Graphen mit BigQuery DataFrames visualisieren
In diesem Dokument wird gezeigt, wie Sie mit der BigQuery DataFrames-Visualisierungsbibliothek verschiedene Arten von Diagrammen erstellen.
Die bigframes.pandas API bietet ein vollständiges Ökosystem von Tools für Python. Die API unterstützt erweiterte statistische Vorgänge und Sie können die von BigQuery DataFrames generierten Aggregationen visualisieren. Sie können auch von BigQuery DataFrames zu einem pandas-DataFrame mit integrierten Stichprobenvorgängen wechseln.
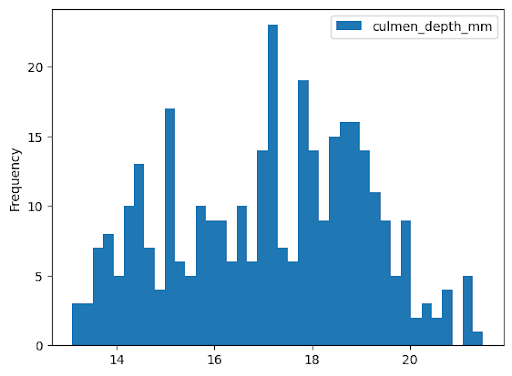
Histogramm
Im folgenden Beispiel werden Daten aus der Tabelle bigquery-public-data.ml_datasets.penguins gelesen, um ein Histogramm zur Verteilung der Schnabeltiefe von Pinguinen zu erstellen:
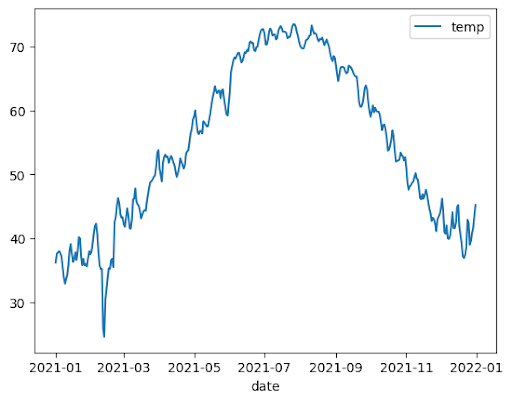
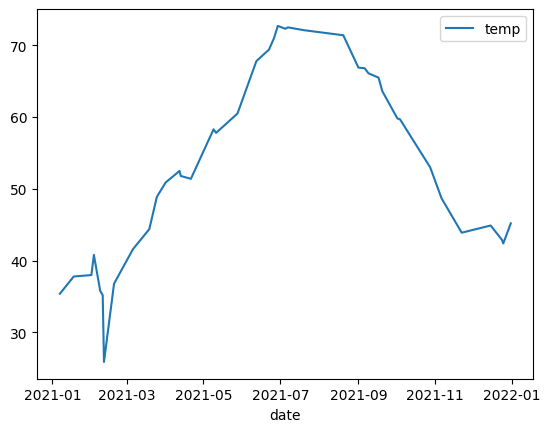
Liniendiagramm
Im folgenden Beispiel werden Daten aus der Tabelle bigquery-public-data.noaa_gsod.gsod2021 verwendet, um ein Liniendiagramm der medianen Temperaturänderungen im Jahresverlauf zu erstellen:
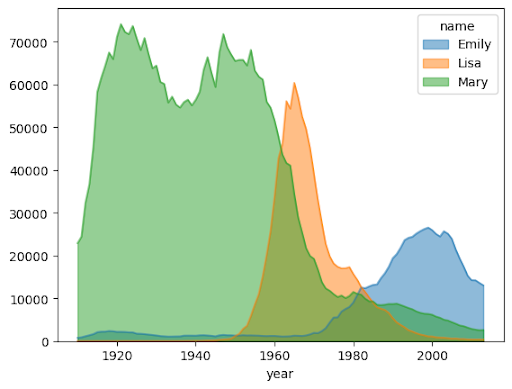
Flächendiagramm
Im folgenden Beispiel wird die Tabelle bigquery-public-data.usa_names.usa_1910_2013 verwendet, um die Beliebtheit von Namen in der Geschichte der USA zu verfolgen. Dabei wird der Fokus auf die Namen Mary, Emily und Lisa gelegt:
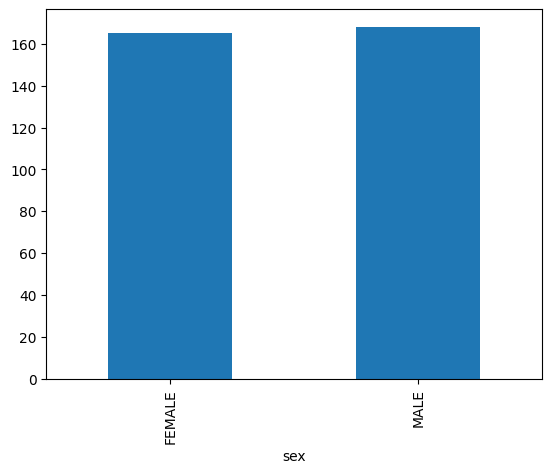
Balkendiagramm
Im folgenden Beispiel wird die Tabelle bigquery-public-data.ml_datasets.penguins verwendet, um die Verteilung der Geschlechter von Pinguinen zu visualisieren:
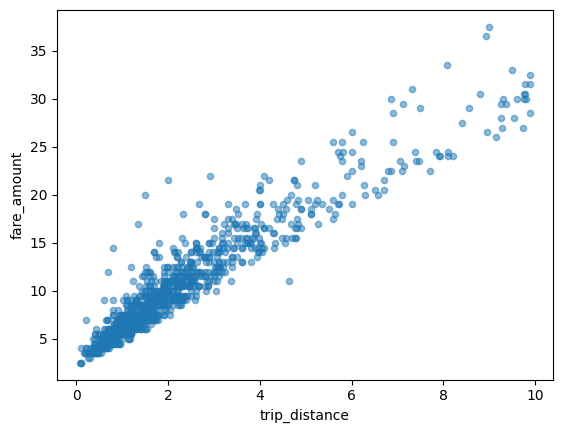
Streudiagramm
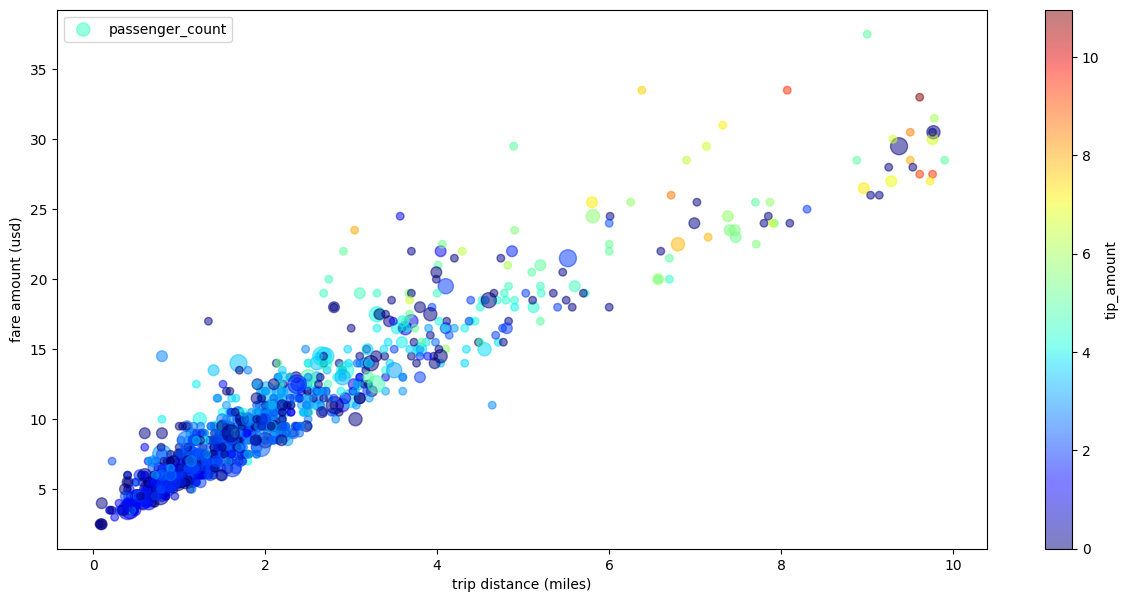
