En este tutorial se explica cómo usar un modelo de serie temporal multivariante para predecir el valor futuro de una columna determinada en función del valor histórico de varias funciones de entrada.
En este tutorial se hacen previsiones de varias series temporales. Los valores previstos se calculan para cada punto temporal y para cada valor de una o varias columnas especificadas. Por ejemplo, si quieres predecir el tiempo y especificas una columna que contenga datos de estados, los datos previstos incluirán las previsiones de todos los puntos temporales del estado A, los valores previstos de todos los puntos temporales del estado B, etc. Si quieres predecir el tiempo y has especificado columnas que contienen datos de estado y ciudad, los datos previstos incluirán previsiones para todos los puntos temporales del estado A y la ciudad A, después los valores previstos para todos los puntos temporales del estado A y la ciudad B, y así sucesivamente.
En este tutorial se usan datos de las tablas públicas
bigquery-public-data.iowa_liquor_sales.sales
y
bigquery-public-data.covid19_weathersource_com.postal_code_day_history. La tabla bigquery-public-data.iowa_liquor_sales.sales contiene datos de ventas de bebidas alcohólicas recogidos de varias ciudades del estado de Iowa. La tabla bigquery-public-data.covid19_weathersource_com.postal_code_day_history contiene datos meteorológicos históricos, como la temperatura y la humedad, de todo el mundo.
Antes de leer este tutorial, te recomendamos que leas el artículo Previsión de una serie temporal con un modelo multivariante.
Crear conjunto de datos
Crea un conjunto de datos de BigQuery para almacenar tu modelo de aprendizaje automático.
Consola
En la Cloud de Confiance consola, ve a la página BigQuery.
En el panel Explorador, haz clic en el nombre de tu proyecto.
Haga clic en Ver acciones > Crear conjunto de datos.
En la página Crear conjunto de datos, haz lo siguiente:
En ID del conjunto de datos, introduce
bqml_tutorial.En Tipo de ubicación, selecciona Multirregión y, a continuación, EE. UU. (varias regiones de Estados Unidos).
Deje el resto de los ajustes predeterminados como están y haga clic en Crear conjunto de datos.
bq
Para crear un conjunto de datos, usa el comando
bq mk
con la marca --location. Para ver una lista completa de los parámetros posibles, consulta la referencia del comando bq mk --dataset.
Crea un conjunto de datos llamado
bqml_tutorialcon la ubicación de los datos definida comoUSy la descripciónBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
En lugar de usar la marca
--dataset, el comando usa el acceso directo-d. Si omite-dy--dataset, el comando creará un conjunto de datos de forma predeterminada.Confirma que se ha creado el conjunto de datos:
bq ls
API
Llama al método datasets.insert con un recurso de conjunto de datos definido.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames que se indican en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de los DataFrames de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta Configurar ADC en un entorno de desarrollo local.
Crear una tabla de datos de entrada
Crea una tabla de datos que puedas usar para entrenar y evaluar el modelo. Esta tabla combina columnas de las tablas bigquery-public-data.iowa_liquor_sales.sales y bigquery-public-data.covid19_weathersource_com.postal_code_day_history para analizar cómo afecta el tiempo al tipo y al número de artículos pedidos por las licorerías. También puede crear las siguientes columnas adicionales que puede usar como variables de entrada del modelo:
date: la fecha del pedidostore_number: número único de la tienda que ha realizado el pedidoitem_number: número único del artículo que se ha pedidobottles_sold: número de botellas pedidas del artículo asociadotemperature: la temperatura media en la ubicación de la tienda en la fecha del pedido.humidity: la humedad media en la ubicación de la tienda en la fecha del pedido.
Sigue estos pasos para crear la tabla de datos de entrada:
En la Cloud de Confiance consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
CREATE OR REPLACE TABLE `bqml_tutorial.iowa_liquor_sales_with_weather` AS WITH sales AS ( SELECT DATE, store_number, item_number, bottles_sold, SAFE_CAST(SAFE_CAST(zip_code AS FLOAT64) AS INT64) AS zip_code FROM `bigquery-public-data.iowa_liquor_sales.sales` AS sales WHERE SAFE_CAST(zip_code AS FLOAT64) IS NOT NULL ), aggregated_sales AS ( SELECT DATE, store_number, item_number, ANY_VALUE(zip_code) AS zip_code, SUM(bottles_sold) AS bottles_sold, FROM sales GROUP BY DATE, store_number, item_number ), weather AS ( SELECT DATE, SAFE_CAST(postal_code AS INT64) AS zip_code, avg_temperature_air_2m_f AS temperature, avg_humidity_specific_2m_gpkg AS humidity, FROM `bigquery-public-data.covid19_weathersource_com.postal_code_day_history` WHERE country = 'US' AND SAFE_CAST(postal_code AS INT64) IS NOT NULL ) SELECT aggregated_sales.date, aggregated_sales.store_number, aggregated_sales.item_number, aggregated_sales.bottles_sold, weather.temperature AS temperature, weather.humidity AS humidity FROM aggregated_sales LEFT JOIN weather ON aggregated_sales.zip_code=weather.zip_code AND aggregated_sales.DATE=weather.DATE;
Crear el modelo de serie temporal
Crea un modelo de serie temporal para predecir las botellas vendidas de cada combinación de ID de tienda e ID de artículo, para cada fecha de la tabla bqml_tutorial.iowa_liquor_sales_with_weather anterior al 1 de septiembre del 2022. Usa la temperatura y la humedad medias de la tienda en cada fecha como características que evaluar durante la previsión. En la tabla bqml_tutorial.iowa_liquor_sales_with_weather hay aproximadamente 1 millón de combinaciones distintas de número de artículo y número de tienda, lo que significa que hay 1 millón de series temporales diferentes que predecir.
Sigue estos pasos para crear el modelo:
En la Cloud de Confiance consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
CREATE OR REPLACE MODEL `bqml_tutorial.multi_time_series_arimax_model` OPTIONS( model_type = 'ARIMA_PLUS_XREG', time_series_id_col = ['store_number', 'item_number'], time_series_data_col = 'bottles_sold', time_series_timestamp_col = 'date' ) AS SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE < DATE('2022-09-01');
La consulta tarda unos 38 minutos en completarse. Después, podrás acceder al modelo
multi_time_series_arimax_model. Como la consulta usa una instrucciónCREATE MODELpara crear un modelo, no se muestran resultados de la consulta.
Usar el modelo para predecir datos
Prevé valores futuros de series temporales con la función ML.FORECAST.
En la siguiente consulta de GoogleSQL, la cláusula STRUCT(5 AS horizon, 0.8 AS confidence_level) indica que la consulta pronostica 5 puntos temporales futuros y genera un intervalo de predicción con un nivel de confianza del 80 %.
La firma de datos de los datos de entrada de la función ML.FORECAST es la misma que la de los datos de entrenamiento que has usado para crear el modelo. La columna bottles_sold no se incluye en la entrada porque son los datos que el modelo intenta predecir.
Sigue estos pasos para predecir datos con el modelo:
En la Cloud de Confiance consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT * FROM ML.FORECAST ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (5 AS horizon, 0.8 AS confidence_level), ( SELECT * EXCEPT (bottles_sold) FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE>=DATE('2022-09-01') ) );
Los resultados deberían ser similares a los siguientes:
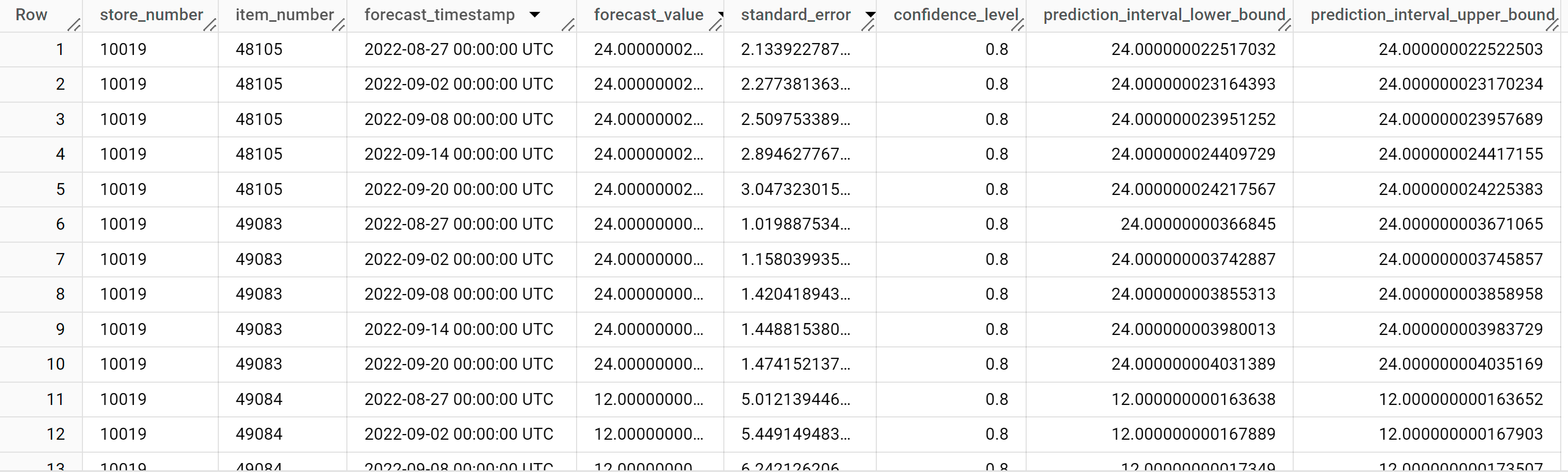
Las filas de salida se ordenan por el valor de
