
Use campos aninhados e repetidos
O BigQuery pode ser usado com muitos métodos de modelagem de dados diferentes e, geralmente, oferece um elevado desempenho em muitas metodologias de modelos de dados. Para otimizar ainda mais um modelo de dados para o desempenho, um método que pode considerar é a desnormalização de dados, o que significa adicionar colunas de dados a uma única tabela para reduzir ou remover as junções de tabelas.
Prática recomendada: use campos aninhados e repetidos para desnormalizar o armazenamento de dados e aumentar o desempenho das consultas.
A desnormalização é uma estratégia comum para melhorar o desempenho de leitura para conjuntos de dados relacionais anteriormente normalizados. A forma recomendada de desnormalizar dados no BigQuery é usar campos aninhados e repetidos. É recomendável usar esta estratégia quando as relações são hierárquicas e consultadas frequentemente em conjunto, como nas relações superior-secundário.
A poupança de armazenamento através da utilização de dados normalizados tem um efeito menor nos sistemas modernos. Os aumentos nos custos de armazenamento compensam os ganhos de desempenho da utilização de dados desnormalizados. As junções requerem coordenação de dados (largura de banda de comunicação). A desnormalização localiza os dados em ranhuras individuais, para que a execução possa ser feita em paralelo.
Para manter as relações enquanto desnormaliza os dados, pode usar campos aninhados e repetidos em vez de simplificar completamente os dados. Quando os dados relacionais são completamente achatados, a comunicação de rede (mistura) pode afetar negativamente o desempenho das consultas.
Por exemplo, a desnormalização de um esquema de encomendas sem usar campos aninhados e repetidos pode exigir que agrupe os dados por um campo como order_id (quando existe uma relação um-para-muitos). Devido à aleatorização envolvida, a agrupagem dos dados é menos eficaz do que a desnormalização dos dados através da utilização de campos aninhados e repetidos.
Em algumas circunstâncias, a desnormalização dos dados e a utilização de campos aninhados e repetidos não resultam num aumento do desempenho. Por exemplo, os esquemas em estrela são esquemas normalmente otimizados para estatísticas e, como resultado, o desempenho pode não ser significativamente diferente se tentar desnormalizar ainda mais.
Usar campos aninhados e repetidos
O BigQuery não requer uma desnormalização completamente simples. Pode usar campos aninhados e repetidos para manter relações.
Dados de aninhamento (
STRUCT)- A aninhagem de dados permite-lhe representar entidades estrangeiras inline.
- A consulta de dados aninhados usa a sintaxe "ponto" para fazer referência a campos de folhas, que é semelhante à sintaxe que usa uma junção.
- Os dados aninhados são representados como um tipo
STRUCTno GoogleSQL.
Dados repetidos (
ARRAY)- A criação de um campo do tipo
RECORDcom o modo definido comoREPEATEDpermite-lhe preservar uma relação um-para-muitos inline (desde que a relação não seja de alta cardinalidade). - Com dados repetidos, não é necessário misturar.
- Os dados repetidos são representados como um
ARRAY. Pode usar umaARRAYfunção no GoogleSQL quando consulta os dados repetidos.
- A criação de um campo do tipo
Dados aninhados e repetidos (
ARRAYdeSTRUCT)- A aninhagem e a repetição complementam-se.
- Por exemplo, numa tabela de registos de transações, pode incluir uma matriz de
STRUCTs de elementos publicitários.
Para mais informações, consulte o artigo Especifique colunas aninhadas e repetidas em esquemas de tabelas.
Para mais informações sobre a desnormalização de dados, consulte o artigo Desnormalização.
Exemplo
Considere uma Orders tabela com uma linha para cada elemento publicitário vendido:
| Order_Id | Item_Name |
|---|---|
| 001 | A1 |
| 001 | B1 |
| 002 | A1 |
| 002 | C1 |
Se quiser analisar dados desta tabela, tem de usar uma cláusula GROUP BY, semelhante à seguinte:
SELECT COUNT (Item_Name) FROM Orders GROUP BY Order_Id;
A cláusula GROUP BY envolve uma sobrecarga de cálculo adicional, mas pode ser evitada aninhando dados repetidos. Pode evitar a utilização de uma cláusula GROUP BY criando uma tabela com uma encomenda por linha, em que os elementos publicitários da encomenda estão num campo aninhado:
| Order_Id | Item_Name |
|---|---|
| 001 |
A1 B1 |
| 002 |
A1 C1 |
No BigQuery, normalmente, especifica um esquema aninhado como uma matriz de objetos ARRAY
STRUCT. Usa o operador UNNEST para simplificar os dados aninhados, como mostrado na seguinte consulta:
SELECT * FROM UNNEST( [ STRUCT('001' AS Order_Id, ['A1', 'B1'] AS Item_Name), STRUCT('002' AS Order_Id, ['A1', 'C1'] AS Item_Name) ] );
Esta consulta gera resultados semelhantes aos seguintes:
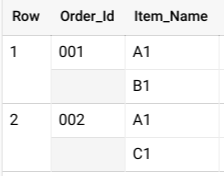
Se estes dados não estivessem aninhados, poderia ter várias linhas para cada encomenda, uma para cada artigo vendido nessa encomenda, o que resultaria numa tabela grande e numa operação GROUP BY dispendiosa.
Exercício físico
Pode ver a diferença de desempenho nas consultas que usam campos aninhados em comparação com as que não usam seguindo os passos nesta secção.
Crie uma tabela com base no
bigquery-public-data.stackoverflow.commentsconjunto de dados público:CREATE OR REPLACE TABLE `PROJECT.DATASET.stackoverflow` AS ( SELECT user_id, post_id, creation_date FROM `bigquery-public-data.stackoverflow.comments` );
Usando a tabela
stackoverflow, execute a seguinte consulta para ver o comentário mais antigo de cada utilizador:SELECT user_id, ARRAY_AGG(STRUCT(post_id, creation_date AS earliest_comment) ORDER BY creation_date ASC LIMIT 1)[OFFSET(0)].* FROM `PROJECT.DATASET.stackoverflow` GROUP BY user_id ORDER BY user_id ASC;
Esta consulta demora cerca de 25 segundos a ser executada e processa 1,88 GB de dados.
Crie uma segunda tabela com dados idênticos que cria um campo
commentsusando um tipoSTRUCTpara armazenar os dadospost_idecreation_date, em vez de dois campos individuais:CREATE OR REPLACE TABLE `PROJECT.DATASET.stackoverflow_nested` AS ( SELECT user_id, ARRAY_AGG(STRUCT(post_id, creation_date) ORDER BY creation_date ASC) AS comments FROM `bigquery-public-data.stackoverflow.comments` GROUP BY user_id );
Usando a tabela
stackoverflow_nested, execute a seguinte consulta para ver o comentário mais antigo de cada utilizador:SELECT user_id, (SELECT AS STRUCT post_id, creation_date as earliest_comment FROM UNNEST(comments) ORDER BY creation_date ASC LIMIT 1).* FROM `PROJECT.DATASET.stackoverflow_nested` ORDER BY user_id ASC;
Esta consulta demora cerca de 10 segundos a ser executada e processa 1,28 GB de dados.
Elimine as tabelas
stackoverflowestackoverflow_nestedquando terminar de as usar.