Im folgenden Beispiel wird die Tabelle bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2021 verwendet, um die Beziehung zwischen Taxitarifbeträgen und Fahrstrecken zu untersuchen:
Großes Dataset visualisieren
BigQuery DataFrames lädt Daten zur Visualisierung auf Ihren lokalen Computer herunter. Die Anzahl der herunterzuladenden Datenpunkte ist standardmäßig auf 1.000 begrenzt. Wenn die Anzahl der Datenpunkte die Obergrenze überschreitet, werden in BigQuery-DataFrames zufällig so viele Datenpunkte ausgewählt, wie die Obergrenze vorgibt.
Sie können diese Obergrenze überschreiben, indem Sie beim Erstellen eines Diagramms den Parameter sampling_n festlegen, wie im folgenden Beispiel gezeigt:
Erweiterte Darstellung mit Pandas- und Matplotlib-Parametern
Sie können weitere Parameter übergeben, um das Diagramm zu optimieren, wie bei Pandas, da die Plotting-Bibliothek von BigQuery DataFrames auf Pandas und Matplotlib basiert. In den folgenden Abschnitten finden Sie Beispiele.
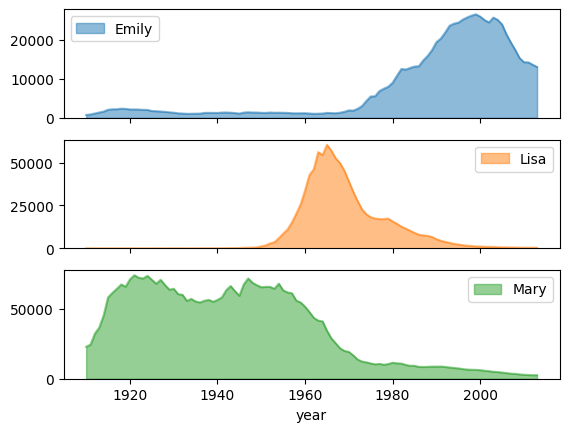
Trend zur Beliebtheit von Namen mit Unterdiagrammen
Anhand der Daten zum Namensverlauf aus dem Beispiel für ein Flächendiagramm werden im folgenden Beispiel einzelne Diagramme für jeden Namen erstellt. Dazu wird subplots=True im plot.area()-Funktionsaufruf festgelegt:
Streudiagramm für Taxifahrten mit mehreren Dimensionen
Im folgenden Beispiel werden die Daten aus dem Streudiagrammbeispiel verwendet. Die Labels für die X- und Y-Achse werden umbenannt, der Parameter passenger_count für die Punktgrößen und der Parameter tip_amount für die Farben verwendet und die Größe der Abbildung wird angepasst: