
Ringkasan persiapan data BigQuery
Anda dapat secara signifikan mengurangi waktu dan upaya yang diperlukan untuk tugas data manual dengan menggunakan persiapan data yang dioptimalkan AI di BigQuery. Persiapan data menggunakan Gemini in BigQuery untuk menganalisis data Anda dan memberikan saran cerdas untuk membersihkan, mentransformasi, dan memperkayanya. Dataform menjadwalkan persiapan data ini.
Manfaat
- Anda dapat mengurangi waktu yang dihabiskan untuk pengembangan pipeline data dengan saran transformasi yang dihasilkan Gemini dan sadar konteks.
- Anda dapat memvalidasi hasil yang dihasilkan dalam pratinjau dan menerima saran pembersihan dan pengayaan kualitas data dengan pemetaan skema otomatis.
- Dataform memungkinkan Anda menggunakan proses continuous integration, continuous development (CI/CD), yang mendukung kolaborasi lintas tim untuk peninjauan kode dan kontrol sumber.
Titik entri persiapan data
Anda dapat membuat dan mengelola persiapan data di halaman BigQuery Studio (lihat Memulai sesi persiapan data).
Saat Anda membuka tabel di penyiapan data BigQuery, tugas BigQuery akan berjalan menggunakan kredensial Anda. Run membuat baris contoh dari tabel yang dipilih dan menulis hasilnya ke tabel sementara dalam project yang sama. Gemini menggunakan data dan skema sampel untuk membuat saran penyiapan data yang ditampilkan di editor penyiapan data.
Tampilan di editor penyiapan data
Persiapan data muncul sebagai tab di halaman BigQuery. Setiap tab memiliki serangkaian sub-tab, atau tampilan penyiapan data, tempat Anda mengembangkan dan mengelola penyiapan data.
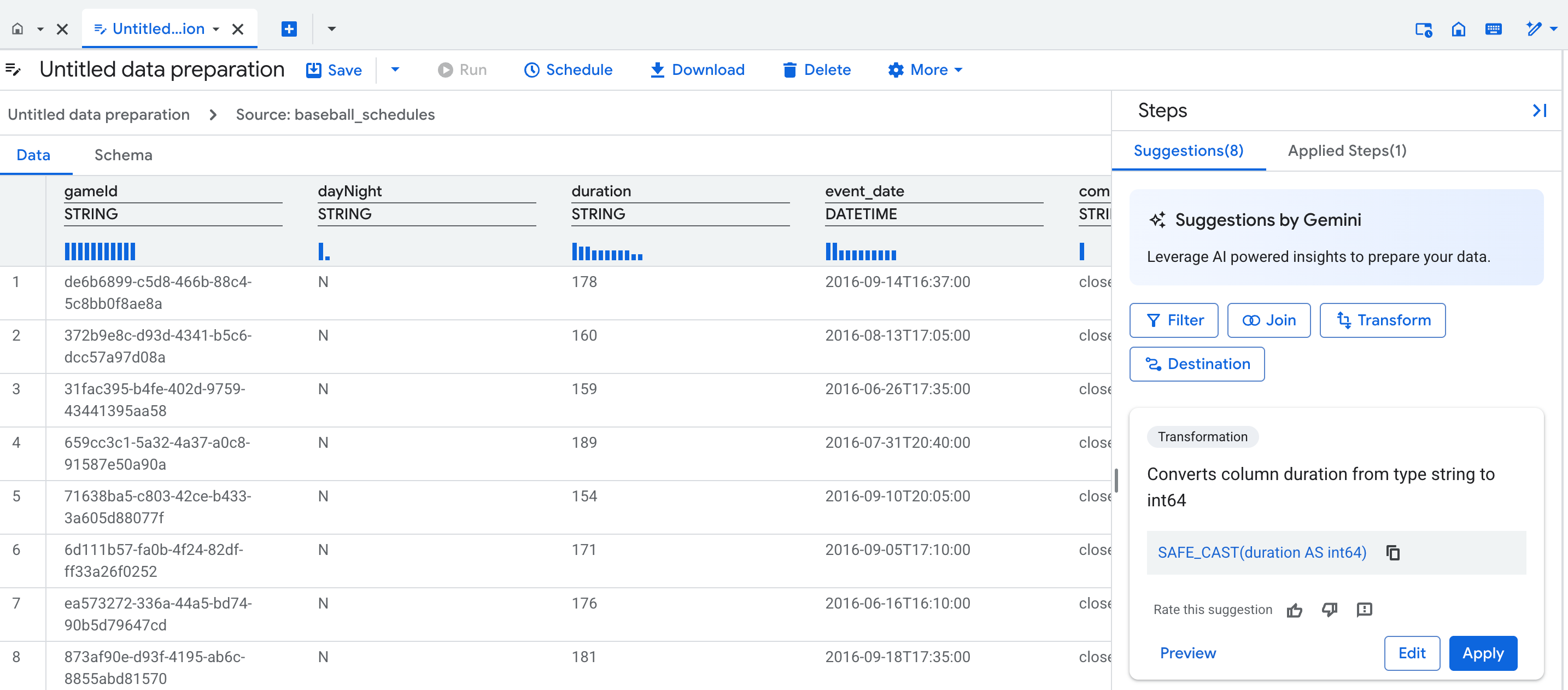
Tampilan data
Saat Anda membuat penyiapan data baru, tab editor penyiapan data akan terbuka, menampilkan tampilan data, yang berisi sampel perwakilan dari tabel. Untuk persiapan data yang ada, Anda dapat membuka tampilan data dengan mengklik node dalam tampilan grafik pipeline persiapan data.
