
Analyser avec le canevas de données BigQuery
Ce document explique comment utiliser le canevas de données pour analyser les données. Vous pouvez également gérer les métadonnées du canevas de données à l'aide de Knowledge Catalog.
Le canevas de données BigQuery, une fonctionnalité de Gemini dans BigQuery, vous permet de rechercher, de transformer, d'interroger et de visualiser des données à l'aide de requêtes en langage naturel et d'une interface graphique pour les workflows d'analyse.
Pour les workflows d'analyse, le canevas de données BigQuery utilise un graphe orienté acyclique (DAG), qui fournit une vue graphique de votre workflow. Dans le canevas de données BigQuery, vous pouvez effectuer une itération sur les résultats de requête et travailler avec plusieurs branches d'interrogation au même endroit.
Le canevas de données BigQuery est conçu pour accélérer les tâches d'analyse et aider les professionnels des données tels que les analystes de données, les ingénieurs en données et d'autres professionnels dans leur parcours d'obtention d'insights à partir de données. Vous n'avez pas besoin de connaissances techniques sur des outils spécifiques, mais seulement de savoir lire et écrire du SQL. Le canevas de données BigQuery fonctionne avec les métadonnées Knowledge Catalog pour identifier les tables appropriées en fonction du langage naturel.
Le canevas de données BigQuery n'est pas destiné à être utilisé directement par les utilisateurs professionnels.
Les canevas de données BigQuery utilisent Gemini dans BigQuery pour rechercher vos données, créer du code SQL, générer des graphiques et créer des résumés de données.
Découvrez comment et quand Gemini pour Cloud de Confiance utilise vos données.
Capacités
Le canevas de données BigQuery vous permet d'effectuer les opérations suivantes :
Utiliser des requêtes en langage naturel ou la syntaxe de recherche de mots clés avec les métadonnées Knowledge Catalog pour rechercher des éléments tels que des tables, des vues ou des vues matérialisées.
Utiliser le langage naturel pour les requêtes SQL de base. Par exemple :
- Requêtes contenant des clauses
FROM, fonctions mathématiques, tableaux et structures. - Opérations
JOINpour deux tables.
- Requêtes contenant des clauses
Créer des visualisations personnalisées en utilisant le langage naturel pour décrire ce que vous souhaitez.
Automatiser les insights sur les données.
Limites
Les commandes en langage naturel peuvent ne pas fonctionner correctement avec les éléments suivants :
- BigQuery ML
- Apache Spark
- Tables d'objets
- BigLake
INFORMATION_SCHEMAvues- JSON
- Champs imbriqués et répétés
- Fonctions et types de données complexes, tels que
DATETIMEetTIMEZONE
Les visualisations de données ne fonctionnent pas avec les graphiques de cartes géographiques.
Bonnes pratiques concernant les requêtes
Avec les bonnes techniques de requêtage, vous pouvez générer des requêtes SQL complexes. Les suggestions suivantes aident le canevas de données BigQuery à affiner vos requêtes en langage naturel pour améliorer la précision de vos requêtes :
Écrivez de manière claire. Énoncez votre demande clairement et évitez d'être vague.
Posez des questions directes. Pour obtenir la réponse la plus précise, posez une question à la fois et rédigez des requêtes concises. Si vous avez initialement formulé une requête comportant plusieurs questions, détaillez chaque partie distincte de la question pour que Gemini comprenne clairement ce que vous attendez.
Donnez des instructions ciblées et explicites. Mettez en avant les termes clés dans vos requêtes.
Spécifiez l'ordre des opérations. Fournissez des instructions claires et ordonnées. Divisez les tâches en petites étapes ciblées.
Affinez et itérez. Essayez différentes expressions et approches pour voir ce qui donne les meilleurs résultats.
Pour en savoir plus, consultez les bonnes pratiques de requêtage pour le canevas de données BigQuery.
Avant de commencer
- Assurez-vous que Gemini dans BigQuery est activé pour votre projet Cloud de Confiance . Cette étape est généralement effectuée par un administrateur.
- Vérifiez que vous disposez des autorisations IAM (Identity and Access Management) nécessaires pour utiliser le canevas de données BigQuery.
- Pour gérer les métadonnées du canevas de données dans Knowledge Catalog, assurez-vous que l'API Dataplex est activée dans votre projet Cloud de Confiance .
Rôles requis
Pour obtenir les autorisations nécessaires pour utiliser le canevas de données BigQuery, demandez à votre administrateur de vous accorder les rôles IAM suivants sur le projet :
- Utilisateur BigQuery Studio (
roles/bigquery.studioUser) - Utilisateur Gemini pour Google Cloud (
roles/cloudaicompanion.user)
Pour en savoir plus sur l'attribution de rôles, consultez Gérer l'accès aux projets, aux dossiers et aux organisations.
Vous pouvez également obtenir les autorisations requises via des rôles personnalisés ou d'autres rôles prédéfinis.
Pour plus d'informations sur les rôles et les autorisations IAM dans BigQuery, consultez la page Présentation d'IAM.
Pour gérer les métadonnées du canevas de données dans Knowledge Catalog, assurez-vous de disposer des rôles Knowledge Catalog requis et de l'autorisation dataform.repositories.get.
Remarques concernant la sécurité des canevas de données
Étant donné que les composants de code dans BigQuery sont fournis par Dataform, vous devez tenir compte des implications de sécurité suivantes pour les utilisateurs ayant accès à ces composants :
- La visibilité des composants de code est régie par les autorisations Dataform au niveau du projet. Les utilisateurs disposant de l'autorisation
dataform.repositories.list(incluse dans les rôles BigQuery standards tels que Utilisateur de job BigQuery, Utilisateur BigQuery Studio et Utilisateur BigQuery) peuvent voir tous les composants de code dans le panneau Explorateur du projet Cloud de Confiance , qu'ils les aient créés ou qu'ils aient été partagés avec eux. Pour limiter la visibilité, vous pouvez créer des rôles personnalisés qui excluent l'autorisationdataform.repositories.list. - Les utilisateurs qui peuvent modifier ces éléments peuvent potentiellement accéder aux secrets partagés avec l'agent de service Dataform. Pour sécuriser vos identifiants, limitez la création et la modification des accès aux utilisateurs de confiance, et limitez les secrets accessibles à l'agent de service Dataform. Pour en savoir plus, consultez Accès aux secrets lors de l'installation du package.
Pour en savoir plus, consultez Remarques sur la sécurité pour les autorisations Dataform.
Types de nœuds
Un canevas est une collection d'un ou plusieurs nœuds. Les nœuds peuvent être connectés dans n'importe quel ordre. Le canevas de données BigQuery comporte les types de nœuds suivants :
- Texte
- Rechercher
- Table
- SQL
- Nœud de destination
- Visualisation
- Insights
Nœud de texte
Dans le canevas de données BigQuery, un nœud de texte vous permet d'ajouter du contenu au format texte enrichi à votre canevas. Il est utile pour ajouter des explications, des notes ou des instructions à votre canevas, ce qui vous permet, à vous et aux autres, de mieux comprendre le contexte et l'objectif de votre analyse. Vous pouvez saisir le contenu textuel de votre choix dans l'éditeur de nœuds de texte, y compris du code Markdown pour la mise en forme. Cette fonctionnalité vous permet de créer des blocs de texte visuellement attrayants et informatifs.
À partir du nœud de texte, vous pouvez effectuer les opérations suivantes :
- Supprimez le nœud.
- Déboguez le nœud.
- Dupliquez le nœud.
Nœud de recherche
Dans le canevas de données BigQuery, un nœud de recherche vous permet de trouver et d'intégrer des composants de données dans votre canevas. Il sert de pont entre vos requêtes en langage naturel ou vos recherches par mots clés et les données avec lesquelles vous souhaitez travailler.
Vous fournissez une requête de recherche, soit en langage naturel, soit à l'aide de mots clés. Le nœud de recherche effectue des recherches dans vos composants de données. Il exploite les métadonnées Knowledge Catalog pour une meilleure connaissance du contexte. Le canevas de données BigQuery suggère également les tables, les requêtes et les requêtes enregistrées récemment utilisées.
Le nœud de recherche renvoie une liste d'assets de données pertinents correspondant à votre requête. Il tient compte des noms de colonnes et des descriptions de tables. Vous pouvez ensuite sélectionner les composants que vous souhaitez ajouter à votre canevas de données en tant que nœuds de tableau, où vous pourrez analyser et visualiser les données plus en détail.
Depuis le nœud de recherche, vous pouvez effectuer les opérations suivantes :
- Supprimez le nœud.
- Déboguez le nœud.
- Dupliquez le nœud.
Nœud de table
Dans le canevas de données BigQuery, un nœud de table représente une table spécifique que vous avez intégrée à votre workflow d'analyse. Il représente les données avec lesquelles vous travaillez et vous permet d'interagir directement avec elles.
Un nœud de table affiche des informations sur la table, comme son nom, son schéma et un aperçu des données. Vous pouvez interagir avec le tableau en affichant des détails tels que le schéma, les informations et un aperçu du tableau.
À partir du nœud de tableau, vous pouvez effectuer les opérations suivantes :
- Supprimez le nœud.
- Déboguez le nœud.
- Dupliquez le nœud.
- Exécutez le nœud.
- Exécutez le nœud et le nœud suivant.
Dans le canevas de données, vous pouvez effectuer les opérations suivantes :
- Interrogez les résultats dans un nouveau nœud SQL.
- Joignez les résultats à une autre table.
Nœud SQL
Dans le canevas de données BigQuery, un nœud SQL vous permet d'exécuter des requêtes SQL personnalisées directement dans votre canevas. Vous pouvez écrire du code SQL directement dans l'éditeur de nœuds SQL ou utiliser un prompt en langage naturel pour générer le code SQL.
Le nœud SQL exécute la requête SQL fournie sur les sources de données spécifiées. Le nœud SQL produit un tableau de résultats, qui peut ensuite être connecté à d'autres nœuds du canevas pour une analyse ou une visualisation plus approfondies. Les résultats de l'exécution d'un nœud SQL, appelés résultats de requête, peuvent également être conservés dans leur propre table à l'aide d'un nœud de destination.
Une fois la requête exécutée, vous pouvez l'exporter en tant que requête programmée, exporter les résultats de la requête ou partager le canevas, comme pour l'exécution d'une requête interactive.
Depuis le nœud SQL, vous pouvez effectuer les opérations suivantes :
- Exportez l'instruction SQL en tant que requête programmée.
- Supprimez le nœud.
- Déboguez le nœud.
- Dupliquez le nœud.
- Exécutez le nœud.
- Exécutez le nœud et le nœud suivant.
Dans le canevas de données, vous pouvez effectuer les opérations suivantes :
- Interrogez les résultats dans un nouveau nœud SQL.
- Enregistrez les résultats dans une table.
- Visualisez les résultats dans un nœud de visualisation.
- Générez des insights sur les résultats dans un nœud d'insights.
- Joignez les résultats à une autre table.
Nœud de destination
Dans le canevas de données BigQuery, un nœud de destination est un enfant d'un nœud SQL qui conserve le résultat d'une exécution SQL dans une table dédiée. Vous pouvez enregistrer la table dans un ensemble de données nouveau ou existant, ou en tant que table nouvelle ou existante dans un ensemble de données. Une fois la table de destination créée, utilisez le bouton bascule SQL pour que la table soit mise à jour en temps réel lorsque le nœud SQL parent est réexécuté.
Un nœud de destination peut devenir un nœud de table lorsqu'il est détaché de son parent et que le contenu de la table n'est pas affecté par les modifications en amont au niveau du nœud SQL parent.
Depuis le nœud de destination, vous pouvez effectuer les opérations suivantes :
- Détachez le nœud du parent pour en faire un nœud de table autonome.
- Interrogez la table dans un nouveau nœud SQL.
- Joignez les résultats à une autre table.
Nœud de visualisation
Dans le canevas de données BigQuery, un nœud de visualisation vous permet d'afficher les données de manière visuelle, ce qui facilite la compréhension des tendances, des modèles et des insights. Il propose différents types de graphiques. Vous pouvez ainsi sélectionner et personnaliser la visualisation la mieux adaptée à vos données.
Un nœud de visualisation prend une table en entrée, qui peut être le résultat d'une requête SQL ou d'un nœud de table. En fonction du type de graphique sélectionné et des données du tableau d'entrée, le nœud de visualisation génère un graphique. Vous pouvez sélectionner Graphique automatique pour laisser BigQuery choisir le type de graphique le mieux adapté à vos données. Le nœud de visualisation affiche ensuite le graphique généré.
Le nœud de visualisation vous permet de personnaliser votre graphique, y compris en modifiant les couleurs, les libellés et les sources de données. Vous pouvez également exporter le graphique au format PNG.
Visualiser les données à l'aide des types de graphiques suivants :
- Graphique à barres
- Carte de densité
- Graphique linéaire
- Graphique à secteurs
- Graphique à nuage de points
Depuis le nœud de visualisation, vous pouvez effectuer les opérations suivantes :
- Exportez le graphique au format PNG.
- Déboguez le nœud.
- Dupliquez le nœud.
- Exécutez le nœud.
- Exécutez le nœud et le nœud suivant.
Dans le canevas de données, vous pouvez effectuer les opérations suivantes :
- Générez des insights sur les résultats dans un nœud d'insights.
- Modifiez la visualisation.
Nœud "Insights"
Dans le canevas de données BigQuery, un nœud d'insights vous permet de générer des insights et des résumés à partir des données de votre canevas de données. Cela vous aide à identifier des modèles, à évaluer la qualité des données et à effectuer des analyses statistiques sur votre canevas. Il identifie les tendances, les modèles, les anomalies et les corrélations dans vos données, et génère des résumés clairs et concis des résultats de l'analyse des données.
Pour en savoir plus sur les insights sur les données, consultez Générer des insights sur les données dans BigQuery.
À partir du nœud "Insights", vous pouvez effectuer les opérations suivantes :
- Supprimez le nœud.
- Dupliquez le nœud.
- Exécutez le nœud.
Utiliser le canevas de données BigQuery
Vous pouvez utiliser le canevas de données BigQuery dans la console Cloud de Confiance , une requête ou une table.
Accédez à la page BigQuery.
Dans l'éditeur de requête, à côté de Requête SQL, cliquez sur Créer, sélectionnez IA et connaissances, puis cliquez sur Tableau de données.
Dans le champ de requête Langage naturel, saisissez un prompt en langage naturel.
Par exemple, si vous saisissez
Find me tables related to trees, le canevas de données BigQuery renvoie une liste de tables possibles, y compris des ensembles de données publics tels quebigquery-public-data.usfs_fia.plot_treeoubigquery-public-data.new_york_trees.tree_species.Sélectionnez une table.
Un nœud de table est ajouté pour la table sélectionnée au canevas de données BigQuery. Pour afficher les informations du schéma, les détails de la table ou prévisualiser les données, sélectionnez les différents onglets du nœud de table.
Facultatif : Une fois le canevas de données enregistré, utilisez la barre d'outils suivante pour afficher les détails du canevas de données ou l'historique des versions, ajouter des commentaires, répondre à un commentaire existant ou obtenir un lien vers celui-ci :
La fonctionnalité de barre d'outils Commentaires est disponible en version preview. Pour envoyer des commentaires ou demander de l'aide concernant cette fonctionnalité, envoyez un e-mail à l'adresse bqui-workspace-pod@google.com.
Commandes de canevas
La barre d'outils du canevas de données fournit les commandes suivantes pour ajouter des nœuds et gérer la vue du canevas :

- Rechercher : ajoute un nœud de recherche au canevas.
- SQL : ajoute un nœud SQL au canevas.
- Texte : ajoute un nœud Markdown ou de texte pour les commentaires.
- Commandes de zoom : vous permettent de définir un niveau de zoom spécifique.
- Ajuster à l'écran : ajuste automatiquement le zoom pour afficher tout le contenu sur le canevas.
- Zoom sur la sélection : ajuste automatiquement le zoom pour se concentrer sur le nœud sélectionné.
- Zoom avant : agrandit la vue du canevas. Vous pouvez également faire un zoom avant en maintenant enfoncée la touche Ctrl et en utilisant la molette de la souris pour faire défiler l'écran.
- Zoom arrière : réduit la vue du canevas. Vous pouvez également faire un zoom arrière en maintenant enfoncée la touche Ctrl et en utilisant la molette de la souris pour faire défiler la page.
- Plein écran : passe en mode plein écran pour le canevas.
- Ranger le canevas : organise automatiquement les nœuds sur votre canevas.
- Actualiser le canevas : exécute tous les nœuds exécutables en un seul bouton.
- Autres actions : ouvre d'autres options, comme effacer le canevas.
Les exemples suivants illustrent différentes façons d'utiliser le canevas de données BigQuery dans les workflows d'analyse.
Exemple de workflow : Rechercher, interroger et visualiser des données
Dans cet exemple, vous allez utiliser des requêtes en langage naturel dans le canevas de données BigQuery pour rechercher des données, générer une requête et la modifier. Vous devez ensuite créer un graphique.
Prompt 1 : Trouver des données
Dans la console Cloud de Confiance , accédez à la page BigQuery.
Dans l'éditeur de requête, à côté de Requête SQL, cliquez sur Créer, sélectionnez IA et connaissances, puis cliquez sur Tableau de données.
Cliquez sur Rechercher des données.
Cliquez sur filter_list Modifier les filtres de recherche, puis, dans le volet Filtrer la recherche, activez l'option Ensembles de données publics BigQuery.
Dans le champ de requête Langage naturel, saisissez le prompt en langage naturel suivant :
Chicago taxi tripsLe canevas de données BigQuery génère une liste de tables potentielles basées sur les métadonnées Knowledge Catalog. Vous pouvez sélectionner plusieurs tables.
Sélectionnez la table
bigquery-public-data.chicago_taxi_trips.taxi_trips, puis cliquez sur Ajouter au canevas.Un nœud de table est ajouté pour
taxi_tripsau canevas de données BigQuery. Pour afficher les informations du schéma, les détails de la table ou prévisualiser les données, sélectionnez les différents onglets du nœud de table.
Prompt 2 : Générer une requête SQL dans la table sélectionnée
Pour générer une requête SQL pour la table bigquery-public-data.chicago_taxi_trips.taxi_trips, procédez comme suit :
Dans le canevas de données, cliquez sur Requête.
Dans le champ de requête Langage naturel, saisissez les informations suivantes :
Get me the 100 longest tripsLe canevas de données BigQuery génère une requête SQL semblable à la suivante :
SELECT taxi_id, trip_start_timestamp, trip_end_timestamp, trip_miles FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` ORDER BY trip_miles DESC LIMIT 100;
Prompt 3 : Modifier la requête
Pour modifier la requête que vous avez générée, vous pouvez modifier manuellement la requête, ou modifier la requête en langage naturel et la regénérer. Dans cet exemple, vous utilisez un prompt en langage naturel pour modifier la requête afin de ne sélectionner que les trajets pour lesquels le client a payé en espèces.
Dans le champ de requête Langage naturel, saisissez les informations suivantes :
Get me the 100 longest trips where the payment type is cashLe canevas de données BigQuery génère une requête SQL semblable à la suivante :
SELECT taxi_id, trip_start_timestamp, trip_end_timestamp, trip_miles FROM `PROJECT_ID.chicago_taxi_trips_123123.taxi_trips` WHERE payment_type = 'Cash' ORDER BY trip_miles DESC LIMIT 100;
Dans l'exemple précédent,
PROJECT_IDcorrespond à l'ID de votre projet Cloud de Confiance .Pour afficher les résultats de la requête, cliquez sur Exécuter.
Créer un graphique
- Dans le canevas de données, cliquez sur Visualiser.
Cliquez sur Créer un graphique à barres.
Le canevas de données BigQuery crée un graphique à barres affichant le nombre maximal de kilomètres par ID de trajet. Outre la fourniture d'un graphique, le canevas de données BigQuery résume certains des détails clés des données à la base de la visualisation.
Facultatif : Effectuez l'une ou plusieurs des opérations suivantes :
- Pour modifier le graphique, cliquez sur Modifier, puis modifiez le graphique dans le volet Modifier la visualisation.
- Pour partager le canevas de données, cliquez sur Partager, puis sur Partager le lien pour copier le lien du canevas de données BigQuery.
- Pour nettoyer le canevas de données, sélectionnez Autres actions, puis Effacer le canevas. Cette étape permet d'obtenir un canevas vide.
Exemple de workflow : Joindre des tables
Dans cet exemple, vous utilisez des requêtes en langage naturel dans le canevas de données BigQuery pour rechercher des données et joindre des tables. Vous allez ensuite exporter une requête sous forme de notebook.
Prompt 1 : Trouver des données
Dans le champ de requête Langage naturel, saisissez le prompt suivant :
Information about treesLe canevas de données BigQuery suggère plusieurs tables contenant des informations sur les arbres.
Pour cet exemple, sélectionnez la table
bigquery-public-data.new_york_trees.tree_census_1995, puis cliquez sur Ajouter au canevas.La table s'affiche sur le canevas.
Prompt 2 : Joindre les tables sur leur adresse
Sur le canevas de données, cliquez sur Joindre.
Le canevas de données BigQuery suggère des tables à joindre.
Pour ouvrir un nouveau champ de requête Langage naturel, cliquez sur Rechercher des tables.
Dans le champ de requête Langage naturel, saisissez le prompt suivant :
Information about treesSélectionnez la table
bigquery-public-data.new_york_trees.tree_census_2005, puis cliquez sur Ajouter au canevas.La table s'affiche sur le canevas.
Sur le canevas de données, cliquez sur Joindre.
Dans la section Sur ce canevas, cochez la case Cellule de table, puis cliquez sur OK.
Dans le champ de requête Langage naturel, saisissez le prompt suivant :
Join on addressLe canevas de données BigQuery suggère la requête SQL pour joindre ces deux tables sur leur adresse :
SELECT * FROM `bigquery-public-data.new_york_trees.tree_census_2015` AS t2015 JOIN `bigquery-public-data.new_york_trees.tree_census_1995` AS t1995 ON t2015.address = t1995.address;
Pour exécuter la requête et afficher les résultats, cliquez sur Exécuter.
Exporter la requête sous forme de notebook
Le canevas de données BigQuery vous permet d'exporter vos requêtes sous forme de notebook.
- Dans le canevas de données, cliquez sur Exporter sous forme de notebook.
- Dans le volet Enregistrer le notebook, saisissez le nom du notebook et la région dans laquelle vous souhaitez l'enregistrer.
- Cliquez sur Enregistrer. Le notebook a bien été créé.
- Facultatif : Pour afficher le notebook créé, cliquez sur Ouvrir.
Exemple de workflow : Modifier un graphique à l'aide d'un prompt
Dans cet exemple, vous utilisez des requêtes en langage naturel dans le canevas de données BigQuery pour rechercher, interroger et filtrer des données, puis modifier les détails de la visualisation.
Prompt 1 : Trouver des données
Pour rechercher des données concernant des noms américains, saisissez le prompt suivant :
Find data about USA namesLe canevas de données BigQuery génère une liste de tables.
Pour cet exemple, sélectionnez la table
bigquery-public-data.usa_names.usa_1910_current, puis cliquez sur Ajouter au canevas.
Prompt 2 : Interroger les données
Pour interroger les données, cliquez sur Interroger dans le canevas de données, puis saisissez le prompt suivant :
Summarize this dataLe canevas de données BigQuery génère une requête semblable à la suivante :
SELECT state, gender, year, name, number FROM `bigquery-public-data.usa_names.usa_1910_current`
Cliquez sur Exécuter. Les résultats de la requête s'affichent.
Prompt 3 : Filtrer les données
- Dans le canevas de données, cliquez sur Interroger ces résultats.
Pour filtrer les données, saisissez le prompt suivant dans le champ de requête SQL :
Get me the top 10 most popular names in 1980Le canevas de données BigQuery génère une requête semblable à la suivante :
SELECT name, SUM(number) AS total_count FROM `bigquery-public-data`.usa_names.usa_1910_current WHERE year = 1980 GROUP BY name ORDER BY total_count DESC LIMIT 10;
Lorsque vous exécutez la requête, vous obtenez une table contenant les 10 prénoms d'enfants nés en 1980 les plus populaires.
Créer et modifier un graphique
Dans le canevas de données, cliquez sur Visualiser.
Le canevas de données BigQuery suggère plusieurs options de visualisation, comme un graphique à barres, un graphique à secteurs, un graphique en courbes et une visualisation personnalisée.
Pour cet exemple, cliquez sur Créer un graphique à barres.
Le canevas de données BigQuery crée un graphique à barres semblable à celui-ci :
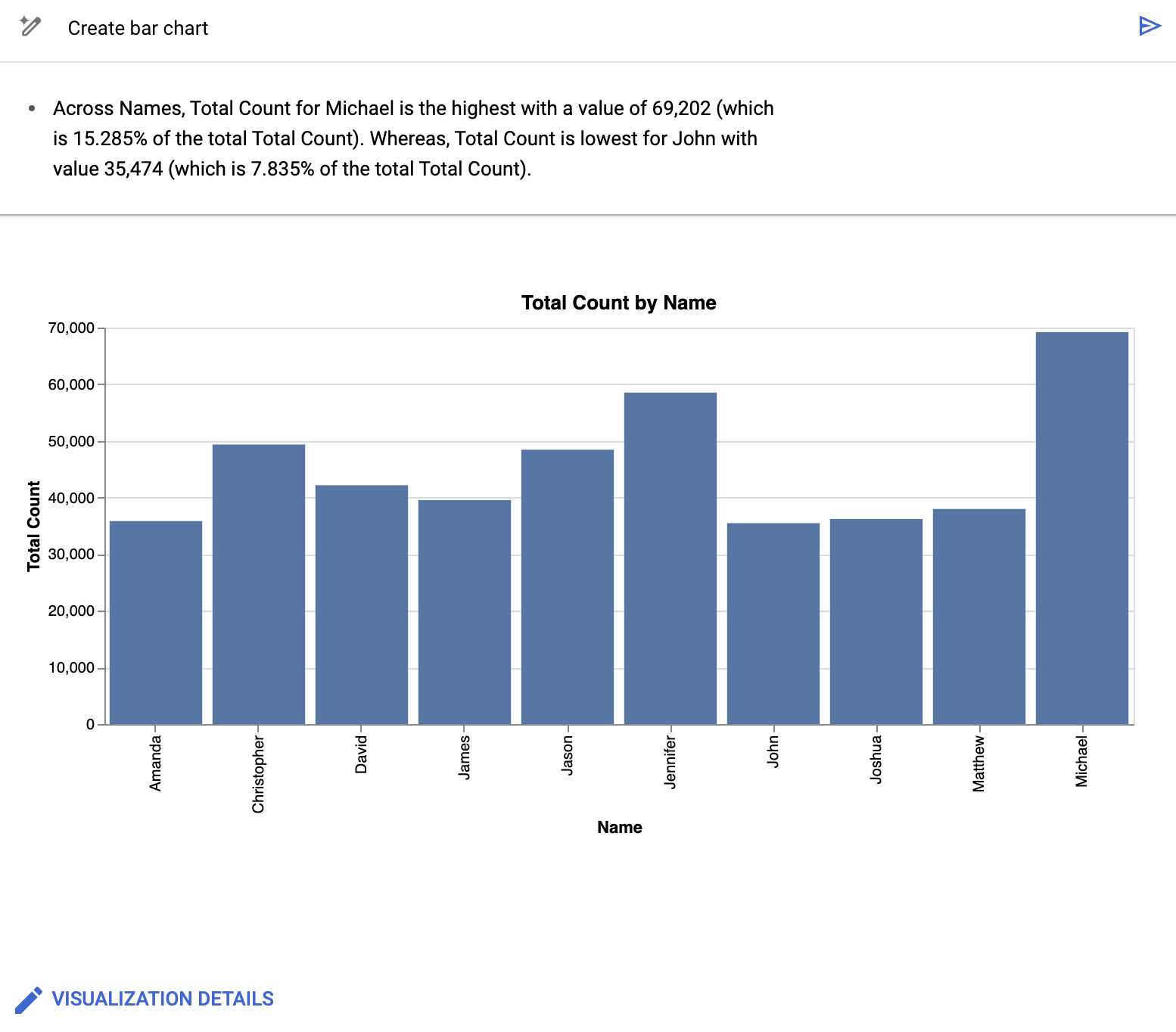
Outre la fourniture d'un graphique, le canevas de données BigQuery résume certains des détails clés des données à la base de la visualisation. Vous pouvez modifier le graphique en cliquant sur Détails de la visualisation et en modifiant votre graphique dans le panneau latéral.
Prompt 4 : Modifier les détails de la visualisation
Dans le champ de prompt Visualisation, saisissez les éléments suivants :
Create a bar chart sorted high to low, with a gradientLe canevas de données BigQuery crée un graphique à barres semblable à celui-ci :
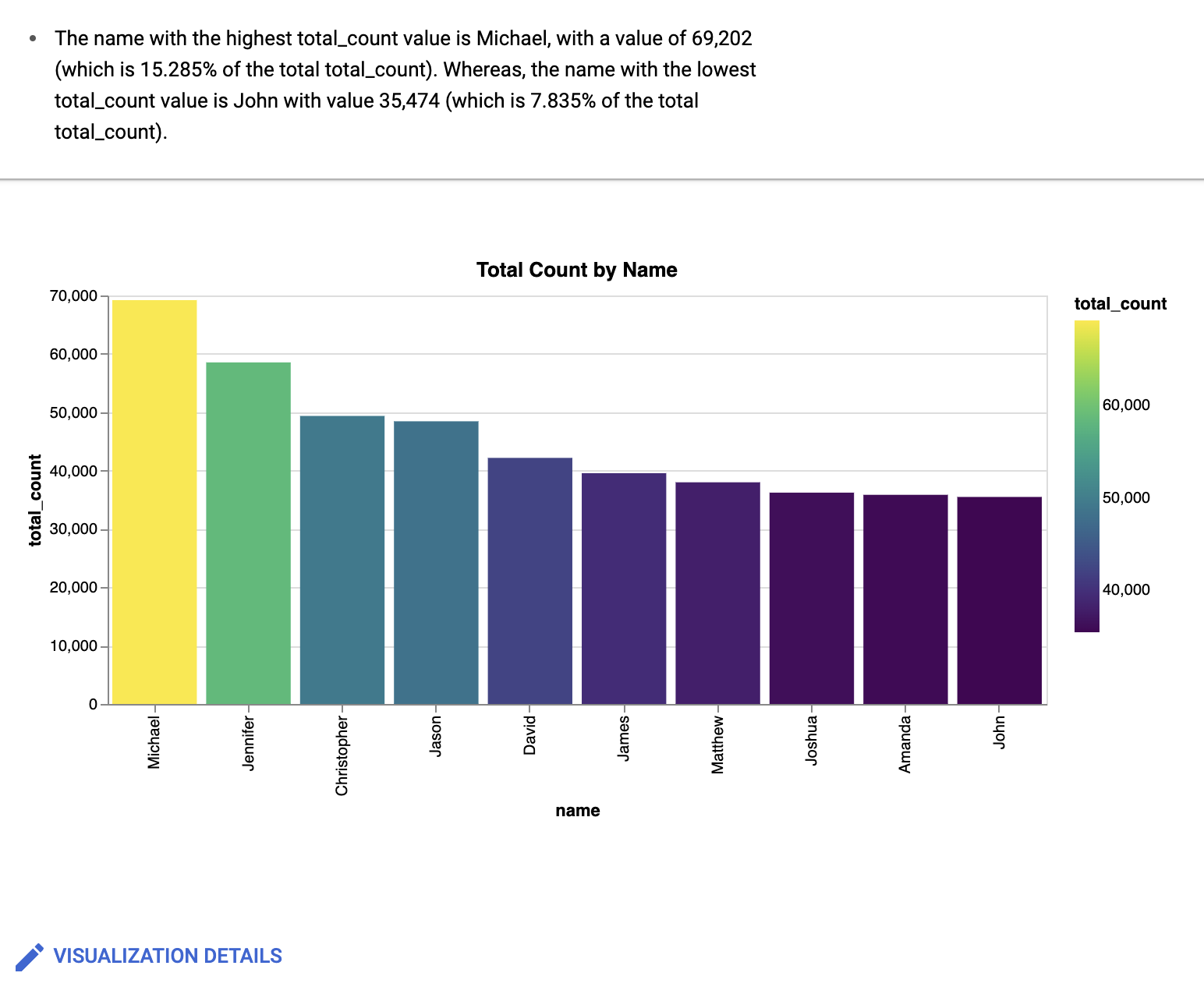
Facultatif : Pour apporter des modifications supplémentaires, cliquez sur Modifier.
Le volet Modifier la visualisation s'affiche. Vous pouvez modifier des détails tels que le titre du graphique, le nom de l'axe des abscisses et le nom de l'axe des ordonnées. De plus, si vous cliquez sur l'onglet Éditeur JSON, vous pouvez modifier directement le graphique en fonction des valeurs JSON.
Travailler avec un assistant Gemini
Vous pouvez utiliser une expérience de chat optimisée par Gemini pour travailler avec le canevas de données BigQuery. L'assistant de chat peut créer des nœuds en fonction de vos demandes, exécuter des requêtes et créer des visualisations. Vous pouvez choisir les tableaux avec lesquels l'assistant doit travailler et ajouter des instructions pour orienter son comportement. L'assistant fonctionne avec les canevas de données nouveaux ou existants.
Pour travailler avec l'assistant Gemini :
- Pour ouvrir l'assistant, cliquez sur spark Ouvrir l'assistant Data Canvas dans le canevas de données.
Dans le champ Poser une question sur les données, saisissez une requête en langage naturel (par exemple, l'une des suivantes) :
Show me interesting statistics of my data.Make a chart based on my data, sorted high to low.I want to see sample data from my table.
La réponse inclut un ou plusieurs nœuds en fonction de la requête. Par exemple, si vous demandez à l'assistant de créer un graphique de vos données, il crée un nœud de visualisation sur le canevas de données.
Lorsque vous cliquez sur le champ Poser une question sur les données, vous pouvez également effectuer les actions suivantes :
- Pour ajouter des données, cliquez sur Paramètres.
- Pour ajouter des instructions, cliquez sur Paramètres.
Pour continuer à travailler avec l'assistant, ajoutez d'autres requêtes en langage naturel.
Vous pouvez continuer à créer des requêtes en langage naturel lorsque vous travaillez avec le canevas de données.
Ajouter des données
Lorsque vous utilisez l'interface de discussion Gemini, vous pouvez ajouter des données pour que l'assistant sache à quel ensemble de données se référer. L'assistant vous demande de sélectionner une table avant d'exécuter des requêtes. Lorsque vous recherchez des données dans l'assistant, vous pouvez limiter le champ d'application des données pouvant être recherchées à tous les projets, aux projets favoris ou à votre projet actuel. Vous pouvez également choisir d'inclure ou non les ensembles de données publics dans votre recherche.
Pour ajouter des données à l'assistant Gemini :
- Pour ouvrir l'assistant, cliquez sur spark Ouvrir l'assistant Data Canvas dans le canevas de données.
- Cliquez sur Paramètres, puis sur Ajouter des données.
- Facultatif : Pour élargir les résultats de recherche afin d'inclure les ensembles de données publics, cliquez sur le bouton Ensembles de données publics pour l'activer.
- Facultatif : Pour modifier le champ d'application des résultats de recherche et l'étendre à d'autres projets, sélectionnez l'option de projet appropriée dans le menu Champ d'application.
- Cochez la case correspondant à chacune des tables que vous souhaitez ajouter à l'assistant.
- Pour rechercher des tables qui ne sont pas suggérées par l'assistant, cliquez sur Rechercher des tables.
- Dans le champ de requête Langage naturel, saisissez une requête décrivant la table que vous recherchez, puis appuyez sur Entrée.
- Cochez la case correspondant à chacune des tables que vous souhaitez ajouter à l'assistant, puis cliquez sur OK.
- Fermez le volet Paramètres de l'Assistant Canvas.
L'assistant base son analyse sur les données que vous choisissez.
Ajouter des instructions
Lorsque vous utilisez l'interface de chat Gemini, vous pouvez ajouter des instructions pour indiquer à l'assistant comment se comporter. Ces instructions s'appliquent à toutes les requêtes du canevas de données. Voici quelques exemples d'instructions potentielles :
Visualize trends over time.Chart colors: Red (negative), Green (positive)Domain: USA
Pour ajouter des instructions à l'assistant :
- Pour ouvrir l'assistant, cliquez sur spark Ouvrir l'assistant Data Canvas dans le canevas de données.
- Cliquez sur Paramètres.
- Dans le champ Instructions, ajoutez une liste d'instructions pour l'assistant, puis fermez le volet Paramètres de l'assistant Canvas.
L'assistant mémorise les instructions et les applique aux requêtes futures.
Bonnes pratiques concernant l'assistant Gemini
Pour obtenir les meilleurs résultats lorsque vous utilisez l'assistant du canevas de données BigQuery, suivez ces bonnes pratiques :
Soyez précis et univoque. Indiquez clairement ce que vous souhaitez calculer, analyser ou visualiser. Par exemple, au lieu de
Analyze trip data, ditesCalculate the average trip duration for trips starting in council district eight.Assurez-vous que le contexte des données est exact. L'assistant ne peut travailler qu'avec les données que vous lui fournissez. Assurez-vous que toutes les tables et colonnes pertinentes ont été ajoutées au canevas.
Commencez simplement, puis itérez. Commencez par une question simple pour vous assurer que l'assistant comprend la structure et les données de base. Par exemple, dites d'abord
Show total trips by, puissubscriber_typeShow total trips by.subscriber_typeand break down the result bycouncil_districtDécomposez les questions complexes. Pour les processus en plusieurs étapes, pensez à formuler clairement votre requête en la divisant en plusieurs parties distinctes ou en utilisant des requêtes distinctes pour chaque étape principale. Par exemple, dites
First, find the top five busiest stations by trip count. Second, calculate the average trip duration for trips starting from only those top five stations.Indiquez clairement les calculs. Spécifiez le calcul choisi, par exemple
SUM,MAXouAVERAGE. Par exemple, ditesFind the.MAXtrip duration perbike_idUtilisez les instructions système pour le contexte et les préférences persistants. Utilisez les instructions système pour indiquer les règles d'information et les préférences qui s'appliquent à toutes les requêtes.
Examinez le canevas. Vérifiez toujours les nœuds générés pour vous assurer que la logique correspond à votre demande et que les résultats sont exacts.
Test Essayez différentes formulations, différents niveaux de détail et différentes structures de requêtes pour comprendre comment l'assistant répond à vos besoins spécifiques en termes de données et d'analyse.
Noms des colonnes de référence. Dans la mesure du possible, utilisez les noms de colonnes réels des données sélectionnées. Par exemple, au lieu de
Show trips by subscriber type, ditesShow the count of trips grouped by.subscriber_typeandstart_station_name
Exemple de workflow : travailler avec un assistant Gemini
Dans cet exemple, vous utilisez des requêtes en langage naturel avec l'assistant Gemini pour rechercher, interroger et visualiser des données.
Dans la console Cloud de Confiance , accédez à la page BigQuery.
Dans l'éditeur de requête, à côté de Requête SQL, cliquez sur Créer, sélectionnez IA et connaissances, puis cliquez sur Tableau de données.
Cliquez sur Rechercher des données.
Cliquez sur filter_list Modifier les filtres de recherche, puis, dans le volet Filtrer la recherche, activez l'option Ensembles de données publics BigQuery.
Dans le champ de requête Langage naturel, saisissez le prompt en langage naturel suivant :
bikeshareLe canevas de données BigQuery génère une liste de tables potentielles basées sur les métadonnées Knowledge Catalog. Vous pouvez sélectionner plusieurs tables.
Sélectionnez les tables
bigquery-public-data.austin_bikeshare.bikeshare_stationsetbigquery-public-data.austin_bikeshare.bikeshare_trips, puis cliquez sur Ajouter au canevas.Un nœud de table est ajouté pour chacune des tables sélectionnées au canevas de données BigQuery. Pour afficher les informations du schéma, les détails de la table ou prévisualiser les données, sélectionnez les différents onglets du nœud de table.
Pour ouvrir l'assistant, cliquez sur spark Ouvrir l'assistant Data Canvas dans le canevas de données.
Cliquez sur Paramètres.
Dans le champ Instructions, ajoutez les instructions suivantes pour l'assistant :
Tasks: - Visualize findings with charts - Show many charts per question - Make sure to cover each part via a separate line of reasoningFermez le volet Paramètres de l'Assistant Canvas.
Dans le champ Poser une question sur les données, saisissez le prompt en langage naturel suivant :
Show the number of trips by council district and subscriber typeVous pouvez continuer à saisir des requêtes dans le champ Poser une question sur les données. Saisissez la requête suivante en langage naturel :
What are most popular stations among the top 5 subscriber typesSaisissez la requête finale :
What station is least used to start and end a tripUne fois que vous avez posé toutes les questions pertinentes, votre canevas est rempli avec les nœuds de requête et de visualisation pertinents en fonction des requêtes et des instructions que vous avez données à l'assistant. Continuez à saisir des requêtes ou à modifier celles existantes pour obtenir les résultats que vous recherchez.
Afficher tous les canevas de données
Pour afficher la liste de tous les canevas de données de votre projet, procédez comme suit :
Dans la console Cloud de Confiance , accédez à la page BigQuery.
Dans le volet de gauche, cliquez sur Explorateur :

Si le volet de gauche ne s'affiche pas, cliquez sur Développer le volet de gauche pour l'ouvrir.
Dans le volet Explorateur, cliquez sur Afficher les actions à côté de Canevas de données, puis effectuez l'une des opérations suivantes :
- Pour ouvrir la liste dans l'onglet actuel, cliquez sur Tout afficher.
- Pour ouvrir la liste dans un nouvel onglet, cliquez sur Tout afficher dans > Nouvel onglet.
- Pour ouvrir la liste dans un onglet divisé, cliquez sur Tout afficher dans > Diviser l'onglet.
Afficher les métadonnées du canevas de données
Pour afficher les métadonnées du canevas de données, procédez comme suit :
Dans la console Cloud de Confiance , accédez à la page BigQuery.
Dans le volet de gauche, cliquez sur Explorateur :
Dans le volet Explorateur, développez votre projet et cliquez sur Canevas de données.
Cliquez sur le nom du canevas de données dont vous souhaitez afficher les métadonnées.
Cliquez sur Détails pour afficher des informations sur le canevas de données, telles que la région qu'il utilise et la date de sa dernière modification.
Utiliser les versions du canevas de données
Vous pouvez choisir de créer un canevas de données à l'intérieur ou à l'extérieur d'un dépôt. La gestion des versions de Data Canvas varie en fonction de l'emplacement de Data Canvas.
Gestion des versions des canevas de données dans les dépôts
Les dépôts sont des dépôts Git qui résident dans BigQuery ou chez un fournisseur tiers. Vous pouvez utiliser des espaces de travail dans les dépôts pour effectuer le contrôle des versions sur les canevas de données. Pour en savoir plus, consultez Utiliser le contrôle des versions avec un fichier.
Gestion des versions des canevas de données en dehors des dépôts
Vous pouvez afficher, comparer et restaurer les versions d'un canevas de données.
Afficher et comparer les versions du canevas de données
Pour afficher différentes versions d'un canevas de données et les comparer à la version actuelle, procédez comme suit :
Dans la console Cloud de Confiance , accédez à la page BigQuery.
Dans le volet de gauche, cliquez sur Explorateur :
Dans le volet Explorateur, développez votre projet et cliquez sur Canevas de données.
Cliquez sur le nom du canevas de données dont vous souhaitez afficher l'historique des versions.
Cliquez sur Historique des versions pour afficher la liste des versions du canevas de données par ordre décroissant de date.
Cliquez sur Afficher les actions à côté d'une version de canevas de données, puis sur Comparer. Le volet de comparaison s'ouvre. Il compare la version du canevas de données que vous avez sélectionnée avec la version actuelle du canevas de données.
(Facultatif) Pour comparer les versions de manière intégrée plutôt que dans des volets distincts, cliquez sur Comparer, puis sur Intégré.
Restaurer une version d'un canevas de données
La restauration à partir du volet de comparaison vous permet de comparer la version précédente du canevas de données à la version actuelle avant de la restaurer.
Dans le volet de gauche, cliquez sur Explorateur :
Dans le volet Explorateur, développez votre projet et cliquez sur Canevas de données.
Cliquez sur le nom du canevas de données dont vous souhaitez restaurer une version précédente.
Cliquez sur Historique des versions.
Cliquez sur Afficher les actions à côté de la version du canevas de données que vous souhaitez restaurer, puis sur Comparer.
Le volet de comparaison s'ouvre. Il compare la version du canevas de données que vous avez sélectionnée avec la dernière version du canevas de données.
Pour restaurer la version précédente du canevas de données après la comparaison, cliquez sur Restaurer.
Cliquez sur Confirmer.
Gérer les métadonnées dans Knowledge Catalog
Knowledge Catalog vous permet d'afficher et de gérer les métadonnées des canevas de données. Les canevas de données sont disponibles dans Knowledge Catalog par défaut, sans configuration supplémentaire.
Vous pouvez utiliser Knowledge Catalog pour gérer les canevas de données dans tous les emplacements BigQuery. La gestion des canevas de données dans Knowledge Catalog est soumise aux quotas et limites de Knowledge Catalog et aux tarifs de Knowledge Catalog.
Knowledge Catalog récupère automatiquement les métadonnées suivantes à partir des canevas de données :
- Nom de l'élément de données
- Parent de l'élément de données
- Emplacement de l'élément de données
- Type d'élément de données
- Projet Cloud de Confiance correspondant
Knowledge Catalog enregistre les canevas de données en tant qu'entrées avec les valeurs d'entrée suivantes :
- Groupe d'entrées système
- Le groupe d'entrées système pour les canevas de données est
@dataform. Pour afficher les détails des entrées du canevas de données dans Knowledge Catalog, vous devez afficher le groupe d'entrées systèmedataform. Pour savoir comment afficher la liste de toutes les entrées d'un groupe d'entrées, consultez Afficher les détails d'un groupe d'entrées dans la documentation Knowledge Catalog. - Type d'entrée système
- Le type d'entrée système pour les canevas de données est
dataform-code-asset. Pour afficher les détails des canevas de données, vous devez afficher le type d'entrée systèmedataform-code-asset, filtrer les résultats avec un filtre basé sur les aspects et définir le champtypedans l'aspectdataform-code-assetsurDATA_CANVAS. Sélectionnez ensuite une entrée du canevas de données sélectionné. Pour savoir comment afficher les détails d'un type d'entrée sélectionné, consultez Afficher les détails d'un type d'entrée dans la documentation Knowledge Catalog. Pour savoir comment afficher les détails d'une entrée sélectionnée, consultez Afficher les détails d'une entrée dans la documentation Knowledge Catalog. - Type d'aspect du système
- Le type d'aspect système des canevas de données est
dataform-code-asset. Pour fournir un contexte supplémentaire aux canevas de données dans le catalogue de connaissances en annotant les entrées de canevas de données avec des aspects, affichez le type d'aspectdataform-code-asset, filtrez les résultats avec un filtre basé sur les aspects et définissez le champtypedans l'aspectdataform-code-assetsurDATA_CANVAS. Pour savoir comment annoter des entrées avec des aspects, consultez Gérer les aspects et enrichir les métadonnées dans la documentation Knowledge Catalog. - Type
- Le type de canevas de données est
DATA_CANVAS. Ce type vous permet de filtrer les canevas de données dans le type d'entrée systèmedataform-code-assetet le type d'aspectdataform-code-assetà l'aide de la requêteaspect:dataplex-types.global.dataform-code-asset.type=DATA_CANVASdans un filtre basé sur les aspects.
Pour savoir comment rechercher des éléments dans Knowledge Catalog, consultez Rechercher des éléments de données dans Knowledge Catalog dans la documentation Knowledge Catalog.
Tarifs
Pour en savoir plus sur les tarifs de cette fonctionnalité, consultez la section Présentation des tarifs de Gemini dans BigQuery.
Emplacements
Vous pouvez utiliser le canevas de données BigQuery dans toutes les zones BigQuery. Pour savoir où Gemini dans BigQuery traite vos données, consultez Où Gemini dans BigQuery traite-t-il vos données ?.
Fournir des commentaires
Vous pouvez nous aider à améliorer les suggestions du canevas de données BigQuery en envoyant vos commentaires à Google. Pour envoyer des commentaires, procédez comme suit :
- Dans la barre d'outils du canevas de données BigQuery, cliquez sur Autres actions, puis sur Envoyer des commentaires.
- Cliquez sur la catégorie à laquelle s'appliquent vos commentaires.
- Dans le champ Décrivez vos commentaires (obligatoire), saisissez vos commentaires.
- Facultatif : Pour fournir à BigQuery une capture d'écran de votre canevas de données, cliquez sur screenshot_monitor Effectuer une capture d'écran.
- Facultatif : Pour fournir votre historique de génération, sélectionnez Autoriser Google à collecter mon historique de génération et à l'envoyer avec mes commentaires.
- Cliquez sur Envoyer.
Les paramètres de partage des données s'appliquent à l'ensemble du projet et ne peuvent être définis que par un administrateur du projet disposant des autorisations IAM serviceusage.services.enable et serviceusage.services.list.
Pour nous faire directement part de vos commentaires sur cette fonctionnalité, vous pouvez également nous contacter à l'adresse datacanvas-feedback@google.com.
Étapes suivantes
Découvrez comment écrire des requêtes avec l'assistance Gemini.
Apprenez à créer des notebooks.
Découvrez comment générer des requêtes en langage naturel sur vos données grâce aux insights sur les données.