
Dieses Dokument bietet einen Überblick über BigQuery-Abos, den zugehörigen Workflow und die zugehörigen Eigenschaften.
Ein BigQuery-Abo ist eine Art von Exportabo, das Nachrichten beim Empfang in eine vorhandene BigQuery-Tabelle schreibt. Sie müssen keinen separaten Abonnentenclient konfigurieren. Mit der Cloud de Confiance Console, der Google Cloud CLI, den Clientbibliotheken oder der Pub/Sub API können Sie ein BigQuery-Abo erstellen, aktualisieren, auflisten, trennen oder löschen.
Ohne den BigQuery-Abo-Typ benötigen Sie ein Pull- oder Push-Abo und einen Abonnenten (z. B. Dataflow), der Nachrichten liest und in eine BigQuery-Tabelle schreibt. Der Aufwand für die Ausführung eines Dataflow-Jobs ist nicht erforderlich, wenn Nachrichten keine zusätzliche Verarbeitung benötigen, bevor sie in einer BigQuery-Tabelle gespeichert werden. In diesem Fall können Sie stattdessen ein BigQuery-Abo verwenden.
Für einfache Änderungen an Nachrichten können Sie Ihrem BigQuery-Abo eine Transformation einzelner Nachrichten anhängen. Für Pub/Sub-Systeme, in denen eine komplexere Datenumwandlung erforderlich ist, bevor die Daten in einer BigQuery-Tabelle gespeichert werden, wird jedoch eine Dataflow-Pipeline empfohlen, insbesondere wenn Sie Fenster oder Aggregate für Nachrichten erstellen möchten.
Informationen zum Streamen von Daten aus Pub/Sub zu BigQuery mit Transformation mithilfe von Dataflow finden Sie unter Von Pub/Sub zu BigQuery streamen.
Die Dataflow-Vorlage „Pub/Sub-Abo für BigQuery“ erzwingt standardmäßig die Exactly-Once-Zustellung. Dies wird in der Regel durch Deduplizierungsmechanismen in der Dataflow-Pipeline erreicht. Das BigQuery-Abo unterstützt jedoch nur die mindestens einmalige Übermittlung. Wenn eine genaue Deduplizierung für Ihren Anwendungsfall entscheidend ist, sollten Sie nachgelagerte Prozesse in BigQuery in Betracht ziehen, um potenzielle Duplikate zu verarbeiten.
Hinweis
Bevor Sie dieses Dokument lesen, sollten Sie mit Folgendem vertraut sein:
Funktionsweise von Pub/Sub und die verschiedenen Pub/Sub-Begriffe.
Die verschiedenen Arten von Abos, die von Pub/Sub unterstützt werden, und die Gründe für die Verwendung eines BigQuery-Abos.
Wie BigQuery funktioniert und wie Sie BigQuery-Tabellen konfigurieren und verwalten.
Workflow für BigQuery-Abos
Das folgende Bild zeigt den Workflow zwischen einem BigQuery-Abo und BigQuery.
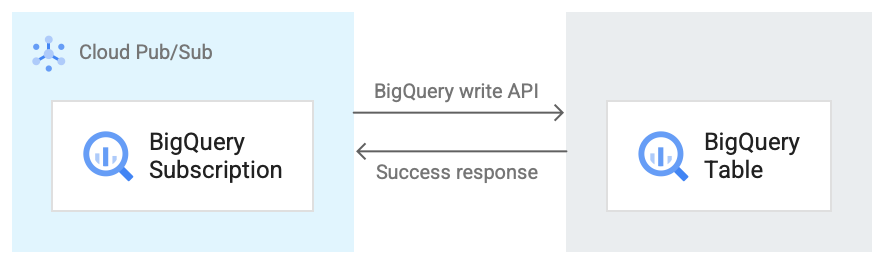
Hier eine kurze Beschreibung des Workflows, der sich auf Abbildung 1 bezieht:
- Pub/Sub verwendet die BigQuery Storage Write API, um Daten an die BigQuery-Tabelle zu senden.