Tampilan data memungkinkan Anda melakukan hal berikut:
- Berinteraksi dengan data Anda untuk membentuk langkah-langkah penyiapan data.
- Menerapkan saran dari Gemini.
- Tingkatkan kualitas saran Gemini dengan memasukkan nilai contoh di sel.
Di atas setiap kolom dalam tabel, profil statistik (histogram) menampilkan jumlah untuk setiap nilai teratas kolom dalam baris pratinjau.
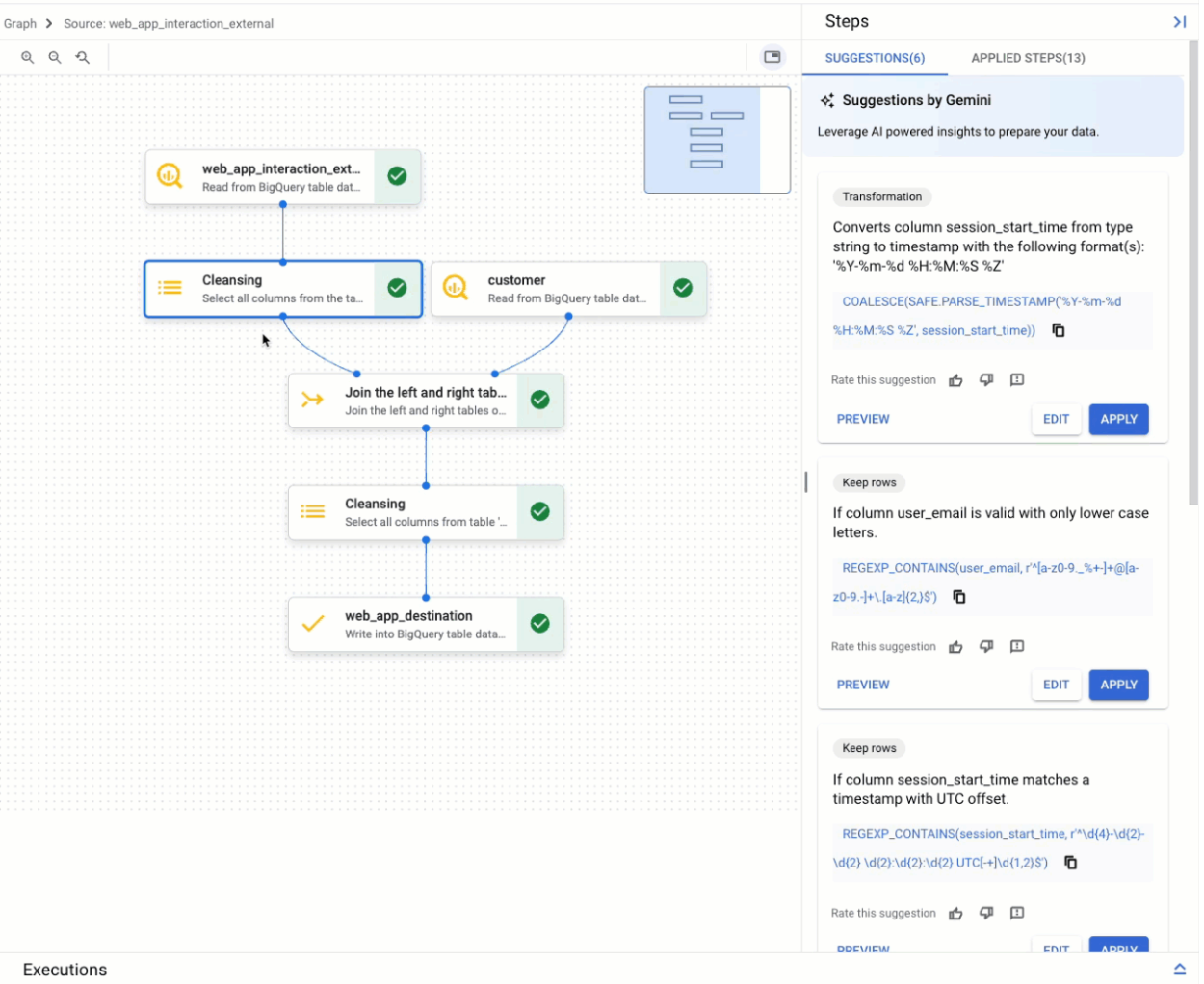
Tampilan grafik
Tampilan grafik adalah ringkasan visual penyiapan data Anda. Tab ini muncul di halaman BigQuery di konsol, saat Anda membuka penyiapan data. Grafik menampilkan node untuk semua langkah dalam pipeline penyiapan data. Anda dapat memilih node pada grafik untuk mengonfigurasi langkah-langkah penyiapan data yang diwakilinya.
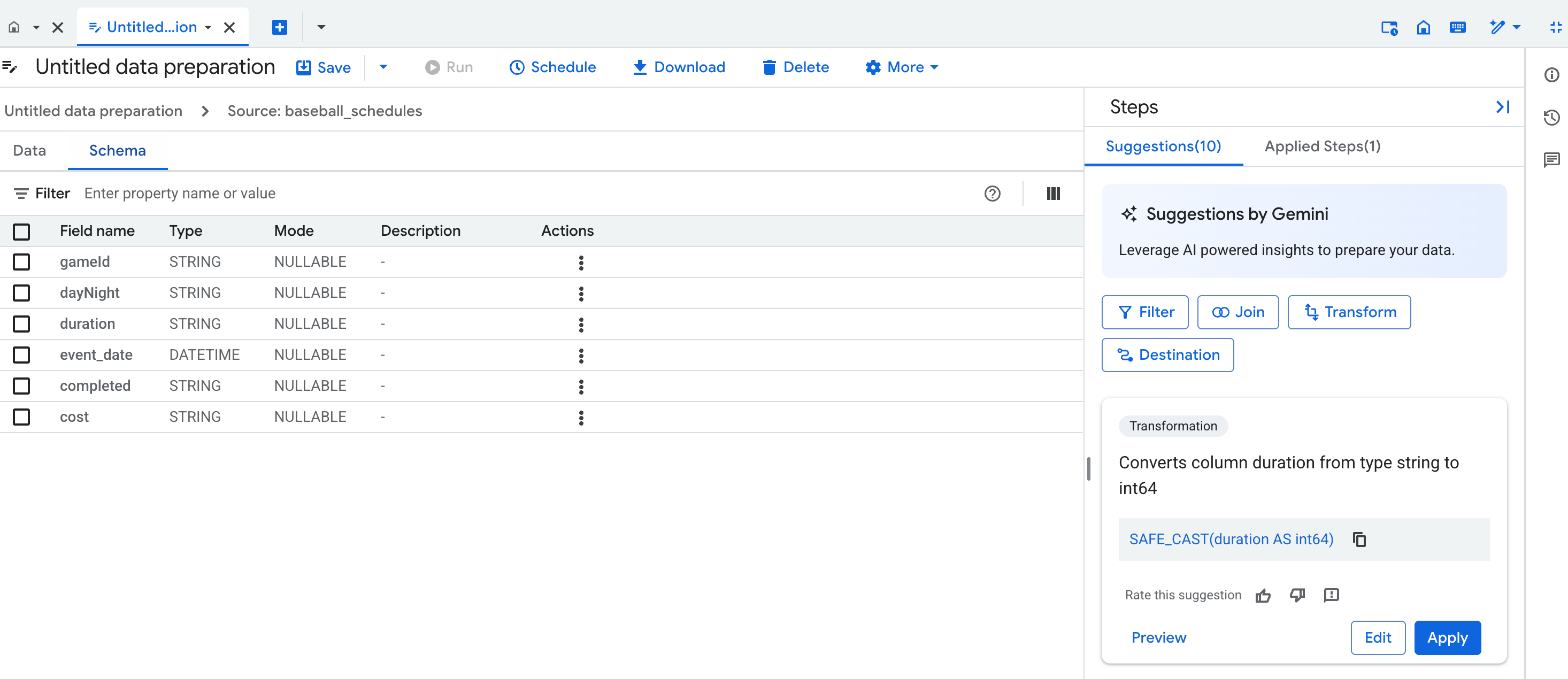
Tampilan skema
Tampilan skema persiapan data menampilkan skema langkah persiapan data aktif saat ini. Skema yang ditampilkan cocok dengan kolom dalam tampilan data.
Dalam tampilan skema, Anda dapat melakukan operasi skema khusus, seperti menghapus kolom, yang juga membuat langkah-langkah dalam daftar Langkah-langkah yang diterapkan.
Saran dari Gemini
Gemini memberikan saran yang sesuai dengan konteks untuk membantu tugas penyiapan data berikut:
- Menerapkan transformasi dan aturan kualitas data
- Menstandardisasi dan memperkaya data
- Mengotomatiskan pemetaan skema
Setiap saran muncul dalam kartu di daftar saran editor persiapan data. Kartu ini berisi informasi berikut:
- Kategori tingkat tinggi dari langkah, seperti Pertahankan baris atau Transformasi
- Deskripsi langkah, seperti Pertahankan baris jika
COLUMN_NAMEbukanNULL - Ekspresi SQL yang sesuai digunakan untuk menjalankan langkah
Anda dapat melihat pratinjau, mengedit, atau menerapkan kartu saran, atau menyesuaikan saran. Anda juga dapat menambahkan langkah-langkah secara manual. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan data dengan Gemini.
Untuk menyesuaikan saran dari Gemini, berikan contoh tentang apa yang perlu diubah dalam kolom.
Sampling data
BigQuery menggunakan pengambilan sampel data untuk memberikan pratinjau penyiapan data Anda. Anda dapat melihat sampel di tampilan data untuk setiap node.
Saat Anda menambahkan tabel standar BigQuery sebagai sumber, data akan disiapkan menggunakan fungsi
TABLESAMPLE BigQuery. Fungsi ini membuat sampel
10 ribu data.
Saat Anda menambahkan tampilan atau tabel eksternal sebagai sumber, sistem akan membaca 1 juta data pertama. Dari data ini, sistem memilih sampel 10 ribu data yang representatif.
Data dalam sampel tidak diperbarui secara otomatis. Contoh tabel disimpan sebagai hasil kueri yang di-cache dan akan berakhir dalam waktu sekitar 24 jam. Untuk memuat ulang tabel sampel secara manual, lihat Memuat ulang sampel penyiapan data.
Mode tulis
Untuk mengoptimalkan biaya dan waktu pemrosesan, Anda dapat mengubah setelan mode penulisan untuk memproses data baru secara inkremental dari sumber. Misalnya, jika Anda memiliki tabel di BigQuery tempat data dimasukkan setiap hari, dan dasbor Looker yang harus mencerminkan perubahan data, Anda dapat menjadwalkan penyiapan data BigQuery untuk membaca data baru secara inkremental dari tabel sumber dan menyebarkannya ke tabel tujuan.
Untuk mengonfigurasi cara penulisan persiapan data ke dalam tabel tujuan, lihat Mengoptimalkan persiapan data dengan memproses data secara inkremental.
Mode penulisan berikut didukung:
| Opsi mode tulis | Deskripsi |
|---|---|
| Pemuatan ulang penuh | Melakukan langkah-langkah penyiapan data pada semua data sumber, lalu membangun ulang tabel tujuan secara penuh. Tabel dibuat ulang, bukan dipangkas. Pemuatan ulang penuh adalah mode default saat menulis ke tabel tujuan. |
| Tambahkan | Menyisipkan semua data dari penyiapan data sebagai baris tambahan dalam tabel tujuan. |
| Inkremental | Hanya menyisipkan data baru atau, bergantung pada pilihan kolom inkremental Anda, data yang diubah dalam tabel tujuan. Berdasarkan pilihan kolom inkremental Anda, penyiapan data akan memilih mekanisme deteksi rekaman perubahan yang optimal. Memilih Nilai maksimum untuk jenis data numerik dan datetime serta Unik untuk data kategoris. Penyisipan maksimum hanya mencatat data jika nilai kolom yang ditentukan lebih besar daripada nilai maksimum untuk kolom yang sama dalam tabel tujuan. Penyisipan unik hanya mencatat jika nilai kolom yang ditentukan tidak ada dalam nilai yang ada untuk kolom yang sama di tabel tujuan. |
| Upsert | Menggabungkan baris menggunakan kunci penggabungan yang ditentukan. Jika baris yang ada di tabel tujuan cocok dengan kunci penggabungan yang ditentukan untuk input data, nilai dalam baris ini akan diperbarui di tabel tujuan. Jika tidak, baris baru akan dimasukkan ke dalam tabel tujuan. |
Langkah-langkah persiapan data yang didukung
BigQuery mendukung jenis langkah persiapan data berikut:
| Jenis langkah | Deskripsi |
|---|---|
| Sumber | Menambahkan sumber saat Anda memilih tabel BigQuery untuk dibaca atau saat Anda menambahkan langkah gabungan. |
| Transformasi | Membersihkan dan mentransformasi data menggunakan ekspresi SQL. Anda menerima
kartu saran untuk ekspresi berikut:
Anda juga dapat menggunakan ekspresi SQL BigQuery yang valid dalam langkah transformasi manual. Contoh:
Untuk mengetahui informasi selengkapnya, lihat Menambahkan transformasi. |
| Filter | Menghapus baris melalui sintaksis klausa WHERE. Saat Anda
menambahkan langkah filter, Anda dapat memilih untuk menjadikannya langkah validasi.
Untuk mengetahui informasi selengkapnya, lihat Memfilter baris. |
| Deduplicate | Menghapus baris duplikat dari data berdasarkan kunci dan
pengurutan yang dipilih.
Untuk mengetahui informasi selengkapnya, lihat Menghapus duplikat data. |
| Validasi | Mengirim baris yang tidak memenuhi kriteria aturan validasi ke tabel error. Jika data gagal dalam aturan validasi dan tidak ada tabel error yang dikonfigurasi, penyiapan data akan gagal selama eksekusi.
Untuk mengetahui informasi selengkapnya, lihat Mengonfigurasi tabel error dan menambahkan aturan validasi. |
| Gabung | Menggabungkan nilai dari dua sumber. Tabel harus berada di lokasi yang sama.
Kolom kunci gabungan harus memiliki jenis data yang sama. Persiapan data
mendukung operasi gabungan berikut:
Untuk mengetahui informasi selengkapnya, lihat Menambahkan operasi gabungan. |
| Tujuan | Menentukan tujuan untuk menampilkan langkah-langkah penyiapan data. Jika Anda
memasukkan tabel tujuan yang tidak ada, penyiapan data
akan membuat tabel baru menggunakan informasi skema saat ini. Untuk mengetahui informasi selengkapnya, lihat Menambahkan atau mengubah tabel tujuan. |
| Menghapus kolom | Menghapus kolom dari skema. Anda melakukan
langkah ini dari tampilan skema.
Untuk mengetahui informasi selengkapnya, lihat Menghapus kolom. |
Menjadwalkan operasi persiapan data
Untuk menjalankan langkah-langkah penyiapan data dan memuat data yang telah disiapkan ke dalam tabel tujuan, buat jadwal. Anda dapat menjadwalkan penyiapan data dari editor penyiapan data, dan mengelolanya dari halaman Penjadwalan BigQuery. Untuk mengetahui informasi selengkapnya, lihat Menjadwalkan penyiapan data.
Membangun pipeline dengan tugas persiapan data
Anda dapat membuat pipeline BigQuery yang terdiri dari tugas persiapan data, kueri SQL, dan notebook. Kemudian, Anda dapat menjalankan pipeline ini sesuai jadwal. Untuk mengetahui informasi selengkapnya, lihat Pengantar pipeline BigQuery.
Mengontrol akses
Mengontrol akses ke penyiapan data menggunakan peran Identity and Access Management (IAM), enkripsi dengan kunci Cloud KMS BigQuery dan Dataform, serta Kontrol Layanan VPC.
Peran dan izin IAM
Pengguna yang menyiapkan data dan akun layanan Dataform yang menjalankan tugas memerlukan izin IAM. Untuk mengetahui informasi selengkapnya, lihat Peran yang diperlukan dan Menyiapkan Gemini untuk BigQuery.
Enkripsi dengan kunci Cloud KMS
Enkripsi data di tingkat set data atau project menggunakan kunci Cloud KMS yang dikelola pelanggan default di BigQuery. Untuk mengetahui informasi selengkapnya, lihat Menetapkan kunci default set data dan Menetapkan kunci default project.
Anda dapat mengenkripsi kode pipeline di tingkat project secara default menggunakan kunci Cloud KMS Dataform.
Perimeter Kontrol Layanan VPC
Jika Anda menggunakan Kontrol Layanan VPC, Anda harus mengonfigurasi perimeter untuk melindungi Dataform dan BigQuery. Untuk mengetahui informasi selengkapnya, lihat batasan Kontrol Layanan VPC untuk BigQuery dan Dataform.
Peran yang diberikan saat membuat persiapan data
Saat Anda membuat persiapan data, BigQuery akan memberi Anda peran Dataform Admin (roles/dataform.admin) pada persiapan data tersebut. Semua pengguna dengan peran Dataform Admin yang diberikan di project Cloud de Confiance memiliki akses pemilik ke semua persiapan data yang dibuat di project. Untuk mengganti perilaku ini, lihat Memberikan peran tertentu saat pembuatan resource.
Batasan
Persiapan data tersedia dengan batasan berikut:
- Semua set data sumber dan tujuan penyiapan data BigQuery untuk penyiapan data tertentu harus berada di lokasi yang sama. Untuk mengetahui informasi selengkapnya, lihat Lokasi.
- Selama pengeditan pipeline, data dan interaksi dikirim ke pusat data Gemini untuk diproses. Untuk mengetahui informasi selengkapnya, lihat Lokasi.
- Gemini in BigQuery tidak didukung oleh Assured Workloads.
- Persiapan data BigQuery tidak mendukung penayangan, perbandingan, atau pemulihan versi persiapan data.
- Respons dari Gemini didasarkan pada sampel set data yang Anda berikan saat mengembangkan pipeline penyiapan data. Untuk mengetahui informasi selengkapnya, lihat cara Gemini untuk Cloud de Confiance menggunakan data Anda dan persyaratan dalam Program Penguji Tepercaya Gemini untuk Cloud de Confiance .
- Persiapan data BigQuery tidak memiliki API sendiri. Untuk API yang diperlukan, lihat Menyiapkan Gemini di BigQuery.
Lokasi
Tugas pemrosesan data Anda dijalankan dan disimpan di lokasi set data sumber. Jika lokasi repositori ditentukan, maka lokasi tersebut harus sama dengan lokasi set data sumber.
Region penyimpanan kode penyiapan data dapat berbeda dengan region eksekusi tugas.
Semua aset kode baru di project Cloud de Confiance Anda menggunakan region default. Setelah aset dibuat, Anda tidak dapat mengubah regionnya.
Untuk menetapkan region default untuk aset kode baru, lakukan hal berikut:
Buka halaman BigQuery.
Di panel kiri, klik File untuk membuka browser file:

Di samping nama project, klik View files panel actions > Switch code region.
Pilih region kode yang ingin Anda gunakan sebagai default.
Klik Simpan.
Untuk mengetahui daftar wilayah yang didukung, lihat Lokasi BigQuery Studio.
Pemrosesan data BigQuery selama waktu pengembangan dan eksekusi selalu dilakukan di lokasi set data sumber Anda. Untuk mempelajari tempat Gemini in BigQuery memproses data Anda, lihat Tempat Gemini in BigQuery memproses data Anda.
Harga
Menjalankan persiapan data dan membuat sampel pratinjau data menggunakan resource BigQuery, yang ditagih dengan tarif yang ditampilkan di harga BigQuery.
Persiapan data disertakan dalam harga Gemini in BigQuery. Anda dapat menggunakan persiapan data BigQuery selama Pratinjau tanpa biaya tambahan. Untuk mengetahui informasi selengkapnya, lihat artikel Menyiapkan Gemini di BigQuery.
Langkah berikutnya
- Pelajari cara menyiapkan data dengan Gemini di BigQuery.
- Pelajari cara menjalankan persiapan data secara manual atau dengan jadwal.