
Sistemas de grelhas para análise espacial
Este documento explica a finalidade e os métodos de utilização de sistemas de grelhas geoespaciais (como S2 e H3) no BigQuery para organizar dados espaciais em áreas geográficas padronizadas. Também explica como escolher o sistema de grelha certo para a sua aplicação. Este documento é útil para qualquer pessoa que trabalhe com dados espaciais e realize análises espaciais no BigQuery.
Vista geral e desafios da utilização da análise espacial
As estatísticas espaciais ajudam a mostrar a relação entre entidades (lojas ou casas) e eventos num espaço físico. A estatística espacial que usa a superfície da Terra como espaço físico denomina-se estatística geoespacial. O BigQuery inclui funcionalidades e funções geoespaciais que lhe permitem realizar análises geoespaciais em grande escala.
Muitos exemplos de utilização geoespaciais envolvem a agregação de dados em áreas localizadas e a comparação das agregações estatísticas dessas áreas entre si. Estas áreas localizadas são representadas como polígonos numa tabela de base de dados espacial. Em alguns contextos, este método é denominado geografia estatística. O método de determinação da extensão das áreas geográficas tem de ser padronizado para melhorar os relatórios, a análise e a indexação espacial. Por exemplo, um retalhista pode querer analisar as alterações demográficas ao longo do tempo em áreas onde as suas lojas estão localizadas ou em áreas onde está a ponderar construir uma nova loja. Em alternativa, uma seguradora pode querer melhorar a sua compreensão dos riscos de propriedade analisando os riscos de perigos naturais prevalecentes numa determinada área.
Devido aos regulamentos de privacidade de dados rigorosos em muitas áreas, os conjuntos de dados que contêm informações de localização têm de ser desidentificados ou parcialmente anónimos para ajudar a proteger a privacidade dos indivíduos representados nos dados. Por exemplo, pode ter de realizar uma análise de risco de concentração de crédito geográfico num conjunto de dados que contenha dados sobre empréstimos hipotecários pendentes. Para remover a identificação do conjunto de dados de modo a torná-lo adequado para a análise em conformidade, tem de reter informações relevantes sobre a localização das propriedades, mas evitar usar uma morada específica ou coordenadas de longitude e latitude.
Nos exemplos anteriores, os criadores destas análises deparam-se com os seguintes desafios:
- Como desenhar os limites da área dentro da qual analisa as alterações ao longo do tempo?
- Como usar os limites administrativos existentes, como os setores censitários ou um sistema de grelha de várias resoluções?
Este documento tem como objetivo responder a estas perguntas explicando cada opção, descrevendo as práticas recomendadas e ajudando a evitar erros comuns.
Erros comuns ao escolher áreas estatísticas
Os conjuntos de dados empresariais, como vendas de imobiliárias, campanhas de marketing, envios de comércio eletrónico e apólices de seguros, são adequados para a análise espacial. Muitas vezes, estes conjuntos de dados contêm o que parece ser uma chave de junção espacial conveniente, como um setor censitário, um código postal ou o nome de uma cidade. Os conjuntos de dados públicos que contêm representações de setores censitários, códigos postais e cidades estão prontamente disponíveis, o que os torna tentadores para usar como limites administrativos para agregação estatística.
Embora sejam nominalmente convenientes, estes e outros limites administrativos têm desvantagens. Além disso, estes limites podem funcionar bem nas fases iniciais de um projeto de análise, mas as desvantagens podem ser notadas nas fases posteriores.
Códigos postais
Os códigos postais são usados para encaminhar correio em vários países em todo o mundo e, devido a esta ubiquidade, são frequentemente usados para fazer referência a localizações e áreas em conjuntos de dados espaciais e não espaciais. Referindo-nos ao exemplo anterior sobre o empréstimo hipotecário, muitas vezes, é necessário remover a identificação de um conjunto de dados antes de poder realizar a análise a jusante. Uma vez que cada morada da propriedade contém um código postal, as tabelas de referência de códigos postais são acessíveis, o que a torna uma opção conveniente para uma chave de junção para análise espacial.
Uma dificuldade na utilização de códigos postais é que não são representados como polígonos e não existe uma única fonte de verdade correta para as áreas de códigos postais. Além disso, os códigos postais não representam bem o comportamento humano real. Os dados de códigos postais mais usados nos EUA são provenientes dos ficheiros shapefile TIGER/Line do US Census Bureau, que contêm um conjunto de dados denominado ZCTA5 (área de tabulação de códigos postais). Este conjunto de dados representa uma aproximação dos limites dos códigos postais derivados de rotas de entrega de correio. No entanto, alguns códigos postais que representam edifícios individuais não têm qualquer limite. Este problema também está presente noutros países, o que dificulta a formação de uma única tabela de factos global que contenha um conjunto de limites de códigos postais autorizados que possam ser usados em todos os sistemas e conjuntos de dados.
Além disso, não existe um formato de código postal padronizado usado em todo o mundo. Alguns são numéricos, variando entre três e dez dígitos, enquanto outros são alfanuméricos. Também existe uma sobreposição entre países, o que torna necessário armazenar o país de origem numa coluna separada juntamente com o código postal. Alguns países não usam códigos postais, o que complica ainda mais a análise.
Grupos de recenseamento, cidades e condados
Existem algumas unidades administrativas, como setores censitários, cidades e condados, que não sofrem da falta de um limite fidedigno. Os limites das cidades, por exemplo, estão na maioria dos casos bem estabelecidos pelas autoridades governamentais. Os grupos de recenseamento estão bem definidos pelo US Census Bureau e pelas respetivas instituições análogas na maioria dos outros países.
Uma desvantagem da utilização destas e de outras fronteiras administrativas é que mudam ao longo do tempo e não são geograficamente consistentes entre si. Os concelhos e as cidades unem-se ou separam-se uns dos outros e, ocasionalmente, são renomeados. Os setores censitários são atualizados uma vez por década nos EUA e em alturas diferentes noutros países. Curiosamente, em alguns casos, o limite geográfico pode mudar, mas o respetivo identificador exclusivo permanece o mesmo, o que dificulta a análise e a compreensão das alterações ao longo do tempo.
Outra desvantagem comum a alguns limites administrativos é que são áreas discretas sem hierarquia geográfica. Além de comparar áreas individuais entre si, um requisito comum é comparar agregações das próprias áreas com outras agregações. Por exemplo, um retalhista que implemente o modelo de Huff pode querer executar esta análise usando várias distâncias, que podem não corresponder a áreas administrativas usadas noutros locais da empresa.
Grelhas de resolução única e múltipla
As grelhas de resolução única consistem em unidades discretas que não têm relação geográfica com áreas maiores que contêm essas unidades. Por exemplo, os códigos postais têm uma relação geográfica inconsistente com os limites de unidades administrativas maiores, como cidades ou condados que podem conter códigos postais. Para a análise espacial, é importante compreender a relação entre as diferentes áreas sem um conhecimento profundo do histórico e da legislação que define o polígono da área.
As grelhas de várias resoluções são, por vezes, denominadas grelhas hierárquicas porque as células em cada nível de zoom são subdivididas em células mais pequenas em níveis de zoom mais elevados. As grelhas de várias resoluções consistem numa hierarquia bem definida de unidades que estão contidas em unidades maiores. Os setores censitários, por exemplo, contêm grupos de quarteirões, que, por sua vez, contêm quarteirões. Esta relação hierárquica consistente pode ser útil para a agregação estatística. Por exemplo, ao calcular a média dos rendimentos de todos os grupos de blocos contidos num setor, pode mostrar o rendimento médio desse setor censitário que contém os grupos de blocos. Isto não seria possível com códigos postais, porque todas as áreas postais estão localizadas numa única resolução. Seria difícil comparar o rendimento de uma área com as áreas circundantes, uma vez que não existe uma forma padronizada de definir a adjacência nem de comparar o rendimento em diferentes países.
Sistemas de grelha S2 e H3
Esta secção oferece uma vista geral dos sistemas de grelha S2 e H3.
