
Eseguire la migrazione di schema e dati da Teradata
La combinazione di BigQuery Data Transfer Service e di un agente speciale per la migrazione ti consente di copiare i dati da un'istanza di data warehouse on-premise Teradata a BigQuery. Questo documento descrive la procedura passo passo per eseguire la migrazione dei dati da Teradata utilizzando BigQuery Data Transfer Service.
Prima di iniziare
-
In the Cloud de Confiance console, on the project selector page, select or create a Cloud de Confiance project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Cloud de Confiance project.
Enable the BigQuery, BigQuery Data Transfer Service, Cloud Storage, and Pub/Sub APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator) and the Project IAM Admin role (roles/resourcemanager.projectIamAdmin). Learn how to grant roles. -
In the Cloud de Confiance console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Cloud de Confiance console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the following roles to the service account: roles/bigquery.user, roles/storage.objectAdmin, roles/iam.serviceAccountTokenCreator.
To grant a role, find the Select a role list, then select the role.
To grant additional roles, click Add another role and add each additional role.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Cloud de Confiance console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
Impostare le autorizzazioni richieste
Assicurati che l'entità che crea il trasferimento disponga dei seguenti ruoli nel progetto contenente il job di trasferimento:
- Visualizzatore log (
roles/logging.viewer) - Amministratore Storage (
roles/storage.admin) o un ruolo personalizzato che concede le seguenti autorizzazioni:storage.objects.createstorage.objects.getstorage.objects.list
- Amministratore BigQuery (
roles/bigquery.admin) o un ruolo personalizzato che concede le seguenti autorizzazioni:bigquery.datasets.createbigquery.jobs.createbigquery.jobs.getbigquery.jobs.listAllbigquery.tables.getbigquery.transfers.getbigquery.transfers.update
Crea un set di dati
Crea un set di dati BigQuery per archiviare i dati. Non devi creare tabelle.
Crea un bucket Cloud Storage
Crea un bucket Cloud Storage per lo staging dei dati durante il job di trasferimento.
Prepara l'ambiente locale
Completa le attività descritte in questa sezione per preparare l'ambiente locale per il job di trasferimento.
Requisiti del computer locale
- L'agente di migrazione utilizza una connessione JDBC con l'istanza Teradata e le API. Assicurati che l'accesso alla rete non sia bloccato da un firewall. Cloud de Confiance by S3NS
- Assicurati che sia installato Java Runtime Environment 8 o versioni successive.
- Assicurati di avere spazio di archiviazione sufficiente per il metodo di estrazione che hai scelto, come descritto in Metodo di estrazione.
- Se hai deciso di utilizzare l'estrazione Teradata Parallel Transporter (TPT),
assicurati che l'utilità
tbuildsia installata. Per ulteriori informazioni sulla scelta di un metodo di estrazione, consulta Metodo di estrazione.
Dettagli della connessione Teradata
Assicurati di disporre del nome utente e della password di un utente Teradata con accesso in lettura alle tabelle di sistema e alle tabelle di cui viene eseguita la migrazione.
Assicurati di conoscere il nome host e il numero di porta per connetterti all'istanza Teradata.
Scarica il driver JDBC
Scarica
il file del driver JDBC terajdbc4.jar da Teradata su una macchina che
può connettersi al data warehouse.
Imposta la variabile GOOGLE_APPLICATION_CREDENTIALS
Imposta la variabile di ambiente GOOGLE_APPLICATION_CREDENTIALS
sulla chiave del account di servizio che hai scaricato nella
sezione Prima di iniziare.
Aggiorna la regola di uscita dei Controlli di servizio VPC
Aggiungi il progetto Cloud de Confiance by S3NS gestito da BigQuery Data Transfer Service corrispondente alla tua regione alla regola di uscita nel perimetro Controlli di servizio VPC.
La tabella seguente è un elenco dei numeri di progetto per le località regionali utilizzate per i trasferimenti di dati. Aggiungi i numeri di progetto corrispondenti alla posizione del set di dati.
Località multiregionali
| Descrizione multiregionale | Nome multi-regione | Numeri dei progetti |
|---|---|---|
| Data center negli stati membri dell'Unione Europea | eu |
17253722542 272853474138 420718595790 929473878322 990232121269 |
| Data center negli Stati Uniti | us |
1005756709729 140222280645 247872939591 312976397333 521896999118 525821192359 892499355189 949134172629 990232121269 |
Località regionali
| Descrizione della regione | Nome regione | Numeri dei progetti |
|---|---|---|
| Americhe | ||
| Montréal | northamerica-northeast1 |
603911341430 644379120249 665941355665 743643531530 990232121269 |
| Toronto | northamerica-northeast2 |
181203883014 569023246094 814935732186 833015518790 990232121269 |
| Messico | northamerica-south1 |
439376105624 737643102222 746316165749 863053761002 990232121269 |
| San Paolo | southamerica-east1 |
133435938206 376122552368 485381725001 796391836836 990232121269 |
| Santiago | southamerica-west1 |
1087357303029 348543783783 659924941015 862900136725 990232121269 |
| Iowa | us-central1 |
298453567688 788415223852 850878823175 986263347210 990232121269 |
| Carolina del Sud | us-east1 |
1055108947046 1084124504460 335013112247 724101498857 990232121269 |
| Virginia del Nord | us-east4 |
1029854080039 517474920593 970314007431 98298633330 990232121269 |
| Columbus, Ohio | us-east5 |
1018267783826 386306739011 420397636038 778968775575 990232121269 |
| Dallas | us-south1 |
1000457898916 1047122215716 241710172671 955278753983 990232121269 |
| Oregon | us-west1 |
232019391832 341405773774 376906440760 477215631937 990232121269 |
| Los Angeles | us-west2 |
1082081077124 593499865061 796558996990 812061960238 990232121269 |
| Salt Lake City | us-west3 |
34769458069 488393466740 870087576864 878441810105 990232121269 |
| Las Vegas | us-west4 |
219770299440 421529192039 516260452158 653925368482 990232121269 |
| Europa | ||
| Varsavia | europe-central2 |
408105394529 556626738827 613447812609 875068591969 990232121269 |
| Finlandia | europe-north1 |
1049140453480 148002628360 610856287987 657186468367 990232121269 |
| Stoccolma | europe-north2 |
264708615094 275871864623 353052212156 915614473443 990232121269 |
| Madrid | europe-southwest1 |
1035291313153 1048466610864 16585749286 684773867031 990232121269 |
| Belgio | europe-west1 |
311010690362 337985836396 348525528820 874692481832 990232121269 |
| Berlino | europe-west10 |
1014021387408 1021109191575 1076988971454 965306537493 990232121269 |
| Torino | europe-west12 |
624998300135 664251133452 672417986210 702529954322 990232121269 |
| Londra | europe-west2 |
1013046052024 424062913611 625972158490 707263280432 990232121269 |
| Francoforte | europe-west3 |
1087781646048 143240061766 312688138599 715827071311 990232121269 |
| Paesi Bassi | europe-west4 |
110044889848 398757511504 557234723212 769143166592 990232121269 |
| Zurigo | europe-west6 |
163551586425 378713015688 416925392034 669890417706 990232121269 |
| Milano | europe-west8 |
103481800693 1082157965924 23655501621 555661886352 990232121269 |
| Parigi | europe-west9 |
1085882338778 176207547936 221990904254 670920836007 990232121269 |
| Asia Pacifico | ||
| Taiwan | asia-east1 |
21873972082 271898158674 389278959284 922460772707 990232121269 |
| Hong Kong | asia-east2 |
263483805684 773980783174 865347783058 90665746791 990232121269 |
| Tokyo | asia-northeast1 |
415417931028 53965067050 953665196151 983967577764 990232121269 |
| Osaka | asia-northeast2 |
205726704771 478186599828 57312416489 861476638029 990232121269 |
| Seul | asia-northeast3 |
320159292295 548035635347 791473645597 935702892639 990232121269 |
| Mumbai | asia-south1 |
13592990997 229940966341 68960523189 901420668689 990232121269 |
| Delhi | asia-south2 |
496191507005 54806403576 741779061357 809478923584 990232121269 |
| Singapore | asia-southeast1 |
541653567103 60558171982 753901882843 944188302893 990232121269 |
| Giacarta | asia-southeast2 |
1074047252998 17464964742 271871433529 427023413305 990232121269 |
| Bangkok | asia-southeast3 |
1020436856624 355273974477 603543103680 777922772431 990232121269 |
| Sydney | australia-southeast1 |
163046745040 591848239128 623326425100 814418810594 990232121269 |
| Melbourne | australia-southeast2 |
1062391852597 441829466914 714897033691 748594785463 990232121269 |
| Medio Oriente | ||
| Doha | me-central1 |
260539430499 380691191456 707684919235 799708208022 990232121269 |
| Dammam | me-central2 |
1067269861014 364585730608 702115426609 932431265647 990232121269 |
| Tel Aviv | me-west1 |
356023739839 748664533815 869899828196 940471234508 990232121269 |
| Africa | ||
| Johannesburg | africa-south1 |
366497204741 900693348777 930834390708 990232121269 995904484959 |
| Altro | ||
| AWS ap-northeast-2 | aws-ap-northeast-2 |
118757274428 227045504542 31525566793 415505940944 990232121269 |
| AWS ap-southeast-2 | aws-ap-southeast-2 |
179772227799 236687515237 779037664799 925378406445 990232121269 |
| AWS eu-central-1 | aws-eu-central-1 |
469423327197 5211207427 905007897524 989902812500 990232121269 |
| AWS eu-west-1 | aws-eu-west-1 |
477582827438 653238211450 795832028199 961178626984 990232121269 |
| AWS us-east-1 | aws-us-east-1 |
1005783963369 293187121246 622189180485 78860240845 990232121269 |
| AWS us-west-2 | aws-us-west-2 |
206681800614 264089603202 419256100048 79353630998 990232121269 |
| Azure eastus2 | azure-eastus2 |
1021739993926 1054000274357 495696597482 590387575526 990232121269 |
| Azure westus2 | azure-westus2 |
118244543872 242088193076 278777007439 662989519829 990232121269 |
| Località solo per uso interno (europe-west15) | europe-west15 |
1075380375245 635354739083 663432613496 904125362271 990232121269 |
| Località solo per uso interno (us-central2) | us-central2 |
1085843140251 269725830808 498892726043 68311303080 990232121269 |
| Località solo per uso interno (us-east7) | us-east7 |
173063949542 661852837608 704905947583 956740768291 990232121269 |
| Località sintetica (us-synthetic1) | us-synthetic1 |
131957618958 250975404179 740244847288 787843086952 990232121269 |
| Posizione solo per uso interno (us-west8) | us-west8 |
13105749132 248649202605 477355088721 653053504449 990232121269 |
Il canale di comunicazione tra l'agente in esecuzione on-premise e BigQuery Data Transfer Service avviene tramite la pubblicazione di messaggi Pub/Sub in un argomento per trasferimento. BigQuery Data Transfer Service deve inviare comandi all'agente per estrarre i dati e l'agente deve pubblicare messaggi in BigQuery Data Transfer Service per aggiornare lo stato e restituire le risposte all'estrazione dei dati.
Crea un file di schema personalizzato
Per utilizzare un file di schema personalizzato anziché il rilevamento automatico dello schema, creane uno manualmente o fai in modo che l'agente di migrazione ne crei uno per te quando inizializzi l'agente.
Se crei un file di schema manualmente e intendi utilizzare la console Cloud de Confiance per creare un trasferimento, carica il file di schema in un bucket Cloud Storage nello stesso progetto che prevedi di utilizzare per il trasferimento.
Scarica l'agente di migrazione
Scarica l'agente di migrazione su una macchina che può connettersi al data warehouse. Sposta il file JAR dell'agente di migrazione nella stessa directory del file JAR del driver JDBC di Teradata.
Configurare il file delle credenziali per il modulo di accesso
Se utilizzi il modulo di accesso per Cloud Storage con l'utilità Teradata Parallel Transporter (TPT) per l'estrazione, è necessario un file delle credenziali.
Prima di creare un file delle credenziali, devi creare una account di servizio account. Dal file della chiave del account di servizio scaricato, ottieni le seguenti informazioni:
client_emailprivate_key: copia tutti i caratteri all'interno di-----BEGIN PRIVATE KEY-----e-----END PRIVATE KEY-----, inclusi tutti i caratteri/ne senza le doppie virgolette di chiusura.
Una volta ottenute le informazioni richieste, crea un file delle credenziali. Di seguito è riportato un esempio di file delle credenziali con una posizione
predefinita di $HOME/.gcs/credentials:
[default] gcs_access_key_id = ACCESS_ID gcs_secret_access_key = ACCESS_KEY
Sostituisci quanto segue:
ACCESS_ID: l'ID chiave di accesso o il valoreclient_emailnel file della chiave del account di servizio.ACCESS_KEY: la chiave di accesso segreta o il valoreprivate_keynel file della chiave del account di servizio.
Configurare un trasferimento
Crea un trasferimento con BigQuery Data Transfer Service.
Se vuoi che venga creato automaticamente un file di schema personalizzato, utilizza l'agente di migrazione per configurare il trasferimento.
Non puoi creare un trasferimento on demand utilizzando lo strumento a riga di comando bq. Devi utilizzare la console Cloud de Confiance o l'API BigQuery Data Transfer Service.
Se crei un trasferimento ricorrente, ti consigliamo vivamente di specificare un file di schema in modo che i dati dei trasferimenti successivi possano essere partizionati correttamente quando vengono caricati in BigQuery. Senza un file schema, BigQuery Data Transfer Service deduce lo schema della tabella dai dati di origine trasferiti e tutte le informazioni su partizionamento, clustering, chiavi primarie e monitoraggio delle modifiche vengono perse. Inoltre, i trasferimenti successivi saltano le tabelle di cui è stata eseguita la migrazione in precedenza dopo il trasferimento iniziale. Per saperne di più su come creare un file schema, consulta File schema personalizzato.
Console
Nella console Cloud de Confiance , vai alla pagina BigQuery.
Fai clic su Trasferimenti di dati.
Fai clic su Crea trasferimento.
Nella sezione Tipo di origine, segui questi passaggi:
- Scegli Migrazione: Teradata.
- Per Nome configurazione di trasferimento, inserisci un nome visualizzato per il trasferimento, ad esempio
My Migration. Il nome visualizzato può essere qualsiasi valore che ti consenta di identificare il trasferimento se devi modificarlo in un secondo momento. - (Facoltativo) Per Opzioni di pianificazione, puoi lasciare il valore predefinito di Giornaliero (in base all'ora di creazione) o scegliere un'altra ora se vuoi un trasferimento incrementale ricorrente. In caso contrario, scegli On demand per un trasferimento una tantum.
Per Impostazioni destinazione, scegli il set di dati appropriato.
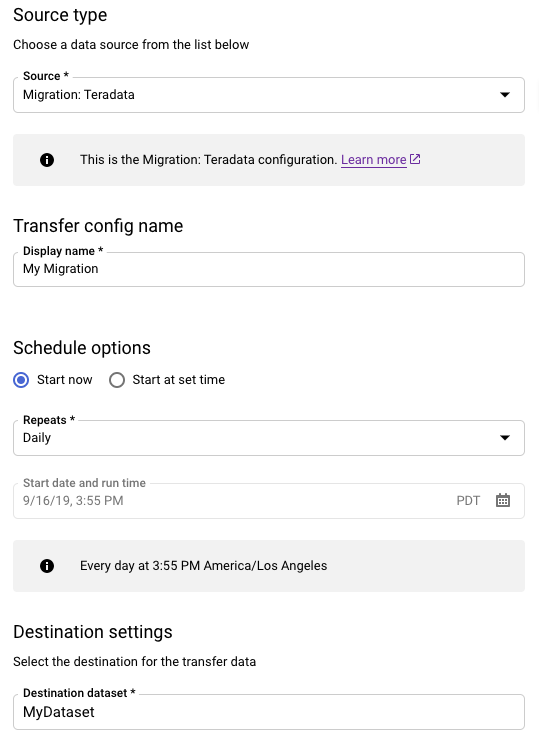
Nella sezione Dettagli origine dati, continua con i dettagli specifici per il trasferimento Teradata.
- Per Tipo di database, scegli Teradata.
- Per Bucket Cloud Storage, cerca il nome del bucket Cloud Storage per preparare i dati della migrazione. Non digitare il prefisso
gs://, inserisci solo il nome del bucket. - In Nome database, inserisci il nome del database di origine in Teradata.
Per Pattern nome tabella, inserisci un pattern per la corrispondenza dei nomi delle tabelle nel database di origine. Puoi utilizzare le espressioni regolari per specificare il pattern. Ad esempio:
sales|expensescorrisponde alle tabelle denominatesaleseexpenses..*corrisponde a tutte le tabelle.
In Email del service account, inserisci l'indirizzo email associato alle credenziali delaccount di serviziot utilizzate da un agente di migrazione.
(Facoltativo) Per Percorso file schema, inserisci il percorso e il nome di un file schema personalizzato. Per saperne di più sulla creazione di un file schema personalizzato, consulta File schema personalizzato. Puoi lasciare vuoto questo campo per consentire a BigQuery di rilevare automaticamente lo schema della tabella di origine.
(Facoltativo) Per Directory radice di output della traduzione, inserisci il percorso e il nome file del file di mapping dello schema fornito dal motore di traduzione BigQuery. Per saperne di più sulla generazione di un file di mapping dello schema, vedi Utilizzare l'output del motore di traduzione per lo schema (anteprima). Puoi lasciare questo campo vuoto per consentire a BigQuery di rilevare automaticamente lo schema della tabella di origine.
(Facoltativo) Per Enable direct unload to GCS (Abilita lo scaricamento diretto su GCS), seleziona la casella di controllo per attivare il modulo di accesso per Cloud Storage.
Nel menu Service account, seleziona un service account tra quelli associati al tuo progettoCloud de Confiance . Puoi associare un account di servizio al trasferimento anziché utilizzare le tue credenziali utente. Per ulteriori informazioni sull'utilizzo dei service account con i trasferimenti di dati, consulta Utilizza i service account.
- Se hai eseguito l'accesso con un'identità federata, è necessario un account di servizio per creare un trasferimento. Se hai eseguito l'accesso con un Account Google, il service account per il trasferimento è facoltativo.
- Il account di servizio deve disporre delle autorizzazioni richieste.
(Facoltativo) Nella sezione Opzioni di notifica, segui questi passaggi:
- Fai clic sul pulsante di attivazione/disattivazione Notifiche via email se vuoi che l'amministratore del trasferimento riceva una notifica via email quando l'esecuzione di un trasferimento non riesce.
- Fai clic sul pulsante di attivazione/disattivazione Notifiche Pub/Sub per configurare le notifiche di esecuzione di Pub/Sub per il trasferimento. In Seleziona un argomento Pub/Sub, scegli il nome dell'argomento o fai clic su Crea un argomento.
Fai clic su Salva.
Nella pagina Dettagli trasferimento, fai clic sulla scheda Configurazione.
Prendi nota del nome della risorsa per questo trasferimento perché ti servirà per eseguire l'agente di migrazione.
bq
Quando crei un trasferimento Cloud Storage utilizzando lo strumento bq, la configurazione del trasferimento viene impostata in modo che si ripeta ogni 24 ore. Per i trasferimenti on demand, utilizza la console Cloud de Confiance o l'API BigQuery Data Transfer Service.
Non puoi configurare le notifiche utilizzando lo strumento bq.
Inserisci il comando
bq mk
e fornisci il flag di creazione del trasferimento
--transfer_config. Sono necessari anche i seguenti flag:
--data_source--display_name--target_dataset--params
bq mk \ --transfer_config \ --project_id=project ID \ --target_dataset=dataset \ --display_name=name \ --service_account_name=service_account \ --params='parameters' \ --data_source=data source
Dove:
- project ID è l'ID progetto. Se non viene fornito
--project_idper specificare un progetto particolare, viene utilizzato il progetto predefinito. - dataset è il set di dati di destinazione (
--target_dataset) per la configurazione del trasferimento. - name è il nome visualizzato (
--display_name) per la configurazione del trasferimento. Il nome visualizzato del trasferimento può essere qualsiasi valore che ti consenta di identificare il trasferimento se devi modificarlo in un secondo momento. - service_account è il nome del account di servizio utilizzato per autenticare il trasferimento. Il account di servizio deve
essere di proprietà dello stesso
project_idutilizzato per creare il trasferimento e deve disporre di tutte le autorizzazioni richieste elencate. - parameters contiene i parametri (
--params) per la configurazione di trasferimento creata in formato JSON. Ad esempio--params='{"param":"param_value"}'.- Per le migrazioni di Teradata, utilizza i seguenti parametri:
bucketè il bucket Cloud Storage che fungerà da area di gestione temporanea durante la migrazione.database_typeè Teradata.agent_service_accountè l'indirizzo email associato al account di servizio che hai creato.database_nameè il nome del database di origine in Teradata.table_name_patternsè un pattern o più pattern per la corrispondenza dei nomi delle tabelle nel database di origine. Puoi utilizzare le espressioni regolari per specificare il pattern. Il pattern deve seguire la sintassi delle espressioni regolari Java. Ad esempio:sales|expensescorrisponde alle tabelle denominatesaleseexpenses..*corrisponde a tutte le tabelle.
is_direct_gcs_unload_enabledè un flag booleano per abilitare lo scaricamento diretto in Cloud Storage.
- Per le migrazioni di Teradata, utilizza i seguenti parametri:
- data_source è l'origine dati (
--data_source):on_premises.
Ad esempio, il seguente comando crea un trasferimento Teradata
denominato My Transfer utilizzando il bucket Cloud Storage mybucket e il set di dati di destinazione
mydataset. Il trasferimento eseguirà la migrazione di tutte le tabelle dal data warehouse Teradata mydatabase e il file di schema facoltativo è myschemafile.json.
bq mk \ --transfer_config \ --project_id=123456789876 \ --target_dataset=MyDataset \ --display_name='My Migration' \ --params='{"bucket": "mybucket", "database_type": "Teradata", "database_name":"mydatabase", "table_name_patterns": ".*", "agent_service_account":"myemail@mydomain.com", "schema_file_path": "gs://mybucket/myschemafile.json", "is_direct_gcs_unload_enabled": true}' \ --data_source=on_premises
Dopo aver eseguito il comando, ricevi un messaggio simile al seguente:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Segui le istruzioni e incolla il codice di autenticazione nella riga di comando.
API
Utilizza il metodo projects.locations.transferConfigs.create e fornisci un'istanza della risorsa TransferConfig.
Java
Prima di provare questo esempio, segui le istruzioni di configurazione di Java nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Java.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configura l'autenticazione per le librerie client.
Prima di eseguire gli esempi di codice, imposta la variabile di ambiente
GOOGLE_CLOUD_UNIVERSE_DOMAIN su s3nsapis.fr.
Agente di migrazione
Se vuoi, puoi configurare il trasferimento direttamente dall'agente di migrazione. Per maggiori informazioni, vedi Inizializzare l'agente di migrazione.
Inizializzare l'agente di migrazione
Per un nuovo trasferimento, devi inizializzare l'agente di migrazione. L'inizializzazione è richiesta una sola volta per un trasferimento, indipendentemente dal fatto che sia ricorrente o meno. L'inizializzazione configura solo l'agente di migrazione, non avvia il trasferimento.
Se utilizzerai l'agente di migrazione per creare un file di schema personalizzato,
assicurati di avere una directory scrivibile nella directory di lavoro
con lo stesso nome del progetto che vuoi utilizzare per il
trasferimento. Qui l'agente di migrazione crea il file di schema.
Ad esempio, se lavori in /home e configuri
il trasferimento nel progetto myProject, crea la directory /home/myProject
e assicurati che sia scrivibile dagli utenti.
Apri una nuova sessione. Nella riga di comando, esegui il comando di inizializzazione, che segue questo formato:
java -cp \ OS-specific-separated-paths-to-jars (JDBC and agent) \ com.google.cloud.bigquery.dms.Agent \ --initialize
L'esempio seguente mostra il comando di inizializzazione quando i file JAR del driver JDBC e dell'agente di migrazione si trovano in una directory
migrationlocale:Unix, Linux, Mac OS
java -cp \ /usr/local/migration/terajdbc4.jar:/usr/local/migration/mirroring-agent.jar \ com.google.cloud.bigquery.dms.Agent \ --initialize
Windows
Copia tutti i file nella cartella
C:\migration(o modifica i percorsi nel comando), poi esegui:java -cp C:\migration\terajdbc4.jar;C:\migration\mirroring-agent.jar com.google.cloud.bigquery.dms.Agent --initialize
Quando richiesto, configura le seguenti opzioni:
- Scegli se salvare il modello Teradata Parallel Transporter (TPT) su disco. Se prevedi di utilizzare il metodo di estrazione TPT, puoi modificare il modello salvato con i parametri adatti alla tua istanza Teradata.
- Digita il percorso di una directory locale che il job di trasferimento può utilizzare per l'estrazione dei file. Assicurati di avere lo spazio di archiviazione minimo consigliato come descritto in Metodo di estrazione.
- Digita il nome host del database.
- Digita la porta del database.
- Scegli se utilizzare Teradata Parallel Transporter (TPT) come metodo di estrazione.
- (Facoltativo) Digita il percorso di un file delle credenziali del database.
Scegli se specificare un nome di configurazione di BigQuery Data Transfer Service.
Se stai inizializzando l'agente di migrazione per un trasferimento che hai già configurato, procedi nel seguente modo:
- Digita il nome della risorsa del trasferimento. Puoi trovarlo nella scheda Configurazione della pagina Dettagli trasferimento per il trasferimento.
- Quando richiesto, digita un percorso e un nome file per il file di configurazione dell'agente di migrazione che verrà creato. Fai riferimento a questo file quando esegui l'agente di migrazione per avviare il trasferimento.
- Ignora i passaggi rimanenti.
Se utilizzi l'agente di migrazione per configurare un trasferimento, premi Invio per passare al prompt successivo.
Digita l'ID progetto Cloud de Confiance by S3NS .
Digita il nome del database di origine in Teradata.
Digita un pattern per la corrispondenza dei nomi delle tabelle nel database di origine. Puoi utilizzare le espressioni regolari per specificare il pattern. Ad esempio:
sales|expensescorrisponde alle tabelle denominatesaleseexpenses..*corrisponde a tutte le tabelle.
(Facoltativo) Digita il percorso di un file di schema JSON locale. Questa opzione è vivamente consigliata per i trasferimenti ricorrenti.
Se non utilizzi un file schema o se vuoi che l'agente di migrazione ne crei uno per te, premi Invio per passare al prompt successivo.
Scegli se creare un nuovo file schema.
Se vuoi creare un file dello schema:
- Digita
yes - Digita il nome utente di un utente Teradata che disponga dell'accesso in lettura alle tabelle di sistema e alle tabelle di cui vuoi eseguire la migrazione.
Digita la password per l'utente.
L'agente di migrazione crea il file dello schema e ne restituisce la posizione.
Modifica il file schema per contrassegnare le colonne di partizionamento, clustering, chiavi primarie e monitoraggio delle modifiche e verifica di voler utilizzare questo schema per la configurazione del trasferimento. Per suggerimenti, consulta File schema personalizzato.
Premi
Enterper passare al prompt successivo.
Se non vuoi creare un file di schema, digita
no.- Digita
Digita il nome del bucket Cloud Storage di destinazione per la migrazione di gestione temporanea dei dati prima del caricamento in BigQuery. Se l'agente di migrazione ha creato un file di schema personalizzato, questo viene caricato anche in questo bucket.
Digita il nome del set di dati di destinazione in BigQuery.
Digita un nome visualizzato per la configurazione del trasferimento.
Digita un percorso e un nome file per il file di configurazione dell'agente di migrazione che verrà creato.
Dopo aver inserito tutti i parametri richiesti, l'agente di migrazione crea un file di configurazione e lo restituisce al percorso locale specificato. Per un'analisi più approfondita del file di configurazione, consulta la sezione successiva.
File di configurazione per l'agente di migrazione
Il file di configurazione creato nel passaggio di inizializzazione è simile a questo esempio:
{
"agent-id": "81f452cd-c931-426c-a0de-c62f726f6a6f",
"transfer-configuration": {
"project-id": "123456789876",
"location": "us",
"id": "61d7ab69-0000-2f6c-9b6c-14c14ef21038"
},
"source-type": "teradata",
"console-log": false,
"silent": false,
"teradata-config": {
"connection": {
"host": "localhost"
},
"local-processing-space": "extracted",
"database-credentials-file-path": "",
"max-local-storage": "50GB",
"gcs-upload-chunk-size": "32MB",
"use-tpt": true,
"transfer-views": false,
"max-sessions": 0,
"spool-mode": "NoSpool",
"max-parallel-upload": 4,
"max-parallel-extract-threads": 1,
"session-charset": "UTF8",
"max-unload-file-size": "2GB"
}
}
Opzioni del job di trasferimento nel file di configurazione dell'agente di migrazione
transfer-configuration: informazioni su questa configurazione di trasferimento in BigQuery.teradata-config: Informazioni specifiche per questa estrazione di Teradata:connection: Informazioni sull'hostname e sulla portalocal-processing-space: la cartella di estrazione in cui l'agente estrarrà i dati della tabella prima di caricarli in Cloud Storage.database-credentials-file-path: (facoltativo) il percorso di un file che contiene le credenziali per la connessione automatica al database Teradata. Il file deve contenere due righe per le credenziali. Puoi utilizzare un nome utente/password, come mostrato nell'esempio seguente:username=abc password=123
username=abc secret_resource_id=projects/my-project/secrets/my-secret-name/versions/1
max-local-storage: la quantità massima di spazio di archiviazione locale da utilizzare per l'estrazione nella directory di staging specificata. Il valore predefinito è50GB. Il formato supportato è:numberKB|MB|GB|TB.In tutte le modalità di estrazione, i file vengono eliminati dalla directory di staging locale dopo essere stati caricati in Cloud Storage.
use-tpt: indica all'agente di migrazione di utilizzare Teradata Parallel Transporter (TPT) come metodo di estrazione.Per ogni tabella, l'agente di migrazione genera uno script TPT, avvia un processo
tbuilde attende il completamento. Al termine del processotbuild, l'agente elenca e carica i file estratti in Cloud Storage, quindi elimina lo script TPT. Per ulteriori informazioni, consulta la sezione Metodo di estrazione.transfer-views: indica all'agente di migrazione di trasferire anche i dati dalle visualizzazioni. Utilizza questa opzione solo quando è necessaria la personalizzazione dei dati durante la migrazione. In altri casi, esegui la migrazione delle viste alle viste BigQuery. Questa opzione presenta i seguenti prerequisiti:- Puoi utilizzare questa opzione solo con Teradata versione 16.10 e successive.
- Una vista deve avere una colonna "partition" di tipo integer definita, che punta a un ID di partizione per la riga specificata nella tabella sottostante.
max-sessions: specifica il numero massimo di sessioni utilizzate dal job di estrazione (FastExport o TPT). Se impostato su 0, il database Teradata determinerà il numero massimo di sessioni per ogni job di estrazione.gcs-upload-chunk-size: un file di grandi dimensioni viene caricato in Cloud Storage in blocchi. Questo parametro, insieme amax-parallel-upload, viene utilizzato per controllare la quantità di dati caricati contemporaneamente in Cloud Storage. Ad esempio, segcs-upload-chunk-sizeè 64 MB emax-parallel-uploadè 10 MB, teoricamente un agente di migrazione può caricare 640 MB (64 MB * 10) di dati contemporaneamente. Se il caricamento del blocco non riesce, è necessario riprovare a caricarlo. La dimensione del chunk deve essere ridotta.max-parallel-upload: questo valore determina il numero massimo di thread utilizzati dall'agente di migrazione per caricare i file in Cloud Storage. Se non specificato, il valore predefinito è il numero di processori disponibili per la macchina virtuale Java. La regola generale è di scegliere il valore in base al numero di core della macchina che esegue l'agente. Quindi, se haincore, il numero ottimale di thread dovrebbe esseren. Se i core sono hyper-threaded, il numero ottimale dovrebbe essere(2 * n). Esistono anche altre impostazioni, come la larghezza di banda di rete, da considerare durante la regolazione dimax-parallel-upload. La regolazione di questo parametro può migliorare le prestazioni di caricamento su Cloud Storage.spool-mode: nella maggior parte dei casi, la modalità NoSpool è l'opzione migliore.NoSpoolè il valore predefinito nella configurazione dell'agente. Puoi modificare questo parametro se si applica al tuo caso uno qualsiasi degli svantaggi di NoSpool.max-unload-file-size: determina la dimensione massima del file estratto. Questo parametro non viene applicato per le estrazioni TPT.max-parallel-extract-threads: questa configurazione viene utilizzata solo in modalità FastExport. Determina il numero di thread paralleli utilizzati per estrarre i dati da Teradata. La modifica di questo parametro potrebbe migliorare le prestazioni dell'estrazione.tpt-template-path: utilizza questa configurazione per fornire uno script di estrazione TPT personalizzato come input. Puoi utilizzare questo parametro per applicare le trasformazioni ai dati di migrazione.tpt-export-count: l'operatore di esportazione è responsabile dell'estrazione dei dati dal database Teradata. Questo parametro esegue l'override del conteggio di esportazione predefinito nello script TPT. Deve essere inferiore o uguale al valore del parametromax-sessionsper garantire che ogni istanza disponga di un numero sufficiente di pipe al database.tpt-file-writer-count: l'operatore di scrittura dei file è responsabile dell'acquisizione dei dati ricevuti dall'operatore di esportazione e della loro scrittura in un file fisico sul sistema di archiviazione. Questo parametro sostituisce il conteggio predefinito dei writer di file nello script TPT. Idealmente, il numero di scrittori di file deve corrispondere al numero di esportazioni; in caso contrario, il trasferimento diventa un collo di bottiglia all'estrazione o alla fine della scrittura.schema-mapping-rule-path: (facoltativo) il percorso di un file di configurazione che contiene una mappatura dello schema per ignorare le regole di mappatura predefinite. Alcuni tipi di mapping funzionano solo con la modalità Teradata Parallel Transporter (TPT).Esempio: mappatura dal tipo Teradata
TIMESTAMPal tipo BigQueryDATETIME:{ "rules": [ { "database": { "name": "database.*", "tables": [ { "name": "table.*" } ] }, "match": { "type": "COLUMN_TYPE", "value": "TIMESTAMP" }, "action": { "type": "MAPPING", "value": "DATETIME" } } ] }
Attributi:
database: (facoltativo)nameè un'espressione regolare per i database da includere. Per impostazione predefinita, sono inclusi tutti i database.tables: (facoltativo) contiene un array di tabelle.nameè un'espressione regolare per le tabelle da includere. Per impostazione predefinita, sono incluse tutte le tabelle.match: (obbligatorio)- Valori supportati per
type:COLUMN_TYPE. - Valori supportati per
value:TIMESTAMP,DATETIME.
- Valori supportati per
action: (obbligatorio)- Valori supportati per
type:MAPPING. - Valori supportati per
value:TIMESTAMP,DATETIME.
- Valori supportati per
compress-output: (facoltativo) indica se i dati devono essere compressi prima di essere archiviati in Cloud Storage. Questa impostazione viene applicata solo in tpt-mode. Per impostazione predefinita, questo valore èfalse.gcs-module-config-dir: (facoltativo) il percorso del file delle credenziali per accedere al bucket Cloud Storage. La directory predefinita è$HOME/.gcs, ma puoi utilizzare questo parametro per modificare la directory.gcs-module-connection-count: (facoltativo) specifica il numero di connessioni TCP al servizio Cloud Storage. Il valore predefinito è 10.gcs-module-buffer-size: (facoltativo) specifica la dimensione dei buffer da utilizzare per le connessioni TCP. Il valore predefinito è 8 MB (8388608 byte). Per facilità d'uso, puoi utilizzare i seguenti moltiplicatori:k (1000)K (1024)m (1000 * 1000)M (1024*1024)
gcs-module-buffer-count: (facoltativo) specifica il numero di buffer da utilizzare con le connessioni TCP specificate dagcs-module-connection-count. Ti consigliamo di utilizzare un valore pari al doppio del numero di connessioni TCP al servizio Cloud Storage. Il valore predefinito è 2 *gcs-module-connection-count.gcs-module-max-object-size: (facoltativo). Questo parametro controlla le dimensioni degli oggetti Cloud Storage. Il valore di questo parametro può essere un numero intero o un numero intero seguito, senza spazi, da uno dei seguenti moltiplicatori:k (1000)K (1024)m (1000 * 1000)M (1024*1024)
gcs-module-writer-instances: (facoltativo). Questo parametro specifica il numero di istanze di scrittura di Cloud Storage. Per impostazione predefinita, il valore è 1. Puoi aumentare questo valore per incrementare il throughput durante la fase di scrittura dell'esportazione TPT.
Ottimizzare l'estrazione dei dati degli agenti
Ottimizzando i parametri dell'agente, puoi ottimizzare il processo di estrazione dei dati e rendere efficiente l'intero processo di trasferimento.
La seguente tabella fornisce informazioni sui parametri che puoi utilizzare per ottimizzare la migrazione:
| Parametro | Valore consigliato | Descrizione |
|---|---|---|
gcs-module-writer-instances |
4 | Aumenta il parallelismo per le operazioni di estrazione TPT e scrittura di Cloud Storage. Regola questo valore per bilanciare l'ottimizzazione del trasferimento e il carico dell'istanza Teradata. |
gcs-module-connection-count |
10 | Imposta il numero di connessioni TCP a Cloud Storage. L'aumento di questo valore migliora la parallelizzazione durante la fase di caricamento di Cloud Storage. |
gcs-module-buffer-size |
32 min | Definisce la dimensione dei buffer per le connessioni TCP. I test indicano che 32m fornisce risultati ottimali. |
tpt-export-count |
Deve essere minore o uguale al valore di max-sessions. |
Esegue l'override del conteggio predefinito degli operatori di esportazione nello script TPT. Il valore deve essere minore o uguale al valore di max-sessions per garantire che ogni istanza abbia un numero sufficiente di pipe al database. |
tpt-file-writer-count |
Deve essere uguale al valore export-count. |
Esegue l'override del conteggio predefinito degli operatori di scrittura dei file nello script TPT. Idealmente, questo valore deve corrispondere al valore tpt-export-count per evitare colli di bottiglia. |
Considera le seguenti best practice per la configurazione:
Vincolo di memoria: assicurati che il risultato del seguente calcolo sia inferiore alla memoria totale della macchina virtuale (VM) che esegue l'agente. Utilizza unità di misura coerenti per tutti i valori nel calcolo.
$$ \text{gcs-module-writer-instances} \times \text{gcs-module-buffer-size} \times \text{gcs-module-buffer-count} < \text{Total VM memory} $$Ordine di ottimizzazione:
- Regola prima il valore parametro
gcs-module-writer-instancesper trovare il miglior equilibrio tra prestazioni e carico. - Se sono necessari ulteriori miglioramenti del rendimento, aumenta il valore di
gcs-module-connection-count.
- Regola prima il valore parametro
Scalabilità automatica: per impostazione predefinita, il valore del parametro
gcs-module-buffer-sizeè in genere impostato sul doppio del conteggio delle connessioni, ma consigliamo di ottimizzare esplicitamente il valore su32mper questi carichi di lavoro.
Esegui l'agente di migrazione
Dopo aver inizializzato l'agente di migrazione e creato il file di configurazione, segui i passaggi riportati di seguito per eseguire l'agente e avviare la migrazione:
Esegui l'agente specificando i percorsi del driver JDBC, dell'agente di migrazione e del file di configurazione creato nel passaggio di inizializzazione precedente.
java -cp \ OS-specific-separated-paths-to-jars (JDBC and agent) \ com.google.cloud.bigquery.dms.Agent \ --configuration-file=path to configuration file
Unix, Linux, Mac OS
java -cp \ /usr/local/migration/Teradata/JDBC/terajdbc4.jar:mirroring-agent.jar \ com.google.cloud.bigquery.dms.Agent \ --configuration-file=config.json
Windows
Copia tutti i file nella cartella
C:\migration(o modifica i percorsi nel comando), poi esegui:java -cp C:\migration\terajdbc4.jar;C:\migration\mirroring-agent.jar com.google.cloud.bigquery.dms.Agent --configuration-file=config.json
Se vuoi procedere con la migrazione, premi
Entere l'agente procederà se il classpath fornito durante l'inizializzazione è valido.Quando ti viene chiesto, digita il nome utente e la password per la connessione al database. Se il nome utente e la password sono validi, inizia la migrazione dei dati.
(Facoltativo) Nel comando per avviare la migrazione, puoi anche utilizzare un flag che passa un file di credenziali all'agente, anziché inserire il nome utente e la password ogni volta. Per saperne di più, consulta il parametro facoltativo
database-credentials-file-pathnel file di configurazione dell'agente. Quando utilizzi un file delle credenziali, adotta le misure appropriate per controllare l'accesso alla cartella in cui lo memorizzi sul file system locale, perché non è criptato.Lascia aperta questa sessione fino al completamento della migrazione. Se hai creato un trasferimento di migrazione ricorrente, mantieni aperta questa sessione a tempo indeterminato. Se questa sessione viene interrotta, le esecuzioni di trasferimento attuali e future non vanno a buon fine.
Monitora periodicamente se l'agente è in esecuzione. Se un trasferimento è in corso e nessun agente risponde entro 24 ore, il trasferimento non va a buon fine.
Se l'agente di migrazione smette di funzionare durante il trasferimento o la pianificazione, la console Cloud de Confiance mostra lo stato di errore e ti chiede di riavviare l'agente. Per riavviare l'agente di migrazione, torna all'inizio di questa sezione. Non è necessario ripetere il comando di inizializzazione. Il trasferimento riprende dal punto in cui le tabelle non sono state completate.
Monitorare l'avanzamento della migrazione
Puoi visualizzare lo stato della migrazione nella console Cloud de Confiance . Puoi anche configurare notifiche Pub/Sub o email. Consulta Notifiche di BigQuery Data Transfer Service.
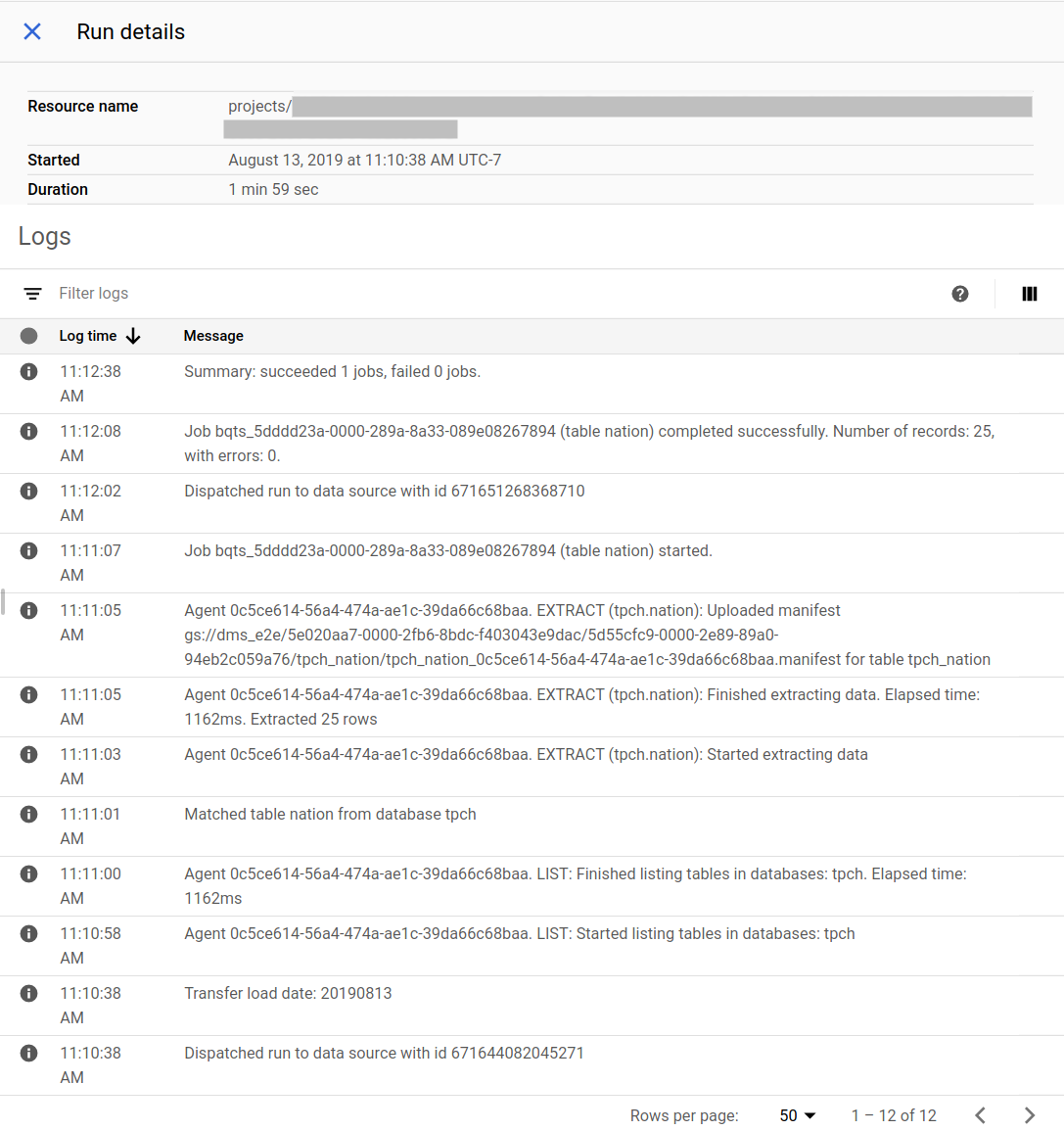
BigQuery Data Transfer Service pianifica e avvia un'esecuzione del trasferimento in base a una pianificazione specificata al momento della creazione della configurazione del trasferimento. È importante che l'agente di migrazione sia in esecuzione quando un'esecuzione del trasferimento è attiva. Se non vengono ricevuti aggiornamenti dall'agente entro 24 ore, l'esecuzione del trasferimento non va a buon fine.
Esempio di stato della migrazione nella console Cloud de Confiance :
Esegui l'upgrade dell'agente di migrazione
Se è disponibile una nuova versione dell'agente di migrazione, devi aggiornarlo manualmente. Per ricevere notifiche relative a BigQuery Data Transfer Service, iscriviti alle note di rilascio.
Passaggi successivi
- Prova una migrazione di test da Teradata a BigQuery.
- Scopri di più su BigQuery Data Transfer Service.
- Esegui la migrazione del codice SQL con la traduzione SQL batch.