- Die Nachrichten werden in Batches an die BigQuery-Tabelle gesendet.
- Nach erfolgreichem Abschluss eines Schreibvorgangs gibt die API eine OK-Antwort zurück.
- Wenn bei der Schreiboperation Fehler auftreten, wird die Pub/Sub-Nachricht selbst negativ bestätigt. Die Nachricht wird dann noch einmal gesendet. Wenn die Zustellung der Nachricht oft genug fehlschlägt und im Abo ein Thema für unzustellbare Nachrichten konfiguriert ist, wird die Nachricht in das Thema für unzustellbare Nachrichten verschoben.
Eigenschaften eines BigQuery-Abos
Die Eigenschaften, die Sie für ein BigQuery-Abo konfigurieren, bestimmen die BigQuery-Tabelle, in die Pub/Sub Nachrichten schreibt, und den Schematyp dieser Tabelle.
Weitere Informationen finden Sie unter BigQuery-Properties.
Schemakompatibilität
Dieser Abschnitt gilt nur, wenn Sie beim Erstellen eines BigQuery-Abos die Option Schema des Themas verwenden auswählen.
Pub/Sub und BigQuery verwenden unterschiedliche Methoden zum Definieren ihrer Schemas. Pub/Sub-Schemas werden im Apache Avro- oder Protocol Buffer-Format definiert, während BigQuery-Schemas in verschiedenen Formaten definiert werden.
Im Folgenden finden Sie eine Liste wichtiger Informationen zur Schemakompatibilität zwischen einem Pub/Sub-Thema und einer BigQuery-Tabelle.
Nachrichten mit einem falsch formatierten Feld werden nicht in BigQuery geschrieben.
Im BigQuery-Schema sind
INT,SMALLINT,INTEGER,BIGINT,TINYINTundBYTEINTAliase fürINTEGER.DECIMAList ein Alias fürNUMERICundBIGDECIMAList ein Alias fürBIGNUMERIC.Wenn der Typ im Themaschema
stringund der Typ in der BigQuery-TabelleJSON,TIMESTAMP,DATETIME,DATE,TIME,NUMERICoderBIGNUMERICist, muss jeder Wert für dieses Feld in einer Pub/Sub-Nachricht dem für den BigQuery-Datentyp angegebenen Format entsprechen.Einige logische Avro-Typen werden unterstützt, wie in der folgenden Tabelle angegeben. Alle nicht aufgeführten logischen Typen entsprechen nur dem entsprechenden Avro-Typ, den sie annotieren, wie in der Avro-Spezifikation beschrieben.
Im Folgenden finden Sie eine Sammlung von Zuordnungen verschiedener Schemaformate zu BigQuery-Datentypen.
Avro-Typen
| Avro-Typ | BigQuery-Datentyp |
null |
Any NULLABLE |
boolean |
BOOLEAN |
int |
INTEGER, NUMERIC oder
BIGNUMERIC |
long |
INTEGER, NUMERIC oder
BIGNUMERIC |
float |
FLOAT64, NUMERIC oder
BIGNUMERIC |
double |
FLOAT64, NUMERIC oder
BIGNUMERIC |
bytes |
BYTES, NUMERIC oder
BIGNUMERIC |
string |
STRING, JSON,
TIMESTAMP, DATETIME,
DATE, TIME,
NUMERIC oder BIGNUMERIC |
record |
RECORD/STRUCT |
array von Type |
REPEATED Type |
map mit dem Werttyp ValueType
|
REPEATED STRUCT <key STRING, value
ValueType> |
union mit zwei Typen: null und Type |
NULLABLE Type |
andere union |
Nicht zuordenbar |
fixed |
BYTES, NUMERIC oder
BIGNUMERIC |
enum |
INTEGER |
Logische Avro-Typen
