
Usa BigQuery DataFrames en dbt
dbt (data build tool) es un framework de línea de comandos de código abierto diseñado para la transformación de datos en almacenes de datos modernos. dbt facilita las transformaciones de datos modulares a través de la creación de modelos reutilizables basados en SQL y Python. La herramienta coordina la ejecución de estas transformaciones dentro del almacén de datos de destino y se enfoca en el paso de transformación de la canalización de ELT. Para obtener más información, consulta la documentación de dbt.
En dbt, un modelo de Python es una transformación de datos que se define y ejecuta con código de Python dentro de tu proyecto de dbt. En lugar de escribir código SQL para la lógica de transformación, escribes secuencias de comandos de Python que dbt luego coordina para que se ejecuten dentro del entorno del almacén de datos. Un modelo de Python te permite realizar transformaciones de datos que podrían ser complejas o ineficientes de expresar en SQL. Esto aprovecha las capacidades de Python y, al mismo tiempo, se beneficia de las funciones de estructura del proyecto, organización, administración de dependencias, pruebas y documentación de dbt. Para obtener más información, consulta Modelos de Python.
El adaptador dbt-bigquery admite la ejecución de código de Python definido en BigQuery DataFrames. Esta función está disponible en dbt Cloud y dbt Core.
También puedes obtener esta función clonando la versión más reciente del adaptador de dbt-bigquery.
Antes de comenzar
Para usar el adaptador de dbt-bigquery, habilita las siguientes APIs en tu proyecto:
- API de BigQuery (
bigquery.googleapis.com) - API de Cloud Storage (
storage.googleapis.com) - API de Compute Engine (
compute.googleapis.com) - API de Dataform (
dataform.googleapis.com) - API de Identity and Access Management (
iam.googleapis.com) - API de Vertex AI (
aiplatform.googleapis.com)
Roles necesarios para habilitar las APIs
Para habilitar las APIs, necesitas el rol de IAM de administrador de Service Usage (roles/serviceusage.serviceUsageAdmin), que contiene el permiso serviceusage.services.enable. Obtén más información para otorgar roles.
Roles obligatorios
El adaptador dbt-bigquery admite la autenticación basada en OAuth y en cuentas de servicio. En las siguientes secciones, se describen los roles necesarios según el método de autenticación que planees usar.
OAuth
Si planeas autenticarte en el adaptador de dbt-bigquery con OAuth, pídele a tu administrador que te otorgue los siguientes roles:
- Rol de usuario de BigQuery (
roles/bigquery.user) en el proyecto - Rol de editor de datos de BigQuery (
roles/bigquery.dataEditor) en el proyecto o el conjunto de datos en el que se guardan las tablas - Rol de usuario de Colab Enterprise (
roles/colabEnterprise.user) en el proyecto - Rol de administrador de almacenamiento (
roles/storage.admin) en el bucket de Cloud Storage de etapa de pruebas para el código y los registros de etapa de pruebas
Cuenta de servicio
Si planeas autenticarte en el adaptador de dbt-bigquery con una cuenta de servicio de tu proyecto, pídele a tu administrador que otorgue los siguientes roles a la cuenta de servicio que planeas usar:
- Rol de usuario de BigQuery
(
roles/bigquery.user) - Rol de editor de datos de BigQuery
(
roles/bigquery.dataEditor) - Rol de Usuario de Colab Enterprise (
roles/colabEnterprise.user) - Rol de administrador de almacenamiento
(
roles/storage.admin)
Si te autenticas con una cuenta de servicio, asegúrate también de tener el rol de usuario de cuenta de servicio (roles/iam.serviceAccountUser) otorgado para la cuenta de servicio que planeas usar.
