
Puoi utilizzare la cache dei dati solo con i cluster GKE Standard. Questa guida ti illustra come attivare GKE Data Cache quando crei un nuovo cluster GKE Standard o upool di nodiol e come eseguire il provisioning dei dischi collegati a GKE con l'accelerazione Data Cache.
Informazioni su GKE Data Cache
Con GKE Data Cache, puoi utilizzare le SSD locali sui nodi GKE come livello di cache per l'archiviazione permanente, come Persistent Disk o Hyperdisk. L'utilizzo di SSD locali riduce la latenza di lettura del disco e aumenta le query al secondo (QPS) per i tuoi workload stateful, riducendo al minimo i requisiti di memoria. GKE Data Cache supporta tutti i tipi di Persistent Disk o Hyperdisk come dischi di supporto.
Per utilizzare GKE Data Cache per la tua applicazione, configura il pool di nodi GKE con SSD locali collegati. Puoi configurare GKE Data Cache in modo che utilizzi tutto o parte dell'SSD locale collegato. Gli SSD locali utilizzati dalla soluzione GKE Data Cache sono criptati at-rest utilizzando la crittografia Cloud de Confiance by S3NS standard.
Vantaggi
GKE Data Cache offre i seguenti vantaggi:
- Aumento della velocità di gestione delle query al secondo per i database convenzionali, come MySQL o Postgres, e per i database vettoriali.
- Prestazioni di lettura migliorate per le applicazioni stateful riducendo al minimo la latenza del disco.
- Idratazione e reidratazione dei dati più rapide perché gli SSD sono locali al nodo. L'idratazione dei dati si riferisce al processo iniziale di caricamento dei dati necessari dallo spazio di archiviazione permanente sull'SSD locale. La reidratazione dei dati si riferisce al processo di ripristino dei dati sulle unità SSD locali dopo il riciclo di un nodo.
Architettura di deployment
Il seguente diagramma mostra un esempio di configurazione di GKE Data Cache con due pod che eseguono ciascuno un'app. I pod vengono eseguiti sullo stesso nodo GKE. Ogni pod utilizza un SSD locale separato e un disco permanente di backup.
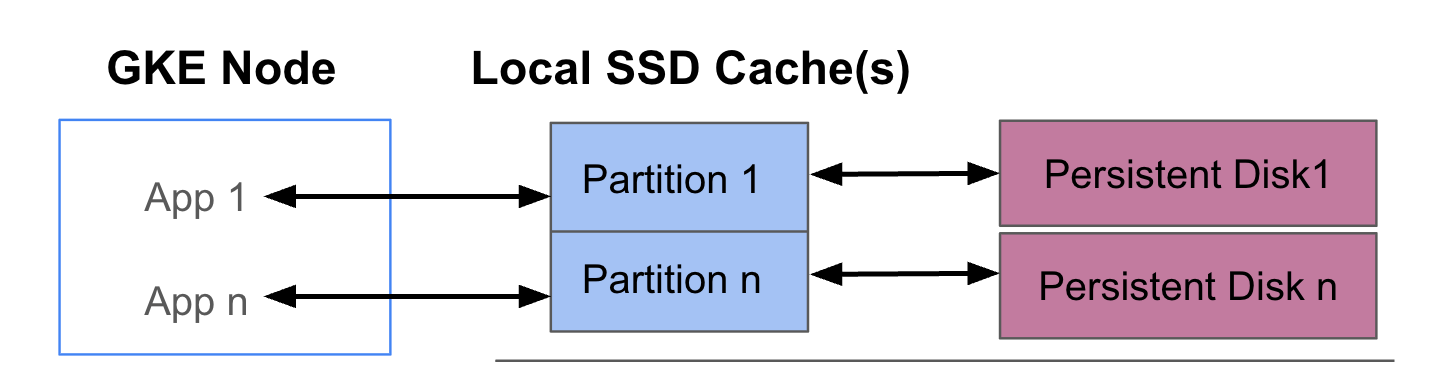
Modalità di deployment
Puoi configurare GKE Data Cache in una delle due modalità:
- Scrittura diretta (consigliato): quando l'applicazione scrive i dati, questi vengono
scritti in modo sincrono sia nella cache sia nel disco permanente sottostante. La modalità
writethroughimpedisce la perdita di dati ed è adatta alla maggior parte dei workload di produzione. - Scrittura differita: quando l'applicazione scrive i dati, questi vengono scritti solo
nella cache. Successivamente, i dati vengono scritti sul disco permanente in modo asincrono
(in background). La modalità
writebackmigliora le prestazioni di scrittura ed è adatta ai workload che si basano sulla velocità. Tuttavia, questa modalità influisce sull'affidabilità. Se il nodo si spegne inaspettatamente, i dati della cache non scaricati andranno persi.
Obiettivi
In questa guida imparerai a:
- Crea un'infrastruttura GKE sottostante per utilizzare GKE Data Cache.
- Crea un node pool dedicato con SSD locali collegati.
- Crea una StorageClass per il provisioning dinamico di un PersistentVolume (PV) quando un pod lo richiede tramite un PersistentVolumeClaim (PVC).
- Crea un PVC per richiedere un PV.
- Crea un deployment che utilizzi un PVC per garantire che la tua applicazione abbia accesso all'archiviazione permanente anche dopo il riavvio di un pod e durante la riprogrammazione.
Requisiti e pianificazione
Assicurati di soddisfare i seguenti requisiti per l'utilizzo di GKE Data Cache:
- Il cluster GKE deve eseguire la versione 1.32.3-gke.1440000 o successive.
- I tuoi pool di nodi devono utilizzare tipi di macchine che supportano gli SSD locali. Per saperne di più, vedi Supporto delle serie di macchine.
Pianificazione
Tieni presente questi aspetti quando pianifichi la capacità di archiviazione per GKE Data Cache:
- Il numero massimo di pod per nodo che utilizzeranno GKE Data Cache contemporaneamente.
- I requisiti di dimensione della cache previsti dei pod che utilizzeranno GKE Data Cache.
- La capacità totale degli SSD locali disponibili sui nodi GKE. Per informazioni sui tipi di macchine con SSD locali collegati per impostazione predefinita e su quelli per cui devi collegare gli SSD locali, consulta Scegli un numero valido di dischi SSD locali.
- Per i tipi di macchine di terza generazione o successive (a cui è collegato un numero predefinito di SSD locali), tieni presente che gli SSD locali per la cache dei dati sono riservati tra gli SSD locali totali disponibili sulla macchina.
- L'overhead del file system che può ridurre lo spazio utilizzabile sugli SSD locali. Ad esempio, anche se hai un nodo con due SSD locali con una capacità grezza totale di 750 GiB, lo spazio disponibile per tutti i volumi della cache dei dati potrebbe essere inferiore a causa dell'overhead del file system. Parte della capacità dell'SSD locale è riservata all'utilizzo del sistema.
Limitazioni
Incompatibilità con Backup per GKE
Per mantenere l'integrità dei dati in scenari come il ripristino di emergenza o la migrazione delle applicazioni, potrebbe essere necessario eseguire il backup e il ripristino dei dati. Se utilizzi Backup per GKE per ripristinare un PVC configurato per utilizzare la cache dei dati, il processo di ripristino non va a buon fine. Questo errore si verifica perché il processo di ripristino non propaga correttamente i parametri della cache dei dati necessari dalla StorageClass originale.
Prezzi
Ti viene addebitato l'importo per la capacità di provisioning totale degli SSD locali e dei dischi permanenti collegati. Ti viene addebitato un importo per GiB al mese.
Per ulteriori informazioni, consulta la sezione Prezzi dei dischi nella documentazione di Compute Engine.
Prima di iniziare
Prima di iniziare, assicurati di aver eseguito le seguenti operazioni:
- Attiva l'API Google Kubernetes Engine. Attiva l'API Google Kubernetes Engine
- Se vuoi utilizzare Google Cloud CLI per questa attività,
installala e poi
inizializza
gcloud CLI. Se hai già installato gcloud CLI, scarica l'ultima
versione eseguendo il comando
gcloud components update. Le versioni precedenti di gcloud CLI potrebbero non supportare l'esecuzione dei comandi in questo documento.
- Esamina i tipi di macchine che supportano gli SSD locali per il tuo pool di nodi.
Configurare i nodi GKE per l'utilizzo della cache dei dati
Per iniziare a utilizzare GKE Data Cache per l'archiviazione accelerata, i nodi devono disporre delle risorse SSD locali necessarie. Questa sezione mostra i comandi per il provisioning degli SSD locali e l'abilitazione di GKE Data Cache quando crei un nuovo cluster GKE o aggiungi un nuovo pool di nodi a un cluster esistente. Non puoi aggiornare un pool di nodi esistente per utilizzare Data Cache. Se vuoi utilizzare la cache dei dati su un cluster esistente, aggiungi un nuovo pool di nodi al cluster.
Su un nuovo cluster
Per creare un cluster GKE con la cache dei dati configurata, utilizza il seguente comando:
gcloud container clusters create CLUSTER_NAME \
--location=LOCATION \
--machine-type=MACHINE_TYPE \
--data-cache-count=DATA_CACHE_COUNT \
# Optionally specify additional Local SSDs, or skip this flag
--ephemeral-storage-local-ssd count=LOCAL_SSD_COUNT
Sostituisci quanto segue:
CLUSTER_NAME: il nome del cluster. Specifica un nome univoco per il cluster GKE che stai creando.LOCATION: la Cloud de Confiance by S3NS regione o la zona del nuovo cluster.MACHINE_TYPE: il tipo di macchina da utilizzare da una serie di macchine di seconda, terza o generazione successiva per il cluster, ad esempion2-standard-2oc3-standard-4-lssd. Questo campo è obbligatorio perché l'SSD locale non può essere utilizzato con il tipoe2-mediumpredefinito. Per ulteriori informazioni, consulta le serie di macchine disponibili.DATA_CACHE_COUNT: il numero di volumi SSD locali da dedicare esclusivamente alla cache dei dati su ogni nodo nel pool di nodi predefinito. Ognuna di queste SSD locali ha una capacità di 375 GiB. Il numero massimo di volumi varia in base al tipo di macchina e alla regione. Tieni presente che una parte della capacità dell'SSD locale è riservata all'utilizzo da parte del sistema.(Facoltativo)
LOCAL_SSD_COUNT: il numero di volumi SSD locali da eseguire il provisioning per altre esigenze di archiviazione temporanea. Utilizza il flag--ephemeral-storage-local-ssd countse vuoi eseguire il provisioning di SSD locali aggiuntivi che non vengono utilizzati per la cache dei dati.Tieni presente quanto segue per i tipi di macchine di terza generazione o successive:
- I tipi di macchine di terza generazione o successive hanno un numero specifico di SSD locali collegati per impostazione predefinita. Il numero di SSD locali collegati a ogni nodo dipende dal tipo di macchina specificato.
- Se prevedi di utilizzare il flag
--ephemeral-storage-local-ssd countper l'archiviazione temporanea aggiuntiva, assicurati di impostare il valore diDATA_CACHE_COUNTsu un numero inferiore al numero di dischi SSD locali totali disponibili sulla macchina. Il conteggio totale degli SSD locali disponibili include i dischi collegati predefiniti e tutti i nuovi dischi che aggiungi utilizzando il flag--ephemeral-storage-local-ssd count.
Questo comando crea un cluster GKE che viene eseguito su un tipo di macchina di seconda, terza o generazione successiva per il pool di nodi predefinito, esegue il provisioning degli SSD locali per la cache dei dati e, se specificato, esegue il provisioning facoltativo di SSD locali aggiuntivi per altre esigenze di spazio di archiviazione temporaneo.
Queste impostazioni si applicano solo al pool di nodi predefinito.
Su un cluster esistente
Per utilizzare la cache dei dati su un cluster esistente, devi creare un nuovo pool di nodi con la cache dei dati configurata.
Per creare un pool di nodi GKE con la cache dati configurata, utilizza il seguente comando:
gcloud container node-pool create NODE_POOL_NAME \
--cluster=CLUSTER_NAME \
--location=LOCATION \
--machine-type=MACHINE_TYPE \
--data-cache-count=DATA_CACHE_COUNT \
# Optionally specify additional Local SSDs, or skip this flag
--ephemeral-storage-local-ssd count=LOCAL_SSD_COUNT
Sostituisci quanto segue:
NODE_POOL_NAME: il nome del pool di nodi. Fornisci un nome univoco per il pool di nodi che stai creando.CLUSTER_NAME: il nome di un cluster GKE esistente in cui vuoi creare il pool di nodi.LOCATION: la stessa Cloud de Confiance by S3NS regione o zona del cluster.MACHINE_TYPE: il tipo di macchina da utilizzare da una serie di macchine di seconda, terza o generazione successiva per il cluster, ad esempion2-standard-2oc3-standard-4-lssd. Questo campo è obbligatorio, in quanto l'SSD locale non può essere utilizzato con il tipoe2-mediumpredefinito. Per ulteriori informazioni, consulta le serie di macchine disponibili.DATA_CACHE_COUNT: il numero di volumi SSD locali da dedicare esclusivamente alla cache dei dati su ogni nodo nel pool di nodi. Ognuna di queste SSD locali ha una capacità di 375 GiB. Il numero massimo di volumi varia in base al tipo di macchina e alla regione. Tieni presente che una parte della capacità dell'SSD locale è riservata all'utilizzo da parte del sistema.(Facoltativo)
LOCAL_SSD_COUNT: il numero di volumi SSD locali da eseguire il provisioning per altre esigenze di archiviazione temporanea. Utilizza il flag--ephemeral-storage-local-ssd countse vuoi eseguire il provisioning di SSD locali aggiuntivi che non vengono utilizzati per la cache dei dati.Tieni presente quanto segue per i tipi di macchine di terza generazione o successive:
- I tipi di macchine di terza generazione o successive hanno un numero specifico di SSD locali collegati per impostazione predefinita. Il numero di SSD locali collegati a ogni nodo dipende dal tipo di macchina specificato.
- Se prevedi di utilizzare il flag
--ephemeral-storage-local-ssd countper ulteriore spazio di archiviazione temporaneo, assicurati di impostareDATA_CACHE_COUNTsu un valore inferiore al numero di dischi SSD locali totali disponibili sulla macchina. Il conteggio totale degli SSD locali disponibili include i dischi collegati predefiniti e tutti i nuovi dischi che aggiungi utilizzando il flag--ephemeral-storage-local-ssd count.
Questo comando crea un pool di nodi GKE che viene eseguito su un tipo di macchina di seconda, terza o generazione successiva, esegue il provisioning degli SSD locali per la cache dei dati e, se specificato, esegue il provisioning facoltativo di SSD locali aggiuntivi per altre esigenze di spazio di archiviazione temporaneo.
Provisioning della cache dei dati per l'archiviazione permanente su GKE
Questa sezione fornisce un esempio di come attivare i vantaggi in termini di prestazioni di GKE Data Cache per le applicazioni stateful.
Crea un pool di nodi con SSD locali per la cache dei dati
Inizia creando un nuovo pool di nodi con SSD locali collegati nel tuo cluster GKE. GKE Data Cache utilizza gli SSD locali per accelerare le prestazioni dei dischi permanenti collegati.
Il seguente comando crea un pool di nodi che utilizza una macchina di seconda generazione,
n2-standard-2:
gcloud container node-pools create datacache-node-pool \
--cluster=CLUSTER_NAME \
--location=LOCATION \
--num-nodes=2 \
--data-cache-count=1 \
--machine-type=n2-standard-2
Sostituisci quanto segue:
CLUSTER_NAME: il nome del cluster. Specifica il cluster GKE in cui stai creando il nuovo pool di nodi.LOCATION: la stessa Cloud de Confiance by S3NS regione o zona del tuo cluster.
Questo comando crea un pool di nodi con le seguenti specifiche:
--num-nodes=2: imposta il numero iniziale di nodi in questo pool su due.--data-cache-count=1: specifica un SSD locale per nodo dedicato a GKE Data Cache.
Il numero totale di SSD locali di cui è stato eseguito il provisioning per questo pool di nodi è due perché per ogni nodo è stato eseguito il provisioning di un SSD locale.
Crea una StorageClass Data Cache
Crea un StorageClass Kubernetes
che indica a GKE come eseguire il provisioning dinamico di un volume permanente
che utilizza la cache dei dati.
Utilizza il seguente manifest per creare e applicare un StorageClass denominato pd-balanced-data-cache-sc:
kubectl apply -f - <<EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: pd-balanced-data-cache-sc
provisioner: pd.csi.storage.gke.io
parameters:
type: pd-balanced
data-cache-mode: writethrough
data-cache-size: "100Gi"
volumeBindingMode: WaitForFirstConsumer
allowVolumeExpansion: true
EOF
I parametri StorageClass per la cache dei dati includono quanto segue:
type: specifica il tipo di disco sottostante per il volume permanente. Per altre opzioni, consulta i tipi di Persistent Disk o i tipi di Hyperdisk supportati.data-cache-mode: utilizza la modalitàwritethroughconsigliata. Per ulteriori informazioni, vedi Modalità di deployment.data-cache-size: imposta la capacità dell'SSD locale su 100 GiB, che viene utilizzata come cache di lettura per ogni PVC.
