
了解槽
BigQuery 槽是 BigQuery 用于执行 SQL 查询、Python 代码或其他作业类型的虚拟计算单元。在执行查询期间,BigQuery 会自动确定查询使用的槽数。使用的槽数取决于处理的数据量、查询的复杂程度以及可用的槽数。通常,可用的槽越多,您可以运行的并发查询就越多,并且复杂查询可以运行得更快。
按需价格和基于容量的价格
虽然所有查询都会使用槽,但您可以选择两种使用量收费方式:按需价格模式或基于容量的价格模式。
默认情况下,系统会采用按需模式向您收取费用。使用此模式时,您需要为每个查询处理的数据量(以 TiB 为单位)付费。采用按需价格模式的项目受每个项目和每个组织的槽限制的约束,且具有瞬时突发功能。对于大多数采用按需模式的用户而言,槽容量限制绰绰有余。不过,根据工作负载的情况,可用的槽越多,查询性能也就越高。如需查看账号的槽用量,请参阅监控健康状况、资源利用率和作业。
采用基于容量的模式,您需要为分配给查询的槽容量支付费用。此模式可让您明确控制总槽容量。您可以通过预留明确选择要使用的槽数。您可以将预留中的槽数指定为始终分配的基准量,也可以指定为在需要时分配的自动扩缩量。具有自动扩缩槽的预留会扩缩其容量,以满足您的工作负载需求。BigQuery 会随着工作负载的变化而分配槽。这样一来,您就可以根据使用预留的工作负载的性能或关键程度来配置预留中的槽数。
使用槽执行查询
BigQuery 在执行查询作业时,会将 SQL 语句转换为执行计划,该计划由一系列查询阶段组成。阶段又由一组执行步骤组成。 BigQuery 使用分布式并行架构来运行查询。阶段会对可并行执行的工作单元进行建模。各阶段之间的数据传递通过分布式 Shuffle 架构实现,这篇Cloud de Confiance by S3NS 博文更详细地介绍了该架构。
BigQuery 查询执行过程是动态的。在处理查询时,可以修改查询计划。随着阶段的添加,可以针对数据分布优化工作分配。此外,随着其他查询的开始或结束,或者随着自动扩缩器向预留添加槽,查询执行的容量也会发生变化。
BigQuery 可以并发运行多个阶段,可以使用推测性执行技术来加速查询,并可动态地重新划分阶段以实现最佳并行性。
槽资源不足
如果查询请求的槽数超过可用的槽数,BigQuery 会将个别工作单元排入队列,并等待槽变为可用状态。随着查询继续执行以及槽被释放,系统会动态地选取这些已排入队列的工作单元用于执行。
BigQuery 可以为查询的特定阶段请求任意数量的槽。所请求的槽数与您购买的容量无关,而是指示 BigQuery 为该阶段选择的最佳并行化因子。工作单元会排入队列并在有可用的槽时执行。
如果查询所需的槽数超出了您承诺使用的槽数,系统不会向您收取额外槽的费用,也不会根据额外的按需使用费率收取相关费用。您的各个工作单元会排队等候。
例如,
- 查询阶段请求 2000 个槽,但只有 1000 个槽可用。
- BigQuery 会将 1000 个可用槽全部占用,并将另外 1000 个槽排入队列。
- 此后,如果有 100 个槽完成了其工作,那么这些槽会从 1000 个已排入队列的工作单元中动态选取 100 个工作单元。其余的 900 个已排入队列的工作单元继续保留。
- 此后,如果有 500 个槽完成了其工作,那么这些槽会从 900 个已排入队列的工作单元中动态选取 500 个工作单元。其余的 400 个已排入队列的工作单元继续保留。

如果工作负载需要的槽数超过了预留可用的槽数,作业运行时长可能会增加,因为作业需要等待槽变为可用状态。这称为“槽争用”。如果工作负载需求远大于预留可用的槽,槽争用可能会加剧。
容量优先级
当 BigQuery 在特定区域对槽资源的需求较高时,它会通过优先分配容量来管理资源争用。这种优先级划分可确保采用更高级别容量模型的客户受到的影响更小。系统会按以下顺序确定容量优先级:
- 企业 Plus 版和企业版基准和承诺容量。
- 企业 Plus 版自动扩缩容量。
- 企业版自动扩缩容量。
- 标准版和按需容量。
如果某个区域出现资源争用,标准版和按需容量请求更可能遇到访问延迟,因为系统会先为更高级别的版本分配资源。
BigQuery 公平调度机制
BigQuery 使用一种称为公平调度的算法在单个预留中分配槽容量。
BigQuery 调度器会强制先在一个预留中正在运行的查询所属的各项目之间均匀共享槽,然后再在给定项目的作业内进行共享。调度器提供最终公平性。在短时间内,某些作业可能会获得不成比例的槽,但调度器最终会纠正此情况。调度器的目标是在主动逐出正在运行的任务(导致浪费槽时间)和过于宽松的逐出(导致包含长时间运行的任务的作业获得不成比例的槽时间)之间找到平衡点。
公平调度可以确保所有查询都可以随时访问所有可用槽,并且系统可以自动根据每个活跃查询的容量需求变化在这些查询之间动态地重新分配容量。在以下情况下,您可以在查询完成后提交新的查询来执行:
- 只要您提交新的查询,系统就会自动在各执行中查询之间重新分配容量。当每个查询的可用容量增加时,个别工作单元可以正常暂停、恢复及排入队列。
- 每当有查询完成时,该查询使用的容量都会自动立即提供给其他所有查询使用。
- 只要查询的容量需求因查询动态 DAG 的更改而发生变化,BigQuery 就会自动重新评估此查询和其他所有查询的可用容量,并根据需要重新分配和暂停槽。

根据查询的复杂性和大小,查询可能并不需要其有权使用的所有槽,也可能需要使用更多的槽。在公平调度机制的作用下,BigQuery 会动态地确保所有槽在任何时间点都会得到充分利用。
如果某个重要的作业需要的槽数始终比它从调度器接收到的槽数多,请考虑创建一个具有所需槽数的额外预留,并将该作业分配给该预留。
下面以公平调度为例,假设您有以下预留配置:
- 预留
A,具有 1,000 个基准槽,没有自动扩缩功能 - 已分配到您的预留的项目
A和项目B
情形 1:在项目 A 中,您运行需要高槽使用率的查询 A(一个并发查询);在项目 B 中,您运行 20 个并发查询。即使总共有 21 个查询在使用预留 A,槽分布如下:
- 项目
A获得 500 个槽,查询A使用 500 个槽运行。 - 项目
B获得 500 个槽,供其 20 个查询共同使用。
情形 2:在项目 A 中,您运行需要 100 个槽的查询 A(一个并发查询);在项目 B 中,您运行 20 个并发查询。由于查询 A 不需要 50% 的预留,因此槽分配如下:
- 项目
A获得 100 个槽,查询A使用 100 个槽运行。 - 项目
B获得 900 个槽,供其 20 个查询共同使用。
反之,请考虑以下预留配置:
- 预留
B,具有 1,000 个基准槽,没有自动扩缩功能。 - 10 个项目,全部分配给预留
B。
假设这 10 个项目正在运行的查询有足够的槽需求,那么无论每个项目正在运行多少个查询,每个项目都会获得总预留槽数的 1/10(即 100 个槽)。
Slot 配额和限制
槽配额和限制可为 BigQuery 提供安全保障。不同的定价模式使用不同的槽配额类型,如下所示:
按需价格模式:您受每个项目和组织的槽限制的约束,且具有瞬时突发功能。根据工作负载的情况,可用的槽越多,查询性能也就越高。
