
Neste tutorial, cria uma vista autorizada no BigQuery que é usada pelos seus analistas de dados. As vistas autorizadas permitem-lhe partilhar resultados de consultas com utilizadores e grupos específicos sem lhes conceder acesso aos dados de origem subjacentes. A vista recebe acesso aos dados de origem, em vez de um utilizador ou um grupo. Também pode usar a consulta SQL da vista para excluir colunas e campos dos resultados da consulta.
Uma abordagem alternativa à utilização de uma visualização autorizada seria configurar controlos de acesso ao nível da coluna nos dados de origem e, em seguida, dar aos utilizadores acesso a uma visualização que consulte os dados com controlo de acesso. Para mais informações sobre os controlos de acesso ao nível da coluna, consulte o artigo Introdução ao controlo de acesso ao nível da coluna.
Se tiver várias visualizações autorizadas que acedem ao mesmo conjunto de dados de origem, pode autorizar o conjunto de dados que contém as visualizações em vez de autorizar uma visualização individual.
Objetivos
- Crie um conjunto de dados para conter os dados de origem.
- Executar uma consulta para carregar dados numa tabela de destino no conjunto de dados de origem.
- Crie um conjunto de dados para conter a sua vista autorizada.
- Crie uma vista autorizada a partir de uma consulta SQL que restrinja as colunas que os seus analistas de dados podem ver nos resultados da consulta.
- Conceda aos seus analistas de dados autorização para executar tarefas de consulta.
- Conceda aos seus analistas de dados acesso ao conjunto de dados que contém a vista autorizada.
- Conceda à vista autorizada acesso ao conjunto de dados de origem.
Custos
Neste documento, usa os seguintes componentes faturáveis do Cloud de Confiance by S3NS:
Quando terminar as tarefas descritas neste documento, pode evitar a faturação contínua eliminando os recursos que criou. Para mais informações, consulte o artigo Limpe.
Antes de começar
-
In the Cloud de Confiance console, on the project selector page, select or create a Cloud de Confiance project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Cloud de Confiance project.
-
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Certifique-se de que tem as autorizações necessárias para realizar as tarefas descritas neste documento.
Aceda à página do BigQuery.
No painel esquerdo, clique em Explorador:

Se não vir o painel do lado esquerdo, clique em Expandir painel do lado esquerdo para o abrir.
No painel Explorador, junto ao projeto onde quer criar o conjunto de dados, clique em Ver ações > Criar conjunto de dados.
Na página Criar conjunto de dados, faça o seguinte:
Para o ID do conjunto de dados, introduza
github_source_data.Para Tipo de localização, verifique se a opção Várias regiões está selecionada.
Para Multirregião, escolha EUA ou UE. Todos os recursos que criar neste tutorial devem estar na mesma localização multirregional.
Clique em Criar conjunto de dados.
Na Cloud de Confiance consola, aceda à página BigQuery.
No editor de consultas, introduza a seguinte declaração:
CREATE SCHEMA github_source_data;
Clique em Executar.
Aceda à página do BigQuery.
No editor de consultas, introduza a seguinte consulta:
SELECT commit, author, committer, repo_name FROM `bigquery-public-data.github_repos.commits` LIMIT 1000;Clique em Mais e selecione Definições de consulta.
Em Destino, selecione Definir uma tabela de destino para os resultados da consulta.
Para Conjunto de dados, introduza
PROJECT_ID.github_source_data.Substitua
PROJECT_IDpelo ID do seu projeto.Para o ID da tabela, introduza
github_contributors.Clique em Guardar.
Clique em Executar.
Quando a consulta estiver concluída, no painel Explorador, clique em Conjuntos de dados e, de seguida, clique no conjunto de dados
github_source_data.Clique em Vista geral > Tabelas e, de seguida, clique na tabela
github_contributors.Para verificar se os dados foram escritos na tabela, clique no separador Pré-visualizar.
Aceda à página do BigQuery.
No painel esquerdo, clique em Explorador:
No painel Explorador, selecione o projeto onde quer criar o conjunto de dados.
Expanda a opção Ver ações e clique em Criar conjunto de dados.
Na página Criar conjunto de dados, faça o seguinte:
Para o ID do conjunto de dados, introduza
shared_views.Para Tipo de localização, verifique se a opção Várias regiões está selecionada.
Para Multirregião, escolha EUA ou UE. Todos os recursos que criar neste tutorial devem estar na mesma localização multirregional.
Clique em Criar conjunto de dados.
Na Cloud de Confiance consola, aceda à página BigQuery.
No editor de consultas, introduza a seguinte declaração:
CREATE SCHEMA shared_views;
Clique em Executar.
Aceda à página do BigQuery.
No editor de consultas, introduza a seguinte consulta.
SELECT commit, author.name AS author, committer.name AS committer, repo_name FROM `PROJECT_ID.github_source_data.github_contributors`;
Substitua
PROJECT_IDpelo ID do seu projeto.Clique em Guardar > Guardar vista.
Na caixa de diálogo Guardar vista, faça o seguinte:
Para Projeto, verifique se o seu projeto está selecionado.
Para Conjunto de dados, introduza
shared_views.Para Tabela, introduza
github_analyst_view.Clique em Guardar.
Na Cloud de Confiance consola, aceda à página BigQuery.
No editor de consultas, introduza a seguinte declaração:
CREATE VIEW shared_views.github_analyst_view AS ( SELECT commit, author.name AS author, committer.name AS committer, repo_name FROM `PROJECT_ID.github_source_data.github_contributors` );
Substitua
PROJECT_IDpelo ID do seu projeto.Clique em Executar.
Na Cloud de Confiance consola, aceda à página IAM.
Certifique-se de que o seu projeto está selecionado no seletor de projetos.
Clique em Conceder acesso.
Na caixa de diálogo Conceder acesso a, faça o seguinte:
No campo Novos responsáveis, introduza o grupo que contém os seus analistas de dados. Por exemplo,
data_analysts@example.com.No campo Selecionar uma função, pesquise a função Utilizador do BigQuery e selecione-a.
Clique em Guardar.
Aceda à página do BigQuery.
No painel esquerdo, clique em Explorador:
No painel Explorador, clique em Conjuntos de dados e, de seguida, selecione o conjunto de dados
shared_viewspara abrir o separador Detalhes.Clique em Partilha > Autorizações.
No painel Autorizações de partilha, clique em Adicionar principal.
Para Novos responsáveis, introduza o grupo que contém os seus analistas de dados, por exemplo,
data_analysts@example.com.Clique em Selecionar uma função e selecione BigQuery > Visualizador de dados do BigQuery.
Clique em Guardar.
Clique em Fechar.
Aceda à página do BigQuery.
No painel esquerdo, clique em Explorador:
No painel Explorador, clique em Conjuntos de dados e, de seguida, selecione o conjunto de dados
github_source_datapara abrir o separador Detalhes.Clique em Partilha > Autorizar visualizações.
No painel Vistas autorizadas, para Vista autorizada, introduza
PROJECT_ID.shared_views.github_analyst_view.Substitua PROJECT_ID pelo ID do seu projeto.
Clique em Adicionar autorização.
Aceda à página do BigQuery.
No editor de consultas, introduza a seguinte declaração:
SELECT * FROM `
PROJECT_ID.shared_views.github_analyst_view`;Substitua
PROJECT_IDpelo ID do seu projeto.Clique em Executar.
- In the Cloud de Confiance console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- In the Cloud de Confiance console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Elimine o conjunto de dados que contém a vista autorizada.
Elimine a tabela no conjunto de dados de origem.
- Para saber mais sobre os controlos de acesso no BigQuery, consulte o artigo Funções e autorizações do IAM do BigQuery.
- Para saber mais acerca das visualizações do BigQuery, consulte o artigo Introdução às visualizações lógicas.
- Para saber mais acerca das vistas autorizadas, consulte o artigo Vistas autorizadas.
- Para saber mais sobre os conceitos básicos do controlo de acesso, consulte o artigo Vista geral da IAM.
- Para saber como gerir o controlo de acesso, consulte o artigo Gerir políticas.
Crie um conjunto de dados para armazenar os dados de origem
Começa por criar um conjunto de dados para armazenar os dados de origem.
Para criar o conjunto de dados de origem, escolha uma das seguintes opções:
Consola
SQL
Use a CREATE SCHEMA declaração DDL:
Para mais informações sobre como executar consultas, consulte o artigo Execute uma consulta interativa.
Java
Antes de experimentar este exemplo, siga as Javainstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Java BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Antes de executar exemplos de código, defina a variável GOOGLE_CLOUD_UNIVERSE_DOMAIN environment
como s3nsapis.fr.
Python
Antes de experimentar este exemplo, siga as Pythoninstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Python BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Antes de executar exemplos de código, defina a variável GOOGLE_CLOUD_UNIVERSE_DOMAIN environment
como s3nsapis.fr.
Crie uma tabela e carregue os dados de origem
Depois de criar o conjunto de dados de origem, preenche uma tabela no mesmo guardando os resultados de uma consulta SQL numa tabela de destino. A consulta obtém dados do conjunto de dados público do GitHub.
Consola
Java
Antes de experimentar este exemplo, siga as Javainstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Java BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Antes de executar exemplos de código, defina a variável GOOGLE_CLOUD_UNIVERSE_DOMAIN environment
como s3nsapis.fr.
Python
Antes de experimentar este exemplo, siga as Pythoninstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Python BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Antes de executar exemplos de código, defina a variável GOOGLE_CLOUD_UNIVERSE_DOMAIN environment
como s3nsapis.fr.
Crie um conjunto de dados para armazenar a sua vista autorizada
Depois de criar o conjunto de dados de origem, cria um novo conjunto de dados separado para armazenar a vista autorizada que partilha com os seus analistas de dados. Num passo posterior, concede à vista autorizada acesso aos dados no conjunto de dados de origem. Os seus analistas de dados têm acesso à vista autorizada, mas não acesso direto aos dados de origem.
As vistas autorizadas devem ser criadas num conjunto de dados diferente dos dados de origem. Desta forma, os proprietários dos dados podem conceder aos utilizadores acesso à vista autorizada sem conceder simultaneamente acesso aos dados subjacentes. O conjunto de dados de origem e o conjunto de dados de visualização autorizado têm de estar na mesma localização regional.
Para criar um conjunto de dados para armazenar a sua vista, escolha uma das seguintes opções:
Consola
SQL
Use a CREATE SCHEMA declaração DDL:
Para mais informações sobre como executar consultas, consulte o artigo Execute uma consulta interativa.
Java
Antes de experimentar este exemplo, siga as Javainstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Java BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Antes de executar exemplos de código, defina a variável GOOGLE_CLOUD_UNIVERSE_DOMAIN environment
como s3nsapis.fr.
Python
Antes de experimentar este exemplo, siga as Pythoninstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Python BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Antes de executar exemplos de código, defina a variável GOOGLE_CLOUD_UNIVERSE_DOMAIN environment
como s3nsapis.fr.
Crie a vista autorizada no novo conjunto de dados
No novo conjunto de dados, crie a visualização que pretende autorizar. Esta é a vista que partilha com os seus analistas de dados. Esta vista é criada através de uma consulta SQL que exclui as colunas que não quer que os analistas de dados vejam.
A tabela de origem github_contributors contém dois campos do tipo RECORD:
author e committer. Para este tutorial, a sua vista autorizada exclui todos os dados do autor, exceto o nome do autor, e exclui todos os dados do autor da confirmação, exceto o nome do autor da confirmação.
Para criar a vista no novo conjunto de dados, escolha uma das seguintes opções:
Consola
SQL
Use a CREATE VIEW declaração DDL:
Para mais informações sobre como executar consultas, consulte o artigo Execute uma consulta interativa.
Java
Antes de experimentar este exemplo, siga as Javainstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Java BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Antes de executar exemplos de código, defina a variável GOOGLE_CLOUD_UNIVERSE_DOMAIN environment
como s3nsapis.fr.
Python
Antes de experimentar este exemplo, siga as Pythoninstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Python BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Antes de executar exemplos de código, defina a variável GOOGLE_CLOUD_UNIVERSE_DOMAIN environment
como s3nsapis.fr.
Conceda aos seus analistas de dados autorização para executar tarefas de consulta
Para consultar a vista, os seus analistas de dados precisam da autorização bigquery.jobs.create para poderem executar tarefas de consulta e têm de ter acesso à vista. Nesta secção, concede a função de bigquery.user aos seus analistas de dados. A função
bigquery.user inclui a autorização bigquery.jobs.create. Num passo posterior, concede aos seus analistas de dados autorização para aceder à vista.
Para atribuir o grupo de analistas de dados à função bigquery.user ao nível do projeto, faça o seguinte:
Conceda aos seus analistas de dados autorização para consultar a vista autorizada
Para que os seus analistas de dados consultem a vista, têm de receber a função bigquery.dataViewer ao nível do conjunto de dados ou da vista.
A concessão desta função ao nível do conjunto de dados dá aos seus analistas acesso a todas as tabelas e vistas no conjunto de dados. Uma vez que o conjunto de dados criado neste tutorial contém uma única visualização de propriedade autorizada, está a conceder acesso ao nível do conjunto de dados. Se tiver uma coleção de vistas autorizadas às quais precisa de conceder acesso, considere usar um conjunto de dados autorizado.
A função bigquery.user que concedeu anteriormente aos seus analistas de dados
dá-lhes as autorizações necessárias para criar tarefas de consulta. No entanto, não podem consultar com êxito a vista, a menos que também tenham acesso bigquery.dataViewer à vista autorizada ou ao conjunto de dados que contém a vista.
Para conceder aos seus analistas de dados bigquery.dataViewer acesso ao conjunto de dados que
contém a vista autorizada, faça o seguinte:
Consola
Java
Antes de experimentar este exemplo, siga as Javainstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Java BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Antes de executar exemplos de código, defina a variável GOOGLE_CLOUD_UNIVERSE_DOMAIN environment
como s3nsapis.fr.
Python
Antes de experimentar este exemplo, siga as Pythoninstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Python BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Antes de executar exemplos de código, defina a variável GOOGLE_CLOUD_UNIVERSE_DOMAIN environment
como s3nsapis.fr.
Autorize a vista a aceder ao conjunto de dados de origem
Depois de criar controlos de acesso para o conjunto de dados que contém a vista autorizada, concede à vista autorizada acesso ao conjunto de dados de origem. Esta autorização dá à vista, mas não ao seu grupo de analistas de dados, acesso aos dados de origem.
Para conceder à vista autorizada acesso aos dados de origem, escolha uma destas opções:
Consola
Java
Antes de experimentar este exemplo, siga as Javainstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Java BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Antes de executar exemplos de código, defina a variável GOOGLE_CLOUD_UNIVERSE_DOMAIN environment
como s3nsapis.fr.
Python
Antes de experimentar este exemplo, siga as Pythoninstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Python BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Antes de executar exemplos de código, defina a variável GOOGLE_CLOUD_UNIVERSE_DOMAIN environment
como s3nsapis.fr.
Valide a configuração
Quando a configuração estiver concluída, um membro do seu grupo de analistas de dados (por exemplo, data_analysts) pode validar a configuração consultando a vista.
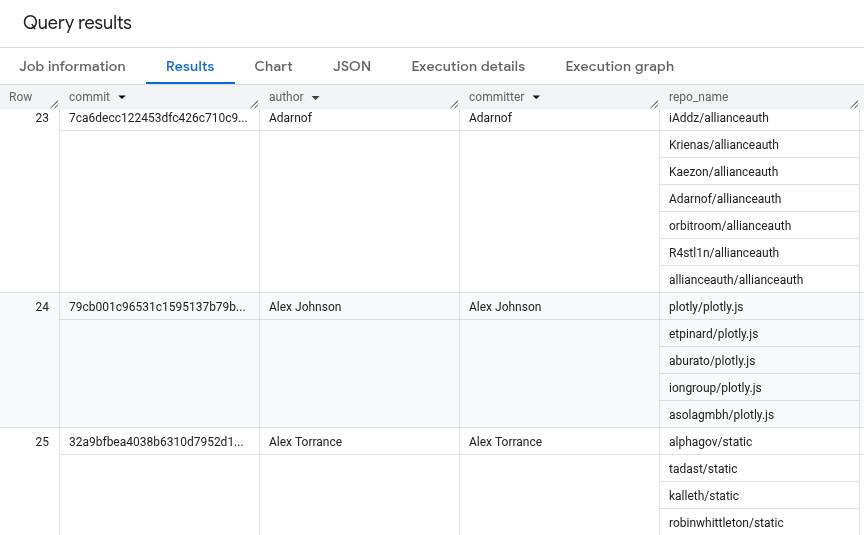
Para validar a configuração, um analista de dados deve executar a seguinte consulta:
Os resultados da consulta são semelhantes aos seguintes. Apenas o nome do autor e o nome do responsável pela confirmação são visíveis nos resultados.
Para mais informações sobre como executar consultas, consulte o artigo Execute uma consulta interativa.
Código fonte completo
Segue-se o código fonte completo do tutorial para sua referência.
Java
Antes de experimentar este exemplo, siga as Javainstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Java BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Antes de executar exemplos de código, defina a variável GOOGLE_CLOUD_UNIVERSE_DOMAIN environment
como s3nsapis.fr.
Python
Antes de experimentar este exemplo, siga as Pythoninstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Python BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Antes de executar exemplos de código, defina a variável GOOGLE_CLOUD_UNIVERSE_DOMAIN environment
como s3nsapis.fr.
Limpar
Para evitar incorrer em custos na sua conta do Google Cloud pelos recursos usados neste tutorial, elimine o projeto que contém os recursos ou mantenha o projeto e elimine os recursos individuais.
Elimine o projeto
Consola
gcloud
Elimine recursos individuais
Em alternativa, para remover os recursos individuais usados neste tutorial, faça o seguinte:
Uma vez que criou os recursos usados neste tutorial, não são necessárias autorizações adicionais para os eliminar.