
Use DataFrames do BigQuery no dbt
O dbt (data build tool) é uma framework de linha de comandos de código aberto criada para a transformação de dados em data warehouses modernos. O dbt facilita as transformações de dados modulares através da criação de modelos reutilizáveis baseados em SQL e Python. A ferramenta orquestra a execução destas transformações no data warehouse de destino, focando-se no passo de transformação do pipeline ELT. Para mais informações, consulte a documentação do dbt.
No dbt, um modelo Python é uma transformação de dados definida e executada com código Python no seu projeto dbt. Em vez de escrever SQL para a lógica de transformação, escreve scripts Python que o dbt orquestra para execução no ambiente do data warehouse. Um modelo Python permite-lhe fazer transformações de dados que podem ser complexas ou ineficientes de expressar em SQL. Isto tira partido das capacidades do Python, ao mesmo tempo que beneficia das funcionalidades de estrutura do projeto, orquestração, gestão de dependências, testes e documentação do dbt. Para mais informações, consulte o artigo Modelos Python.
O dbt-bigquery adaptador
suporta a execução de código Python definido em
DataFrames do BigQuery. Esta funcionalidade está disponível no
dbt Cloud e no
dbt Core.
Também pode obter esta funcionalidade clonando a versão mais recente do adaptador dbt-bigquery.
Antes de começar
Para usar o adaptador dbt-bigquery, ative as seguintes APIs no seu projeto:
- API BigQuery (
bigquery.googleapis.com) - API Cloud Storage (
storage.googleapis.com) - API Compute Engine (
compute.googleapis.com) - API Dataform (
dataform.googleapis.com) - API Identity and Access Management (
iam.googleapis.com) - API Vertex AI (
aiplatform.googleapis.com)
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
Funções necessárias
O adaptador dbt-bigquery suporta a autenticação baseada em OAuth e em contas de serviço.
Se planear autenticar-se no adaptador dbt-bigquery através do OAuth, peça ao seu administrador para lhe conceder as seguintes funções:
- Função de utilizador do BigQuery
(
roles/bigquery.user) no projeto - Função de editor de dados do BigQuery
(
roles/bigquery.dataEditor) no projeto ou no conjunto de dados onde as tabelas são guardadas - Função de utilizador do Colab Enterprise
(
roles/colabEnterprise.user) no projeto - Função de administrador de armazenamento
(
roles/storage.admin) no contentor do Cloud Storage de preparação para código e registos
Se planeia autenticar-se no adaptador dbt-bigquery através de uma conta de serviço, peça ao seu administrador para conceder as seguintes funções à conta de serviço que planeia usar:
- Função de utilizador do BigQuery
(
roles/bigquery.user) - Função de editor de dados do BigQuery
(
roles/bigquery.dataEditor) - Função de utilizador do Colab Enterprise
(
roles/colabEnterprise.user) - Função de administrador de armazenamento
(
roles/storage.admin)
Se estiver a fazer a autenticação através de uma conta de serviço, certifique-se também de que tem a
função Utilizador da conta de serviço
(roles/iam.serviceAccountUser) concedida para a conta de serviço que planeia usar.
Se estiver a usar o Colab Enterprise num ambiente de VPC partilhada, peça ao seu administrador para conceder as seguintes funções e autorizações:
Autorização
compute.subnetworks.use: conceda esta autorização à conta de serviço usada pelo tempo de execução do Colab Enterprise no projeto anfitrião ou em sub-redes específicas. Esta autorização está incluída na função de utilizador da rede de computação (roles/compute.networkUser).Autorização
compute.subnetworks.get: conceda esta autorização à conta de serviço usada pelo tempo de execução do Colab Enterprise no projeto anfitrião ou em sub-redes específicas. Esta autorização está incluída na função de visitante da rede de computação (roles/compute.networkViewer).Função de utilizador da rede de computação (
roles/compute.networkUser): conceda esta função ao agente do serviço Vertex AIservice-PROJECT_NUMBER@gcp-sa-aiplatform.s3ns-system.iam.gserviceaccount.com, no projeto anfitrião da VPC partilhada.Função de utilizador da rede de computação (
roles/compute.networkUser): se estiver a usar a funcionalidade de tarefa de execução do bloco de notas, conceda esta função ao agente do serviço Colab Enterprise,service-PROJECT_NUMBER@gcp-sa-vertex-nb.s3ns-system.iam.gserviceaccount.com, no projeto anfitrião de VPC partilhada.
Para mais informações sobre a atribuição de funções, consulte o artigo Faça a gestão do acesso a projetos, pastas e organizações.
Também pode conseguir as autorizações necessárias através de funções personalizadas ou outras funções predefinidas.
Ambiente de execução do Python
O adaptador dbt-bigquery usa o
serviço de execução de blocos de notas do Colab Enterprise
para executar o código Python dos DataFrames do BigQuery. É criado e executado automaticamente um bloco de notas do Colab Enterprise
pelo adaptador dbt-bigquery para cada modelo Python. Pode escolher o
Cloud de Confiance projeto no qual executar o bloco de notas. O bloco de notas executa o código Python do modelo, que é convertido em SQL do BigQuery pela biblioteca BigQuery DataFrames. O SQL do BigQuery é, em seguida, executado no projeto configurado. O diagrama seguinte apresenta o fluxo de controlo:
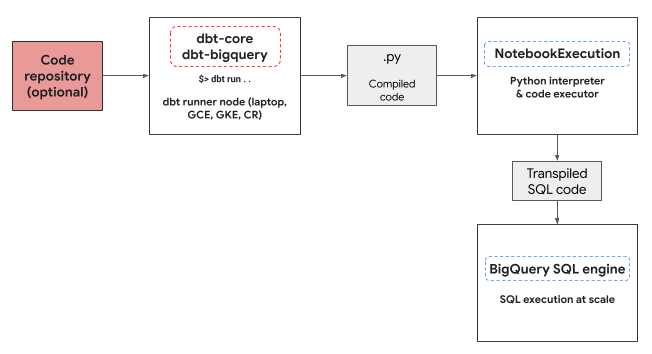
Se ainda não existir um modelo de bloco de notas no projeto e o utilizador que executa o código tiver as autorizações para criar o modelo, o adaptador cria e usa automaticamente o modelo de bloco de notas predefinido.dbt-bigquery Também pode especificar um modelo de bloco de notas diferente através de uma configuração do dbt.
A execução do bloco de notas requer um contentor do Cloud Storage de preparação para armazenar o código e os registos. No entanto, o adaptador dbt-bigquery copia os registos para os registos do dbt, pelo que não tem de procurar no contentor.
Funcionalidades suportadas
O adaptador dbt-bigquery suporta as seguintes capacidades para modelos dbt Python que executam DataFrames do BigQuery:
- Carregar dados de uma tabela do BigQuery existente com a macro
dbt.source(). - Carregar dados de outros modelos do dbt com a macro
dbt.ref()para criar dependências e gráficos acíclicos dirigidos (DAGs) com modelos Python. - Especificar e usar pacotes Python do PyPi que podem ser usados com a execução de código Python. Para mais informações, consulte o artigo Configurações.
- Especificar um modelo de tempo de execução do bloco de notas personalizado para os seus modelos de BigQuery DataFrames.
O adaptador dbt-bigquery suporta as seguintes estratégias de materialização:
- Materialização de tabelas, em que os dados são reconstruídos como uma tabela em cada execução.
- Materialização incremental com uma estratégia de união, em que os dados novos ou atualizados são adicionados a uma tabela existente, muitas vezes através de uma estratégia de união para processar alterações.
Configurar o dbt para usar DataFrames do BigQuery
Se estiver a usar o
dbt Core,
tem de usar um ficheiro profiles.yml para utilização com os DataFrames do BigQuery.