基于容量的价格模式:预留配额和限制定义了您可以在一个位置的所有预留中分配的槽数上限。如果您使用自动扩缩功能,则预留大小上限的总和不得超出此限制。您只需为预留和承诺付费,无需为配额付费。 如需了解如何增加槽配额,请参阅申请增加配额。
如需查看您使用的槽数,请参阅 BigQuery 监控。
空闲槽
在任何给定时间,某些槽都可能处于空闲状态。这可能包括:
- 未分配给任何预留基准的槽承诺。
- 分配给预留基准但未使用的槽。
使用按需价格模式时,空闲槽不适用。
默认情况下,在预留中运行的查询自动使用来自同一区域和管理项目中的其他预留的空闲槽。当需要空闲槽时,BigQuery 会立即将其分配给指定的预留。如果原始预留需要,系统会快速抢占其他预留正在使用的空闲槽。您可能会在短时间内看到所有预留的总槽消耗量超过您指定的最大值,但我们不会针对这部分额外的槽用量向您收费。
例如,假设您有以下预留设置:
project_a分配给reservation_a,后者有 500 个基准槽,但没有自动扩缩功能。project_b分配给reservation_b,后者有 100 个基准槽,但没有自动扩缩功能。- 这两个预留位于同一区域和管理项目中,并且没有其他项目分配给这些预留。
您在 project_b 中运行 query_b。如果 project_a 中没有运行任何查询,则 query_b 可以使用 reservation_a 中的 500 个空闲槽。在 query_b 仍在运行时,它最多可能会使用 600 个槽:100 个基准槽加上 500 个空闲槽。
假设在 query_b 运行时,您在 project_a 中运行 query_a,该 project_a 可以使用 500 个槽。
- 由于您为
project_a预留了 500 个基准槽,因此query_a会立即启动并分配到 500 个槽。 - 分配给
query_b的槽数快速减少到 100 个基准槽。 - 在
project_b中运行的其他查询会共享这 100 个槽。如果后续查询没有足够的槽来启动,则它们会排队,直到正在运行的查询完成并且有槽可用为止。
在此示例中,如果 project_b 被分配给没有基准槽或自动扩缩的预留,则在 query_a 开始运行后,query_b 将没有槽。BigQuery 会暂停 query_b,直到有空闲槽可用或查询超时。project_b 中的其他查询会排队,直到有空闲槽可用。
为确保预留仅使用预配的槽,请将 ignore_idle_slots 设置为 true。ignore_idle_slots 设置为 true 的预留可以与其他预留共享其空闲槽。
您不能在不同版本的预留之间共享空闲槽。您只能共享基准槽或承诺槽。自动扩缩的槽可能暂时可用,但无法作为其他预留的空闲槽进行共享,因为它们可能会缩容。
只要 ignore_idle_slots 为 false,即使预留的槽数为 0,也仍然可以访问未使用的槽。如果您仅使用 default 预留,则最好关闭 ignore_idle_slots。然后,您可以向该预留分配项目或文件夹,并且它仅使用空闲槽。
ML_EXTERNAL 类型的分配例外,因为 BigQuery ML 外部模型创建作业使用的槽不是可抢占的。具有 ML_EXTERNAL 和 QUERY 分配类型的预留中的槽只有在未被 ML_EXTERNAL 作业占用情况下才能供其他查询作业使用。此外,这些作业无法使用其他预留中的空闲槽。
基于预留的公平性
借助基于预留的公平性,BigQuery 会优先处理同一管理项目中的所有预留,并为这些预留平均分配空闲槽,无论每个预留中有多少个项目正在运行作业。每个预留都会获得空闲槽池中类似比例的可用容量,然后其槽会在项目内均匀分配。此功能仅在企业版或企业 Plus 版中受支持。
下图显示了在未启用基于预留的公平性时,空闲槽的分配方式:

在此图表中,空闲槽在各个项目之间平均分配。
如果未启用基于预留的公平性,则可用的空闲槽会在预留中的项目之间均匀分配。
下图显示了在启用基于预留的公平性后,空闲槽的分配方式:

在此图表中,空闲槽在预留之间平均分配,而不是在项目之间平均分配。
启用基于预留的公平性后,可用的空闲槽会在各个预留之间平均分配。
启用基于预留的公平性后,请查看资源消耗情况,以便管理槽可用性和查询性能。
对于时间要求严格的生产工作负载,请避免仅依赖空闲槽,这些作业必须使用基准槽或自动扩缩槽。我们建议将空闲槽用于优先级较低的作业,因为这些槽可随时被抢占。
槽自动扩缩
以下部分讨论了自动扩缩槽以及它们如何与预留搭配使用。
使用自动扩缩预留
您无需在创建自动扩缩预留之前购买槽承诺。槽用量承诺可以为持续使用的槽提供折扣费率,但可选配自动扩缩预留。如需创建自动扩缩预留,请为预留分配槽数上限(预留大小上限)。您可以通过将预留大小上限减去分配给预留的任何可选基准槽来确定自动扩缩槽数上限。
创建自动扩缩预留时,请考虑以下事项:
- BigQuery 几乎可以即时扩容预留,直到达到执行作业所需的槽数,或者达到预留可用的槽数上限。槽始终会自动扩缩到 50 的倍数。
- 纵向扩容基于实际用量,并向上取整到最接近的 50 个槽增量。
- 在纵向扩容时,您的自动扩缩槽将按关联版本的容量计算价格付费。您需要按扩缩的槽数付费,而不是按使用的槽数付费。即使导致 BigQuery 纵向扩容的作业失败,您也需要支付此费用。 因此,请勿使用作业信息架构来匹配结算信息。请改为参阅使用信息架构监控自动扩缩。
- 虽然槽数始终按 50 的倍数进行扩容,但只需一步即可扩容超过 50 个槽。例如,如果您的工作负载需要额外的 450 个槽,BigQuery 可以尝试一次性扩容到 450 个槽来满足容量要求。
- 当与预留关联的作业不再需要该容量时(最少 1 分钟),BigQuery 会纵向缩容。
任何自动扩缩的容量都会保留至少 60 秒。这 60 秒的时间段称为纵向缩容时段。容量出现任何新峰值都会重置纵向缩容时段,并将整个容量级别视为新的授权。但是,如果自上次容量增加以来超过 60 秒或更长时间且需求减少,则系统会在不重置纵向缩容时段的情况下减少容量,从而实现连续减少,而不会强制延迟。
例如,如果您的初始工作负载容量扩容到 100 个槽位,则峰值至少会保留 60 秒。如果在缩减窗口期间,您的工作负载缩减到 200 个槽位的新的峰值,则会开始新的缩减窗口,持续 60 秒。如果在此缩减窗口期间没有出现新的峰值,您的工作负载将在 60 秒结束时开始缩减。
请考虑以下详细示例:在 12:00:00,您的初始容量扩容到 100 个槽位,且用量持续 1 秒。该峰值将至少保留 60 秒,从 12:00:00 开始。60 秒后(12:01:01),如果新用量为 50 个槽位,BigQuery 会缩减到 50 个槽位。如果在 12:01:02 时,新用量为 0 个槽位,BigQuery 会再次立即缩减到 0 个槽位。缩减窗口结束后,BigQuery 可以连续多次缩减,而无需新的缩减窗口。
如需了解如何使用自动扩缩功能,请参阅使用自动扩缩槽。
将预留与基准槽和自动扩缩槽搭配使用
除了指定预留大小上限之外,您还可以选择为每个预留指定基准槽数。基准是始终分配给预留的槽数下限,您始终需要为这些槽付费。只有在使用所有基准槽(以及空闲槽 [如果适用])后,系统才会添加自动扩缩槽。您可以将一项预留中的空闲基准槽与需要容量的其他预留共享。
您可以每隔几分钟增加一次预留中的基准槽。如果您想减少基准槽,并且您最近更改了基准槽容量,而且您的基准槽超过了承诺的槽,则每小时只能减少一次。否则,您可以每隔几分钟减少一次基准槽。
基准槽和自动扩缩槽旨在根据您的近期工作负载提供容量。如果您预计工作负载会出现很大变化,与近期的工作负载大不相同,我们建议您在事件发生之前增加基准容量,而不是依赖自动扩缩槽来覆盖工作负载容量。如果您在增加基准容量时遇到问题,请等待 15 分钟后重试请求。
如果预订没有基准槽或未配置为从其他预留借用空闲槽,则 BigQuery 会尝试进行扩缩。 否则,必须先充分利用基准槽,然后才能进行扩缩。
预留按照以下优先级使用和添加槽:
- 基准槽。
- 空闲槽共享(如果已启用)。预留只能共享具有同一版本和同一区域的其他预留的空闲基准槽或已提交槽。
- 自动扩缩槽。
在以下示例中,槽数从指定的基准数量进行扩缩。etl 和 dashboard 预留的基准大小分别为 700 个和 300 个槽。
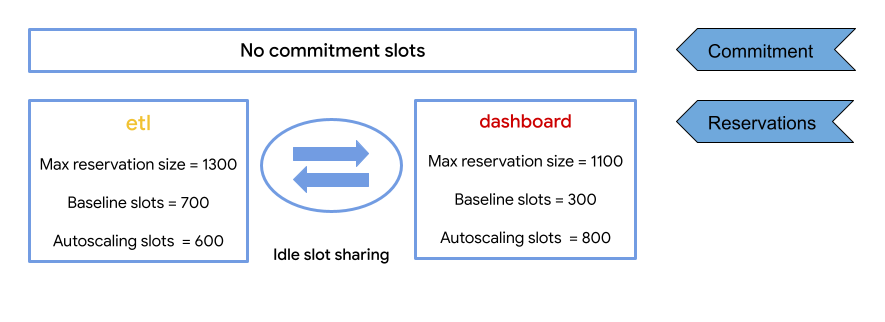
在此示例中,etl 预留可以扩容到 1,300 个槽(700 个基准槽加上 600 个自动扩缩槽)。如果 dashboard 预留未使用,则 etl 预留可以使用 dashboard 预留中的 300 个槽(如果没有作业在其中运行),最多可以使用 1600 个槽。
dashboard 预留可以扩容到 1,100 个槽(300 个基准槽加上 800 个自动扩缩槽)。如果 etl 预留完全空闲,则 dashboard 预留最多可扩容到 1800 个槽(300 个基准槽加上 800 个自动扩缩槽,再加上 etl 预留中的 700 个空闲槽)。
如果 etl 预留需要 700 个以上的基准槽(始终可用),则它会尝试使用以下方法按顺序添加槽:
- 700 个基准槽。
- 与
dashboard预留中的 300 个基准槽共享的空闲槽。您的预留仅会与使用相同版本创建的其他预留共享空闲基准槽。 - 将额外 600 个槽纵向扩容到预留大小上限。
使用槽承诺
以下示例展示了如何使用容量承诺自动扩缩槽。
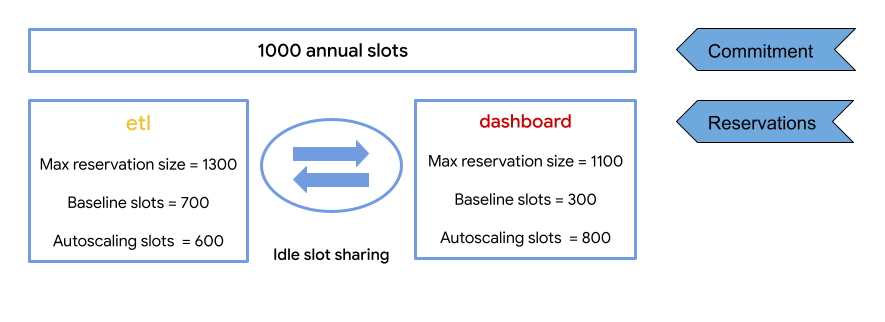
与预留基准一样,槽承诺可让您分配固定数量的槽以供所有预留使用。与基准槽不同的是,在相应期限内,承诺不能减少。槽承诺是可选的,但如果长期需要基准槽,则可以节省费用。槽用量承诺用于涵盖预留的基准槽。然后,所有未使用的槽容量将作为空闲槽在其他预留之间共享。槽承诺量不适用于自动扩缩槽。为确保您获得承诺槽的折扣价,请确保您的槽承诺足以覆盖您的基准槽。
在此示例中,您需要按容量承诺槽的预定义费率付费。在自动扩缩激活并且预留处于升级状态后,您需要按自动扩缩费率为自动扩缩槽数付费。 对于自动扩缩费率,您需要按照扩缩的槽数付费,而不是按使用的槽数付费。
以下示例展示了在基准槽数超过承诺槽数时的预留。

在此示例中,两个预留总共包含 1000 个基准槽,其中 etl 预留包含 500 个基准槽,dashboard 预留包含 500 个基准槽。不过,承诺仅涵盖 800 个槽。在此情况下,超额槽会按照随用随付 (PAYG) 费率收费。
可用槽数上限
如需计算预留可以使用的最大槽数,您可以把基准槽数、最大自动扩缩槽数以及使用相同版本创建但未被基准槽覆盖的承诺中的所有槽数相加。上图中的示例设置如下:
- 每年 1000 个槽的容量承诺。这些槽会作为
etl预留和dashboard预留中的基准槽进行分配。 - 分配给
etl预留的 700 个基准槽。 - 分配给
dashboard预留的 300 个基准槽。 - 为
etl预留设置 600 个自动扩缩槽。 - 为
