
Présentation de BigQuery
BigQuery est une plate-forme de données entièrement gérée et compatible avec l'IA, qui vous aide à gérer et analyser vos données grâce à des fonctionnalités intégrées telles que le machine learning, la recherche, l'analyse géospatiale et l'informatique décisionnelle. L'architecture sans serveur de BigQuery vous permet d'utiliser des langages tels que SQL et Python pour répondre à des questions cruciales pour votre organisation, sans aucune infrastructure à gérer.
BigQuery offre une manière uniforme de travailler avec des données structurées et non structurées, et est compatible avec des formats de table ouverts tels qu'Apache Iceberg, Delta et Apache Hudi. Le flux BigQuery permet l'ingestion et l'analyse de données en continu, tandis que le moteur d'analyse distribué et évolutif de BigQuery vous permet d'interroger des téraoctets en quelques secondes et des pétaoctets en quelques minutes.
L'architecture de BigQuery se compose de deux parties : une couche de stockage qui ingère, stocke et optimise les données, et une couche de calcul qui fournit des fonctionnalités d'analyse. Ces couches de calcul et de stockage fonctionnent efficacement indépendamment les unes des autres grâce au réseau de Google à l'échelle du pétaoctet, qui permet la communication nécessaire entre elles.
Les anciennes bases de données doivent généralement partager des ressources entre les opérations de lecture et d'écriture et les opérations d'analyse. Cela peut entraîner des conflits de ressources et ralentir les requêtes lorsque les données sont écrites ou lues dans l'espace de stockage. Les pools de ressources partagées peuvent être davantage sollicités lorsque des ressources sont nécessaires pour des tâches de gestion de base de données, telles que l'attribution ou la révocation d'autorisations. La séparation des couches de calcul et de stockage dans BigQuery permet à chaque couche d'allouer des ressources de manière dynamique sans affecter les performances ou la disponibilité des autres couches.
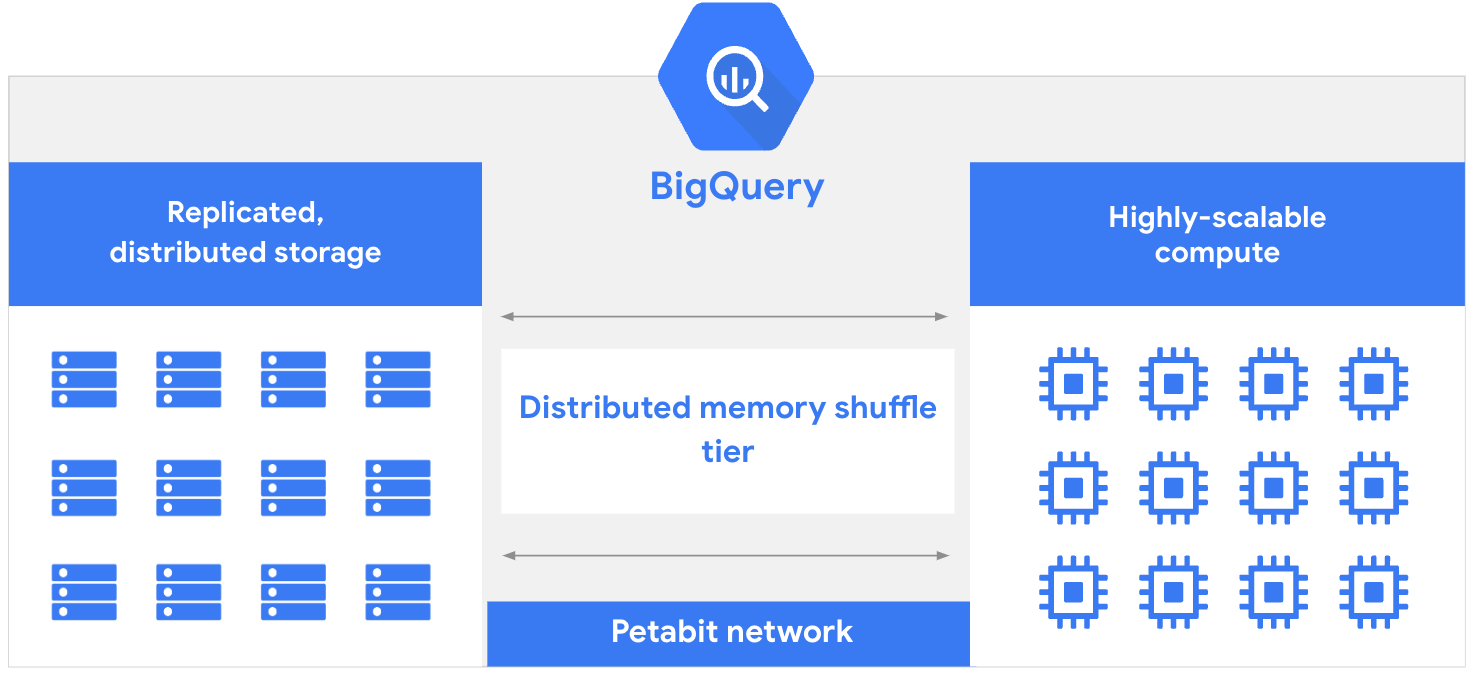
Ce principe de séparation permet à BigQuery d'innover plus rapidement, car les améliorations de stockage et de calcul peuvent être déployées indépendamment, sans temps d'arrêt ni impact négatif sur les performances du système. Il est également essentiel de proposer un entrepôt de données sans serveur entièrement géré dans lequel l'équipe d'ingénieurs BigQuery gère les mises à jour et la maintenance. En conséquence, vous n'avez pas besoin de provisionner ou de faire évoluer manuellement les ressources, ce qui vous permet de vous concentrer sur la génération de valeur plutôt que sur les tâches traditionnelles de gestion de bases de données.
Les interfaces BigQuery incluent Cloud de Confiance console interface et l'outil de ligne de commande BigQuery. Les développeurs et les data scientists peuvent utiliser des bibliothèques clientes dans les langages de programmation familiers, y compris Python, Java, JavaScript et Go, ainsi que l'API REST et l'API RPC de BigQuery, pour transformer et gérer les données. Les pilotes ODBC et JDBC permettent d'interagir avec des applications existantes, y compris des outils et des utilitaires tiers.
En tant qu'analyste de données, ingénieur de données, administrateur d'entrepôt de données ou data scientist, BigQuery vous aide à charger, traiter et analyser des données afin d'éclairer des décisions commerciales critiques.
Premiers pas avec BigQuery
Vous pouvez commencer à explorer BigQuery en quelques minutes.
Explorer BigQuery
L'infrastructure sans serveur de BigQuery vous permet de vous concentrer sur vos données plutôt que sur la gestion des ressources. BigQuery combine un entrepôt de données cloud et de puissants outils d'analyse.
Stockage BigQuery
BigQuery stocke les données dans un format de stockage en colonnes optimisé pour les requêtes analytiques. BigQuery présente les données sous forme de tables, de lignes et de colonnes, et est entièrement compatible avec la sémantique des transactions de base de données (ACID). Le stockage BigQuery est automatiquement répliqué sur plusieurs emplacements afin de fournir une haute disponibilité.
- Découvrez les modèles courants d'organisation des ressources BigQuery dans l'entrepôt de données et les magasins de données.
- Découvrez les ensembles de données, le conteneur de premier niveau des tables et vues BigQuery.
- Chargez des données dans BigQuery de différentes manières :
- Transférez des données par flux avec l'API Storage Write.
- Chargez des données par lots depuis des fichiers locaux ou depuis Cloud Storage, dans des formats incluant : Avro, Parquet, ORC, CSV, JSON.
Pour en savoir plus, consultez la page Présentation du stockage BigQuery.
Analyses BigQuery
L'analyse descriptive et l'analyse prescriptive incluent l'informatique décisionnelle, l'analyse ad hoc, les analyses géospatiales et le machine learning. Vous pouvez interroger les données stockées dans BigQuery ou exécuter des requêtes sur des données où qu'elles soient hébergées, à l'aide de tables externes ou de requêtes fédérées, y compris dans Cloud Storage.
- Requêtes SQL standard ANSI (Compatibilité ISO/IEC 9075) y compris la gestion des jointures, des champs imbriqués et répétés, des fonctions d'analyse et d'agrégation, des requêtes à plusieurs instructions, et de diverses fonctions spatiales avec l'analyse géospatiale (systèmes d'informations géographiques).
- API Python compatible avec Pandas, fournie par BigQuery DataFrames.
- Création de vues pour partager votre analyse.
- Compatibilité avec les outils d'informatique décisionnelle, y compris les outils tiers utilisant les pilotes ODBC et JDBC Simba pour BigQuery
- BigQuery ML fournit des données analytiques de machine learning et des analyses prédictives.
- BigQuery Studio facilite la réalisation de vos workflows d'analyse de données et de machine learning (ML) dans BigQuery.
- Interrogation de données en dehors de BigQuery avec des tables externes.
Pour en savoir plus, consultez la page Présentation des analyses BigQuery.
Administration de BigQuery
BigQuery offre une gestion centralisée des données et des ressources de calcul tandis que la gestion de l'authentification et des accès (IAM) vous aide à sécuriser ces ressources avec le modèle d'accès utilisé dans Cloud de Confiance by S3NS.
- La section Présentation de la sécurité et de la gouvernance des données vous aide à comprendre la gouvernance des données et les contrôles dont vous pourriez avoir besoin pour sécuriser vos ressources BigQuery.
- Les jobs sont des actions que BigQuery exécute en votre nom pour charger, exporter, interroger ou copier des données.
- Les réservations vous permettent de basculer entre la tarification à la demande et la tarification basée sur la capacité.
Pour en savoir plus, consultez la page Présentation de l'administration de BigQuery.
Ressources BigQuery
Explorez les ressources BigQuery :
- Les notes de version fournissent des journaux des modifications des fonctionnalités, des changements et des abandons.
- Stack Overflow héberge une communauté dynamique de développeurs et d'analystes qui travaillent avec BigQuery.
- Le livre Google BigQuery: The Definitive Guide: Data Warehousing, Analytics, and Machine Learning at Scale de Valliappa Lakshmanan et Jordan Tigani explique le fonctionnement de BigQuery et fournit un tutoriel détaillé sur l'utilisation du service.
API, outils et documentations de références
Documentation de référence pour les développeurs et les analystes BigQuery :
- API BigQuery et bibliothèques clientes présentent les fonctionnalités de BigQuery et leur utilisation.
- La documentation de référence de l'API BigQuery DataFrames fournit des détails sur l'utilisation de l'API Python compatible avec Pandas.
- DML et les fonctions définies par l'UDF permettent de gérer et de transformer vos données BigQuery.
- La documentation de référence de l'outil de ligne de commande bq décrit la syntaxe, les commandes, les options et les arguments de l'interface de CLI
bq. - L'intégration ODBC / JDBC connecte BigQuery à vos outils et infrastructures existants.
Rôles et ressources BigQuery
BigQuery répond aux besoins des professionnels du traitement des données ayant les rôles et responsabilités suivants.
Analyste de données
Conseils à suivre pour effectuer les tâches suivantes :
- Interroger des données BigQuery à l'aide de requêtes interactives ou par lot avec la syntaxe de requête SQL
- Analyser et transformer des données BigQuery à l'aide de l'API BigQuery DataFrames compatible avec Pandas.
- Référencer des fonctions, des opérateurs et des expressions conditionnelles SQL pour interroger des données
Utiliser divers outils pour analyser et visualiser des données BigQuery y compris Google Sheets.
Utiliser les analyses géospatiales pour analyser et visualiser des données géospatiales avec les outils de systèmes d'informations géographiques de BigQuery.
Optimiser les performances des requêtes à l'aide des éléments suivants :
- Tables partitionnées : élaguez les tables volumineuses en fonction d'horodatages ou de plages d'entiers.
- Vues matérialisées : définissez des vues mises en cache pour optimiser les requêtes ou fournir des résultats persistants .
Administrateur de données
Conseils à suivre pour effectuer les tâches suivantes :
- Gérer les coûts avec les réservations pour équilibrer la tarification à la demande et la tarification basée sur la capacité.
- Comprendre la sécurité et la gouvernance des données pour sécuriser les données par dataset, table, colonne, ligne ou vue.
- Sauvegarder les données avec des instantanés de table pour conserver le contenu d'une table à un moment donné.
- Consulter les tables BigQuery INFORMATION_SCHEMA pour comprendre les métadonnées des ensembles de données, des jobs, du contrôle des accès, des réservations, des tables et autres.
- Utiliser des jobs pour que BigQuery charge, exporte, interroge ou copie des données en votre nom.
- Surveiller les journaux et les ressources pour comprendre BigQuery et les charges de travail.
Pour en savoir plus, consultez la page Présentation de l'administration de BigQuery.
Data scientist
Conseils d'utilisation pour l'utilisation des tâches de machine learning de BigQuery ML pour effectuer les opérations suivantes :
- Comprendre le parcours utilisateur de bout en bout pour les modèles de machine learning
- Gérer le contrôle des accès pour BigQuery ML
- Créer et entraîner des modèles BigQuery ML, y compris :
- Prévisions de régressions linéaires
- Classifications de régressions logistiques binaires et logistiques à classes multiples
- Clustering des k-moyennes pour la segmentation des données
- Prévisions de séries temporelles avec des modèles ARIMA+
Développeur de données
Conseils à suivre pour effectuer les tâches suivantes :
- Charger des données dans BigQuery
avec :
- Données par lot pour Avro, Parquet, ORC, CSV, JSON formats
- API BigQuery Storage Write
Utiliser une bibliothèque d'exemples de code, y compris :
Cloud de Confiance Explorateur d'exemples (limité à BigQuery)
Étape suivante
- Découvrez les différences entre BigQuery dans Cloud de Confiance et Google Cloud.
- Pour obtenir une présentation du stockage BigQuery, consultez la page Présentation du stockage BigQuery.
- Pour une présentation des requêtes BigQuery, consultez la page Présentation des analyses BigQuery.
- Pour une présentation de l'administration de BigQuery, consultez la page Présentation de l'administration de BigQuery.
- Pour une présentation de la sécurité de BigQuery, consultez la page Présentation de la sécurité et de la gouvernance des données.