Richiedere spazio di archiviazione con un PersistentVolumeClaim (PVC)
Crea un PVC che faccia riferimento alla classe di archiviazione pd-balanced-data-cache-sc che hai creato. La richiesta di volume permanente richiede un volume permanente con la cache dati attivata.
Utilizza il seguente manifest per creare una PVC denominata pvc-data-cache che richiede
un volume permanente di almeno 300 GiB con accesso ReadWriteOnce.
kubectl apply -f - <<EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-data-cache
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 300Gi
storageClassName: pd-balanced-data-cache-sc
EOF
Crea un deployment che utilizza la PVC
Crea un deployment denominato postgres-data-cache che esegua un pod che utilizza la PVC pvc-data-cache creata in precedenza. Il selettore di nodi cloud.google.com/gke-data-cache-count
garantisce che il pod venga pianificato su un nodo che dispone delle risorse SSD locali necessarie per utilizzare GKE Data Cache.
Crea e applica il seguente manifest per configurare un pod che esegue il deployment di un server web Postgres utilizzando la PVC:
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-data-cache
labels:
name: database
app: data-cache
spec:
replicas: 1
selector:
matchLabels:
service: postgres
app: data-cache
template:
metadata:
labels:
service: postgres
app: data-cache
spec:
nodeSelector:
cloud.google.com/gke-data-cache-disk: "1"
containers:
- name: postgres
image: postgres:14-alpine
volumeMounts:
- name: pvc-data-cache-vol
mountPath: /var/lib/postgresql/data2
subPath: postgres
env:
- name: POSTGRES_USER
value: admin
- name: POSTGRES_PASSWORD
value: password
restartPolicy: Always
volumes:
- name: pvc-data-cache-vol
persistentVolumeClaim:
claimName: pvc-data-cache
EOF
Verifica che il deployment sia stato creato correttamente:
kubectl get deployment
Potrebbero essere necessari alcuni minuti prima che il provisioning del container Postgres venga completato
e venga visualizzato lo stato READY.
Verificare il provisioning della cache dei dati
Dopo aver creato il deployment, verifica che l'archiviazione permanente con la cache dei dati venga eseguita correttamente.
Per verificare che
pvc-data-cachesia associato correttamente a un volume persistente, esegui questo comando:kubectl get pvc pvc-data-cacheL'output è simile al seguente:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE pvc-data-cache Bound pvc-e9238a16-437e-45d7-ad41-410c400ae018 300Gi RWO pd-balanced-data-cache-sc <unset> 10mPer verificare che il gruppo Logical Volume Manager (LVM) per la cache dei dati sia stato creato sul nodo:
Recupera il nome del pod del driver PDCSI su quel nodo:
NODE_NAME=$(kubectl get pod --output json | jq '.items[0].spec.nodeName' | sed 's/\"//g') kubectl get po -n kube-system -o wide | grep ^pdcsi-node | grep $NODE_NAMEDall'output, copia il nome del pod
pdcsi-node.Visualizza i log del driver PDCSI per la creazione del gruppo LVM:
PDCSI_POD_NAME="PDCSI-NODE_POD_NAME" kubectl logs -n kube-system $PDCSI_POD_NAME gce-pd-driver | grep "Volume group creation"Sostituisci
PDCSI-NODE_POD_NAMEcon il nome del pod effettivo che hai copiato nel passaggio precedente.L'output è simile al seguente:
Volume group creation succeeded for LVM_GROUP_NAME
Questo messaggio conferma che la configurazione LVM per la cache dei dati è impostata correttamente sul nodo.
Esegui la pulizia
Per evitare che al tuo account Cloud de Confiance by S3NS vengano addebitati costi, elimina le risorse di archiviazione che hai creato in questa guida.
Elimina il deployment.
kubectl delete deployment postgres-data-cacheElimina PersistentVolumeClaim.
kubectl delete pvc pvc-data-cacheElimina il pool di nodi.
gcloud container node-pools delete datacache-node-pool \ --cluster CLUSTER_NAMESostituisci
CLUSTER_NAMEcon il nome del cluster in cui hai creato il pool di nodi che utilizza la cache dei dati.
Passaggi successivi
- Consulta la sezione Risoluzione dei problemi di archiviazione in GKE.
- Scopri di più sul driver CSI per il disco permanente su GitHub.