Identidad temporal como cuenta de servicio
Si planeas autenticarte en el adaptador de dbt-bigquery con OAuth, pero quieres que el procesamiento de datos y la ejecución de notebooks se realicen con la identidad de una cuenta de servicio en el mismo proyecto en el que se ejecutan los trabajos, pídele a tu administrador que te otorgue los siguientes roles:
- Rol de creador de tokens de cuenta de servicio(
roles/iam.serviceAccountTokenCreator) - Usuario de cuenta de servicio
(
roles/iam.serviceAccountUser)
La cuenta de servicio suplantada también debe tener todos los roles necesarios para la autenticación.
Cuentas de servicio entre proyectos
Si planeas autenticarte en el adaptador de dbt-bigquery con una cuenta de servicio en un proyecto diferente (el proyecto de credenciales, desde el que se ejecutan los trabajos, el proyecto de ejecución), pídele a tu administrador que haga lo siguiente:
- Inhabilita la restricción
constraints/iam.disableCrossProjectServiceAccountUsageen el proyecto de credenciales. Además de todos los roles necesarios para la autenticación de la cuenta de servicio, otorga los siguientes roles a la cuenta de servicio en el proyecto de credenciales:
- Rol de agente de servicio de Vertex AI (roles/aiplatform.serviceAgent) para
service-PROJECT_NUMBER@gcp-sa-aiplatform.s3ns-system.iam.gserviceaccount.com - Rol de agente de servicio de Colab de Vertex AI (roles/aiplatform.colabServiceAgent) para
service-PROJECT_NUMBER@gcp-sa-vertex-nb.s3ns-system.iam.gserviceaccount.com - Rol de agente de servicio de Compute Engine (roles/compute.serviceAgent) a
service-PROJECT_NUMBER@compute-system.s3ns-system.iam.gserviceaccount.com
- Rol de agente de servicio de Vertex AI (roles/aiplatform.serviceAgent) para
Si planeas autenticarte en el adaptador de dbt-bigquery con OAuth, pero quieres que el procesamiento de datos y la ejecución de notebooks se realicen con la identidad de una cuenta de servicio en un proyecto diferente desde el que se ejecutan los trabajos, pídele a tu administrador que haga lo siguiente:
- Sigue los pasos descritos anteriormente para las cuentas de servicio entre proyectos de la cuenta de servicio en otro proyecto.
- Otorgarte a ti y a la cuenta de servicio los roles necesarios para la suplantación de identidad de la cuenta de servicio
VPC compartida
Si usas Colab Enterprise en un entorno de VPC compartida, pídele a tu administrador que otorgue los siguientes roles y permisos:
Permiso de
compute.subnetworks.use: Otorga este permiso a la cuenta de servicio que usa el entorno de ejecución de Colab Enterprise en el proyecto host o en subredes específicas. Este permiso se incluye en el rol de usuario de red de Compute (roles/compute.networkUser).Permiso de
compute.subnetworks.get: Otorga este permiso a la cuenta de servicio que usa el entorno de ejecución de Colab Enterprise en el proyecto host o en subredes específicas. Este permiso se incluye en el rol Compute Network Viewer (roles/compute.networkViewer).Rol de usuario de la red de Compute (
roles/compute.networkUser): Otorga este rol al agente de servicio de Gemini Enterprise Agent Platform,service-PROJECT_NUMBER@gcp-sa-aiplatform.s3ns-system.iam.gserviceaccount.com, en el proyecto host de la VPC compartida.Rol de usuario de la red de Compute (
roles/compute.networkUser): Si se usa la función de trabajo de ejecución de notebook, otorga este rol al agente de servicio de Colab Enterprise,service-PROJECT_NUMBER@gcp-sa-vertex-nb.s3ns-system.iam.gserviceaccount.com, en el proyecto host de la VPC compartida.
Para obtener más información sobre cómo otorgar roles, consulta Administra el acceso a proyectos, carpetas y organizaciones.
También puedes obtener los permisos necesarios a través de roles personalizados o cualquier otro rol predefinido.
Entorno de ejecución de Python
El adaptador de dbt-bigquery utiliza el servicio de ejecución de notebooks de Colab Enterprise para ejecutar el código de Python de BigQuery DataFrames. El adaptador de dbt-bigquery crea y ejecuta automáticamente un notebook de Colab Enterprise para cada modelo de Python. Puedes elegir el proyectoCloud de Confiance en el que se ejecutará el notebook. El notebook ejecuta el código de Python del modelo, que la biblioteca de BigQuery DataFrames convierte en SQL de BigQuery. Luego, el SQL de BigQuery se ejecuta en el proyecto configurado. En el siguiente diagrama, se presenta el flujo de control:
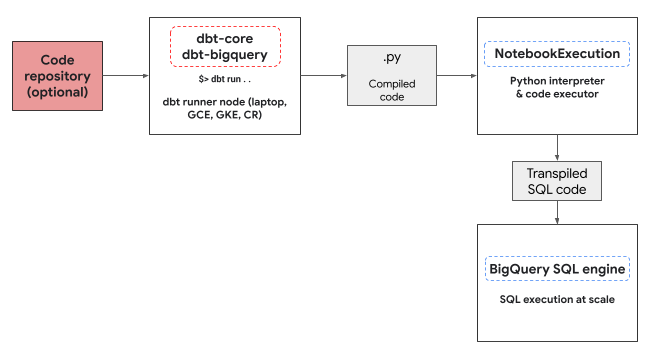
Si aún no hay una plantilla de notebook disponible en el proyecto y el usuario que ejecuta el código tiene los permisos para crear la plantilla, el adaptador dbt-bigquery crea y usa automáticamente la plantilla de notebook predeterminada. También puedes especificar una plantilla de notebook diferente con una configuración de dbt.
La ejecución del notebook requiere un bucket de Cloud Storage de etapa de pruebas para almacenar el código y los registros. Sin embargo, el adaptador de dbt-bigquery copia los registros en los registros de dbt, por lo que no tienes que buscar en el bucket.
Funciones admitidas
El adaptador de dbt-bigquery admite las siguientes capacidades para los modelos de dbt Python que ejecutan BigQuery DataFrames:
- Cargar datos desde una tabla de BigQuery existente con la macro
dbt.source() - Cargar datos de otros modelos de dbt con la macro
dbt.ref()para crear dependencias y grafos acíclicos dirigidos (DAG) con modelos de Python - Especificar y usar paquetes de Python de PyPi que se pueden usar con la ejecución de código de Python Para obtener más información, consulta Configuraciones.
- Especificar una plantilla de tiempo de ejecución de notebook personalizada para tus modelos de BigQuery DataFrames
El adaptador de dbt-bigquery admite las siguientes estrategias de materialización:
- Materialización de la tabla, en la que los datos se vuelven a generar como una tabla en cada ejecución.
- Materialización incremental con una estrategia de combinación, en la que los datos nuevos o actualizados se agregan a una tabla existente, a menudo con una estrategia de combinación para controlar los cambios.
Configura dbt para usar BigQuery DataFrames
Si usas dbt Core, debes usar un archivo profiles.yml para usarlo con BigQuery DataFrames.
En el siguiente ejemplo, se usa el método oauth:
your_project_name:
outputs:
dev:
compute_region: us-central1
dataset: your_bq_dateset
gcs_bucket: your_gcs_bucket
job_execution_timeout_seconds: 300
job_retries: 1
location: US
method: oauth
priority: interactive
project: your_gcp_project
threads: 1
type: bigquery
target: dev
Si usas dbt Cloud, puedes conectarte a tu plataforma de datos directamente en la interfaz de dbt Cloud. En este caso, no necesitas un archivo profiles.yml. Para obtener más información, consulta Acerca de profiles.yml.
Este es un ejemplo de una configuración a nivel del proyecto para el archivo dbt_project.yml:
# Name your project! Project names should contain only lowercase characters
# and underscores. A good package name should reflect your organization's
# name or the intended use of these models.
name: 'your_project_name'
version: '1.0.0'
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the config(...) macro.
models:
your_project_name:
submission_method: bigframes
notebook_template_id: 7018811640745295872
packages: ["scikit-learn", "mlflow"]
timeout: 3000
# Config indicated by + and applies to all files under models/example/
example:
+materialized: view
Algunos parámetros también se pueden configurar con el método dbt.config en tu código de Python. Si estos parámetros de configuración entran en conflicto con tu archivo dbt_project.yml, tendrán prioridad los parámetros de configuración con dbt.config.
Para obtener más información, consulta Configuraciones del modelo y dbt_project.yml.
Parámetros de configuración
Puedes configurar los siguientes parámetros con el método dbt.config en tu modelo de Python. Estos parámetros de configuración anulan la configuración a nivel del proyecto.
| Configuración | Obligatorio | Uso |
|---|---|---|
submission_method |
Sí | submission_method=bigframes |
notebook_template_id |
No | Si no se especifica, se crea y se usa una plantilla predeterminada. |
packages |
No | Si es necesario, especifica la lista adicional de paquetes de Python. |
timeout |
No | Opcional: Extiende el tiempo de espera de ejecución del trabajo. |
Ejemplo de modelos de Python
En las siguientes secciones, se presentan ejemplos de situaciones y modelos de Python.
Carga datos desde una tabla de BigQuery
Para usar datos de una tabla de BigQuery existente como fuente en tu modelo de Python, primero debes definir esta fuente en un archivo YAML. El siguiente ejemplo se define en un archivo source.yml.
version: 2
sources:
- name: my_project_source # A custom name for this source group
database: bigframes-dev # Your Google Cloud project ID
schema: yyy_test_us # The BigQuery dataset containing the table
tables:
- name: dev_sql1 # The name of your BigQuery table
Luego, compila tu modelo de Python, que puede usar las fuentes de datos configuradas en este archivo YAML:
def model(dbt, session):
# Configure the model to use BigFrames for submission
dbt.config(submission_method="bigframes")
# Load data from the 'dev_sql1' table within 'my_project_source'
source_data = dbt.source('my_project_source', 'dev_sql1')
# Example transformation: Create a new column 'id_new'
source_data['id_new'] = source_data['id'] * 10
return source_data
Cómo hacer referencia a otro modelo
Puedes compilar modelos que dependan del resultado de otros modelos de dbt, como se muestra en el siguiente ejemplo. Esto es útil para crear canalizaciones de datos modulares.
def model(dbt, session):
# Configure the model to use BigFrames
dbt.config(submission_method="bigframes")
# Reference another dbt model named 'dev_sql1'.
# It assumes you have a model defined in 'dev_sql1.sql' or 'dev_sql1.py'.
df_from_sql = dbt.ref("dev_sql1")
# Example transformation on the data from the referenced model
df_from_sql['id'] = df_from_sql['id'] * 100
return df_from_sql
Cómo especificar una dependencia de paquete
Si tu modelo de Python requiere bibliotecas de terceros específicas, como MLflow o Boto3, puedes declarar el paquete en la configuración del modelo, como se muestra en el siguiente ejemplo. Estos paquetes se instalan en el entorno de ejecución.
def model(dbt, session):
# Configure the model for BigFrames and specify required packages
dbt.config(
submission_method="bigframes",
packages=["mlflow", "boto3"] # List the packages your model needs
)
# Import the specified packages for use in your model
import mlflow
import boto3
# Example: Create a DataFrame showing the versions of the imported packages
data = {
"mlflow_version": [mlflow.__version__],
"boto3_version": [boto3.__version__],
"note": ["This demonstrates accessing package versions after import."]
}
bdf = bpd.DataFrame(data)
return bdf
Cómo especificar una plantilla no predeterminada
Para tener más control sobre el entorno de ejecución o usar parámetros de configuración predefinidos, puedes especificar una plantilla de notebook no predeterminada para tu modelo de BigQuery DataFrames, como se muestra en el siguiente ejemplo.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# ID of your pre-created notebook template
notebook_template_id="857350349023451yyyy",
)
data = {"int": [1, 2, 3], "str": ['a', 'b', 'c']}
return bpd.DataFrame(data=data)
Materializa las tablas
Cuando dbt ejecuta tus modelos de Python, necesita saber cómo guardar los resultados en tu almacén de datos. Esto se denomina materialización.
En el caso de la materialización de tablas estándar, dbt crea o reemplaza por completo una tabla en tu almacén con el resultado de tu modelo cada vez que se ejecuta. Esto se hace de forma predeterminada o configurando explícitamente la propiedad materialized='table', como se muestra en el siguiente ejemplo.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# Instructs dbt to create/replace this model as a table
materialized='table',
)
data = {"int_column": [1, 2], "str_column": ['a', 'b']}
return bpd.DataFrame(data=data)
La materialización incremental con una estrategia de combinación permite que dbt actualice tu tabla solo con las filas nuevas o modificadas. Esto es útil para los conjuntos de datos grandes, ya que volver a compilar una tabla por completo cada vez puede ser ineficiente. La estrategia de combinación es una forma común de controlar estas actualizaciones.
Este enfoque integra los cambios de forma inteligente de la siguiente manera:
- Actualiza las filas existentes que cambiaron.
- Agregar filas nuevas
- Opcional, según la configuración: Borra las filas que ya no están presentes en la fuente.
Para usar la estrategia de combinación, debes especificar una propiedad unique_key que dbt pueda usar para identificar las filas coincidentes entre el resultado de tu modelo y la tabla existente, como se muestra en el siguiente ejemplo.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
materialized='incremental',
incremental_strategy='merge',
unique_key='int', # Specifies the column to identify unique rows
)
# In this example:
# - Row with 'int' value 1 remains unchanged.
# - Row with 'int' value 2 has been updated.
# - Row with 'int' value 4 is a new addition.
# The 'merge' strategy will ensure that only the updated row ('int 2')
# and the new row ('int 4') are processed and integrated into the table.
data = {"int": [1, 2, 4], "str": ['a', 'bbbb', 'd']}
return bpd.DataFrame(data=data)
Soluciona problemas
Puedes observar la ejecución de Python en los registros de dbt.
Además, puedes ver el código y los registros (incluidas las ejecuciones anteriores) en la página Ejecuciones de Colab Enterprise.
Ir a Ejecuciones de Colab Enterprise
Facturación
Cuando usas el adaptador dbt-bigquery con BigQuery DataFrames, se aplican Cloud de Confiance by S3NS cargos por lo siguiente:
Ejecución de notebooks: Se te cobra por la ejecución del entorno de ejecución del notebook. Para obtener más información, consulta Precios del tiempo de ejecución de Notebooks.
Ejecución de consultas de BigQuery: En el notebook, BigQuery DataFrames convierte Python en SQL y ejecuta el código en BigQuery. Se te cobrará según la configuración de tu proyecto y tu consulta, como se describe en los precios de BigQuery DataFrames.
Puedes usar la siguiente etiqueta de facturación en la consola de facturación de BigQuery para filtrar el informe de facturación de la ejecución del notebook y de las ejecuciones de BigQuery que activa el adaptador dbt-bigquery:
- Etiqueta de ejecución de BigQuery:
bigframes-dbt-api
¿Qué sigue?
- Para obtener más información sobre dbt y BigQuery DataFrames, consulta Cómo usar BigQuery DataFrames con modelos de dbt en Python.
- Para obtener más información sobre los modelos de Python de dbt, consulta Modelos de Python y Configuración de modelos de Python.
- Para obtener más información sobre los notebooks de Colab Enterprise, consulta Crea un notebook de Colab Enterprise con la Cloud de Confiance consola.
- Para obtener más información sobre los socios de Cloud de Confiance by S3NS , consulta Cloud de Confiance by S3NS Ready - BigQuery Partners.