| Logischer Avro-Typ | BigQuery-Datentyp |
timestamp-micros |
TIMESTAMP |
timestamp-millis |
TIMESTAMP |
date |
DATE |
time-micros |
TIME |
time-millis |
TIME |
duration |
INTERVAL |
decimal |
NUMERIC oder BIGNUMERIC |
Protokollzwischenspeichertypen
| Protocol Buffer Type (Protokollpuffertyp) | BigQuery-Datentyp |
double |
FLOAT64, NUMERIC oder
BIGNUMERIC |
float |
FLOAT64, NUMERIC oder
BIGNUMERIC |
int32 |
INTEGER, NUMERIC,
BIGNUMERIC oder DATE |
int64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME oder TIMESTAMP |
uint32 |
INTEGER, NUMERIC,
BIGNUMERIC oder DATE |
uint64 |
NUMERIC oder BIGNUMERIC |
sint32 |
INTEGER, NUMERIC oder
BIGNUMERIC |
sint64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME oder TIMESTAMP |
fixed32 |
INTEGER, NUMERIC,
BIGNUMERIC oder DATE |
fixed64 |
NUMERIC oder BIGNUMERIC |
sfixed32 |
INTEGER, NUMERIC,
BIGNUMERIC oder DATE |
sfixed64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME oder TIMESTAMP |
bool |
BOOLEAN |
string |
STRING, JSON,
TIMESTAMP, DATETIME,
DATE, TIME,
NUMERIC oder BIGNUMERIC |
bytes |
BYTES, NUMERIC oder
BIGNUMERIC |
enum |
INTEGER |
message |
RECORD/STRUCT |
oneof |
Nicht zuordenbar |
map<KeyType, ValueType> |
REPEATED RECORD<key KeyType, value
ValueType> |
enum |
INTEGER |
repeated/array of Type |
REPEATED Type |
Ganzzahldarstellung von Datum und Uhrzeit
Wenn Sie eine Ganzzahl einem der Datums- oder Uhrzeittypen zuordnen, muss die Zahl den richtigen Wert darstellen. Nachfolgend finden Sie die Zuordnung von BigQuery-Datentypen zu der Ganzzahl, die sie darstellt.
| BigQuery-Datentyp | Ganzzahldarstellung |
DATE |
Die Anzahl der Tage seit der Unix-Epoche, dem 1. Januar 1970 |
DATETIME |
Das Datum und die Uhrzeit in Mikrosekunden, ausgedrückt als amtliche Zeit mit dem CivilTimeEncoder |
TIME |
Die Zeit in Mikrosekunden, ausgedrückt als amtliche Zeit mit dem CivilTimeEncoder |
TIMESTAMP |
Die Anzahl der Mikrosekunden seit der Unix-Epoche (1. Januar 1970, 00:00:00 UTC) |
BigQuery Change Data Capture-Aufnahme
BigQuery-Abos unterstützen CDC-Aufnahmeupdates (Change Data Capture), wenn use_topic_schema oder use_table_schema in den Aboeigenschaften auf true festgelegt ist. Wenn Sie das Feature mit use_topic_schema verwenden möchten, legen Sie das Schema des Themas mit den folgenden Feldern fest:
_CHANGE_TYPE(erforderlich): Einstring-Feld, das aufUPSERToderDELETEgesetzt ist.Wenn für eine Pub/Sub-Nachricht, die in die BigQuery-Tabelle geschrieben wird,
_CHANGE_TYPEaufUPSERTfestgelegt ist, aktualisiert BigQuery die Zeile mit demselben Schlüssel, sofern sie vorhanden ist, oder fügt eine neue Zeile ein, falls nicht.Wenn für eine Pub/Sub-Nachricht, die in die BigQuery-Tabelle geschrieben wird,
_CHANGE_TYPEaufDELETEgesetzt ist, löscht BigQuery die Zeile in der Tabelle mit demselben Schlüssel, sofern sie vorhanden ist.
_CHANGE_SEQUENCE_NUMBER(optional): Einstring-Feld, das dafür sorgt, dass Aktualisierungen und Löschvorgänge, die an der BigQuery-Tabelle vorgenommen werden, in der richtigen Reihenfolge verarbeitet werden. Nachrichten für denselben Zeilenschlüssel müssen einen kontinuierlich steigenden Wert für_CHANGE_SEQUENCE_NUMBERenthalten. Nachrichten mit Sequenznummern, die kleiner als die höchste Sequenznummer sind, die für eine Zeile verarbeitet wurde, haben keine Auswirkungen auf die Zeile in der BigQuery-Tabelle. Die Sequenznummer muss dem Format_CHANGE_SEQUENCE_NUMBERentsprechen.
Wenn Sie die Funktion mit use_table_schema verwenden möchten, fügen Sie die oben genannten Felder in die JSON-Nachricht ein.
Informationen zu den Preisen finden Sie unter Preise für die BigQuery-CDC-Aufnahme.
BigLake-Tabellen für Apache Iceberg in BigQuery
BigQuery-Abos können ohne zusätzliche Änderungen mit BigLake-Tabellen für Apache Iceberg in BigQuery verwendet werden.
BigLake-Tabellen für Apache Iceberg in BigQuery bilden die Grundlage für die Erstellung von Lakehouses im offenen Format auf Cloud de Confiance by S3NS. Diese Tabellen bieten dieselbe vollständig verwaltete Umgebung wie Standard-BigQuery-Tabellen (integriert), speichern Daten jedoch in kundeneigenen Speicher-Buckets im Parquet-Format, um mit offenen Iceberg-Tabellenformaten kompatibel zu sein.
Informationen zum Erstellen von BigLake-Tabellen für Apache Iceberg in BigQuery finden Sie unter Iceberg-Tabelle erstellen.
Umgang mit Nachrichtenfehlern
Wenn eine Pub/Sub-Nachricht nicht in BigQuery geschrieben werden kann, kann sie nicht bestätigt werden. Wenn Sie solche nicht zustellbaren Nachrichten weiterleiten möchten, konfigurieren Sie ein Thema für unzustellbare Nachrichten für das BigQuery-Abo. Die an das Thema für unzustellbare Nachrichten weitergeleitete Pub/Sub-Nachricht enthält ein Attribut CloudPubSubDeadLetterSourceDeliveryErrorMessage mit dem Grund, warum die Pub/Sub-Nachricht nicht in BigQuery geschrieben werden konnte.
Wenn Pub/Sub keine Nachrichten in BigQuery schreiben kann, wird die Zustellung von Nachrichten ähnlich wie beim Push-Backoff-Verhalten zurückgestellt. Wenn dem Abo jedoch ein Thema für unzustellbare Nachrichten angehängt ist, wird die Übermittlung von Pub/Sub nicht zurückgefahren, wenn Nachrichtenfehler auf Schema-Kompatibilitätsfehler zurückzuführen sind.
Kontingente und Limits
Für den BigQuery-Abonnentendurchsatz pro Region gelten Kontingentbeschränkungen. Weitere Informationen finden Sie unter Pub/Sub-Kontingente und ‑Limits.
BigQuery-Abos schreiben Daten mit der BigQuery Storage Write API. Informationen zu Kontingenten und Limits für die Storage Write API finden Sie unter Storage Write API-Anfragen. Bei BigQuery-Abos wird nur das Durchsatzkontingent für die Storage Write API verwendet. Die anderen Kontingentüberlegungen für die Storage Write API können Sie in diesem Fall ignorieren.
Preise
Informationen zu den Preisen für BigQuery-Abos finden Sie auf der Pub/Sub-Preisseite.
Nächste Schritte
Erstellen Sie ein Abo, z. B. ein BigQuery-Abo.
Fehlerbehebung bei einem BigQuery-Abo
Preise für Pub/Sub, einschließlich BigQuery-Abos, ansehen
Erstellen oder ändern Sie ein Abo mit
gcloud-CLI-Befehlen.Erstellen oder ändern Sie ein Abo mit REST APIs.