store_number, después por el valor deitem_IDy, por último, por el valor de la columnaforecast_timestampen orden cronológico. En la previsión de series temporales, el intervalo de predicción, representado por los valores de las columnasprediction_interval_lower_boundyprediction_interval_upper_bound, es tan importante como el valor de la columnaforecast_value. El valorforecast_valuees el punto medio del intervalo de predicción. El intervalo de predicción depende de los valores de las columnasstandard_erroryconfidence_level.Para obtener más información sobre las columnas de salida, consulta
ML.FORECAST.
Explicar los resultados de las previsiones
Puede obtener métricas de interpretabilidad además de datos de previsión mediante la función ML.EXPLAIN_FORECAST. La función ML.EXPLAIN_FORECAST predice los valores de series temporales futuras y también devuelve todos los componentes independientes de la serie temporal.
Al igual que la función ML.FORECAST, la cláusula STRUCT(5 AS horizon, 0.8 AS confidence_level) utilizada en la función ML.EXPLAIN_FORECAST indica que la consulta pronostica 30 puntos temporales futuros y genera un intervalo de predicción con una confianza del 80 %.
La función ML.EXPLAIN_FORECAST proporciona datos históricos y previsiones. Para ver solo los datos de previsión, añade la opción time_series_type a la consulta y especifica forecast como valor de la opción.
Sigue estos pasos para explicar los resultados del modelo:
En la Cloud de Confiance consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT * FROM ML.EXPLAIN_FORECAST ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (5 AS horizon, 0.8 AS confidence_level), ( SELECT * EXCEPT (bottles_sold) FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
Los resultados deberían ser similares a los siguientes:
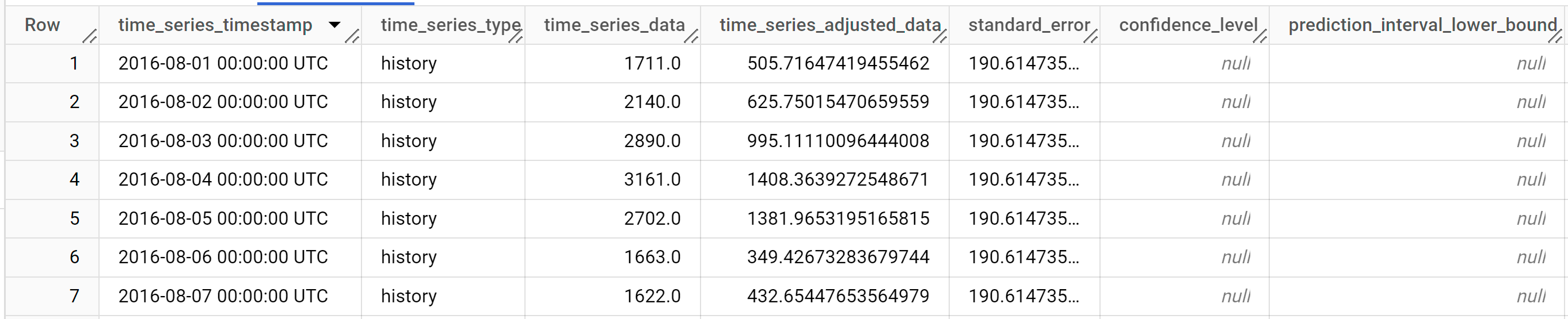
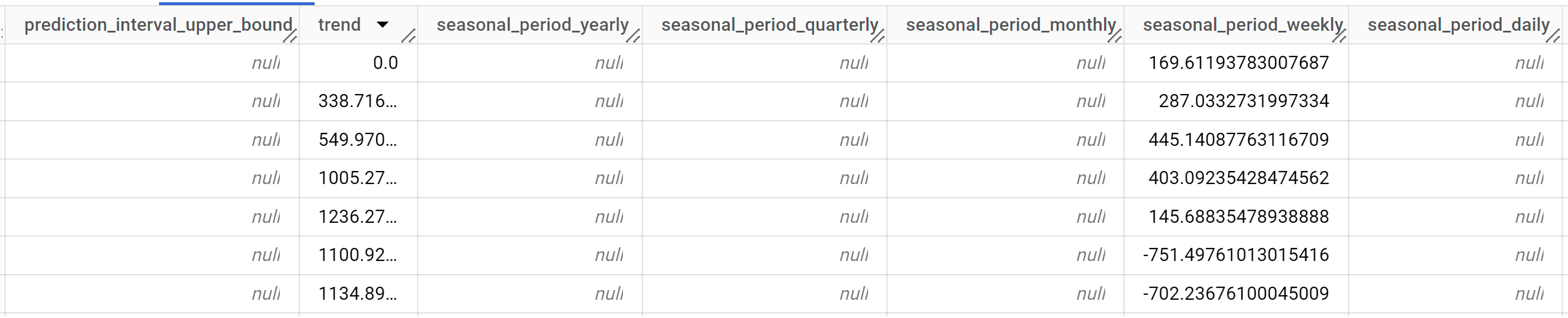
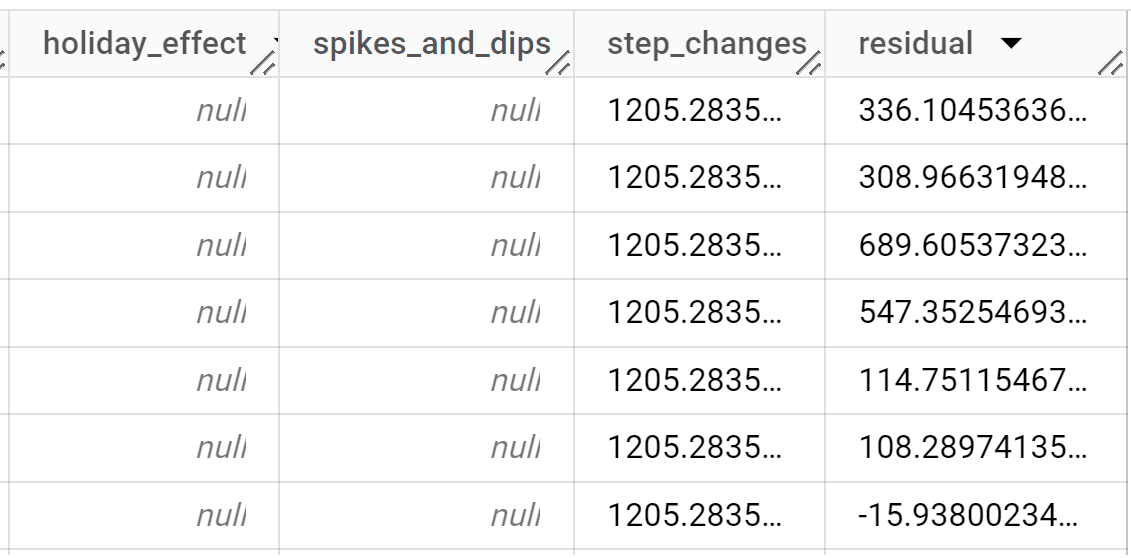
Las filas de salida se ordenan cronológicamente por el valor de la columna
time_series_timestamp.Para obtener más información sobre las columnas de salida, consulta
ML.EXPLAIN_FORECAST.
Evaluar la precisión de las previsiones
Evalúa la precisión de las previsiones del modelo ejecutándolo con datos con los que no se ha entrenado. Para ello, puedes usar la función ML.EVALUATE. La función ML.EVALUATE evalúa cada serie temporal de forma independiente.
En la siguiente consulta de GoogleSQL, la segunda instrucción SELECT proporciona los datos con las funciones futuras, que se usan para predecir los valores futuros y compararlos con los datos reales.
Sigue estos pasos para evaluar la precisión del modelo:
En la Cloud de Confiance consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT * FROM ML.EVALUATE ( model `bqml_tutorial.multi_time_series_arimax_model`, ( SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
Los resultados deberían ser similares a los siguientes:
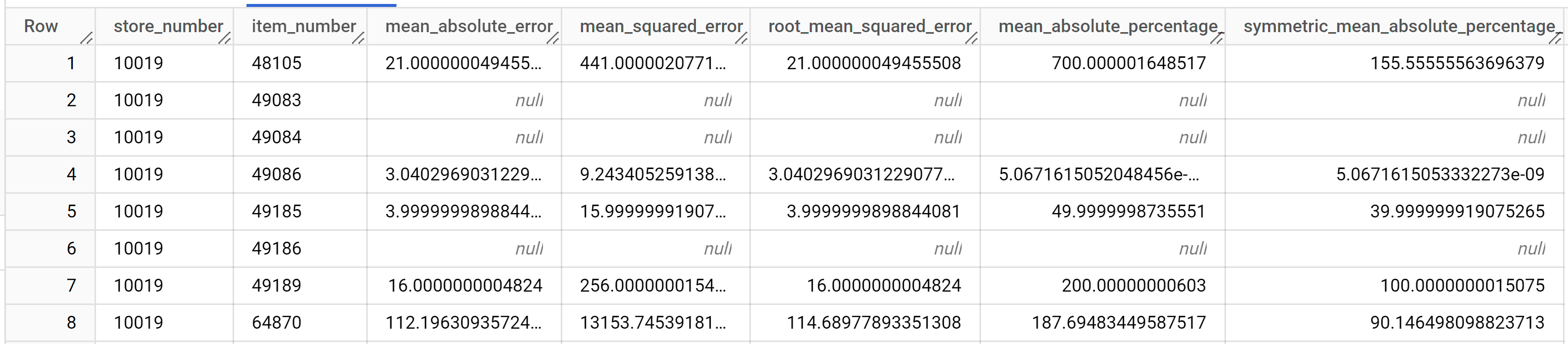
Para obtener más información sobre las columnas de salida, consulta
ML.EVALUATE.
Usar el modelo para detectar anomalías
Detecta anomalías en los datos de entrenamiento mediante la función ML.DETECT_ANOMALIES.
En la siguiente consulta, la cláusula STRUCT(0.95 AS anomaly_prob_threshold) hace que la función ML.DETECT_ANOMALIES identifique los puntos de datos anómalos con un nivel de confianza del 95 %.
Sigue estos pasos para detectar anomalías en los datos de entrenamiento:
En la Cloud de Confiance consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
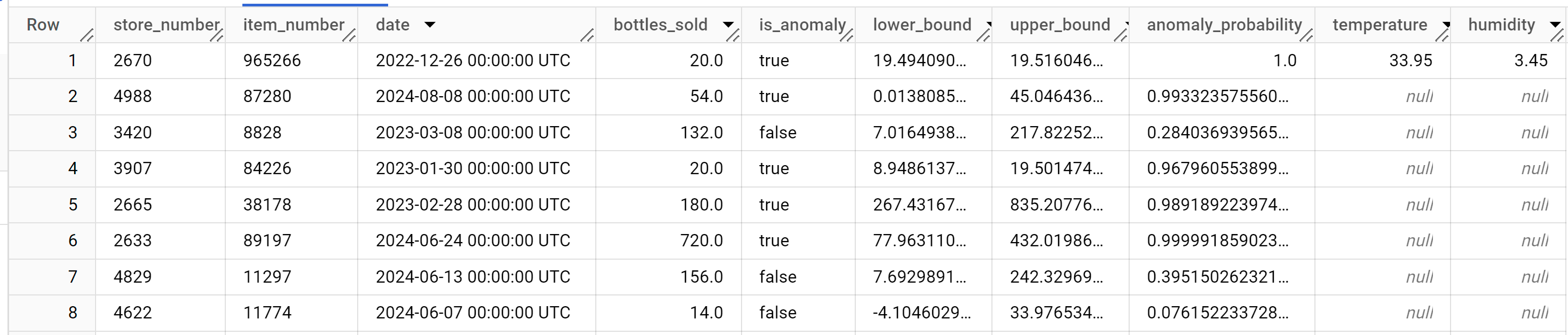
SELECT * FROM ML.DETECT_ANOMALIES ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (0.95 AS anomaly_prob_threshold) );
Los resultados deberían ser similares a los siguientes:
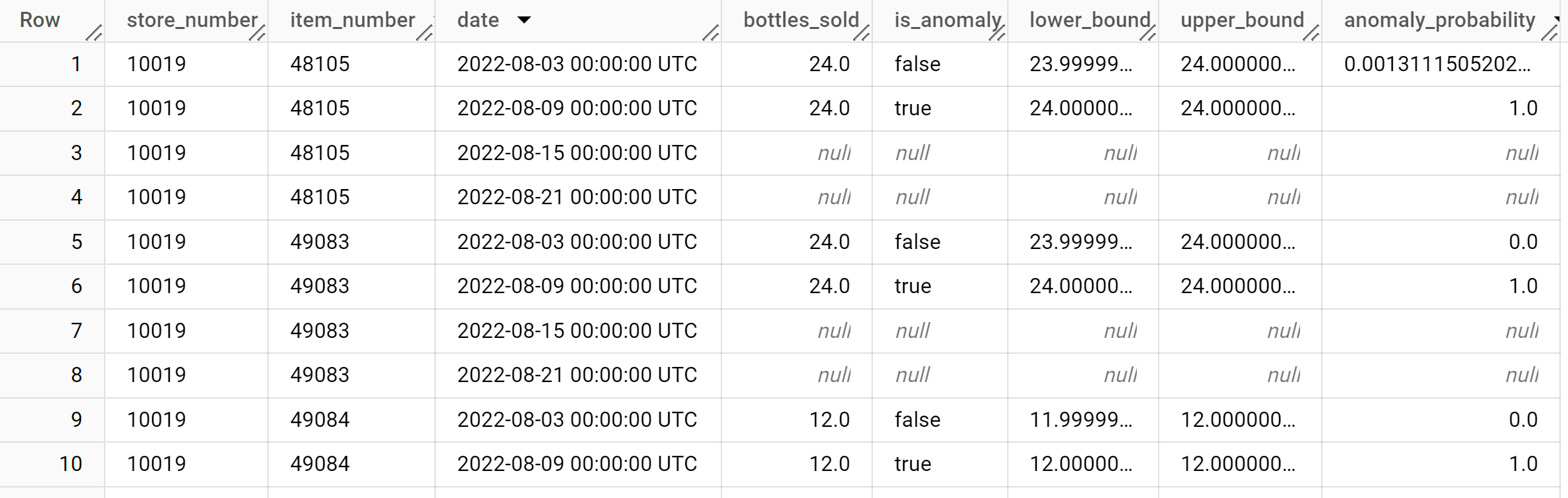
La columna
anomaly_probabilityde los resultados identifica la probabilidad de que un valor de la columnabottles_soldsea anómalo.Para obtener más información sobre las columnas de salida, consulta
ML.DETECT_ANOMALIES.
Detectar anomalías en los datos nuevos
Detecta anomalías en los datos nuevos proporcionando datos de entrada a la función ML.DETECT_ANOMALIES. Los datos nuevos deben tener la misma firma de datos que los datos de entrenamiento.
Sigue estos pasos para detectar anomalías en los datos nuevos:
En la Cloud de Confiance consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT * FROM ML.DETECT_ANOMALIES ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (0.95 AS anomaly_prob_threshold), ( SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
Los resultados deberían ser similares a los siguientes: