
Introdução às tabelas agrupadas
As tabelas agrupadas no BigQuery são tabelas que têm uma ordem de ordenação de colunas definida pelo utilizador através de colunas agrupadas. As tabelas agrupadas podem melhorar o desempenho das consultas e reduzir os custos das consultas.
No BigQuery, uma coluna agrupada é uma propriedade de tabela definida pelo utilizador que ordena os blocos de armazenamento com base nos valores das colunas agrupadas. Os blocos de armazenamento são dimensionados de forma adaptável com base no tamanho da tabela. A colocação conjunta ocorre ao nível dos blocos de armazenamento e não ao nível das linhas individuais. Para mais informações sobre a colocação conjunta neste contexto, consulte a secção Agrupamento.
Uma tabela agrupada mantém as propriedades de ordenação no contexto de cada operação que a modifica. As consultas que filtram ou agregam pelas colunas agrupadas apenas analisam os blocos relevantes com base nas colunas agrupadas, em vez de toda a tabela ou partição da tabela. Como resultado, o BigQuery pode não conseguir estimar com precisão os bytes a serem processados pela consulta ou os custos da consulta, mas tenta reduzir o total de bytes na execução.
Quando agrupa uma tabela com várias colunas, a ordem das colunas determina
que colunas têm precedência quando o BigQuery ordena e agrupa os
dados em blocos de armazenamento, como se vê no exemplo seguinte. A tabela 1 mostra a disposição dos blocos de armazenamento lógicos de uma tabela não agrupada. Em comparação, a tabela 2 só está agrupada pela coluna Country, enquanto a tabela 3 está agrupada por várias colunas, Country e Status.
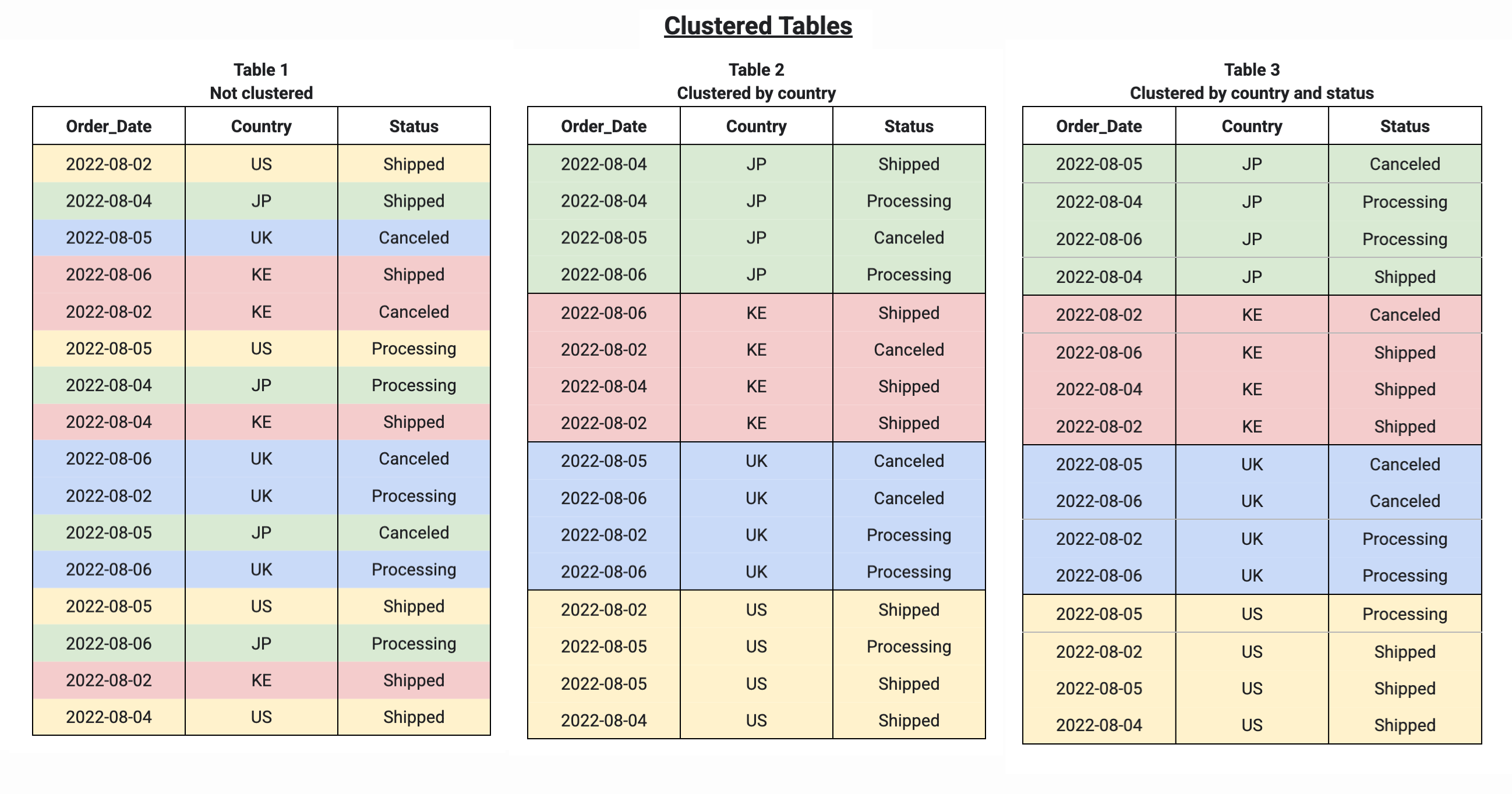
Quando consulta uma tabela agrupada, não recebe uma estimativa precisa do custo da consulta antes da execução da consulta, porque o número de blocos de armazenamento a serem analisados não é conhecido antes da execução da consulta. O custo final é determinado após a conclusão da execução da consulta e baseia-se nos blocos de armazenamento específicos que foram analisados.
Quando usar a agrupagem
O agrupamento aborda a forma como uma tabela é armazenada, pelo que é geralmente uma boa primeira opção para melhorar o desempenho das consultas. Por isso, deve sempre considerar a agrupagem, tendo em conta as seguintes vantagens que oferece:
- As tabelas não particionadas com mais de 64 MB beneficiam provavelmente do agrupamento. Da mesma forma, as partições de tabelas com mais de 64 MB também têm maior probabilidade de beneficiar da agrupagem. É possível agrupar tabelas ou partições mais pequenas, mas a melhoria do desempenho é geralmente insignificante.
- Se as suas consultas filtrarem frequentemente colunas específicas, o agrupamento acelera as consultas porque a consulta apenas analisa os blocos que correspondem ao filtro.
- Se as suas consultas filtrarem colunas com muitos valores distintos (cardinalidade elevada), a clustering acelera estas consultas fornecendo ao BigQuery metadados detalhados sobre onde obter os dados de entrada.
- O clustering permite que os blocos de armazenamento subjacentes da tabela sejam dimensionados de forma adaptativa com base no tamanho da tabela.
Pode considerar particionar a tabela além da agrupagem. Nesta abordagem, primeiro segmenta os dados em partições e, em seguida, agrupa os dados em cada partição pelas colunas de agrupamento. Considere esta abordagem nas seguintes circunstâncias:
- Precisa de uma estimativa de custo de consulta rigorosa antes de executar uma consulta. O custo das consultas em tabelas agrupadas só pode ser determinado após a execução da consulta. A partição fornece estimativas detalhadas dos custos das consultas antes de executar uma consulta.
- A partição da tabela resulta num tamanho médio de partição de, pelo menos, 10 GB por partição. A criação de muitas partições pequenas aumenta os metadados da tabela e pode afetar os tempos de acesso aos metadados quando consulta a tabela.
- Precisa de atualizar continuamente a sua tabela, mas quer tirar partido dos preços de armazenamento a longo prazo. A partição permite que cada partição seja considerada separadamente para elegibilidade para preços a longo prazo. Se a tabela não estiver particionada, não pode editar a tabela inteira durante 90 dias consecutivos para ser considerada para os preços a longo prazo.
Para mais informações, consulte o artigo Combine tabelas agrupadas e particionadas.
Tipos de colunas de clusters e ordenação
Esta secção descreve os tipos de colunas e como funciona a ordem das colunas no agrupamento de tabelas.
Tipos de colunas de clusters
As colunas de cluster têm de ser colunas de nível superior não repetidas de um dos seguintes tipos:
BIGNUMERICBOOLDATEDATETIMEGEOGRAPHYINT64NUMERICRANGESTRINGTIMESTAMP
Para mais informações sobre os tipos de dados, consulte o artigo Tipos de dados do GoogleSQL.
Ordem das colunas de cluster
A ordem das colunas agrupadas afeta o desempenho das consultas. No exemplo seguinte, a tabela Orders está agrupada através de uma ordem de classificação de colunas de Order_Date, Country e Status. A primeira coluna agrupada neste exemplo é Order_Date, pelo que uma consulta que filtre por Order_Date e Country é otimizada para o agrupamento, enquanto uma consulta que filtre apenas por Country e Status não é otimizada.
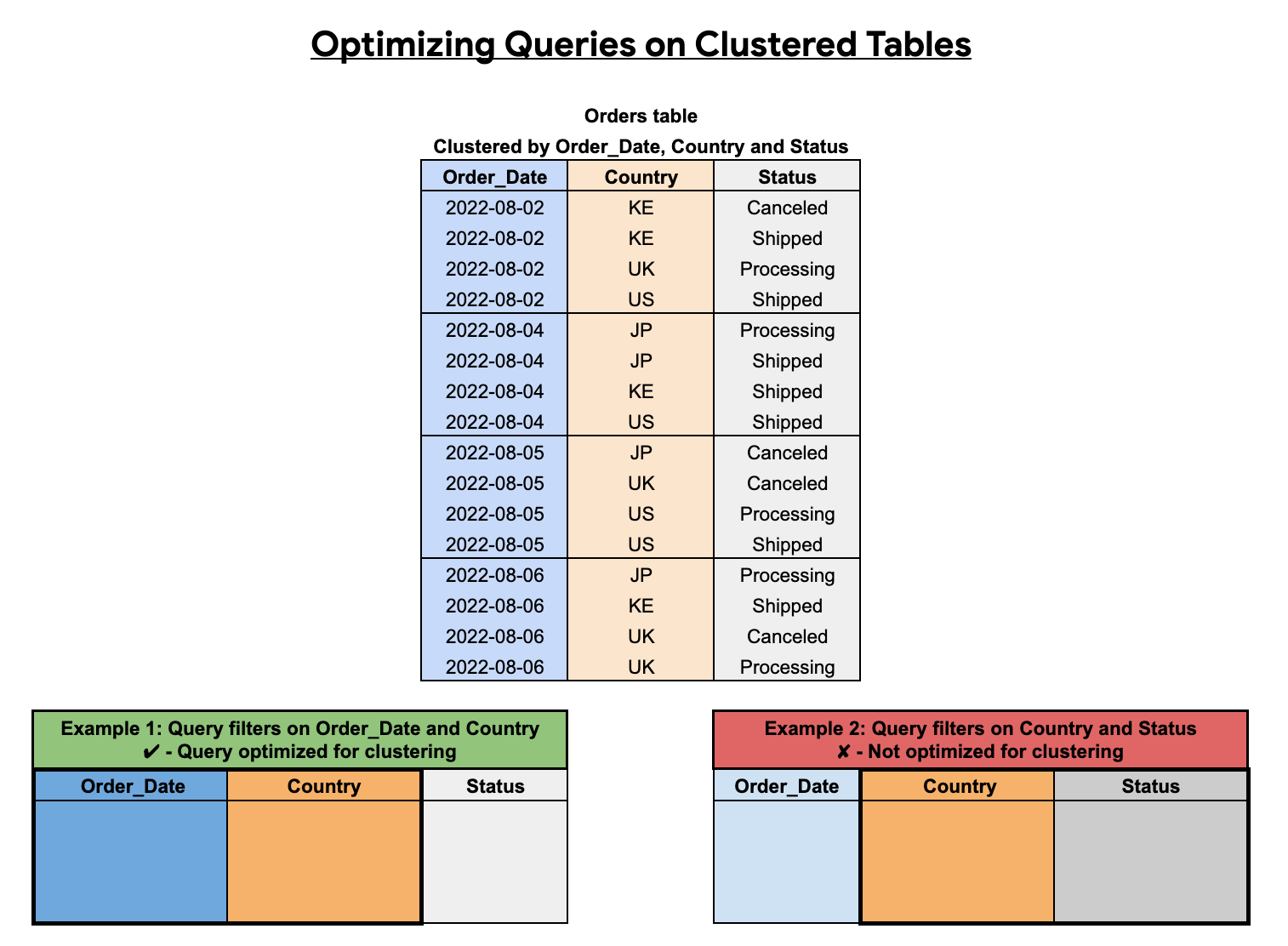
Poda de blocos
As tabelas agrupadas podem ajudar a reduzir os custos das consultas através do corte de dados para que não sejam processados pela consulta. Este processo é denominado remoção de blocos. O BigQuery ordena os dados numa tabela agrupada com base nos valores das colunas de agrupamento e organiza-os em blocos.
Quando executa uma consulta numa tabela agrupada e a consulta inclui um filtro nas colunas agrupadas, o BigQuery usa a expressão de filtro e os metadados de blocos para remover os blocos analisados pela consulta. Isto permite que o BigQuery analise apenas os blocos relevantes.
Quando um bloco é removido, não é analisado. Apenas os blocos analisados são usados para calcular os bytes de dados processados pela consulta. O número de bytes processados por uma consulta numa tabela agrupada é igual à soma dos bytes lidos em cada coluna referenciada pela consulta nos blocos analisados.
Se uma tabela agrupada for referenciada várias vezes numa consulta que usa vários filtros, o BigQuery cobra pela análise das colunas nos blocos adequados em cada um dos respetivos filtros. Para ver um exemplo de como funciona a remoção de blocos, consulte o exemplo.
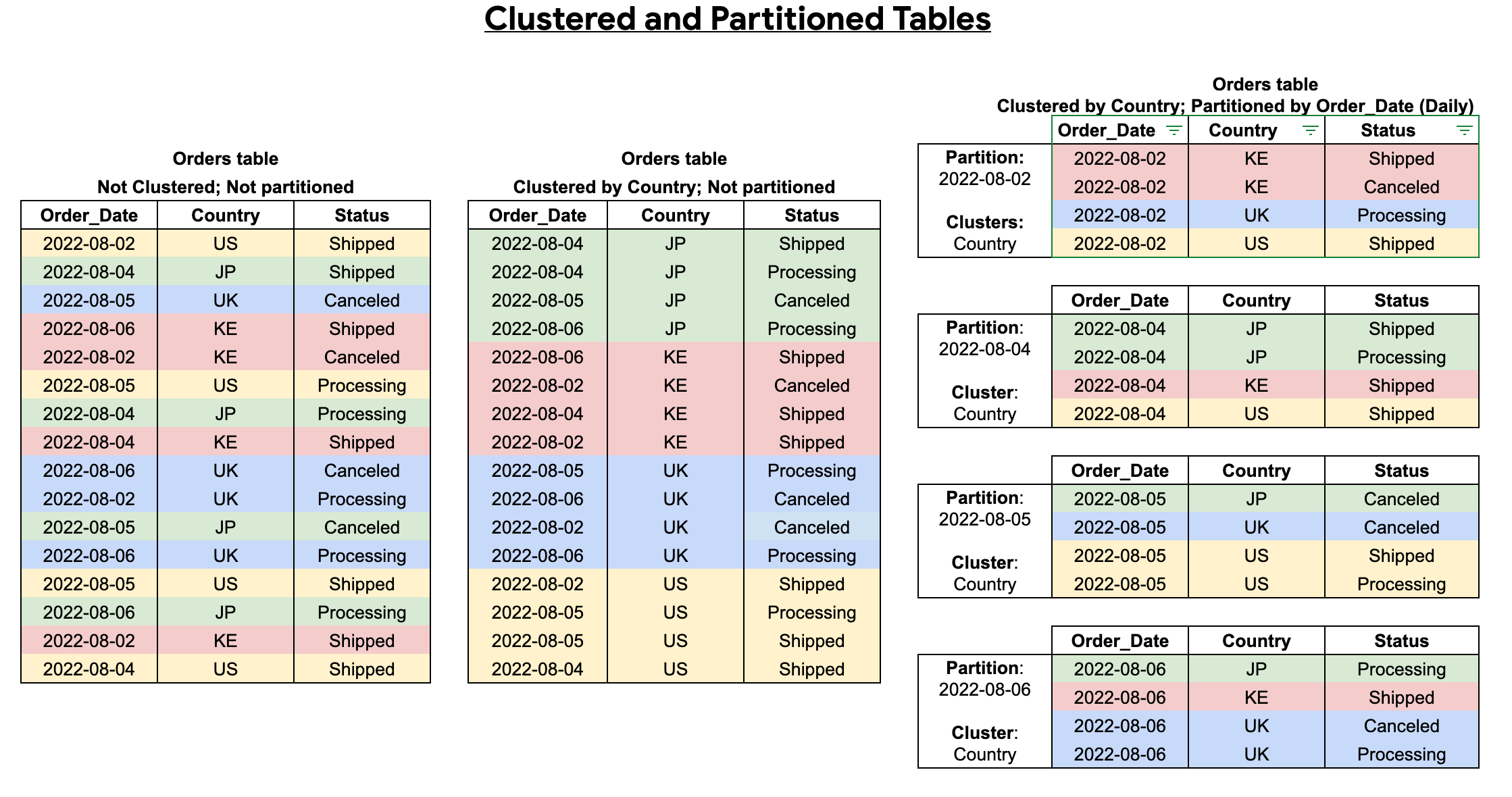
Combine tabelas particionadas e agrupadas
Pode combinar a agrupamento em cluster de tabelas com a partição de tabelas para conseguir uma ordenação detalhada para uma maior otimização das consultas.
Numa tabela particionada, os dados são armazenados em blocos físicos, cada um dos quais contém uma partição de dados. Cada tabela particionada mantém vários metadados sobre as propriedades de ordenação em todas as operações que a modificam. Os metadados permitem ao BigQuery estimar com maior precisão o custo de uma consulta antes de a consulta ser executada. No entanto, a partição requer que o BigQuery mantenha mais metadados do que com uma tabela não particionada. À medida que o número de partições aumenta, a quantidade de metadados a manter aumenta.
Quando cria uma tabela agrupada e particionada, pode conseguir uma ordenação mais detalhada, como mostra o diagrama seguinte:
Exemplo
Tem uma tabela agrupada com o nome ClusteredSalesData. A tabela está particionada pela coluna timestamp e agrupada pela coluna customer_id. Os dados estão organizados no seguinte conjunto de blocos:
| Identificador de partição | ID do bloco | Valor mínimo para customer_id no bloco | Valor máximo para customer_id no bloco |
|---|---|---|---|
| 20160501 | B1 | 10000 | 19999 |
| 20160501 | B2 | 20000 | 24999 |
| 20160502 | B3 | 15000 | 17999 |
| 20160501 | B4 | 22000 | 27999 |
Executa a seguinte consulta na tabela. A consulta contém um filtro na coluna customer_id.
SELECT SUM(totalSale) FROM `mydataset.ClusteredSalesData` WHERE customer_id BETWEEN 20000 AND 23000 AND DATE(timestamp) = "2016-05-01"
A consulta anterior envolve os seguintes passos:
- Analisa as colunas
timestamp,customer_idetotalSalenos blocos B2 e B4. - Remove o bloco B3 devido ao predicado de filtro na coluna de partição
timestamp.DATE(timestamp) = "2016-05-01" - Remove o bloco B1 devido ao predicado de filtro na coluna de agrupamento
customer_id.customer_id BETWEEN 20000 AND 23000
Reagrupamento automático
À medida que são adicionados dados a uma tabela agrupada, os novos dados são organizados em blocos, o que pode criar novos blocos de armazenamento ou atualizar os blocos existentes. O bloqueio da otimização é necessário para um desempenho ideal das consultas e do armazenamento, porque os novos dados podem não ser agrupados com os dados existentes que têm os mesmos valores de cluster.
Para manter as caraterísticas de desempenho de uma tabela agrupada, o BigQuery faz o reagrupamento automático em segundo plano. Para tabelas particionadas, a agrupamento é mantido para os dados no âmbito de cada partição.
Limitações
- Apenas o GoogleSQL é suportado para consultar tabelas agrupadas e para escrever resultados de consultas em tabelas agrupadas.
- Só pode especificar até quatro colunas de agrupamento. Se precisar de colunas adicionais, pondere combinar a agrupamento com a partição.
- Quando usa colunas do tipo
STRINGpara a agrupamento, o BigQuery usa apenas os primeiros 1024 carateres para agrupar os dados. Os valores nas colunas podem ter mais de 1024 carateres. - Se alterar uma tabela não agrupada existente para ser agrupada, os dados existentes não são agrupados automaticamente. Apenas os novos dados armazenados com as colunas agrupadas estão sujeitos a reagrupamento automático. Para mais
informações sobre a reagrupagem de dados existentes através de uma declaração
UPDATE, consulte Modificar a especificação de agrupamento.
Quotas e limites de tabelas agrupadas
O BigQuery restringe a utilização de Cloud de Confiance by S3NS recursos partilhados com quotas e limites, incluindo limitações em determinadas operações de tabelas ou no número de tarefas executadas num dia.
Quando usa a funcionalidade de tabelas agrupadas com uma tabela particionada, está sujeito aos limites das tabelas particionadas.
As quotas e os limites também se aplicam aos diferentes tipos de trabalhos que pode executar em tabelas agrupadas. Para ver informações sobre as quotas de tarefas que se aplicam às suas tabelas, consulte Tarefas em "Quotas e limites".
Preços de tabelas agrupadas
Quando cria e usa tabelas agrupadas no BigQuery, os seus custos baseiam-se na quantidade de dados armazenados nas tabelas e nas consultas que executa nos dados. Para mais informações, consulte os preços de armazenamento e os preços de consultas.
Tal como outras operações de tabelas do BigQuery, as operações de tabelas agrupadas tiram partido das operações gratuitas do BigQuery, como o carregamento em lote, a cópia de tabelas, o reagrupamento automático e a exportação de dados. Estas operações estão sujeitas a quotas e limites do BigQuery. Para obter informações sobre operações gratuitas, consulte o artigo Operações gratuitas.
Para ver um exemplo detalhado de preços de tabelas agrupadas, consulte o artigo Estime os custos de armazenamento e de consultas.
Segurança da mesa
Para controlar o acesso a tabelas no BigQuery, consulte o artigo Controle o acesso a recursos com a IAM.
O que se segue?
- Para saber como criar e usar tabelas agrupadas, consulte o artigo Criar e usar tabelas agrupadas.
- Para obter informações sobre como consultar tabelas agrupadas, consulte o artigo Consultar tabelas agrupadas.