dashboard预留设置 800 个自动扩缩槽。
对于 etl 预留,可能的槽数上限等于 etl 基准槽 (700) 加上 dashboard 基准槽(如果所有槽都处于空闲状态,则为 300 个)加上自动扩缩槽数上限 (600)。因此,在此示例中,etl 预留可以使用的槽数上限为 1,600。此数量超过容量承诺中的槽数。
在以下示例中,年度承诺超出分配的基准槽数。
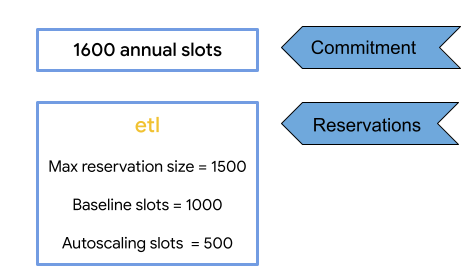
此示例包含:
- 每年 1600 个槽的容量承诺。
- 预留大小上限为 1,500(包括 500 个自动扩缩槽)。
- 分配给
etl预留的 1,000 个基准槽。
预留可用的槽数上限等于基准槽 (1,000) 加上任何不专用于基准槽的承诺空闲槽(1600 个年度槽 - 1,000 个基准槽 = 600 个槽),再加上自动扩缩槽 (500)。因此,此预留中的最大潜在槽数为 2100。自动扩缩槽是指超出容量承诺之外的额外槽。
自动扩缩最佳实践
首次使用自动扩缩器时,请根据过去的性能和预期的性能将自动扩缩槽数设置为有意义的数字。创建预留后,请主动监控失败率、性能和账单,并根据需要调整自动扩缩槽的数量。
自动扩缩器在纵向缩容之前至少需要 1 分钟的时间,因此请务必设置自动扩缩槽的数量上限,以便在性能和费用之间取得平衡。如果自动扩缩槽数上限过大,并且您的作业可以使用所有槽来在几秒钟内完成作业,那么您仍需要为完整分钟的最大槽数付费。如果将槽数上限降低到当前数量的一半,则预留会缩减到较小的数字,并且作业可以在该分钟内使用更多
slot_seconds,从而减少浪费。如需有关确定槽要求方面的帮助,请参阅监控作业性能。如需了解确定槽要求的替代方法,请参阅查看版本槽建议。槽用量有时可能会超过基准槽数和扩缩的槽数之和。您不需要为超过基准槽数和扩缩的槽数的槽用量付费。
自动扩缩器最适合长时间运行的高负荷工作负载,例如具有多个并发查询的工作负载。 请避免一次发送一个查询,因为每个查询都会扩缩预留,使其至少保持 1 分钟。如果您持续发送查询,使工作负载保持不变,则设置基准并购买承诺可按折扣价格提供稳定的容量。
BigQuery 自动扩缩功能受容量可用性的限制。BigQuery 会尝试根据历史用量来满足客户容量需求。如需实现容量保证,您可以设置可选的槽基准,即预留中保证的槽数。设置基准后,槽会立即可用。无论您是否使用这些槽,都需要支付其费用。为确保产生非自然的大量需求(例如高流量节假日)时有容量可用,请提前数周与 BigQuery 团队联系。
基准槽始终都会收费。如果容量承诺到期,您可能需要手动调整预留中的基准槽数,以免产生任何不必要的费用。例如,假设您的 1 年期承诺包含 100 个槽,一个预留包含 100 个基准槽。承诺会到期,并且没有续订套餐。承诺使用合约到期后,您需要按随用随付费率支付 100 个基准槽的费用。
监控自动扩缩
如需了解如何监控自动扩缩功能下的槽使用情况和作业性能,请参阅监控自动扩缩。
槽用量过高
如果作业占用槽的时间过长,可能会获得不公平的槽份额。为防止延迟,BigQuery 允许其他作业借用额外的槽,从而导致总槽使用量在一段时间内超过您指定的槽容量。任何超额槽用量都仅归因于获得超过其公平份额的作业。
超额槽不会直接向您收取费用。相反,作业会继续运行,并以公平份额累积槽使用量,直到所有超额使用量都由您分配的容量覆盖为止。报告的槽使用情况中不包含超额槽,但某些详细的执行统计信息除外。
请注意,有时系统会预先借用一些槽,以减少未来的延迟,并提供其他好处,例如降低槽成本变异性以及缩短尾部延迟时间。槽借用仅限于您总槽容量的一小部分。