
Introdução à preparação de dados do BigQuery
Este documento descreve a preparação de dados melhorada pela IA no BigQuery. As preparações de dados são recursos do BigQuery que usam o Gemini no BigQuery para analisar os seus dados e fornecer sugestões inteligentes para os limpar, transformar e enriquecer. Pode reduzir significativamente o tempo e o esforço necessários para as tarefas de preparação de dados manuais. O agendamento das preparações de dados é feito pelo Dataform.
Vantagens
- Pode reduzir o tempo gasto no desenvolvimento do pipeline de dados com sugestões de transformação geradas pelo Gemini e sensíveis ao contexto.
- Pode validar os resultados gerados numa pré-visualização e receber sugestões de limpeza e enriquecimento da qualidade de dados com o mapeamento de esquemas automático.
- O Dataform permite-lhe usar um processo de integração contínua e desenvolvimento contínuo (CI/CD), suportando a colaboração entre equipas para revisões de código e controlo de origem.
Pontos de entrada de preparação de dados
Pode criar e gerir preparações de dados na página do BigQuery Studio (consulte o artigo Abra o editor de preparação de dados no BigQuery).
Quando abre uma tabela na preparação de dados do BigQuery, é executada uma tarefa do BigQuery com as suas credenciais. A execução cria linhas de exemplo a partir da tabela escolhida e escreve os resultados numa tabela temporária no mesmo projeto. O Gemini usa os dados de exemplo e o esquema para gerar sugestões de preparação de dados apresentadas no editor de preparação de dados.
Vistas no editor de preparação de dados
As preparações de dados aparecem como separadores na página do BigQuery. Cada separador tem uma série de subseparadores ou vistas de preparação de dados, onde concebe e gere as preparações de dados.
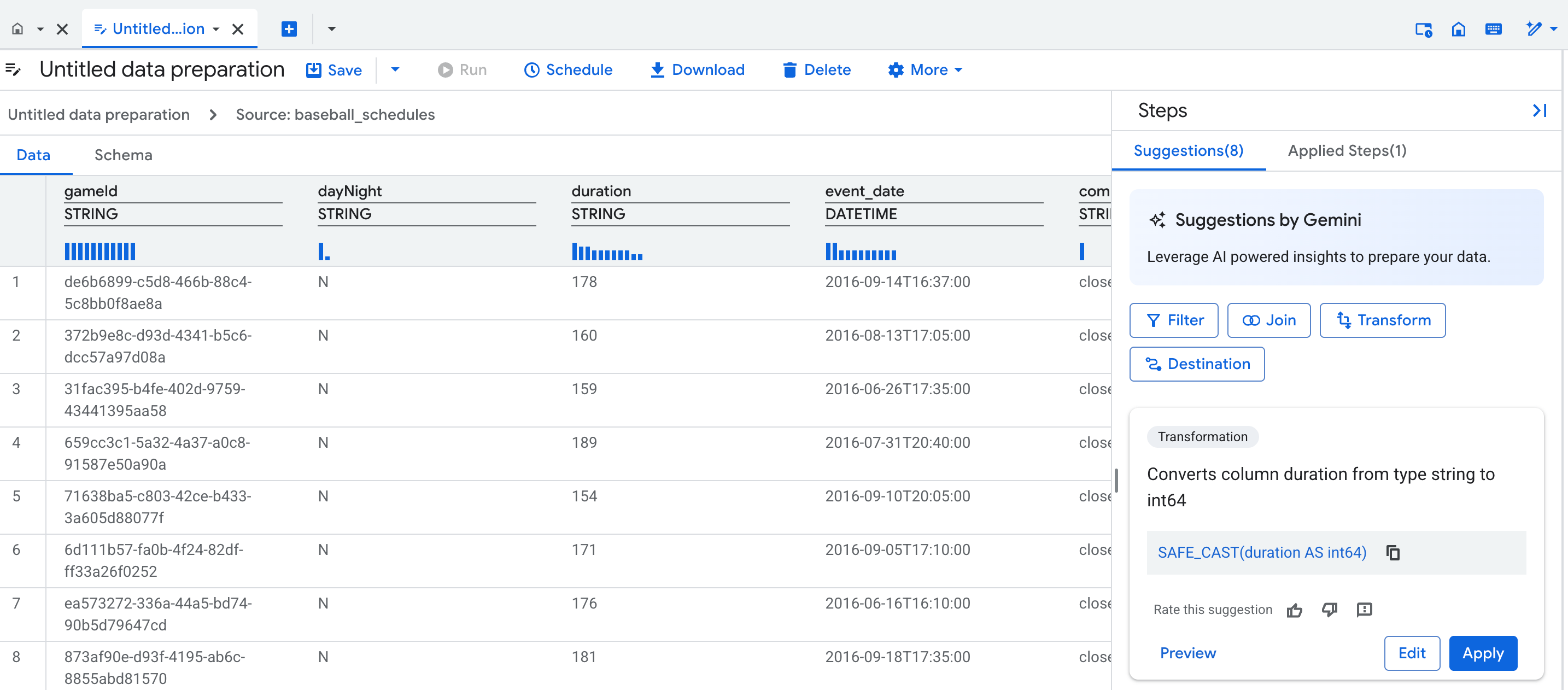
Vista de dados
Quando cria uma nova preparação de dados, é aberto um separador do editor de preparação de dados, que apresenta a vista de dados, que contém uma amostra representativa da tabela. Para preparações de dados existentes, pode navegar para a vista de dados clicando num nó na vista de gráfico do pipeline de preparação de dados.
A vista de dados permite-lhe fazer o seguinte:
- Interaja com os seus dados para formar passos de preparação de dados.
- Aplicar sugestões do Gemini.
- Melhore a qualidade das sugestões do Gemini introduzindo valores de exemplo nas células.
Sobre cada coluna na tabela, um perfil estatístico (um histograma) mostra a quantidade dos principais valores de cada coluna nas linhas de pré-visualização.
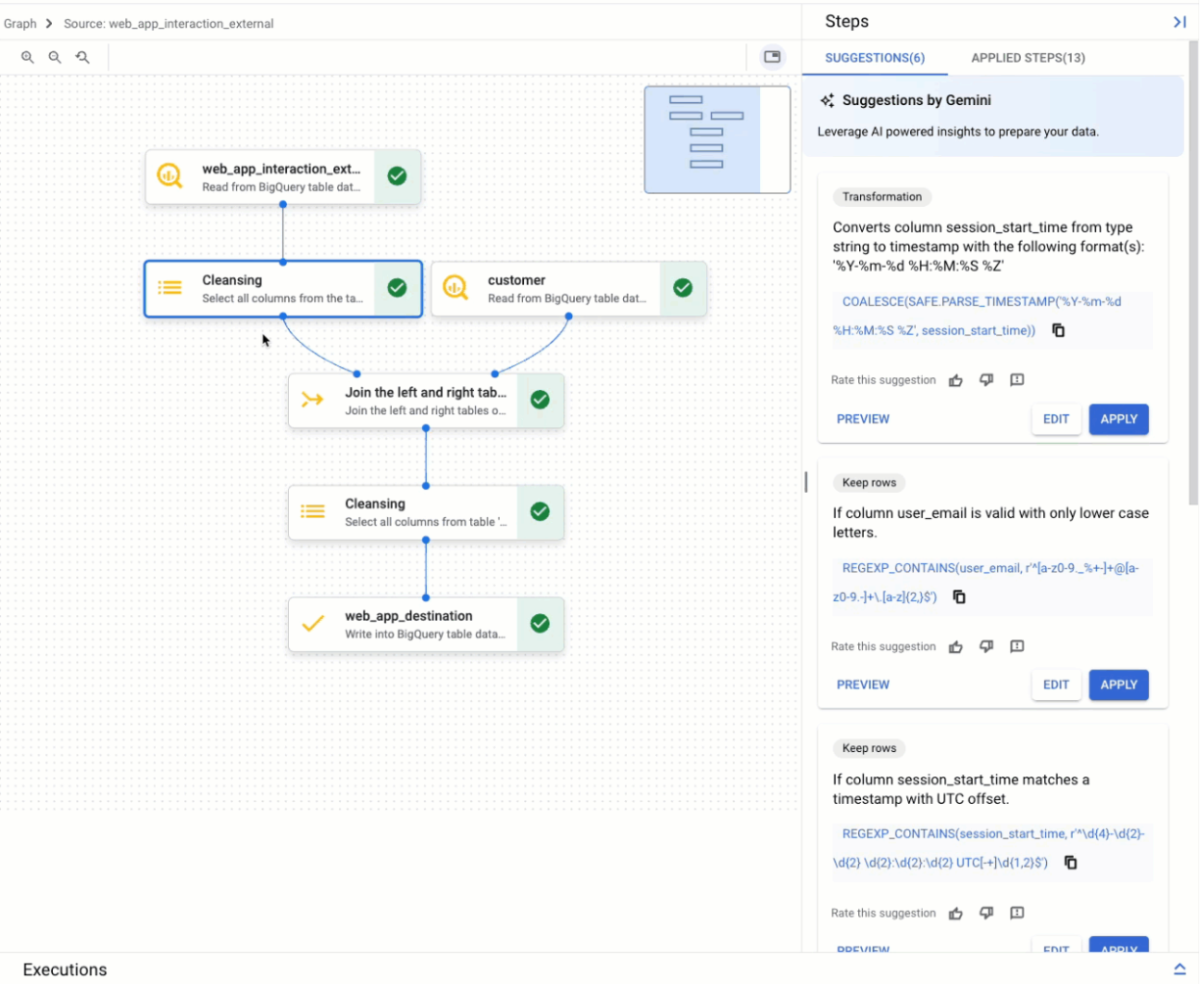
Vista de gráfico
A vista de gráfico é uma vista geral visual da preparação de dados. Aparece como um separador na página BigQuery na consola quando abre uma preparação de dados. O gráfico apresenta nós para todos os passos no pipeline de preparação de dados. Pode selecionar um nó no gráfico para configurar os passos de preparação de dados que representa.
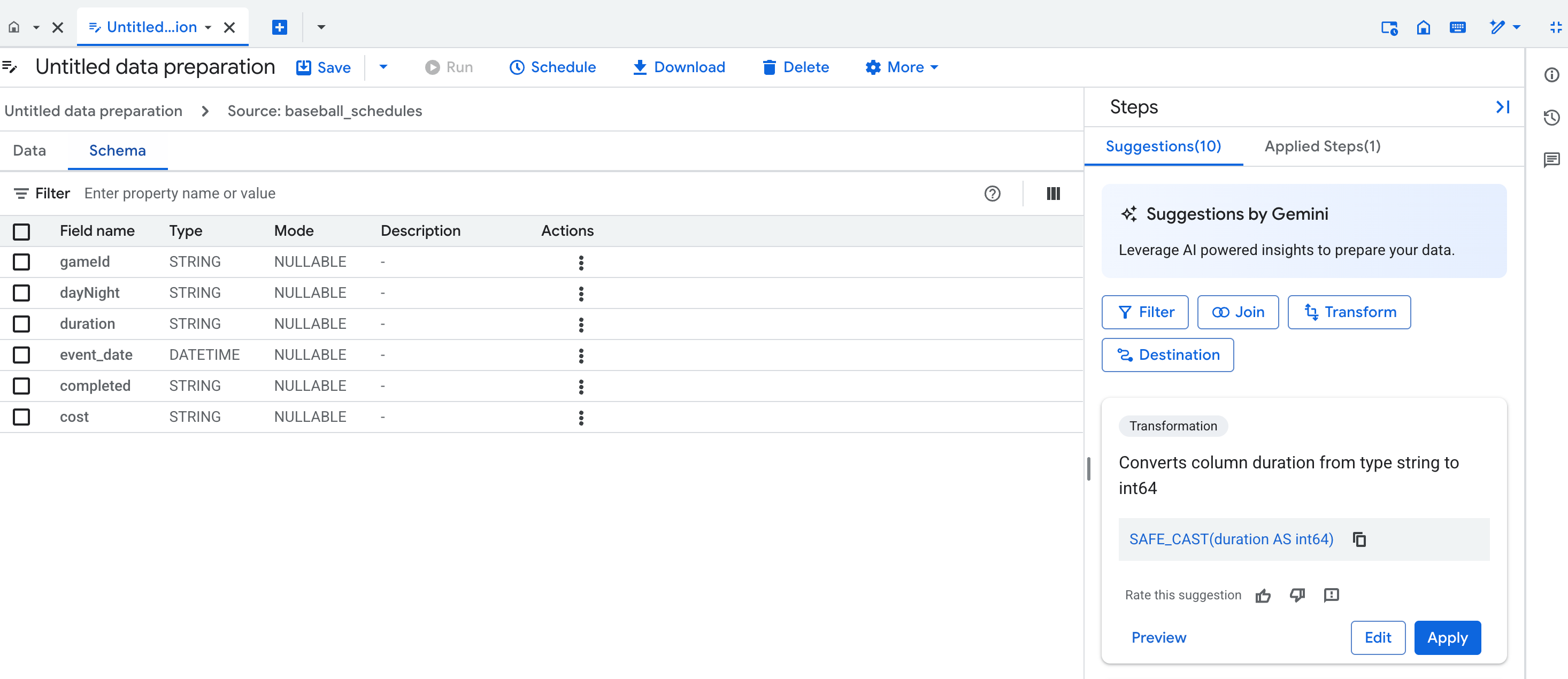
Vista de esquema
A vista do esquema de preparação de dados apresenta o esquema atual do passo de preparação de dados ativo. O esquema apresentado corresponde às colunas na vista de dados.
Na vista de esquema, pode realizar operações de esquema dedicadas, como remover colunas, o que também cria passos na lista Passos aplicados.
Sugestões do Gemini
O Gemini fornece sugestões sensíveis ao contexto para ajudar com as seguintes tarefas de preparação de dados:
- Aplicar transformações e regras de qualidade de dados
- Padronizar e enriquecer dados
- Automatizar o mapeamento de esquemas
Cada sugestão aparece num cartão na lista de sugestões do editor de preparação de dados. O cartão contém as seguintes informações:
- A categoria de nível superior do passo, como Manter linhas ou Transformação
- Uma descrição do passo, como Manter linhas se
COLUMN_NAMEnão forNULL - A expressão SQL correspondente usada para executar o passo
Pode pré-visualizar, editar ou aplicar o cartão de sugestão, ou ajustar a sugestão. Também pode adicionar passos manualmente. Para mais informações, consulte o artigo Prepare dados com o Gemini.
Para otimizar as sugestões do Gemini, dê-lhe um exemplo do que alterar numa coluna.
Amostragem de dados
O BigQuery usa a amostragem de dados para fornecer uma pré-visualização da preparação dos dados. Pode ver o exemplo na vista de dados de cada nó.
Quando adiciona tabelas padrão do BigQuery como origem, os dados são preparados através de uma função TABLESAMPLE do BigQuery. Esta função cria uma amostra de 10 000 registos.
Quando adiciona uma vista ou uma tabela externa como origem, o sistema lê os primeiros 1 milhão de registos. A partir destes registos, o sistema seleciona uma amostra representativa de 10 000 registos.
Os dados na amostra não são atualizados automaticamente. As tabelas de exemplo são armazenadas como resultados de consultas em cache e expiram em aproximadamente 24 horas. Para atualizar manualmente a tabela de exemplo, consulte o artigo Atualize exemplos de preparação de dados.
Modo de escrita
Para otimizar os custos e o tempo de processamento, pode alterar as definições do modo de gravação para processar incrementalmente novos dados da origem. Por exemplo, se tiver uma tabela no BigQuery onde os registos são inseridos diariamente e um painel de controlo do Looker que tem de refletir os dados alterados, pode agendar a preparação de dados do BigQuery para ler incrementalmente os novos registos da tabela de origem e propagá-los para a tabela de destino.
Para configurar a forma como a preparação de dados é escrita numa tabela de destino, consulte o artigo Otimize a preparação de dados processando os dados de forma incremental.
São suportados os seguintes modos de escrita:
| Opção de modo de escrita | Descrição |
|---|---|
| Atualização completa | Executa os passos de preparação de dados em todos os dados de origem e, em seguida, recria a tabela de destino na íntegra. A tabela é recriada e não truncada. A atualização completa é o modo predefinido quando escreve numa tabela de destino. |
| Anexar | Insere todos os dados da preparação de dados como linhas adicionais na tabela de destino. |
| Incremental | Insere apenas os dados novos ou, consoante a sua escolha de coluna incremental, alterados na tabela de destino. Com base na sua escolha de coluna incremental, a preparação de dados seleciona o mecanismo de deteção de registo de alterações ideal. Seleciona os valores máximos para os tipos de dados numéricos e de data/hora e os valores únicos para os dados categóricos. Maximum insere apenas registos em que o valor da coluna especificada é superior ao valor máximo desta mesma coluna na tabela de destino. As inserções únicas registam apenas os casos em que os valores das colunas especificadas não estão presentes nos valores existentes da mesma coluna na tabela de destino. |
| Upsert | Mescla linhas usando as chaves de mesclagem especificadas. Quando uma linha existente na tabela de destino corresponde às chaves de união especificadas para um registo de entrada, os valores nesta linha são atualizados na tabela de destino. Caso contrário, é inserida uma nova linha na tabela de destino. |
Passos de preparação de dados suportados
O BigQuery suporta os seguintes tipos de passos de preparação de dados:
| Tipo de passo | Descrição |
|---|---|
| Origem | Adiciona uma origem quando seleciona uma tabela do BigQuery para ler ou quando adiciona um passo de junção. |
| Transformação | Limpa e transforma dados através de uma expressão SQL. Recebe cartões de sugestões para as seguintes expressões:
Também pode usar quaisquer expressões SQL do BigQuery válidas nos passos de transformação manual. Por exemplo:
Para mais informações, consulte o artigo Adicione uma transformação. |
| Filtro | Remove linhas através da sintaxe da cláusula WHERE. Quando
adiciona um passo de filtro, pode optar por transformá-lo num passo de validação.
Para mais informações, consulte o artigo Filtrar linhas. |
| Remova duplicados | Remove linhas duplicadas dos dados com base nas chaves e na ordenação selecionadas.
Para mais informações, consulte o artigo Remova dados duplicados. |
| Validação | Envia linhas que não cumprem os critérios da regra de validação para uma tabela de erros. Se os dados não cumprirem a regra de validação e não estiver configurada nenhuma tabela de erros, a preparação de dados falha durante a execução.
Para mais informações, consulte o artigo Configure a tabela de erros e adicione uma regra de validação. |
| Adira | Junta valores de duas origens. As tabelas têm de estar na mesma localização.
As colunas de chaves de junção têm de ser do mesmo tipo de dados. As preparações de dados
suportam as seguintes operações de junção:
Para mais informações, consulte o artigo Adicione uma operação de junção. |
| Destino | Define um destino para a saída dos passos de preparação de dados. Se
introduzir uma tabela de destino que não existe, a preparação de dados
cria uma nova tabela com as informações do esquema atual. Para mais informações, consulte o artigo Adicione ou altere uma tabela de destino. |
| Elimine colunas | Elimina colunas do esquema. Realiza este passo na vista de esquema.
Para mais informações, consulte o artigo Elimine uma coluna. |
Agendar execuções de preparação de dados
Para executar os passos de preparação de dados e carregar os dados preparados para a tabela de destino, crie uma agenda. Pode agendar preparações de dados a partir do editor de preparação de dados e geri-las a partir da página Agendamento do BigQuery. Para mais informações, consulte o artigo Agende preparações de dados.
Criar pipelines com tarefas de preparação de dados
Pode criar pipelines do BigQuery compostos por tarefas de preparação de dados, consultas SQL e blocos de notas. Em seguida, pode executar estes pipelines de acordo com um agendamento. Para mais informações, consulte o artigo Introdução aos pipelines do BigQuery.
Controlar o acesso
Controle o acesso às preparações de dados através das funções de gestão de identidade e de acesso (IAM), da encriptação com chaves do Cloud KMS do BigQuery e do Dataform e dos VPC Service Controls.
Funções e autorizações do IAM
Os utilizadores que estão a preparar os dados e as contas de serviço do Dataform que estão a executar as tarefas requerem autorizações do IAM. Para mais informações, consulte os Funções necessárias e Configure o Gemini para o BigQuery.
Encriptação com chaves do Cloud KMS
Encriptar dados ao nível do conjunto de dados ou do projeto através das chaves do Cloud KMS geridas pelo cliente predefinidas no BigQuery. Para mais informações, consulte os artigos Defina uma chave predefinida do conjunto de dados e Defina uma chave predefinida do projeto.
Pode encriptar o código do pipeline ao nível do projeto por predefinição usando uma chave do Dataform Cloud KMS.
Perímetros dos VPC Service Controls
Se usar os VPC Service Controls, tem de configurar o perímetro para proteger o Dataform e o BigQuery. Para mais informações, consulte as limitações dos VPC Service Controls para o BigQuery e o Dataform.
Função concedida ao criar uma preparação de dados
Quando cria uma preparação de dados, o BigQuery concede-lhe a
função de administrador do Dataform
(roles/dataform.admin) nessa preparação de dados. Todos os utilizadores com a função de administrador do Dataform concedida no projeto têm acesso de proprietário a todas as preparações de dados criadas no projeto. Cloud de Confiance Para substituir este comportamento, consulte o artigo
Conceda uma função específica na criação de recursos.
Limitações
A preparação de dados está disponível com as seguintes limitações:
- Todos os conjuntos de dados de origem e de destino de preparação de dados do BigQuery de uma determinada preparação de dados têm de estar na mesma localização. Para mais informações, consulte o artigo Localizações.
- Durante a edição de pipelines, os dados e as interações são enviados para um centro de dados do Gemini para processamento. Para mais informações, consulte o artigo Localizações.
- O Gemini no BigQuery não é suportado por Assured Workloads.
- As preparações de dados do BigQuery não suportam a visualização, a comparação nem o restauro de versões de preparação de dados.
- As respostas do Gemini baseiam-se numa amostra do conjunto de dados que fornece quando cria o pipeline de preparação de dados. Para mais informações, consulte como o Gemini para Cloud de Confiance usa os seus dados e os termos no Programa de Testadores Fidedignos do Cloud de Confiance Gemini para.
- A preparação de dados do BigQuery não tem a sua própria API. Para ver as APIs necessárias, consulte o artigo Configure o Gemini no BigQuery.
Localizações
Pode usar a preparação de dados em qualquer localização do BigQuery compatível. As tarefas de tratamento de dados são executadas e armazenadas na localização dos conjuntos de dados de origem. Se for especificada uma localização do repositório, tem de ser igual à localização dos conjuntos de dados de origem. A região de armazenamento do código de preparação de dados pode ser diferente da região de execução da tarefa.
Todos os recursos de código no BigQuery Studio usam a mesma região predefinida. Para definir a região predefinida para recursos de código, siga estes passos:
Aceda à página do BigQuery.
No painel Explorador, encontre o projeto no qual ativou os recursos de código.
Clique em Ver ações junto ao projeto e, de seguida, clique em Alterar a minha região de código predefinida.
Para Região, selecione a região que quer usar para recursos de códigos.
Clique em Selecionar.
Para ver uma lista das regiões suportadas, consulte o artigo Localizações do BigQuery Studio.
O Gemini no BigQuery opera a nível global, pelo que não pode restringir o processamento de dados do Gemini a uma região específica quando cria as suas preparações de dados, embora o processamento de dados do BigQuery no momento da criação e execução seja sempre realizado na localização dos seus conjuntos de dados de origem. Para saber mais sobre as localizações onde o Gemini no BigQuery processa dados, consulte o artigo Localizações de fornecimento do Gemini.
Preços
A execução de preparações de dados e a criação de exemplos de pré-visualização de dados usam recursos do BigQuery, que são cobrados às taxas apresentadas nos preços do BigQuery.
A preparação de dados está incluída nos preços do Gemini no BigQuery. Pode usar a preparação de dados do BigQuery durante a pré-visualização sem custos adicionais. Para mais informações, consulte o artigo Configure o Gemini no BigQuery.
Quotas
Para mais informações, consulte as cotas do Gemini no BigQuery.