
BigQuery-Datenvorbereitung – Übersicht
Mit der KI-gestützten Datenvorbereitung in BigQuery können Sie den Zeit- und Arbeitsaufwand für manuelle Datenaufgaben erheblich reduzieren. Bei der Datenvorbereitung wird Gemini in BigQuery verwendet, um Ihre Daten zu analysieren und intelligente Vorschläge zum Bereinigen, Transformieren und Anreichern zu machen. Dataform plant diese Datenvorbereitungen.
Vorteile
- Mit kontextbezogenen, von Gemini generierten Transformationsvorschlägen können Sie den Zeitaufwand für die Entwicklung von Datenpipelines reduzieren.
- Sie können die generierten Ergebnisse in einer Vorschau prüfen und erhalten Vorschläge für die Bereinigung und Anreicherung der Datenqualität mit automatischer Schemazuordnung.
- Mit Dataform können Sie einen CI/CD-Prozess (Continuous Integration, Continuous Development) verwenden, der die teamübergreifende Zusammenarbeit für Code-Reviews und die Quellcodeverwaltung unterstützt.
Einstiegspunkte für die Datenvorbereitung
Sie können Datenvorbereitungen auf der Seite BigQuery Studio erstellen und verwalten (siehe Datenvorbereitungssitzung starten).
Wenn Sie eine Tabelle in der BigQuery-Datenaufbereitung öffnen, wird mit Ihren Anmeldedaten ein BigQuery-Job ausgeführt. Dabei werden Beispielzeilen aus der ausgewählten Tabelle erstellt und die Ergebnisse in eine temporäre Tabelle im selben Projekt geschrieben. Gemini verwendet die Beispieldaten und das Schema, um Vorschläge für die Datenaufbereitung zu generieren, die im Editor für die Datenaufbereitung angezeigt werden.
Ansichten im Editor für die Datenvorbereitung
Datenvorbereitungen werden als Tabs auf der Seite BigQuery angezeigt. Jeder Tab enthält eine Reihe von Untertabs oder Ansichten für die Datenvorbereitung, in denen Sie Ihre Datenvorbereitungen entwickeln und verwalten.
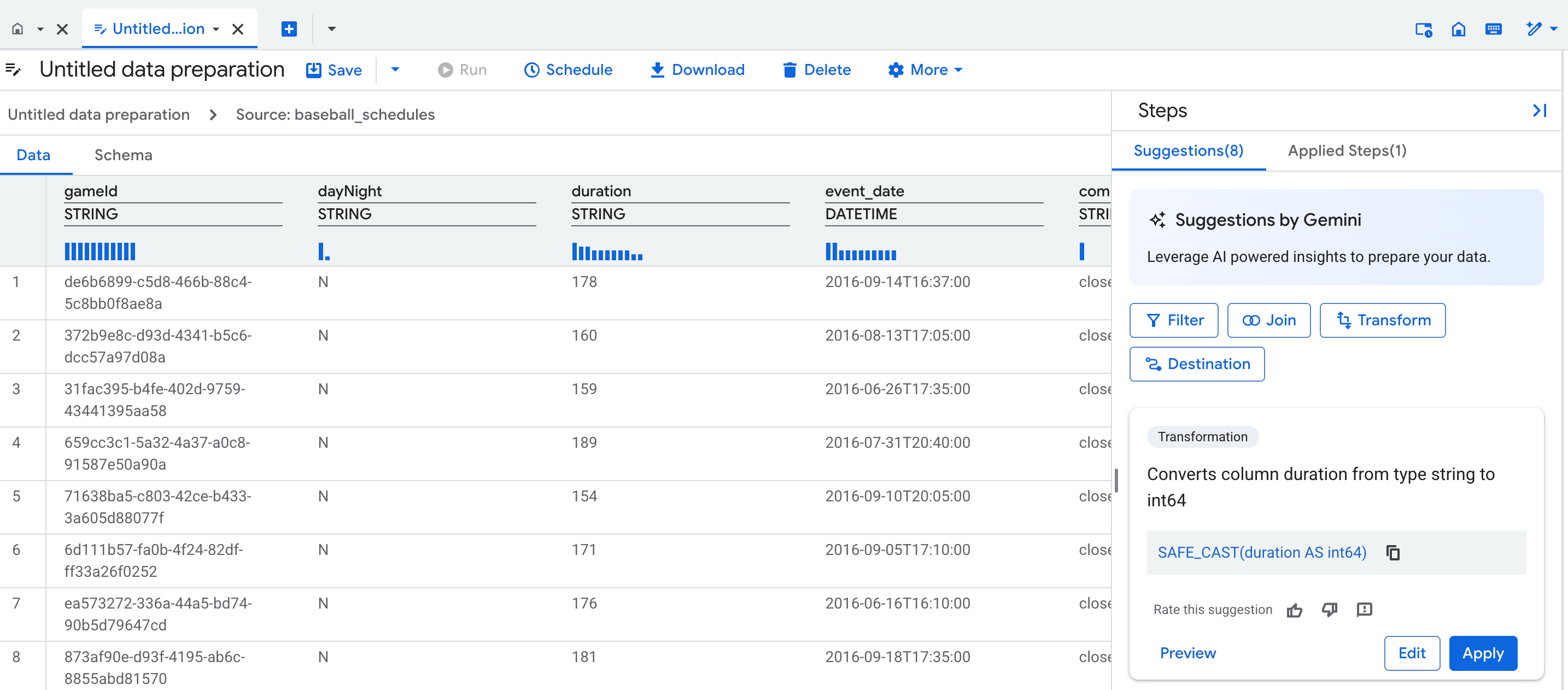
Datenansicht
Wenn Sie eine neue Datenvorbereitung erstellen, wird ein Tab mit dem Datenvorbereitungseditor geöffnet, auf dem die Datenansicht mit einer repräsentativen Stichprobe der Tabelle angezeigt wird. Bei vorhandenen Datenaufbereitungen können Sie zur Datenansicht wechseln, indem Sie in der Grafiksicht Ihrer Datenaufbereitungspipeline auf einen Knoten klicken.
In der Datenansicht haben Sie folgende Möglichkeiten:
- Mit Daten interagieren, um Schritte zur Datenaufbereitung zu erstellen
- Vorschläge von Gemini übernehmen
- Sie können die Qualität der Gemini-Vorschläge verbessern, indem Sie Beispielwerte in die Zellen eingeben.
Über jeder Spalte in der Tabelle wird ein statistisches Profil (ein Histogramm) mit der Anzahl der Top-Werte der jeweiligen Spalte in den Vorschauzeilen angezeigt.
Diagrammansicht
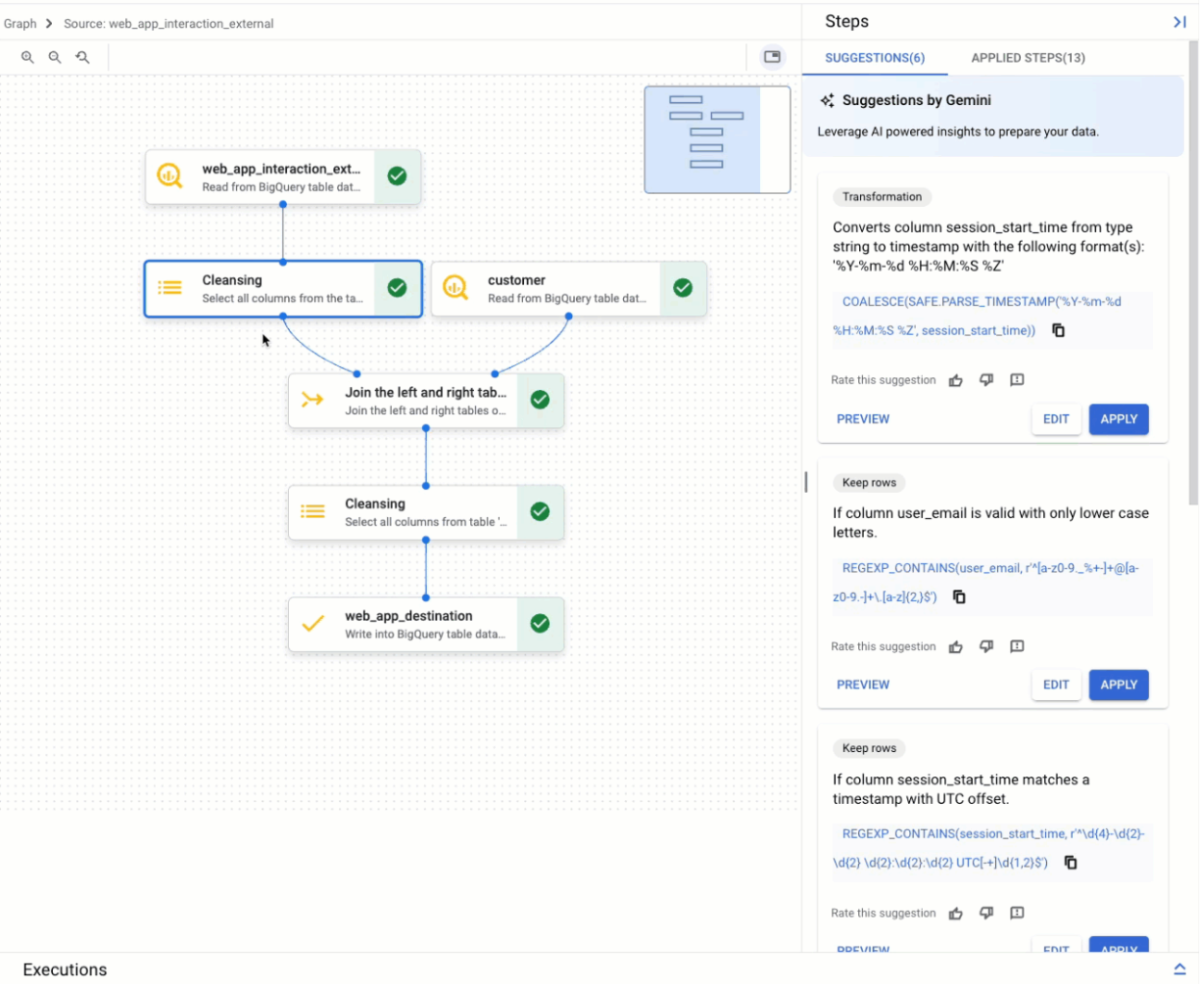
Die Grafiksicht bietet einen visuellen Überblick über die Datenaufbereitung. Sie wird als Tab auf der Seite BigQuery in der Console angezeigt, wenn Sie eine Datenaufbereitung öffnen. Im Diagramm werden Knoten für alle Schritte in Ihrer Datenaufbereitungspipeline dargestellt. Sie können einen Knoten im Diagramm auswählen, um die Datenaufbereitungsschritte zu konfigurieren, die er repräsentiert.
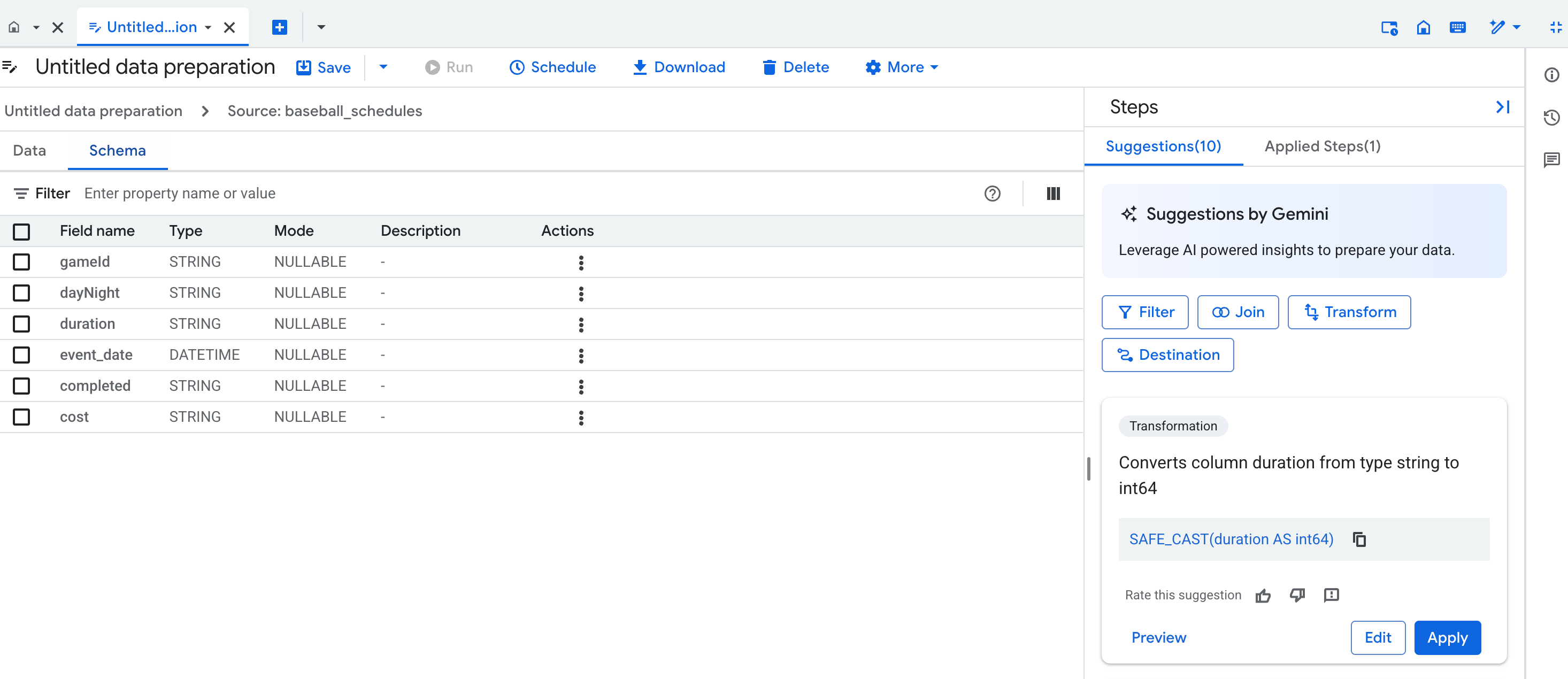
Schemaansicht
In der Schemansicht für die Datenaufbereitung wird das aktuelle Schema des aktiven Datenaufbereitungsschritts angezeigt. Das angezeigte Schema entspricht den Spalten in der Datenansicht.
In der Schemaansicht können Sie spezielle Schemaoperationen ausführen, z. B. Spalten entfernen. Dadurch werden auch Schritte in der Liste Angewendete Schritte erstellt.
Vorschläge von Gemini
Gemini bietet kontextbezogene Vorschläge für die folgenden Aufgaben zur Datenvorbereitung:
- Transformationen und Regeln für Datenqualität anwenden
- Daten standardisieren und anreichern
- Schemazuordnung automatisieren
Jeder Vorschlag wird in einer Karte in der Vorschlagsliste des Editors für die Datenaufbereitung angezeigt. Die Karte enthält die folgenden Informationen:
- Die übergeordnete Kategorie des Schritts, z. B. Zeilen beibehalten oder Transformation
- Eine Beschreibung des Schritts, z. B. Zeilen beibehalten, wenn
COLUMN_NAMEnichtNULList - Der entsprechende SQL-Ausdruck, der zum Ausführen des Schritts verwendet wird
Sie können sich eine Vorschau der Vorschlagskarte ansehen, sie bearbeiten oder anwenden oder den Vorschlag optimieren. Sie können Schritte auch manuell hinzufügen. Weitere Informationen finden Sie unter Daten mit Gemini vorbereiten.
Um die Vorschläge von Gemini zu optimieren, geben Sie ein Beispiel dafür, was in einer Spalte geändert werden soll.
Stichprobenerhebung
In BigQuery wird Stichprobenerhebung verwendet, um eine Vorschau auf die Datenaufbereitung zu geben. Sie können die Stichprobe in der Datenansicht für jeden Knoten aufrufen.
Wenn Sie BigQuery-Standardtabellen als Quelle hinzufügen, werden die Daten mit einer BigQuery-TABLESAMPLE-Funktion vorbereitet. Mit dieser Funktion wird eine Stichprobe mit 10.000 Datensätzen erstellt.
Wenn Sie eine Ansicht oder eine externe Tabelle als Quelle hinzufügen, werden die ersten 1 Million Datensätze gelesen. Aus diesen Datensätzen wählt das System eine repräsentative Stichprobe von 10.000 Datensätzen aus.
Die Daten in der Stichprobe werden nicht automatisch aktualisiert. Beispieltabelle werden als im Cache gespeicherte Abfrageergebnisse gespeichert und laufen nach etwa 24 Stunden ab. Informationen zum manuellen Aktualisieren der Beispieltabellen finden Sie unter Beispiele für die Datenaufbereitung aktualisieren.
Schreibmodus
Um Kosten und Verarbeitungszeit zu optimieren, können Sie die Einstellungen für den Schreibmodus ändern, damit neue Daten aus der Quelle inkrementell verarbeitet werden. Wenn Sie beispielsweise eine Tabelle in BigQuery haben, in die täglich Datensätze eingefügt werden, und ein Looker-Dashboard, das die geänderten Daten widerspiegeln muss, können Sie die BigQuery-Datenaufbereitung so planen, dass die neuen Datensätze inkrementell aus der Quelltabelle gelesen und in die Zieltabelle übertragen werden.
Informationen zum Konfigurieren der Art und Weise, wie die Datenaufbereitung in eine Zieltabelle geschrieben wird, finden Sie unter Datenaufbereitung durch inkrementelle Verarbeitung von Daten optimieren.
Die folgenden Schreibmodi werden unterstützt:
| Option für den Schreibmodus | Beschreibung |
|---|---|
| Vollständige Aktualisierung | Führt die Datenvorbereitungsschritte für alle Quelldaten aus und erstellt dann die Zieltabelle vollständig neu. Die Tabelle wird neu erstellt, nicht gekürzt. Der vollständige Aktualisierungsmodus ist der Standardmodus beim Schreiben in eine Zieltabelle. |
| Anhängen | Fügt alle Daten aus der Datenaufbereitung als zusätzliche Zeilen in die Zieltabelle ein. |
| Inkrementell | Nur die neuen oder, je nach Auswahl der inkrementellen Spalte, geänderten Daten in die Zieltabelle einfügen. Je nachdem, welche inkrementelle Spalte Sie auswählen, wird bei der Datenaufbereitung der optimale Mechanismus zur Erkennung von Änderungsdatensätzen ausgewählt. Für numerische und Datums-/Uhrzeit-Datentypen werden die Maximalwerte und für kategorische Daten die eindeutigen Werte ausgewählt. Bei „Maximum“ werden nur Datensätze eingefügt, bei denen der angegebene Spaltenwert größer als der Maximalwert für dieselbe Spalte in der Zieltabelle ist. Bei „Unique inserts“ werden nur Datensätze eingefügt, in denen die angegebenen Spaltenwerte nicht in den vorhandenen Werten für dieselbe Spalte in der Zieltabelle vorhanden sind. |
| Upsert | Führt Zeilen mit den angegebenen Zusammenführungsschlüsseln zusammen. Wenn eine vorhandene Zeile in der Zieltabelle mit den angegebenen Zusammenführungsschlüsseln für einen Eingabe-Datensatz übereinstimmt, werden die Werte in dieser Zeile in der Zieltabelle aktualisiert. Andernfalls wird eine neue Zeile in die Zieltabelle eingefügt. |
Unterstützte Schritte zur Datenvorbereitung
BigQuery unterstützt die folgenden Arten von Datenaufbereitungsschritten:
| Schritttyp | Beschreibung |
|---|---|
| Quelle | Fügt eine Quelle hinzu, wenn Sie eine BigQuery-Tabelle zum Lesen auswählen oder einen Join-Schritt hinzufügen. |
| Transformation | Bereinigt und transformiert Daten mithilfe eines SQL-Ausdrucks. Sie erhalten Vorschlagskarten für die folgenden Ausdrücke:
Sie können auch beliebige gültige BigQuery-SQL-Ausdrücke in manuellen Transformationsschritten verwenden. Beispiel:
Weitere Informationen finden Sie unter Transformation hinzufügen. |
| Filter | Entfernt Zeilen mithilfe der WHERE-Klauselsyntax. Wenn Sie einen Filterschritt hinzufügen, können Sie ihn in einen Validierungsschritt umwandeln.
Weitere Informationen finden Sie unter Zeilen filtern. |
| Deduplizieren | Entfernt doppelte Zeilen aus den Daten basierend auf ausgewählten Schlüsseln und der Sortierung.
Weitere Informationen finden Sie unter Daten deduplizieren. |
| Validierung | Sendet Zeilen, die die Kriterien der Validierungsregel nicht erfüllen, an eine Fehlertabelle. Wenn Daten die Validierungsregel nicht erfüllen und keine Fehlertabelle konfiguriert ist, schlägt die Datenvorbereitung während der Ausführung fehl.
Weitere Informationen finden Sie unter Fehlertabelle konfigurieren und Validierungsregel hinzufügen. |
| Beitreten | Führt Werte aus zwei Quellen zusammen. Tabellen müssen sich am selben Standort befinden.
Join-Schlüsselspalten müssen denselben Datentyp haben. Bei der Datenaufbereitung werden die folgenden Join-Vorgänge unterstützt:
Weitere Informationen finden Sie unter Join-Vorgang hinzufügen. |
| Ziel | Definiert ein Ziel für die Ausgabe von Datenvorbereitungsschritten. Wenn Sie eine Zieltabelle eingeben, die nicht vorhanden ist, wird bei der Datenvorbereitung eine neue Tabelle mit den aktuellen Schemainformationen erstellt. Weitere Informationen finden Sie unter Zieltabellen hinzufügen oder ändern. |
| Spalten löschen | Löscht Spalten aus dem Schema. Sie führen diesen Schritt in der Schemaansicht aus.
Weitere Informationen finden Sie unter Spalte löschen. |
Ausführungen der Datenvorbereitung planen
Erstellen Sie einen Zeitplan, um die Datenvorbereitungsschritte auszuführen und die vorbereiteten Daten in die Zieltabelle zu laden. Sie können Datenvorbereitungen über den Datenvorbereitungseditor planen und über die Seite Planung in BigQuery verwalten. Weitere Informationen finden Sie unter Datenvorbereitung planen.
Pipelines mit Datenvorbereitungsaufgaben erstellen
Sie können BigQuery-Pipelines erstellen, die aus Aufgaben zur Datenvorbereitung, SQL-Abfrage und Notebooks bestehen. Anschließend können Sie diese Pipelines nach Zeitplan ausführen. Weitere Informationen finden Sie unter Einführung in BigQuery-Pipelines.
Zugriff steuern
Sie können den Zugriff auf Datenaufbereitungen mit IAM-Rollen (Identity and Access Management), Verschlüsselung mit BigQuery- und Dataform-Cloud KMS-Schlüsseln und VPC Service Controls steuern.
IAM-Rollen und -Berechtigungen
Nutzer, die die Daten vorbereiten, und die Dataform-Dienstkonten, mit denen die Jobs ausgeführt werden, benötigen IAM-Berechtigungen. Weitere Informationen finden Sie unter Erforderliche Rollen und Gemini für BigQuery einrichten.
Verschlüsselung mit Cloud KMS-Schlüsseln
Verschlüsseln Sie Daten auf Dataset- oder Projektebene mit den standardmäßigen vom Kunden verwalteten Cloud KMS-Schlüsseln in BigQuery. Weitere Informationen finden Sie unter Standardschlüssel für ein Dataset festlegen und Standardschlüssel für ein Projekt festlegen.
Sie können Pipeline-Code standardmäßig auf Projektebene mit einem Dataform Cloud KMS-Schlüssel verschlüsseln.
VPC Service Controls-Perimeter
Wenn Sie VPC Service Controls verwenden, müssen Sie den Perimeter so konfigurieren, dass Dataform und BigQuery geschützt werden. Weitere Informationen finden Sie unter den VPC Service Controls-Einschränkungen für BigQuery und Dataform.
Rolle, die beim Erstellen einer Datenaufbereitung gewährt wird
Wenn Sie eine Datenaufbereitung erstellen, wird Ihnen in BigQuery die Rolle „Dataform Admin“ (roles/dataform.admin) für diese Datenaufbereitung zugewiesen. Alle Nutzer, die für das Cloud de Confiance -Projekt die Rolle „Dataform-Administrator“ haben, haben Inhaberzugriff auf alle im Projekt erstellten Datenaufbereitungen. Informationen zum Überschreiben dieses Verhaltens finden Sie unter Beim Erstellen einer Ressource eine bestimmte Rolle zuweisen.
Beschränkungen
Die Datenaufbereitung ist mit den folgenden Einschränkungen verfügbar:
- Alle BigQuery-Quell- und ‑Ziel-Datasets für die Datenaufbereitung müssen sich am selben Standort befinden. Weitere Informationen finden Sie unter Standorte.
- Während der Bearbeitung von Pipelines werden Daten und Interaktionen zur Verarbeitung an ein Gemini-Rechenzentrum gesendet. Weitere Informationen finden Sie unter Standorte.
- Gemini in BigQuery wird von Assured Workloads nicht unterstützt.
- In BigQuery-Datenvorbereitungen können keine Versionen der Datenvorbereitung aufgerufen, verglichen oder wiederhergestellt werden.
- Antworten von Gemini basieren auf einer Stichprobe des Datensatzes, den Sie bei der Entwicklung Ihrer Datenaufbereitungspipeline bereitstellen. Weitere Informationen finden Sie unter So verwendet Gemini für Cloud de Confiance Ihre Daten und in den Nutzungsbedingungen für das Trusted Tester-Programm von Gemini für Cloud de Confiance .
- Für die BigQuery-Datenvorbereitung gibt es keine eigene API. Informationen zu den erforderlichen APIs finden Sie unter Gemini in BigQuery einrichten.
Standorte
Ihre Datenverarbeitungsjobs werden am Standort Ihrer Quelldatasets ausgeführt und gespeichert. Wenn ein Repository-Standort angegeben ist, muss er mit dem Standort der Quelldatasets übereinstimmen.
Die Region für die Speicherung des Datenaufbereitungscodes kann sich von der Region für die Jobausführung unterscheiden.
Für alle neuen Code-Assets in Ihrem Cloud de Confiance -Projekt wird eine Standardregion verwendet. Nachdem das Asset erstellt wurde, können Sie seine Region nicht mehr ändern.
So legen Sie die Standardregion für neue Code-Assets fest:
Rufen Sie die Seite BigQuery auf.
Klicken Sie im linken Bereich auf Dateien, um den Dateibrowser zu öffnen:

Klicken Sie neben dem Projektnamen auf Aktionen für den Bereich „Dateien“ ansehen > Code-Region wechseln.
Wählen Sie die Code-Region aus, die Sie als Standard verwenden möchten.
Klicken Sie auf Speichern.
Eine Liste der unterstützten Regionen finden Sie unter BigQuery Studio-Standorte.
Die BigQuery-Datenverarbeitung während der Entwicklungs- und Ausführungszeit erfolgt immer am Standort Ihrer Quelldatasets. Informationen dazu, wo Gemini in BigQuery Ihre Daten verarbeitet, finden Sie unter Wo Gemini in BigQuery Ihre Daten verarbeitet.
Preise
Für die Datenvorbereitung und die Erstellung von Datenvorschau-Beispielen werden BigQuery-Ressourcen verwendet, die zu den in den BigQuery-Preisen angegebenen Preisen berechnet werden.
Die Datenvorbereitung ist in den Preisen für Gemini in BigQuery enthalten. Die BigQuery-Datenvorbereitung kann während der Vorschauphase ohne zusätzliche Kosten verwendet werden. Weitere Informationen finden Sie unter Gemini in BigQuery einrichten.