 表的元数据,还必须授予
roles/bigquery.admin角色。 - 如果您要将元数据迁移到 BigLake metastore Iceberg REST 目录,还必须授予
roles/biglake.admin角色。
- 如果您要迁移 BigLake Iceberg 表的元数据,还必须授予
使用以下命令向服务代理授予
roles/iam.serviceAccountTokenCreator角色:gcloud iam service-accounts add-iam-policy-binding SERVICE_ACCOUNT --member serviceAccount:service-PROJECT_NUMBER@gcp-sa-bigquerydatatransfer.s3ns-system.iam.gserviceaccount.com --role roles/iam.serviceAccountTokenCreator
为 HDFS 数据湖配置存储转移代理
当文件存储在 HDFS 中时,此参数为必需参数。如需设置 HDFS 数据湖转移作业所需的存储转移代理,请执行以下操作:
- 配置权限,以便在 Hadoop 集群上运行存储转移代理。
- 在本地代理机器上安装 Docker。
- 在 Cloud de Confiance by S3NS 项目中创建 Storage Transfer Service 代理池。
- 在本地代理机器上安装代理。
为 Amazon S3 配置 Storage Transfer Service 权限
如果文件存储在 Amazon S3 中,则为必需。从 Amazon S3 转移数据属于无代理转移,需要特定权限。如需为 Amazon S3 转移作业配置 Storage Transfer Service,请执行以下操作:
- 配置无代理转移权限。
- 为 AWS Amazon S3 设置访问凭证。
- 设置访问凭证后,请记下访问密钥 ID 和私有访问密钥。
- 如果您的 AWS 项目使用 IP 限制,请将 Storage Transfer Service 工作器使用的 IP 范围添加到允许的 IP 列表。
安排 Hive 托管式表转移
从下列选项中选择一项:
控制台
前往 Cloud de Confiance 控制台中的“数据转移”页面。
点击 创建转移作业。
在来源类型部分的来源列表中选择 Hive 托管式表。
在位置中,选择位置类型,然后选择区域。
在转移配置名称部分的显示名称中,输入数据转移作业的名称。
在时间表选项部分,执行以下操作:
- 在重复频率列表中,选择一个选项来指定此数据转移作业的运行频率。如需指定自定义重复频率,请选择自定义。如果您选择按需,则当您手动触发转移作业时,此转移作业会运行。
- 如果适用,请选择立即开始或在设置的时间开始,并提供开始日期和运行时间。
在数据源详细信息部分,执行以下操作:
- 在表名称模式字段中,通过提供与 HDFS 数据库中的表匹配的表名称或模式来指定要转移的 HDFS 数据湖表。您必须使用 Java 正则表达式语法来指定表模式。例如:
db1..*匹配 db1 中的所有表。db1.table1;db2.table2匹配 db1 中的 table1 和 db2 中的 table2。
- 对于 BQMS 发现转储 GCS 路径,请输入包含您在为 Apache Hive 创建元数据文件时生成的
hive-dumper-output.zip文件的相应存储桶的路径。 - 从下拉列表中选择 Metastore 类型:
DATAPROC_METASTORE:选择此选项可在 Dataproc Metastore 中存储元数据。您必须在 Dataproc metastore url 中提供 Dataproc Metastore 的网址。BIGLAKE_METASTORE:选择此选项可在 BigLake metastore 中存储元数据。您必须在 BigQuery 数据集中提供 BigQuery 数据集。BIGLAKE_REST_CATALOG:选择此选项可将元数据存储在 BigLake metastore Iceberg REST 目录中。
在目标 GCS 路径部分,输入 Cloud Storage 存储桶的路径,以存储迁移的数据。
可选:在服务账号字段中,输入要用于此数据转移作业的服务账号。该服务账号应属于在其中创建转移作业配置和目标数据集的同一Cloud de Confiance by S3NS 项目。
可选:您可以启用使用转换输出,为每个迁移的表设置唯一的 Cloud Storage 路径和数据库。为此,请在 BQMS 转换输出 GCS 路径字段中提供包含转换结果的 Cloud Storage 文件夹的路径。如需了解详情,请参阅配置转换输出。
- 如果您指定转换输出 Cloud Storage 路径,系统将从该路径中的文件获取目标 Cloud Storage 路径和 BigQuery 数据集。
对于存储类型,请选择以下选项之一:
HDFS:如果您的文件存储空间为HDFS,请选择此选项。在 STS 代理池名称字段中,您必须提供在配置 Storage Transfer Agent 时创建的代理池的名称。S3:如果您的文件存储空间为Amazon S3,请选择此选项。在访问密钥 ID 和私有访问密钥字段中,您必须提供在设置访问凭证时创建的访问密钥 ID 和私有访问密钥。
- 在表名称模式字段中,通过提供与 HDFS 数据库中的表匹配的表名称或模式来指定要转移的 HDFS 数据湖表。您必须使用 Java 正则表达式语法来指定表模式。例如:
bq
如需安排 Hive 托管式表转移作业,请输入 bq mk 命令并提供转移作业创建标志 --transfer_config:
bq mk --transfer_config --data_source=hadoop --display_name='TRANSFER_NAME' --service_account_name='SERVICE_ACCOUNT' --project_id='PROJECT_ID' --location='REGION' --params='{"table_name_patterns":"LIST_OF_TABLES", "table_metadata_path":"gs://DUMPER_BUCKET/hive-dumper-output.zip", "target_gcs_file_path":"gs://MIGRATION_BUCKET", "metastore":"METASTORE", "destination_dataproc_metastore":"DATAPROC_METASTORE_URL", "destination_bigquery_dataset":"BIGLAKE_METASTORE_DATASET", "translation_output_gcs_path":"gs://TRANSLATION_OUTPUT_BUCKET/metadata/config/default_database/", "storage_type":"STORAGE_TYPE", "agent_pool_name":"AGENT_POOL_NAME", "aws_access_key_id":"AWS_ACCESS_KEY_ID", "aws_secret_access_key":"AWS_SECRET_ACCESS_KEY" }'
替换以下内容:
TRANSFER_NAME:此标志表示转移配置的显示名称。转移作业名称可以是任何易于识别该作业的值,以便您以后在需要修改时找到作业。SERVICE_ACCOUNT:用于对转移作业进行身份验证的服务账号名称。该服务账号应属于用于创建转移作业的同一project_id,并且应具有所有所需的权限。PROJECT_ID:您的 Cloud de Confiance by S3NS 项目 ID。 如果未提供--project_id来指定具体项目,则系统会使用默认项目。REGION:此转移作业配置的位置。LIST_OF_TABLES:要转移的实体列表。使用分层命名规范 -database.table。此字段支持使用 RE2 正则表达式指定表。例如:db1..*:指定数据库中的所有表db1.table1;db2.table2:表的列表
DUMPER_BUCKET:包含hive-dumper-output.zip文件的 Cloud Storage 存储桶。MIGRATION_BUCKET:所有底层文件将加载到的目标 GCS 路径。METASTORE:要迁移到的元存储区类型。请将此项设置为以下值之一:DATAPROC_METASTORE:用于将元数据转移到 Dataproc Metastore。BIGLAKE_METASTORE:将元数据转移到 BigLake metastore。BIGLAKE_REST_CATALOG:将元数据转移到 BigLake metastore Iceberg REST 目录。
DATAPROC_METASTORE_URL:Dataproc Metastore 的网址。如果metastore为DATAPROC_METASTORE,则必须提供此值。BIGLAKE_METASTORE_DATASET:BigLake metastore 的 BigQuery 数据集。如果metastore为BIGLAKE_METASTORE,则必须提供此值。TRANSLATION_OUTPUT_BUCKET:(可选)指定用于存储转换输出的 Cloud Storage 存储桶。如需了解详情,请参阅使用转换输出。STORAGE_TYPE:指定表的底层文件存储。支持的类型为HDFS和S3。AGENT_POOL_NAME:用于创建代理的代理池的名称。 如果storage_type为HDFS,则必须提供此值。AWS_ACCESS_KEY_ID:访问凭证中的访问密钥 ID。如果storage_type为S3,则必须设置此字段。AWS_SECRET_ACCESS_KEY:访问凭证中的私有访问密钥。如果storage_type为S3,则必须设置此字段。
运行此命令以创建转移作业配置并启动 Hive 托管式表转移作业。默认情况下,转移作业安排为每 24 小时运行一次,但可以通过转移作业安排选项进行配置。
转移作业完成后,Hadoop 集群中的表将迁移到 MIGRATION_BUCKET。
数据注入选项
以下部分详细介绍了如何配置 Hive 托管式表转移作业。
增量转移
如果转移作业配置是按周期性时间表设置的,则每个后续转移作业都会使用对源表进行的最新更新来更新 Cloud de Confiance by S3NS 上的表。例如在每个转移作业中,所有包含架构更改的插入、删除或更新操作都会在 Cloud de Confiance by S3NS 中得到反映。
转移作业安排选项
默认情况下,转移作业安排为每 24 小时运行一次。如需配置转移作业的运行频率,请将 --schedule 标志添加到转移作业配置中,并使用 schedule 语法指定转移作业时间表。Hive 托管式表转移作业的运行间隔时间必须至少为 24 小时。
对于一次性转移作业,您可以向转移作业配置添加 end_time 标志,以便仅运行一次转移作业。
配置转换输出
您可以为每个迁移的表配置唯一的 Cloud Storage 路径和数据库。为此,请执行以下步骤来生成表映射 YAML 文件,以便在转移配置中使用。
在
DUMPER_BUCKET中创建一个配置 YAML 文件(以config.yaml为后缀),其中包含以下内容:type: object_rewriter relation: - match: relationRegex: ".*" external: location_expression: "'gs://MIGRATION_BUCKET/' + table.schema + '/' + table.name"
- 将
MIGRATION_BUCKET替换为所迁移表文件的目标 Cloud Storage 存储桶的名称。location_expression字段是一个通用表达式语言 (CEL) 表达式。
- 将
在
DUMPER_BUCKET中创建另一个配置 YAML 文件(以config.yaml为后缀),其中包含以下内容:type: experimental_object_rewriter relation: - match: schema: SOURCE_DATABASE outputName: database: null schema: TARGET_DATABASE
- 将
SOURCE_DATABASE和TARGET_DATABASE替换为源数据库名称和 Dataproc Metastore 数据库或 BigQuery 数据集的名称,具体取决于所选的 metastore。如果您要为 BigLake metastore 配置数据库,请确保 BigQuery 数据集存在。
如需详细了解这些配置 YAML,请参阅创建配置 YAML 文件的准则。
- 将
使用以下命令生成表映射 YAML 文件:
curl -d '{ "tasks": { "string": { "type": "HiveQL2BigQuery_Translation", "translation_details": { "target_base_uri": "TRANSLATION_OUTPUT_BUCKET", "source_target_mapping": { "source_spec": { "base_uri": "DUMPER_BUCKET" } }, "target_types": ["metadata"] } } } }' \ -H "Content-Type:application/json" \ -H "Authorization: Bearer TOKEN" -X POST https://bigquerymigration.googleapis.com/v2alpha/projects/PROJECT_ID/locations/LOCATION/workflows
替换以下内容:
TRANSLATION_OUTPUT_BUCKET:(可选)指定用于存储转换输出的 Cloud Storage 存储桶。如需了解详情,请参阅使用转换输出。DUMPER_BUCKET:包含hive-dumper-output.zip和配置 YAML 文件的 Cloud Storage 存储桶的基本 URI。TOKEN:OAuth 令牌。您可以在命令行中使用gcloud auth print-access-token命令生成此项。PROJECT_ID:处理转换的项目。LOCATION:处理作业的位置。例如eu或us。
监控此作业的状态。完成后,系统会在
TRANSLATION_OUTPUT_BUCKET的预定义路径中为数据库中的每个表生成一个映射文件。
使用 cron 命令编排转储程序的执行
您可以使用 cron 作业来执行 dwh-migration-dumper 工具,从而实现增量转移自动化。通过自动执行元数据提取,您可以确保 Hadoop 中提供最新的转储,以供后续增量传输运行使用。
准备工作
在使用此自动化脚本之前,请完成转储程序安装前提条件。如需运行该脚本,您必须安装 dwh-migration-dumper 工具并配置必要的 IAM 权限。
安排自动化操作
将以下脚本保存到本地文件。此脚本旨在由
crondaemon 进行配置和执行,以自动执行提取和上传转储程序输出的过程:#!/bin/bash # Exit immediately if a command exits with a non-zero status. set -e # Treat unset variables as an error when substituting. set -u # Pipelines return the exit status of the last command to exit with a non-zero status. set -o pipefail # These values are used if not overridden by command-line options. DUMPER_EXECUTABLE="DUMPER_PATH/dwh-migration-dumper" GCS_BASE_PATH="gs://PATH_TO_DUMPER_OUTPUT" LOCAL_BASE_DIR="LOCAL_BASE_DIRECTORY_PATH" # Function to display usage information usage() { echo "Usage: $0 [options]" echo "" echo "Runs the dwh-migration-dumper tool and uploads its output to provided GCS path." echo "" echo "Options:" echo " --dumper-executable
The full path to the dumper executable. (Required)" echo " --gcs-base-pathThe base GCS path for output files. (Required)" echo " --local-base-dirThe local base directory for logs and temp files. (Required)" echo " -h, --help Display this help message and exit." exit 1 } # This loop processes command-line options and overrides the default configuration. while [[ "$#" -gt 0 ]]; do case $1 in --dumper-executable) DUMPER_EXECUTABLE="$2" shift # past argument shift # past value ;; --gcs-base-path) GCS_BASE_PATH="$2" shift shift ;; --local-base-dir) LOCAL_BASE_DIR="$2" shift shift ;; -h|--help) usage ;; *) echo "Unknown option: $1" usage ;; esac done # This runs AFTER parsing arguments to ensure no placeholder values are left. if [[ "$DUMPER_EXECUTABLE" == "DUMPER_PATH"* || "$GCS_BASE_PATH" == "gs://PATH_TO_DUMPER_OUTPUT" || "$LOCAL_BASE_DIR" == "LOCAL_BASE_DIRECTORY_PATH" ]]; then echo "ERROR: One or more configuration variables have not been set. Please provide them as command-line arguments or edit the script." >&2 echo "Run with --help for more information." >&2 exit 1 fi # Create unique timestamp and directories for this run EPOCH=$(date +%s) LOCAL_LOG_DIR="${LOCAL_BASE_DIR}/logs" mkdir -p "${LOCAL_LOG_DIR}" # Ensures the base and logs directories exist # Define the unique log and zip file path for this run LOG_FILE="${LOCAL_LOG_DIR}/dumper_execution_${EPOCH}.log" ZIP_FILE_NAME="hive-dumper-output_${EPOCH}.zip" LOCAL_ZIP_PATH="${LOCAL_BASE_DIR}/${ZIP_FILE_NAME}" echo "Script execution started. All subsequent output will be logged to: ${LOG_FILE}" # --- Helper Functions --- log() { echo "$(date '+%Y-%m-%d %H:%M:%S') - $@" >> "${LOG_FILE}"} cleanup() { local path_to_remove="$1" log "Cleaning up local file/directory: ${path_to_remove}..." rm -rf "${path_to_remove}" } # This function is called when the script exits to ensure cleanup and logging happen reliably. handle_exit() { local exit_code=$? # Only run the failure logic if the script is exiting with an error if [[ ${exit_code} -ne 0 ]]; then log "ERROR: Script is exiting with a failure code (${exit_code})." local gcs_log_path_on_failure="${GCS_BASE_PATH}/logs/$(basename "${LOG_FILE}")" log "Uploading log file to ${gcs_log_path_on_failure} for debugging..." # Attempt to upload the log file on failure, but don't let this command cause the script to exit. gsutil cp "${LOG_FILE}" "${gcs_log_path_on_failure}" > /dev/null 2>&1 || log "WARNING: Failed to upload log file to GCS." else # SUCCESS PATH log "Script finished successfully. Now cleaning up local zip file...." # Clean up the local zip file ONLY on success cleanup "${LOCAL_ZIP_PATH}" fi log "*****Script End*****" exit ${exit_code} } # Trap the EXIT signal to run the handle_exit function, ensuring cleanup always happens. trap handle_exit EXIT # Validates the dumper log file based on a strict set of rules. validate_dumper_output() { local log_file_to_check="$1" # Check for the specific success message from the dumper tool. if grep -q "Dumper execution: SUCCEEDED" "${log_file_to_check}"; then log "Validation Successful: Found 'Dumper execution: SUCCEEDED' message." return 0 # Success else log "ERROR: Validation failed. The 'Dumper execution: SUCCEEDED' message was not found." return 1 # Failure fi } # --- Main Script Logic --- log "*****Script Start*****" log "Dumper Executable: ${DUMPER_EXECUTABLE}" log "GCS Base Path: ${GCS_BASE_PATH}" log "Local Base Directory: ${LOCAL_BASE_DIR}" # Use an array to build the command safely dumper_command_args=( "--connector" "hiveql" "--output" "${LOCAL_ZIP_PATH}" ) log "Starting dumper tool execution..." log "COMMAND: ${DUMPER_EXECUTABLE} ${dumper_command_args[*]}" "${DUMPER_EXECUTABLE}" "${dumper_command_args[@]}" >> "${LOG_FILE}" 2>&1 log "Dumper process finished." # Validate the output from the dumper execution for success or failure. validate_dumper_output "${LOG_FILE}" # Upload the ZIP file to GCS gcs_zip_path="${GCS_BASE_PATH}/${ZIP_FILE_NAME}" log "Uploading ${LOCAL_ZIP_PATH} to ${gcs_zip_path}..." if [ ! -f "${LOCAL_ZIP_PATH}" ]; then log "ERROR: Expected ZIP file ${LOCAL_ZIP_PATH} not found after dumper execution." # The script will exit here with an error code, and the trap will run. exit 1 fi gsutil cp "${LOCAL_ZIP_PATH}" "${gcs_zip_path}" >> "${LOG_FILE}" 2>&1 log "Upload to GCS successful." # The script will now exit with code 0. The trap will call cleanup and log the script end.运行以下命令,使脚本可执行:
chmod +x PATH_TO_SCRIPT
使用
crontab安排脚本,并将变量替换为适合您作业的值。添加条目以安排作业。 以下示例每天凌晨 2:30 运行脚本:# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES
创建转移作业时,请确保将
table_metadata_path字段设置为您为GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT配置的同一 Cloud Storage 路径。这是包含转储程序输出 ZIP 文件的路径。
安排注意事项
为避免数据过时,元数据转储必须在预定的转移开始之前准备就绪。相应地配置 cron 作业频率。
我们建议您手动试运行几次脚本,以确定转储程序工具生成输出的平均时间。使用此时间来设置 cron 调度,该调度安全地先于 DTS 转移运行,并确保新鲜度。
监控 Hive 托管式表的转移
在您安排 Hive 托管式表转移作业后,可以使用 bq 命令行工具命令监控转移作业。如需了解如何监控转移作业,请参阅查看转移作业。
跟踪表迁移状态
您还可以运行 dwh-dts-status 工具来监控转移作业配置或特定数据库中所有转移的表的状态。您还可以使用 dwh-dts-status 工具列出项目中的所有转移作业配置。
准备工作
在使用 dwh-dts-status 工具之前,请执行以下操作:
通过从
dwh-migration-toolsGitHub 仓库下载dwh-migration-tool软件包来获取dwh-dts-status工具。使用以下命令向 Cloud de Confiance by S3NS 验证您的账号身份:
gcloud auth application-default login如需了解详情,请参阅应用默认凭证的工作原理。
验证用户是否具有
bigquery.admin和logging.viewer角色。如需详细了解 IAM 角色,请参阅访问权限控制参考文档。
列出项目中的所有转移作业配置
如需列出项目中的所有转移作业配置,请使用以下命令:
./dwh-dts-status --list-transfer-configs --project-id=[PROJECT_ID] --location=[LOCATION]
替换以下内容:
PROJECT_ID:运行转移作业的 Cloud de Confiance by S3NS 项目 ID。LOCATION:创建转移作业配置的位置。
此命令会输出一个表,其中包含转移作业配置名称和 ID 的列表。
查看配置中所有表的状态
如需查看转移作业配置中包含的所有表的状态,请使用以下命令:
./dwh-dts-status --list-status-for-config --project-id=[PROJECT_ID] --config-id=[CONFIG_ID] --location=[LOCATION]
替换以下内容:
PROJECT_ID:运行转移作业的 Cloud de Confiance by S3NS 项目 ID。LOCATION:创建转移作业配置的位置。CONFIG_ID:指定转移作业配置的 ID。
此命令会输出一个表,其中包含指定转移作业配置中的表的列表以及这些表的转移状态。转移状态可以是以下值之一:PENDING、RUNNING、SUCCEEDED、FAILED、CANCELLED。
查看数据库中所有表的状态
如需查看从特定数据库转移的所有表的状态,请使用以下命令:
./dwh-dts-status --list-status-for-database --project-id=[PROJECT_ID] --database=[DATABASE]
替换以下内容:
PROJECT_ID:运行转移作业的 Cloud de Confiance by S3NS 项目 ID。DATABASE:指定数据库的名称。
此命令会输出一个表,其中包含指定数据库中的表的列表以及这些表的转移状态。转移状态可以是以下值之一:PENDING、RUNNING、SUCCEEDED、FAILED、CANCELLED。