S2
A geometria S2 é um sistema de grelha hierárquico de código aberto desenvolvido pela Google e lançado publicamente em 2011. Pode usar o sistema de grelha S2 para organizar e indexar dados espaciais atribuindo um número inteiro de 64 bits exclusivo a cada célula. Existem 31 níveis de resolução. Cada célula é representada como um quadrado e foi concebida para operações em geometrias esféricas (por vezes, denominadas geografias). Cada quadrado é subdividido em quatro quadrados mais pequenos. A travessia de vizinhos, que é a capacidade de identificar células S2 vizinhas, está menos bem definida porque os quadrados podem ter quatro ou oito vizinhos relevantes, consoante o tipo de análise. Segue-se um exemplo de células da grelha S2 com várias resoluções:
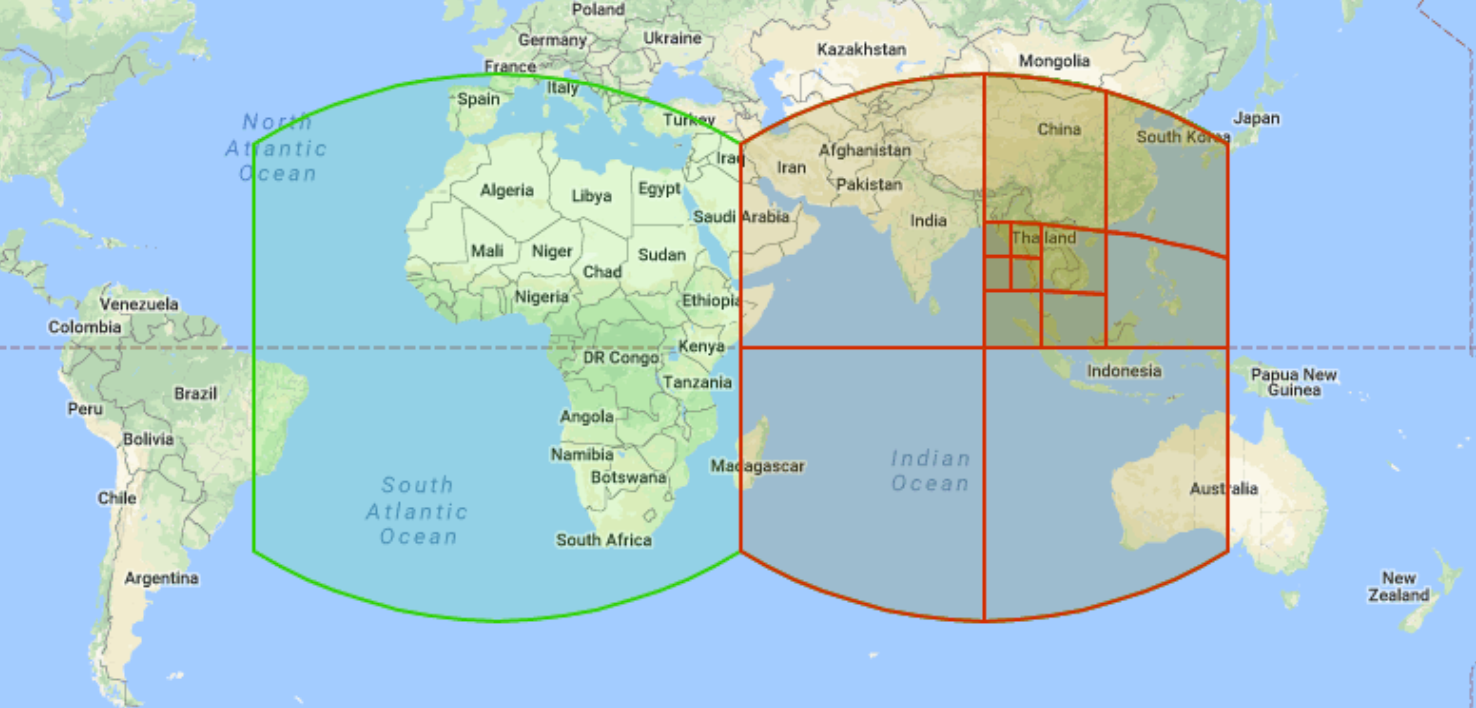
O BigQuery usa células S2 para indexar dados espaciais e expõe várias funções. Por exemplo, S2_CELLIDFROMPOINT
devolve o ID da célula S2 que contém um ponto na superfície da Terra a um determinado nível.
H3
O H3 é um sistema de grelha hierárquico de código aberto desenvolvido pela Uber e usado pelo Overture Maps. Existem 16 níveis de resolução. Cada célula é representada como um hexágono e, tal como no S2, a cada célula é atribuído um número inteiro de 64 bits exclusivo. No exemplo sobre a visualização de células H3 que cobrem o Golfo do México, as células H3 mais pequenas não estão perfeitamente contidas nas células maiores.
Cada célula subdivide-se em sete hexágonos mais pequenos. A subdivisão não é exata, mas é adequada para muitos exemplos de utilização. Cada célula partilha uma aresta com seis células vizinhas, o que simplifica a travessia de vizinhos. Por exemplo, em cada nível, existem 12 pentágonos, que, em vez disso, partilham uma aresta com cinco vizinhos, em vez de seis. Embora o H3 não seja suportado no BigQuery, pode adicionar suporte do H3 ao BigQuery através da Carto Analytics Toolbox for BigQuery.
Embora as bibliotecas S2 e H3 sejam de código aberto e estejam disponíveis ao abrigo da licença Apache 2, a biblioteca H3 tem documentação mais detalhada.
HEALPix
Um esquema adicional para dividir a esfera em quadrículas, usado frequentemente no campo da astronomia, é conhecido como Hierarchical Equal Area isoLatitude Pixelation (HEALPix). O HEALPix é independente da profundidade hierárquica dos píxeis, mas o tempo de cálculo permanece constante.
O HEALPix é um esquema de pixelização hierárquico de área igual para a esfera. É usada para representar e analisar dados na esfera celeste (ou noutra). Além do tempo de computação constante, a grelha HEALPix tem as seguintes características:
- As células da grelha são hierárquicas, onde as relações principal/secundário são mantidas.
- Numa hierarquia específica, as células têm áreas iguais.
- As células seguem uma distribuição de iso-latitude, o que permite um desempenho mais elevado para métodos espectrais.
O BigQuery não suporta HEALPix, mas existem várias implementações em vários idiomas, incluindo JavaScript, o que facilita a utilização em funções definidas pelo utilizador (UDFs) do BigQuery.
Exemplos de utilização para cada estratégia de indexação
Esta secção apresenta alguns exemplos que ajudam a avaliar qual é o melhor sistema de grelha para o seu exemplo de utilização.
Muitos exemplos de utilização de estatísticas e relatórios envolvem a visualização, quer como parte da análise em si, quer para a criação de relatórios para as partes interessadas da empresa. Estas visualizações são apresentadas frequentemente em Web Mercator, que é a projeção plana usada pelo Google Maps e muitas outras aplicações de mapas Web. Nos casos em que a visualização desempenha um papel vital, as células H3 oferecem uma experiência de visualização subjetivamente melhor. As células S2, especialmente em latitudes mais elevadas, tendem a aparecer mais distorcidas do que as H3 e não aparecem de forma consistente com as células de latitudes mais baixas quando apresentadas numa projeção plana.
As células H3 simplificam a implementação quando a comparação de vizinhos desempenha um papel importante na análise. Por exemplo, uma análise comparativa entre secções de uma cidade pode ajudar a decidir que localização é adequada para abrir uma nova loja de retalho ou um centro de distribuição. A análise requer cálculos estatísticos para os atributos de uma determinada célula que é comparada com as células adjacentes.
As células S2 podem funcionar melhor em análises de natureza global, como análises que envolvem medições de distâncias e ângulos. O Pokemon Go da Niantic usa células S2 para determinar onde os recursos do jogo são colocados e como são distribuídos. A propriedade de subdivisão exata das células S2 garante que os recursos do jogo podem ser distribuídos uniformemente em todo o mundo.
O que se segue?
- Para ver as práticas recomendadas para a agrupamento espacial, consulte o artigo Agrupamento espacial no BigQuery: práticas recomendadas.
- Saiba como criar uma hierarquia espacial a partir de dados imperfeitos.
- Saiba mais sobre a geometria S2 no GitHub.
- Saiba mais sobre a geometria H3 no GitHub.
- Veja exemplos que usam H3, BigQuery e Earth Engine.