
Esegui la migrazione del codice con il traduttore SQL batch
Questo documento descrive come utilizzare il traduttore SQL batch in BigQuery per tradurre script scritti in altri dialetti SQL in query GoogleSQL. Questo documento è destinato agli utenti che hanno familiarità con la consoleCloud de Confiance .
Prima di iniziare
Prima di inviare un job di traduzione, completa i seguenti passaggi:
- Assicurati di disporre di tutte le autorizzazioni richieste.
- Abilita l'API BigQuery Migration.
- Raccogli i file di origine contenenti gli script e le query SQL da tradurre.
- Facoltativo. Crea un file di metadati per migliorare l'accuratezza della traduzione.
- Facoltativo. Decidi se devi mappare i nomi degli oggetti SQL nei file di origine con nuovi nomi in BigQuery. Determina quali regole di mappatura dei nomi utilizzare, se necessario.
- Decidi quale metodo utilizzare per inviare il lavoro di traduzione.
- Carica i file di origine su Cloud Storage.
Autorizzazioni obbligatorie
Per abilitare BigQuery Migration Service, devi disporre delle seguenti autorizzazioni per il progetto:
resourcemanager.projects.getserviceusage.services.enableserviceusage.services.get
Per accedere e utilizzare BigQuery Migration Service, devi disporre delle seguenti autorizzazioni per il progetto:
bigquerymigration.workflows.createbigquerymigration.workflows.getbigquerymigration.workflows.listbigquerymigration.workflows.deletebigquerymigration.subtasks.getbigquerymigration.subtasks.listIn alternativa, puoi utilizzare i seguenti ruoli per ottenere le stesse autorizzazioni:
bigquerymigration.viewer- Accesso di sola lettura.bigquerymigration.editor- Accesso in lettura/scrittura.
Per accedere ai bucket Cloud Storage per i file di input e output:
storage.objects.getsul bucket Cloud Storage di origine.storage.objects.listsul bucket Cloud Storage di origine.storage.objects.createsul bucket Cloud Storage di destinazione.
Puoi disporre di tutte le autorizzazioni Cloud Storage necessarie dai seguenti ruoli:
roles/storage.objectAdminroles/storage.admin
Abilita l'API BigQuery Migration
Se il tuo progetto Google Cloud CLI è stato creato prima del 15 febbraio 2022, abilita l'API BigQuery Migration nel seguente modo:
Nella console Cloud de Confiance , vai alla pagina API BigQuery Migration.
Fai clic su Attiva.
Raccogliere i file di origine
I file di origine devono essere file di testo contenenti SQL valido per il dialetto di origine. I file di origine possono includere anche commenti. Fai del tuo meglio per assicurarti che l'SQL sia valido, utilizzando tutti i metodi a tua disposizione.
Creare file di metadati
Per aiutare il servizio a generare risultati di traduzione più accurati, ti consigliamo di fornire file di metadati. Tuttavia, questa operazione non è obbligatoria.
Puoi utilizzare lo strumento di estrazione da riga di comando dwh-migration-dumper per generare le informazioni sui metadati oppure puoi fornire i tuoi file di metadati. Una volta preparati i file di metadati, puoi includerli insieme ai file di origine nella cartella di origine della traduzione. Il traduttore li rileva automaticamente e li utilizza per tradurre i file di origine, senza che tu debba configurare impostazioni aggiuntive.
Per generare informazioni sui metadati utilizzando lo
strumento dwh-migration-dumper, consulta
Generare metadati per la traduzione.
Per fornire i tuoi metadati, raccogli le istruzioni del linguaggio di definizione dei dati (DDL) per gli oggetti SQL nel sistema di origine in file di testo separati.
Decidi come inviare il job di traduzione
Hai tre opzioni per inviare un job di traduzione batch:
Client di traduzione batch: configura un job modificando le impostazioni in un file di configurazione e invia il job utilizzando la riga di comando. Questo approccio non richiede il caricamento manuale dei file di origine su Cloud Storage. Il client utilizza ancora Cloud Storage per archiviare i file durante l'elaborazione del job di traduzione.
Il client di traduzione batch legacy è un client Python open source che ti consente di tradurre i file di origine che si trovano sulla tua macchina locale e di inviare i file tradotti a una directory locale. Configura il client per l'utilizzo di base modificando alcune impostazioni nel relativo file di configurazione. Se vuoi, puoi anche configurare il client per gestire attività più complesse come la sostituzione delle macro e l'elaborazione pre e post degli input e degli output di traduzione. Per saperne di più, consulta il readme del client di traduzione batch.
Cloud de Confiance Console: configura e invia un job utilizzando un'interfaccia utente. Questo approccio richiede il caricamento dei file di origine su Cloud Storage.
Crea file YAML di configurazione
Se vuoi, puoi creare e utilizzare file YAML di configurazione per personalizzare le traduzioni batch. Questi file possono essere utilizzati per trasformare l'output della traduzione in vari modi. Ad esempio, puoi creare un file YAML di configurazione per modificare le maiuscole e minuscole di un oggetto SQL durante la traduzione.
Se vuoi utilizzare la console Cloud de Confiance o l'API BigQuery Migration per un job di traduzione batch, puoi caricare il file YAML di configurazione nel bucket Cloud Storage contenente i file di origine.
Se vuoi utilizzare il client di traduzione batch, puoi inserire il file YAML di configurazione nella cartella di input della traduzione locale.
Carica i file di input su Cloud Storage
Se vuoi utilizzare la Cloud de Confiance console o l'API BigQuery Migration per eseguire un job di traduzione, devi caricare i file di origine contenenti le query e gli script che vuoi tradurre in Cloud Storage. Puoi caricare anche eventuali file di metadati o file YAML di configurazione nello stesso bucket Cloud Storage e nella stessa directory contenenti i file di origine. Per saperne di più sulla creazione di bucket e sul caricamento di file in Cloud Storage, consulta Creare bucket e Caricare oggetti da un file system.
Dialetti SQL supportati
Il traduttore SQL batch fa parte di BigQuery Migration Service. Il traduttore SQL batch può tradurre i seguenti dialetti SQL in GoogleSQL:
- Amazon Redshift SQL
- Apache HiveQL e interfaccia a riga di comando Beeline
- IBM Netezza SQL e NZPLSQL
- Teradata e Teradata Vantage:
- SQL
- Basic Teradata Query (BTEQ)
- Teradata Parallel Transport (TPT)
Inoltre, la traduzione dei seguenti dialetti SQL è supportata in anteprima:
- SQL Apache Impala
- Apache Spark SQL
- Azure Synapse T-SQL
- GoogleSQL (BigQuery)
- Greenplum SQL
- IBM DB2 SQL
- MySQL SQL
- Oracle SQL, PL/SQL, Exadata
- SQL PostgreSQL
- Trino o PrestoSQL
- Snowflake SQL
- SQL Server T-SQL
- SQLite
- Vertica SQL
Gestione delle funzioni SQL non supportate con le funzioni definite dall'utente di assistenza
Quando si traduce SQL da un dialetto di origine a BigQuery, alcune funzioni potrebbero non avere un equivalente diretto. Per risolvere questo problema, BigQuery Migration Service (e la community BigQuery più ampia) forniscono funzioni definite dall'utente (UDF) helper che replicano il comportamento di queste funzioni del dialetto di origine non supportate.
Queste UDF si trovano spesso nel set di dati pubblico bqutil, consentendo alle query tradotte di farvi riferimento inizialmente utilizzando il formato bqutil.<dataset>.<function>(). Ad esempio: bqutil.fn.cw_count().
Considerazioni importanti per gli ambienti di produzione:
Sebbene bqutil offra un accesso comodo a queste UDF helper per la traduzione e il test iniziali, l'utilizzo diretto di bqutil per i carichi di lavoro di produzione non è consigliato per diversi motivi:
- Controllo delle versioni: il progetto
bqutilospita l'ultima versione di queste UDF, il che significa che le loro definizioni possono cambiare nel tempo. Fare affidamento direttamente abqutilpotrebbe comportare un comportamento imprevisto o modifiche che causano interruzioni nelle query di produzione se la logica di una UDF viene aggiornata. - Isolamento delle dipendenze: il deployment delle UDF nel tuo progetto isola l'ambiente di produzione dalle modifiche esterne.
- Personalizzazione: potresti dover modificare o ottimizzare queste UDF per adattarle meglio alla tua logica di business o ai tuoi requisiti di rendimento specifici. Questa operazione è possibile solo se si trovano all'interno del tuo progetto.
- Sicurezza e governance: le norme di sicurezza della tua organizzazione potrebbero limitare l'accesso diretto a set di dati pubblici come
bqutilper l'elaborazione dei dati di produzione. La copia delle UDF nel tuo ambiente controllato è in linea con queste norme.
Deployment delle UDF helper nel tuo progetto:
Per un utilizzo di produzione affidabile e stabile, devi eseguire il deployment di queste UDF helper nel tuo progetto e nel tuo set di dati. In questo modo, hai il controllo completo della versione, della personalizzazione e dell'accesso. Per istruzioni dettagliate su come eseguire il deployment di queste UDF, consulta la guida al deployment delle UDF su GitHub. Questa guida fornisce gli script e i passaggi necessari per copiare le UDF nel tuo ambiente.
Località
Il traduttore SQL batch è disponibile nelle seguenti posizioni di elaborazione:
| Descrizione della regione | Nome regione | Dettagli | |
|---|---|---|---|
| Asia Pacifico | |||
| Bangkok | asia-southeast3 |
||
| Delhi | asia-south2 |
||
| Hong Kong | asia-east2 |
||
| Giacarta | asia-southeast2 |
||
| Melbourne | australia-southeast2 |
||
| Mumbai | asia-south1 |
||
| Osaka | asia-northeast2 |
||
| Seul | asia-northeast3 |
||
| Singapore | asia-southeast1 |
||
| Sydney | australia-southeast1 |
||
| Taiwan | asia-east1 |
||
| Tokyo | asia-northeast1 |
||
| Europa | |||
| Belgio | europe-west1 |
|
|
| Berlino | europe-west10 |
||
| UE (multi-regione) | eu |
||
| Finlandia | europe-north1 |
|
|
| Francoforte | europe-west3 |
||
| Londra | europe-west2 |
|
|
| Madrid | europe-southwest1 |
|
|
| Milano | europe-west8 |
||
| Paesi Bassi | europe-west4 |
|
|
| Parigi | europe-west9 |
|
|
| Stoccolma | europe-north2 |
|
|
| Torino | europe-west12 |
||
| Varsavia | europe-central2 |
||
| Zurigo | europe-west6 |
|
|
| Americhe | |||
| Columbus, Ohio | us-east5 |
||
| Dallas | us-south1 |
|
|
| Iowa | us-central1 |
|
|
| Las Vegas | us-west4 |
||
| Los Angeles | us-west2 |
||
| Messico | northamerica-south1 |
||
| Virginia del Nord | us-east4 |
||
| Oregon | us-west1 |
|
|
| Québec | northamerica-northeast1 |
|
|
| San Paolo | southamerica-east1 |
|
|
| Salt Lake City | us-west3 |
||
| Santiago | southamerica-west1 |
|
|
| Carolina del Sud | us-east1 |
||
| Toronto | northamerica-northeast2 |
|
|
| Stati Uniti (multi-regione) | us |
||
| Africa | |||
| Johannesburg | africa-south1 |
||
| MiddleEast | |||
| Dammam | me-central2 |
||
| Doha | me-central1 |
||
| Israele | me-west1 |
||
Inviare un job di traduzione
Segui questi passaggi per avviare un progetto di traduzione, visualizzarne l'avanzamento e vedere i risultati.
Console
Questi passaggi presuppongono che tu abbia già caricato i file di origine in un bucket Cloud Storage.
Nella console Cloud de Confiance , vai alla pagina SQL Translation.
Nel riquadro Traduzione SQL, fai clic su Avvia traduzione.
In Configurazione della traduzione, inserisci quanto segue:
- In Nome visualizzato, digita un nome per il job di traduzione. Il nome può contenere lettere, numeri o trattini bassi.
- Per Località di elaborazione, seleziona la località in cui vuoi eseguire il job di traduzione. Ad esempio, se ti trovi in Europa e non vuoi che i dati superino i confini di località, seleziona la regione
eu. Il job di traduzione ha un rendimento migliore quando scegli la stessa posizione del bucket del file di origine. - Per Dialetto di origine, seleziona il dialetto SQL che vuoi tradurre.
- Per Dialetto di destinazione, seleziona GoogleSQL.
Fai clic su Avanti.
Per Dettagli posizione file, specifica i percorsi Cloud Storage da utilizzare per l'input e l'output della traduzione. Puoi digitare i percorsi nel formato
bucket_name/folder_name/o utilizzare l'opzione Sfoglia per passare a una cartella.- Per Posizione della directory di output, specifica un percorso alla cartella Cloud Storage di destinazione per i file tradotti. Questa funge da directory root per tutti gli output di traduzione.
- Scegli una o più posizioni della directory di input contenenti il percorso dei file SQL da tradurre.
- Se necessario, a ogni directory di input può essere assegnato un nome della sottodirectory di output sotto la directory di output principale.
Fai clic su Avanti.
Seleziona le impostazioni facoltative che ti servono per personalizzare i metadati e gli output di traduzione aggiuntivi.
Puoi personalizzare ulteriormente il comportamento di traduzione creando file YAML di configurazione e inserendoli nel bucket Cloud Storage di input. Questi file possono essere utilizzati per impostare la ridenominazione degli oggetti, attivare le ottimizzazioni, migliorare le traduzioni con Gemini e altro ancora. Per ulteriori informazioni sui file YAML di configurazione, vedi Creare un file YAML di configurazione.
Fai clic su Crea per avviare il job di traduzione.
Una volta creato il job di traduzione, puoi visualizzarne lo stato nell'elenco dei job di traduzione.
Client di traduzione batch
Nella directory di installazione del client di traduzione batch, utilizza l'editor di testo che preferisci per aprire il file
config.yamle modificare le seguenti impostazioni:project_number: digita il numero del progetto che vuoi utilizzare per il job di traduzione batch. Puoi trovarlo nel riquadro Informazioni sul progetto della Cloud de Confiance pagina di benvenuto della console per il progetto.gcs_bucket: digita il nome del bucket Cloud Storage che il client di traduzione batch utilizza per archiviare i file durante l'elaborazione del job di traduzione.input_directory: digita il percorso assoluto o relativo della directory contenente i file di origine e gli eventuali file di metadati.output_directory: digita il percorso assoluto o relativo della directory di destinazione per i file tradotti.
Salva le modifiche e chiudi il file
config.yaml.Inserisci i file di origine e dei metadati nella directory di input.
Esegui il client di traduzione batch utilizzando questo comando:
bin/dwh-migration-clientCrea un job di traduzione.
L'esempio seguente mostra un comando per creare un job di traduzione. Il comando eseguirà il flusso di lavoro e mostrerà l'output se il flusso di lavoro ha esito positivo.
gcloud bq migration-workflows create --location=us --config-file=CONFIG_FILE_NAME.json
L'esempio seguente mostra un comando per creare ed eseguire il flusso di lavoro con il flag
--async. Il comando creerà ed eseguirà il flusso di lavoro e restituirà immediatamente un link al flusso di lavoro.gcloud bq migration-workflows create --location=LOCATION --config-file=CONFIG_FILE_NAME.json --async
L'esempio seguente mostra un comando per elencare i job di traduzione:
gcloud bq migration-workflows list --location=LOCATION
Sostituisci quanto segue:
LOCATION: la posizione del progetto Cloud de Confiance by S3NS che esegue questo job di traduzione.CONFIG_FILE_NAME: il nome del fileconfig.yaml. Una volta creato il job di traduzione, puoi visualizzarne lo stato nell'elenco dei job di traduzione nella console Cloud de Confiance .
Facoltativo. Una volta completato il job di traduzione, elimina i file creati dal job nel bucket Cloud Storage specificato per evitare costi di archiviazione.
CLI di BigQuery
Puoi eseguire lo strumento di traduzione SQL batch utilizzando lo strumento a riga di comando bq con i seguenti passaggi:
Crea un file di configurazione della traduzione in formato YAML o JSON. In questo file devi definire il percorso del file di origine, la destinazione di output e i dialetti di origine e di destinazione della traduzione.
Il seguente esempio mostra un file YAML di configurazione della traduzione per una traduzione da Teradata a BigQuery:
tasks: translation_task: type: Teradata2BigQuery_Translation translationDetails: sourceTargetMapping: - sourceSpec: baseUri: gs://bq-translations/input targetSpec: relativePath: output targetBaseUri: gs://bq-translations targetTypes: - sql sourceEnvironment: defaultDatabase: default_db schemaSearchPath: - foo
L'esempio seguente mostra un file JSON di configurazione della traduzione per una traduzione da Teradata a BigQuery:
{ "tasks": { "translation_task": { "type": "Teradata2BigQuery_Translation", "translationDetails": { "sourceTargetMapping": [ { "sourceSpec": { "literal": { "literalString": "sel 1", "relativePath": "my_input_1" }, "encoding": "UTF-8" } }, { "sourceSpec": { "literal": { "literalString": "sel 2", "relativePath": "my_input_2" }, "encoding": "UTF-8" } } ], "targetReturnLiterals": [ "sql/my_input_1", "sql/my_input_2" ] } } } }
Una volta creata la configurazione di traduzione, esegui il comando seguente per eseguire il job di traduzione.
bq mk --migration_workflow --location=LOCATION --config_file=CONFIG_FILE_NAME.json
Sostituisci quanto segue:
LOCATION: la posizione del progetto Cloud de Confiance by S3NS che esegue questo job di traduzione.CONFIG_FILE_NAME: il nome del fileconfig.yaml.
Per visualizzare i dettagli di uno specifico job di traduzione, esegui questo comando:
bq show --migration_workflow projects/PROJECT_ID/ locations/us/workflows/WORKFLOW_ID
Sostituisci quanto segue:
PROJECT_ID: l'ID del progetto Cloud de Confiance by S3NS che esegue questo job di traduzione.WORKFLOW_ID: l'ID del job di traduzione.
Per visualizzare i risultati di uno specifico job di traduzione, esegui questo comando:
gcloud bq migration-workflows describe projects/PROJECT_ID /locations/us/workflows/WORKFLOW_ID
Per rimuovere un job di traduzione dall'elenco, esegui questo comando:
bq rm --migration_workflow projects/PROJECT_ID/locations/us/workflows/WORKFLOW_ID
Per elencare tutti i tuoi job di traduzione, esegui questo comando:
bq ls --migration_workflow --location=LOCATION
Esplora l'output della traduzione
Dopo aver eseguito il job di traduzione, puoi visualizzare le informazioni sul job nella console Cloud de Confiance . Se hai utilizzato la console Cloud de Confiance per eseguire il job, puoi visualizzare i risultati del job nel bucket Cloud Storage di destinazione che hai specificato. Se hai utilizzato il client di traduzione batch per eseguire il job, puoi visualizzare i risultati del job nella directory di output che hai specificato. Il traduttore SQL batch genera i seguenti file nella destinazione specificata:
- I file tradotti.
- Il report di riepilogo della traduzione in formato CSV.
- Il mapping dei nomi degli output utilizzati in formato JSON.
- I file di suggerimenti dell'AI.
Cloud de Confiance console output
Per visualizzare i dettagli di un progetto di traduzione:
Nella console Cloud de Confiance , vai alla pagina SQL Translation.
Nell'elenco dei job di traduzione, individua quello per cui vuoi visualizzare i dettagli della traduzione. Quindi, fai clic sul nome del job di traduzione. Puoi visualizzare una visualizzazione Sankey che illustra la qualità complessiva del job, il numero di righe di codice di input (escluse le righe vuote e i commenti) e un elenco dei problemi che si sono verificati durante il processo di traduzione. Devi dare la priorità alle correzioni da sinistra a destra. I problemi in una fase iniziale possono causare problemi aggiuntivi nelle fasi successive.
Tieni il puntatore sopra le barre di errore o avviso e rivedi i suggerimenti per determinare i passaggi successivi per eseguire il debug del job di traduzione.
Seleziona la scheda Riepilogo log per visualizzare un riepilogo dei problemi di traduzione, incluse le categorie di problemi, le azioni suggerite e la frequenza con cui si è verificato ciascun problema. Puoi fare clic sulle barre della visualizzazione Sankey per filtrare i problemi. Puoi anche selezionare una categoria di problemi per visualizzare i messaggi di log associati a quella categoria.
Seleziona la scheda Messaggi di log per visualizzare ulteriori dettagli su ogni problema di traduzione, inclusi la categoria del problema, il messaggio specifico del problema e un link al file in cui si è verificato il problema. Puoi fare clic sulle barre della visualizzazione Sankey per filtrare i problemi. Puoi selezionare un problema nella scheda Messaggio di log per aprire la scheda Codice che mostra il file di input e output, se applicabile.
Fai clic sulla scheda Dettagli job per visualizzare i dettagli di configurazione del job di traduzione.
Rapporto riepilogativo
Il report di riepilogo è un file CSV che contiene una tabella di tutti i messaggi di avviso ed errore riscontrati durante il lavoro di traduzione.
Per visualizzare il file di riepilogo nella console Cloud de Confiance :
Nella console Cloud de Confiance , vai alla pagina SQL Translation.
Nell'elenco dei progetti di traduzione, individua quello che ti interessa, poi fai clic sul nome del progetto o su Altre opzioni > Mostra dettagli.
Nella scheda Dettagli job, nella sezione Report di traduzione, fai clic su translation_report.csv.
Nella pagina Dettagli oggetto, fai clic sul valore nella riga URL di autenticazione per visualizzare il file nel browser.
La tabella seguente descrive le colonne del file di riepilogo:
| Colonna | Descrizione |
|---|---|
| Timestamp | Il timestamp in cui si è verificato il problema. |
| FilePath | Il percorso del file di origine a cui è associato il problema. |
| FileName | Il nome del file di origine a cui è associato il problema. |
| ScriptLine | Il numero di riga in cui si è verificato il problema. |
| ScriptColumn | Il numero di colonna in cui si è verificato il problema. |
| TranspilerComponent | Il componente interno del motore di traduzione in cui si è verificato l'avviso o l'errore. Questa colonna potrebbe essere vuota. |
| Ambiente | L'ambiente dialetto di traduzione associato all' avviso o all'errore. Questa colonna potrebbe essere vuota. |
| ObjectName | L'oggetto SQL nel file di origine associato all'avviso o all'errore. Questa colonna potrebbe essere vuota. |
| Gravità | La gravità del problema, avviso o errore. |
| Categoria | La categoria del problema di traduzione. |
| SourceType | L'origine del problema. Il valore in questa colonna può essere
SQL, che indica un problema nei file SQL di input, oppure
METADATA, che indica un problema nel pacchetto di metadati. |
| Messaggio | Il messaggio di avviso o di errore relativo al problema di traduzione. |
| ScriptContext | Lo snippet SQL nel file di origine associato al problema. |
| Azione | L'azione che ti consigliamo di intraprendere per risolvere il problema. |
Scheda Codice
La scheda del codice ti consente di esaminare ulteriori informazioni sui file di input e output per un determinato job di traduzione. Nella scheda del codice puoi esaminare i file utilizzati in un lavoro di traduzione, rivedere un confronto fianco a fianco di un file di input e della relativa traduzione per eventuali imprecisioni e visualizzare i riepiloghi e i messaggi dei log per un file specifico in un lavoro.
Per accedere alla scheda Codice:
Nella console Cloud de Confiance , vai alla pagina SQL Translation.
Nell'elenco dei progetti di traduzione, individua quello che ti interessa, poi fai clic sul nome del progetto o su Altre opzioni > Mostra dettagli.