O exemplo seguinte usa o método oauth:
your_project_name:
outputs:
dev:
compute_region: us-central1
dataset: your_bq_dateset
gcs_bucket: your_gcs_bucket
job_execution_timeout_seconds: 300
job_retries: 1
location: US
method: oauth
priority: interactive
project: your_gcp_project
threads: 1
type: bigquery
target: dev
Se estiver a usar o
dbt Cloud,
pode
estabelecer ligação à sua plataforma de dados
diretamente na interface do dbt Cloud. Neste cenário, não precisa de um ficheiro
profiles.yml. Para mais informações, consulte o artigo
Acerca do ficheiro profiles.yml
Este é um exemplo de uma configuração ao nível do projeto para o dbt_project.yml
ficheiro:
# Name your project! Project names should contain only lowercase characters
# and underscores. A good package name should reflect your organization's
# name or the intended use of these models.
name: 'your_project_name'
version: '1.0.0'
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the config(...) macro.
models:
your_project_name:
submission_method: bigframes
notebook_template_id: 7018811640745295872
packages: ["scikit-learn", "mlflow"]
timeout: 3000
# Config indicated by + and applies to all files under models/example/
example:
+materialized: view
Também é possível configurar alguns parâmetros através do método dbt.config no código Python. Se estas definições entrarem em conflito com o seu ficheiro dbt_project.yml, as configurações com dbt.config têm prioridade.
Para mais informações, consulte os artigos Configurações de modelos e dbt_project.yml.
Configurações
Pode configurar as seguintes configurações através do método dbt.config no seu modelo Python. Estas configurações substituem a configuração ao nível do projeto.
| Configuração | Obrigatória | Utilização |
|---|---|---|
submission_method |
Sim | submission_method=bigframes |
notebook_template_id |
Não | Se não for especificado, é criado e usado um modelo predefinido. |
packages |
Não | Especifique a lista adicional de pacotes Python, se necessário. |
timeout |
Não | Opcional: prolongue o limite de tempo de execução da tarefa. |
Exemplos de modelos Python
As secções seguintes apresentam cenários de exemplo e modelos Python.
Carregar dados de uma tabela do BigQuery
Para usar dados de uma tabela do BigQuery existente como origem no seu modelo Python, primeiro defina esta origem num ficheiro YAML. O exemplo
seguinte está definido num ficheiro source.yml.
version: 2
sources:
- name: my_project_source # A custom name for this source group
database: bigframes-dev # Your Google Cloud project ID
schema: yyy_test_us # The BigQuery dataset containing the table
tables:
- name: dev_sql1 # The name of your BigQuery table
Em seguida, cria o seu modelo Python, que pode usar as origens de dados configuradas neste ficheiro YAML:
def model(dbt, session):
# Configure the model to use BigFrames for submission
dbt.config(submission_method="bigframes")
# Load data from the 'dev_sql1' table within 'my_project_source'
source_data = dbt.source('my_project_source', 'dev_sql1')
# Example transformation: Create a new column 'id_new'
source_data['id_new'] = source_data['id'] * 10
return source_data
Referenciar outro modelo
Pode criar modelos que dependam da saída de outros modelos do dbt, como mostrado no exemplo seguinte. Isto é útil para criar pipelines de dados modulares.
def model(dbt, session):
# Configure the model to use BigFrames
dbt.config(submission_method="bigframes")
# Reference another dbt model named 'dev_sql1'.
# It assumes you have a model defined in 'dev_sql1.sql' or 'dev_sql1.py'.
df_from_sql = dbt.ref("dev_sql1")
# Example transformation on the data from the referenced model
df_from_sql['id'] = df_from_sql['id'] * 100
return df_from_sql
Especificar uma dependência de pacote
Se o seu modelo Python exigir bibliotecas de terceiros específicas, como o MLflow ou o Boto3, pode declarar o pacote na configuração do modelo, conforme mostrado no exemplo seguinte. Estes pacotes são instalados no ambiente de execução.
def model(dbt, session):
# Configure the model for BigFrames and specify required packages
dbt.config(
submission_method="bigframes",
packages=["mlflow", "boto3"] # List the packages your model needs
)
# Import the specified packages for use in your model
import mlflow
import boto3
# Example: Create a DataFrame showing the versions of the imported packages
data = {
"mlflow_version": [mlflow.__version__],
"boto3_version": [boto3.__version__],
"note": ["This demonstrates accessing package versions after import."]
}
bdf = bpd.DataFrame(data)
return bdf
Especificar um modelo não predefinido
Para ter mais controlo sobre o ambiente de execução ou usar definições pré-configuradas, pode especificar um modelo de bloco de notas não predefinido para o seu modelo de DataFrames do BigQuery, conforme mostrado no exemplo seguinte.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# ID of your pre-created notebook template
notebook_template_id="857350349023451yyyy",
)
data = {"int": [1, 2, 3], "str": ['a', 'b', 'c']}
return bpd.DataFrame(data=data)
Materializar as tabelas
Quando o dbt executa os seus modelos Python, tem de saber como guardar os resultados no seu data warehouse. A isto chama-se materialização.
Para a materialização de tabelas padrão, o dbt cria ou substitui totalmente uma tabela no seu data warehouse com o resultado do seu modelo cada vez que é executado. Isto é feito por predefinição ou definindo explicitamente a propriedade materialized='table', conforme mostrado no exemplo seguinte.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# Instructs dbt to create/replace this model as a table
materialized='table',
)
data = {"int_column": [1, 2], "str_column": ['a', 'b']}
return bpd.DataFrame(data=data)
A materialização incremental com uma estratégia de união permite que o dbt atualize a sua tabela apenas com linhas novas ou modificadas. Isto é útil para conjuntos de dados grandes, porque a recriação completa de uma tabela sempre que necessário pode ser ineficiente. A estratégia de união é uma forma comum de processar estas atualizações.
Esta abordagem integra as alterações de forma inteligente fazendo o seguinte:
- Atualizar linhas existentes que foram alteradas.
- Adicionar novas linhas.
- Opcional, consoante a configuração: eliminar linhas que já não estão presentes na origem.
Para usar a estratégia de união, tem de especificar uma propriedade que o dbt possa usar para identificar as linhas correspondentes entre o resultado do seu modelo e a tabela existente, conforme mostrado no exemplo seguinte.unique_key
def model(dbt, session):
dbt.config(
submission_method="bigframes",
materialized='incremental',
incremental_strategy='merge',
unique_key='int', # Specifies the column to identify unique rows
)
# In this example:
# - Row with 'int' value 1 remains unchanged.
# - Row with 'int' value 2 has been updated.
# - Row with 'int' value 4 is a new addition.
# The 'merge' strategy will ensure that only the updated row ('int 2')
# and the new row ('int 4') are processed and integrated into the table.
data = {"int": [1, 2, 4], "str": ['a', 'bbbb', 'd']}
return bpd.DataFrame(data=data)
Resolução de problemas
Pode observar a execução do Python nos registos do dbt.
Além disso, pode ver o código e os registos (incluindo execuções anteriores) na página Execuções do Colab Enterprise.
Aceder às execuções do Colab Enterprise
Faturação
Quando usa o adaptador dbt-bigquery com DataFrames do BigQuery, existem Cloud de Confiance by S3NS cobranças das seguintes origens:
Execução do notebook: é-lhe cobrada a execução do tempo de execução do notebook. Para mais informações, consulte os preços de tempo de execução do bloco de notas.
Execução de consultas do BigQuery: no bloco de notas, os DataFrames do BigQuery convertem Python em SQL e executam o código no BigQuery. A cobrança é feita de acordo com a configuração do projeto e a consulta, conforme descrito nos preços dos DataFrames do BigQuery.
Pode usar a seguinte etiqueta de faturação na consola de faturação do BigQuery para filtrar o relatório de faturação da execução do bloco de notas e das execuções do BigQuery acionadas pelo adaptador dbt-bigquery:
- Etiqueta de execução do BigQuery:
bigframes-dbt-api
O que se segue?
- Para saber mais sobre o dbt e os DataFrames do BigQuery, consulte o artigo Usar DataFrames do BigQuery com modelos Python do dbt.
- Para saber mais acerca dos modelos Python do dbt, consulte os artigos Modelos Python e Configuração do modelo Python.
- Para saber mais sobre os blocos de notas do Colab Enterprise, consulte o artigo Crie um bloco de notas do Colab Enterprise através da Cloud de Confiance consola.
- Para saber mais acerca dos Cloud de Confiance by S3NS parceiros, consulte o artigo Cloud de Confiance by S3NS Ready – Parceiros do BigQuery.