Seleziona Scheda Codice. La scheda Codice è composta dai seguenti riquadri:
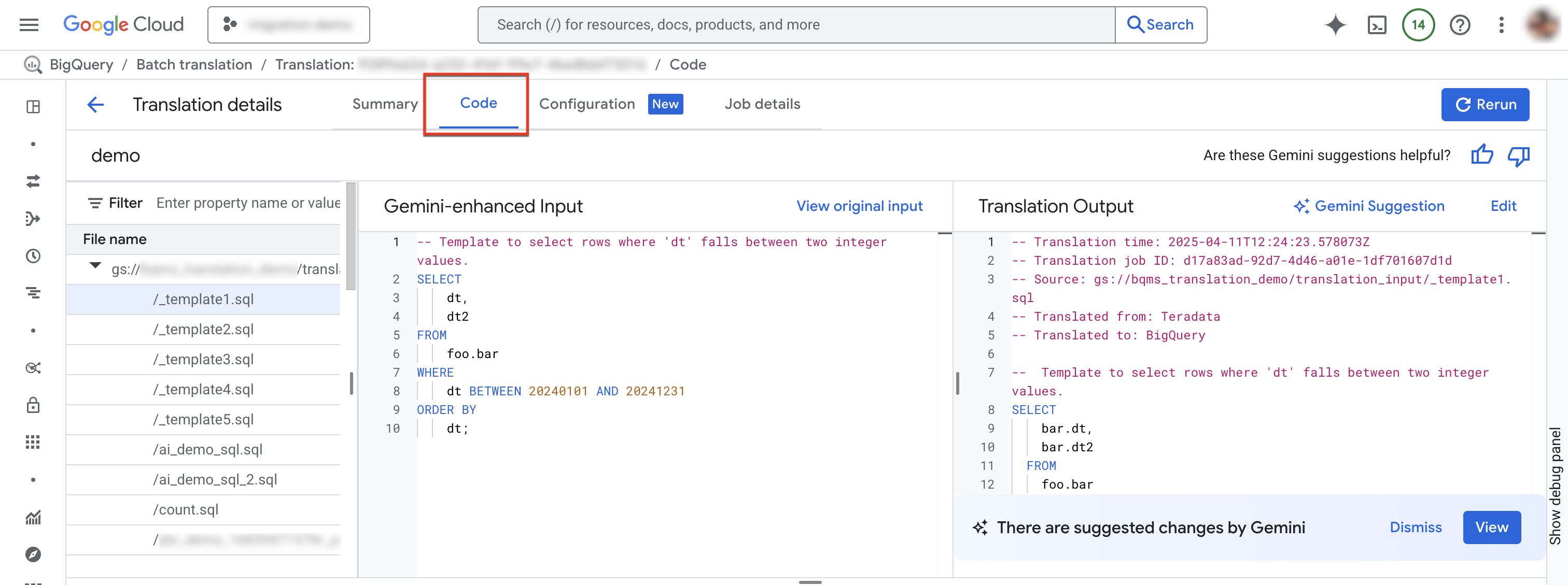
- Esplora file: contiene tutti i file SQL utilizzati per la traduzione. Fai clic su un file per visualizzare l'input e l'output della traduzione, nonché eventuali problemi di traduzione.
- Input ottimizzato con Gemini: l'SQL di input tradotto dal motore di traduzione. Se hai specificato regole di personalizzazione di Gemini per l'SQL di origine nella configurazione di Gemini, il traduttore trasforma prima l'input originale e poi traduce l'input ottimizzato con Gemini. Per visualizzare l'input originale, fai clic su Visualizza input originale.
- Output della traduzione: il risultato della traduzione. Se hai specificato regole di personalizzazione di Gemini per l'SQL di destinazione nella configurazione di Gemini, la trasformazione viene applicata al risultato tradotto come output ottimizzato con Gemini. Se è disponibile un output migliorato con Gemini, puoi fare clic sul pulsante Suggerimento di Gemini per esaminare l'output migliorato con Gemini.
(Facoltativo) Per visualizzare un file di input e il relativo file di output nel traduttore SQL interattivo di BigQuery, fai clic su Modifica. Puoi modificare i file e salvare il file di output in Cloud Storage.
Scheda Configurazione
Puoi aggiungere, rinominare, visualizzare o modificare i file YAML di configurazione nella scheda Configurazione.Esplora schema mostra la documentazione per i tipi di configurazione supportati per aiutarti a scrivere i file YAML di configurazione. Dopo aver modificato i file YAML di configurazione, puoi eseguire di nuovo il job per utilizzare la nuova configurazione.
Per accedere alla scheda di configurazione:
Nella console Cloud de Confiance , vai alla pagina SQL Translation.
Nell'elenco dei progetti di traduzione, individua quello che ti interessa, poi fai clic sul nome del progetto o su Altre opzioni > Mostra dettagli.
Nella finestra Dettagli traduzione, fai clic sulla scheda Configurazione.
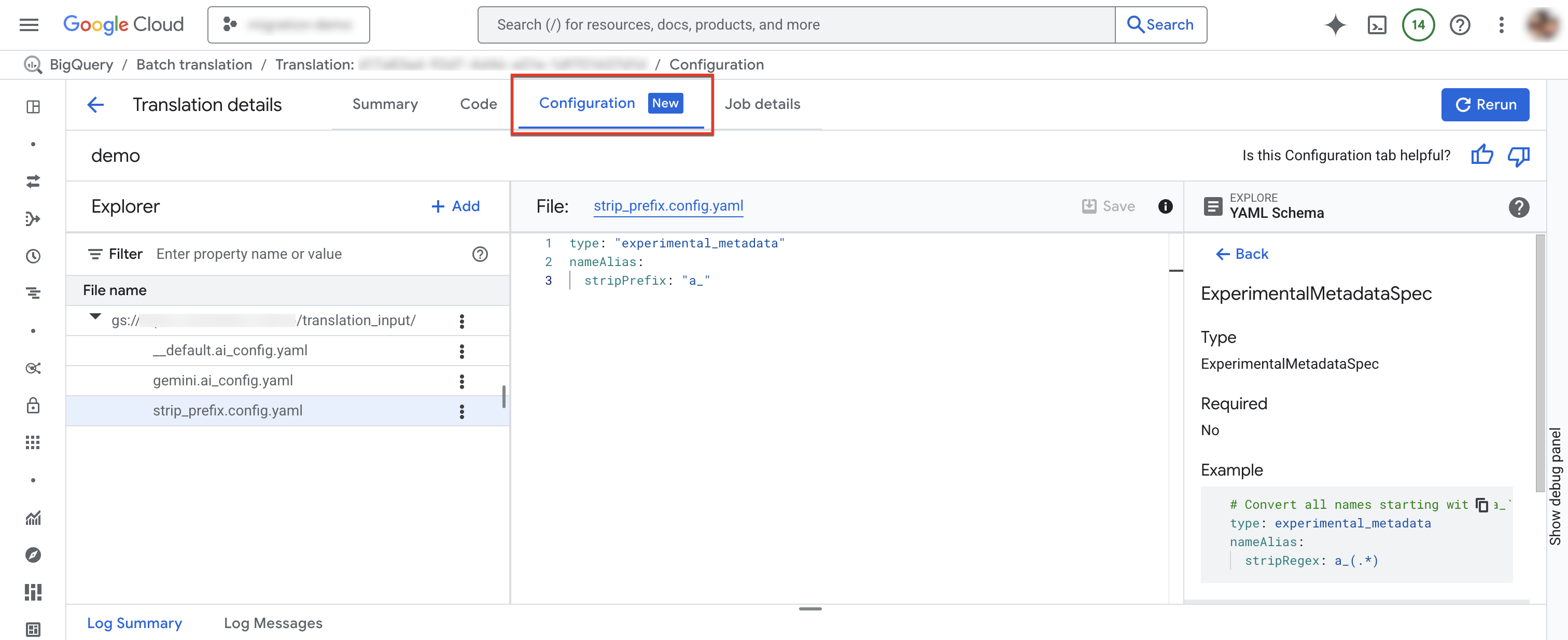
Per aggiungere un nuovo file di configurazione:
- Fai clic su more_vert Altre opzioni > Crea file YAML di configurazione.
- Viene visualizzato un riquadro in cui puoi scegliere il tipo, la posizione e il nome del nuovo file YAML di configurazione.
- Fai clic su Crea.
Per modificare un file di configurazione esistente:
- Fai clic sul file YAML di configurazione.
- Modifica il file e poi fai clic su Salva.
- Fai clic su Esegui di nuovo per eseguire un nuovo job di traduzione che utilizza i file YAML di configurazione modificati.
Puoi rinominare un file di configurazione esistente facendo clic su more_vert Altre opzioni > Rinomina.
File di mapping dei nomi di output utilizzato
Questo file JSON contiene le regole di mapping dei nomi di output utilizzate dal job di traduzione. Le regole in questo file potrebbero differire da quelle di mapping dei nomi di output specificate per il job di traduzione, a causa di conflitti nelle regole di mapping dei nomi o della mancanza di regole di mapping dei nomi per gli oggetti SQL identificati durante la traduzione. Esamina questo file per determinare se le regole di mapping dei nomi devono essere corrette. In caso affermativo, crea nuove regole di mapping dei nomi di output che risolvano eventuali problemi identificati ed esegui un nuovo job di traduzione.
File tradotti
Per ogni file di origine, viene generato un file di output corrispondente nel percorso di destinazione. Il file di output contiene la query tradotta.
Esegui il debug delle query SQL tradotte in batch con il traduttore SQL interattivo
Puoi utilizzare il traduttore SQL interattivo di BigQuery per esaminare o eseguire il debug di una query SQL utilizzando le stesse informazioni di mapping di metadati o oggetti del database di origine. Dopo aver completato un job di traduzione batch, BigQuery genera un ID configurazione di traduzione che contiene informazioni sui metadati del job, sul mapping degli oggetti o sul percorso di ricerca dello schema, a seconda dei casi. Utilizza l'ID configurazione di traduzione batch con il traduttore SQL interattivo per eseguire query SQL con la configurazione specificata.
Per avviare una traduzione SQL interattiva utilizzando un ID configurazione di traduzione batch, segui questi passaggi:
Nella console Cloud de Confiance , vai alla pagina SQL Translation.
Nell'elenco dei lavori di traduzione, individua quello che ti interessa, quindi fai clic su Altre opzioni > Apri traduzione interattiva.
Il traduttore SQL interattivo di BigQuery ora si apre con l'ID configurazione di traduzione batch corrispondente. Per visualizzare l'ID configurazione di traduzione per la traduzione interattiva, fai clic su Strumenti > Traduzione query > Impostazioni di traduzione nel traduttore SQL interattivo.
Per eseguire il debug di un file di traduzione batch nel traduttore SQL interattivo:
Nella console Cloud de Confiance , vai alla pagina SQL Translation.
Nell'elenco dei job di traduzione, individua quello che ti interessa, quindi fai clic sul nome del job o su Altre opzioni > Mostra dettagli.
Nella finestra Dettagli traduzione, fai clic sulla scheda Codice.
In Esplora file, fai clic sul nome del file per aprirlo.
Accanto al nome del file di output, fai clic su Modifica per aprire i file nel traduttore SQL interattivo (anteprima).
Vedi i file di input e output compilati nel traduttore SQL interattivo, che ora utilizza l'ID di configurazione della traduzione batch corrispondente.
Per salvare il file di output modificato in Cloud Storage, nel traduttore SQL interattivo fai clic su Salva > Salva in GCS.
Limitazioni
Il traduttore non può tradurre le funzioni definite dall'utente (UDF) da lingue diverse da SQL perché non può analizzarle per determinare i tipi di dati di input e output. Ciò causa una traduzione imprecisa delle istruzioni SQL che fanno riferimento a queste UDF. Per assicurarti che le UDF non SQL vengano correttamente referenziate durante la traduzione, utilizza SQL valido per creare UDF segnaposto con le stesse firme.
Ad esempio, supponiamo di avere una UDF scritta in C che calcola la somma di due numeri interi. Per assicurarti che le istruzioni SQL che fanno riferimento a questa UDF vengano tradotte correttamente, crea una UDF SQL segnaposto che condivida la stessa firma della UDF C, come mostrato nell'esempio seguente:
CREATE FUNCTION Test.MySum (a INT, b INT)
RETURNS INT
LANGUAGE SQL
RETURN a + b;
Salva questa UDF segnaposto in un file di testo e includi questo file tra i file di origine del job di traduzione. In questo modo, il traduttore può apprendere la definizione della UDF e identificare i tipi di dati di input e output previsti.
Quota e limiti
- Si applicano le quote dell'API BigQuery Migration.
- Ogni progetto può avere al massimo 10 attività di traduzione attive.
- Sebbene non esista un limite rigido al numero totale di file di origine e metadati, ti consigliamo di mantenere il numero di file inferiore a 1000 per un rendimento migliore.
Risolvere i problemi relativi agli errori di traduzione
Problemi di traduzione di RelationNotFound o AttributeNotFound
Dopo aver tradotto una query utilizzando il traduttore SQL batch, potresti riscontrare una traduzione non riuscita con l'errore RelationNotFound o AttributeNotFound.
Puoi trovare le traduzioni non riuscite accedendo alla pagina Dettagli traduzione e aprendo la scheda Messaggi di log.
La traduzione funziona meglio con i DDL dei metadati. Quando non è possibile trovare le definizioni degli oggetti SQL, il motore di traduzione genera problemi RelationNotFound o AttributeNotFound. Ti consigliamo di utilizzare lo strumento di estrazione dei metadati per generare pacchetti di metadati
per assicurarti che siano presenti tutte le definizioni degli oggetti. L'aggiunta di metadati è il
primo passaggio consigliato per risolvere la maggior parte degli errori di traduzione, in quanto spesso può correggere
molti altri errori causati indirettamente dalla mancanza di metadati.
Per saperne di più, consulta Generare metadati per la traduzione e la valutazione.
Risolvere i problemi di traduzione con Gemini
Per correggere i job di traduzione non riusciti con gli errori RelationNotFound o AttributeNotFound, puoi anche utilizzare Gemini per provare a risolvere questi problemi seguendo questi passaggi.
Vai alla pagina Dettagli traduzione e apri la scheda Messaggi di log.
Fai clic sulla query che contiene il messaggio
RelationNotFoundoAttributeNotFoundnella colonna Categoria.Fai clic sul messaggio di errore per passare al file e alla riga contenenti l'errore nella scheda Codice.
Nella colonna Azione, fai clic su Correzione suggerita.
Seleziona una delle seguenti opzioni: Applica o Applica ed esegui di nuovo:
- Fai clic su Applica per copiare il file dello schema generato dalla directory di output alla directory di input.
- Fai clic su Applica ed esegui di nuovo per copiare il file dello schema generato dalla directory di output alla directory di input e aprire una finestra di riesecuzione.
Prezzi
Non è previsto alcun costo per l'utilizzo del traduttore SQL batch. Tuttavia, lo spazio di archiviazione utilizzato per archiviare i file di input e di output comporta le normali tariffe. Per maggiori informazioni, consulta la pagina Prezzi dello spazio di archiviazione.
Passaggi successivi
Scopri di più sui seguenti passaggi della migrazione del data warehouse: