
עבודה עם פונקציות בהגדרת המשתמש ב-Python
פונקציה בהגדרת המשתמש (UDF) ב-Python מאפשרת להטמיע פונקציה סקלרית ב-Python ולהשתמש בה בשאילתת SQL. פונקציות מוגדרות על ידי המשתמש ב-Python דומות לפונקציות מוגדרות על ידי המשתמש ב-SQL וב-JavaScript, אבל יש להן יכולות נוספות. פונקציות UDF ב-Python מאפשרות לכם להתקין ספריות של צד שלישי מ-Python Package Index (PyPI) ולגשת לשירותים חיצוניים באמצעות קישור למשאבים ב-Cloud.
פונקציות UDF ב-Python נוצרות ומופעלות במשאבים מנוהלים של BigQuery.
מגבלות
-
python-3.11היא סביבת זמן הריצה היחידה שנתמכת. - אי אפשר ליצור פונקציה זמנית מוגדרת על ידי המשתמש (UDF) ב-Python.
- אי אפשר להשתמש בפונקציה מוגדרת על ידי המשתמש (UDF) בשפת Python עם תצוגה מגובה בחומר.
- התוצאות של שאילתה שקוראת לפונקציית Python UDF לא נשמרות במטמון, כי ערך ההחזרה של פונקציית Python UDF תמיד נחשב כלא דטרמיניסטי.
- אין תמיכה ב-Assured Workloads.
- סוגי הנתונים הבאים לא נתמכים:
JSON,RANGE,INTERVALו-GEOGRAPHY. - אפשר להגדיר קונטיינרים שמריצים פונקציות מוגדרות על ידי המשתמש (UDF) ב-Python עד 4 vCpu ו-16 GiB.
- אין תמיכה בהצפנת קוד של פונקציות מוגדרות על ידי המשתמש (UDF) ב-Python באמצעות מפתחות הצפנה בניהול הלקוח (CMEK).
- פונקציות UDF ב-Python תומכות ב-VPC Service Controls, אבל לא תומכות ברשתות VPC.
התפקידים הנדרשים
תפקידי ה-IAM הנדרשים תלויים בשאלה אם אתם הבעלים של UDF ב-Python או משתמשים ב-UDF ב-Python.
בעלי פונקציות UDF
בדרך כלל, הבעלים של פונקציית UDF ב-Python יוצר או מעדכן את הפונקציה. נדרשים תפקידים נוספים גם אם יוצרים פונקציית UDF ב-Python שמפנה לחיבור למשאב ב-Cloud.
החיבור הזה נדרש רק אם ה-UDF משתמש בסעיף WITH CONNECTION כדי לגשת לשירות חיצוני.
כדי לקבל את ההרשאות שדרושות ליצירה או לעדכון של פונקציה מוגדרת על ידי המשתמש (UDF) ב-Python, צריך לבקש מהאדמין להקצות לכם את תפקידי ה-IAM הבאים:
- עריכה של נתוני BigQuery (
roles/bigquery.dataEditor) במערך הנתונים - BigQuery Job User (
roles/bigquery.jobUser) בפרויקט - BigQuery Connection Admin (
roles/bigquery.connectionAdmin) on the project
להסבר על מתן תפקידים, ראו איך מנהלים את הגישה ברמת הפרויקט, התיקייה והארגון.
התפקידים המוגדרים מראש האלה מכילים את ההרשאות שנדרשות ליצירה או לעדכון של פונקציית UDF ב-Python. כדי לראות בדיוק אילו הרשאות נדרשות, אפשר להרחיב את הקטע ההרשאות הנדרשות:
ההרשאות הנדרשות
כדי ליצור או לעדכן פונקציה מוגדרת על ידי המשתמש (UDF) ב-Python, נדרשות ההרשאות הבאות:
-
יוצרים פונקציה מוגדרת על ידי המשתמש (UDF) ב-Python באמצעות ההצהרה
CREATE FUNCTION:bigquery.routines.createבמערך הנתונים -
כדי לעדכן פונקציה מוגדרת על ידי המשתמש (UDF) ב-Python, משתמשים בהצהרה
CREATE FUNCTION:bigquery.routines.updateon the dataset -
הרצת משימת שאילתה של הצהרה
CREATE FUNCTION:bigquery.jobs.createבפרויקט -
יוצרים קישור חדש למשאבים ב-Cloud:
bigquery.connections.createבפרויקט -
שימוש בחיבור בהצהרת
CREATE FUNCTION:bigquery.connections.delegateon the connection
יכול להיות שתקבלו את ההרשאות האלה באמצעות תפקידים בהתאמה אישית או תפקידים מוגדרים מראש אחרים.
מידע נוסף על תפקידים ב-BigQuery זמין במאמר תפקידים מוגדרים מראש ב-IAM.
משתמשי UDF
משתמש ב-Python UDF מפעיל UDF שנוצר על ידי מישהו אחר. נדרשים גם תפקידים נוספים אם מפעילים פונקציית UDF של Python שמפנה לחיבור למשאב Cloud.
כדי לקבל את ההרשאות שדרושות להפעלת פונקציית UDF ב-Python שנוצרה על ידי מישהו אחר, צריך לבקש מהאדמין להקצות לכם את תפקידי ה-IAM הבאים:
- BigQuery User (
roles/bigquery.user) בפרויקט - BigQuery Data Viewer (
roles/bigquery.dataViewer) במערך הנתונים - BigQuery Connection User (
roles/bigquery.connectionUser) on the connection
להסבר על מתן תפקידים, ראו איך מנהלים את הגישה ברמת הפרויקט, התיקייה והארגון.
התפקידים המוגדרים מראש האלה מכילים את ההרשאות שנדרשות להפעלת פונקציית UDF של Python שנוצרה על ידי מישהו אחר. כדי לראות בדיוק אילו הרשאות נדרשות, אפשר להרחיב את הקטע ההרשאות הנדרשות:
ההרשאות הנדרשות
כדי להפעיל פונקציית UDF ב-Python שנוצרה על ידי מישהו אחר, נדרשות ההרשאות הבאות:
-
כדי להריץ עבודת שאילתה שמפנה ל-UDF ב-Python:
bigquery.jobs.createבפרויקט -
כדי להפעיל פונקציית UDF ב-Python שנוצרה על ידי מישהו אחר:
bigquery.routines.getבמערך הנתונים -
כדי להריץ פונקציית UDF של Python שמפנה לקישור למשאבים ב-Cloud:
bigquery.connections.useבקישור
יכול להיות שתקבלו את ההרשאות האלה באמצעות תפקידים בהתאמה אישית או תפקידים מוגדרים מראש אחרים.
מידע נוסף על תפקידים ב-BigQuery זמין במאמר תפקידים מוגדרים מראש ב-IAM.
יצירת פונקציה מתמידה מוגדרת על ידי המשתמש (UDF) ב-Python
כשיוצרים פונקציית UDF ב-Python, צריך לפעול לפי הכללים הבאים:
הגוף של פונקציית Python UDF חייב להיות מחרוזת מילולית בתוך מרכאות שמייצגת את קוד Python. מידע נוסף על פורמטים של מחרוזות ליטרליות במירכאות
גוף הפונקציה המוגדרת על ידי המשתמש ב-Python חייב לכלול פונקציית Python שמשמשת בארגומנט
entry_pointברשימת האפשרויות של הפונקציה המוגדרת על ידי המשתמש ב-Python.צריך לציין גרסת זמן ריצה של Python באפשרות
runtime_version. גרסת זמן הריצה היחידה של Python שנתמכת היאpython-3.11. רשימה מלאה של האפשרויות הזמינות מופיעה ברשימת האפשרויות של הפונקציה עבור ההצהרהCREATE FUNCTION.
כדי ליצור פונקציית UDF מתמשכת ב-Python, משתמשים בהצהרה CREATE FUNCTION בלי מילות המפתח TEMP או TEMPORARY. כדי למחוק פונקציית Python UDF מתמידה, משתמשים בהצהרה DROP FUNCTION.
דוגמה
כדי לראות דוגמה ליצירת פונקציית UDF מתמשכת ב-Python, בוחרים באחת מהאפשרויות הבאות:
המסוף
בדוגמה הבאה נוצרת פונקציה מתמידה בשפת Python בשם multiplyInputs, והפונקציה נקראת מתוך הצהרת SELECT:
עוברים לדף BigQuery.
בעורך השאילתות, מזינים את ההצהרה הבאה של
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyInputs(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS(runtime_version="python-3.11", entry_point="multiply") AS r''' def multiply(x, y): return x * y '''; -- Call the Python UDF. WITH numbers AS (SELECT 1 AS x, 5 as y UNION ALL SELECT 2 AS x, 10 as y UNION ALL SELECT 3 as x, 15 as y) SELECT x, y, `PROJECT_ID.DATASET_ID`.multiplyInputs(x, y) AS product FROM numbers;
החלפה של PROJECT_ID.DATASET_ID במזהה הפרויקט ובמזהה מערך הנתונים.
לוחצים על הפעלה.
הדוגמה הזו יוצרת את הפלט הבא:
+-----+-----+--------------+ | x | y | product | +-----+-----+--------------+ | 1 | 5 | 5.0 | | 2 | 10 | 20.0 | | 3 | 15 | 45.0 | +-----+-----+--------------+
BigQuery DataFrames
בדוגמה הבאה נעשה שימוש ב-BigQuery DataFrames כדי להפוך פונקציה מותאמת אישית ל-UDF של Python:
סטטוס ה-build של הקונטיינר
כשיוצרים פונקציה מוגדרת על ידי המשתמש (UDF) ב-Python באמצעות ההצהרה CREATE FUNCTION, BigQuery יוצר או מעדכן קובץ אימג' של קונטיינר שמבוסס על קובץ אימג' בסיסי. הקונטיינר נוצר על בסיס תמונת הבסיס באמצעות הקוד שלכם ותלות החבילות שצוינו.
יצירת הקונטיינר היא תהליך ארוך. השאילתה הראשונה אחרי שמריצים את ההצהרה CREATE FUNCTION מחכה עד ש-build התמונה מסתיים. אם אין תלות חיצונית, בדרך כלל קובץ אימג' של קונטיינר נוצר תוך פחות מדקה.
הגודל של כל קובצי ה-UDF של Python בכל פרויקט ובכל אזור מוגבל לסכום כולל של 10GiB. מידע נוסף זמין במאמר בנושא מגבלות על פונקציות בהגדרת משתמש (UDF) עבור פונקציות מתמידות בהגדרת משתמש. אם הפרויקט הגיע למכסה, ה-build של הקונטיינר ייכשל.
כדי לראות את הסטטוס של בניית מאגר התגים, בוחרים באחת מהאפשרויות הבאות:
המסוף
עוברים לדף Studio ב-BigQuery.
בחלונית הימנית, מרחיבים את הפרויקט ואז לוחצים על Datasets (מערכי נתונים).
לוחצים על הקישור כדי לפתוח את מערך הנתונים שמכיל את פונקציית ה-UDF של Python.
בדף של מערך הנתונים, לוחצים על הכרטיסייה שגרות.
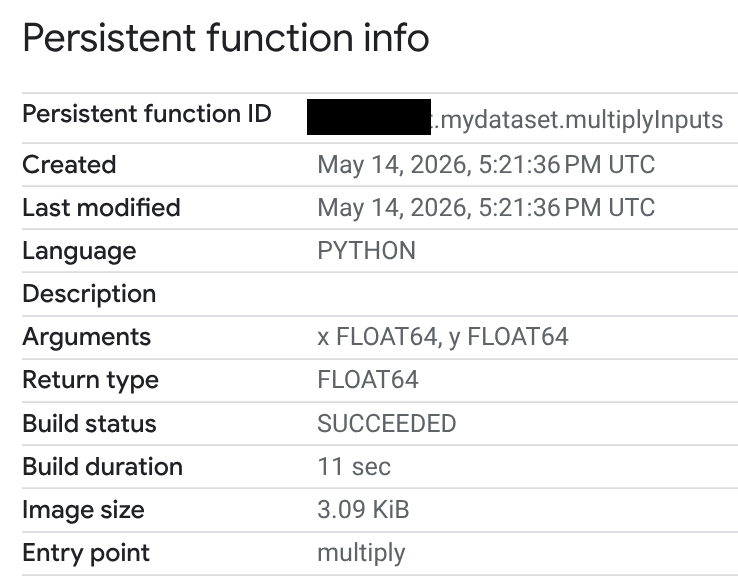
בעמודה Routine ID, לוחצים על פונקציית Python UDF.
בדף Persistent function info (מידע על פונקציה מתמשכת) אפשר לראות את סטטוס הבנייה, משך הבנייה וגודל התמונה. סטטוס הבנייה הוא אחד מהבאים:
- בתהליך
- הושלמה
- נכשל
אם בנייה נכשלת, בדף המידע של הפונקציה מופיעות הודעות שגיאה מפורטות, כדי שתוכלו לפתור בעיות כמו שגיאות תחביר או בעיות בהתקנת חבילות חיצוניות.
SQL
כדי לשלוח שאילתה לשדות של סטטוס הבנייה בתצוגה INFORMATION_SCHEMA.ROUTINES, פועלים לפי השלבים הבאים:
עוברים לדף Studio ב-BigQuery.
עוברים לעורך השאילתות או לוחצים על שאילתת SQL.
מזינים את השאילתה הבאה כדי לאחזר את השדות
BUILD_STATUSמהתצוגהINFORMATION_SCHEMA.ROUTINES. העמודהBUILD_STATUSהיא מסוגSTRUCTב-GoogleSQL:SELECT build_status.* FROM `PROJECT_ID.DATASET_ID`.INFORMATION_SCHEMA.ROUTINES;החלפה של PROJECT_ID.DATASET_ID במזהה הפרויקט ובמזהה מערך הנתונים.
הפלט אמור להיראות כך: השדות של השגיאות מושמטים:
+---------------+--------------------------------+------------------------+------------------+ | build_state | build_state_update_time | build_duration_seconds | image_size_bytes | +---------------+--------------------------------+------------------------+------------------+ | SUCCEEDED | 2026-05-14 17:21:49.736000 UTC | 11 | 3167 | +---------------+--------------------------------+------------------------+------------------+
API
אפשר להציג את סטטוס בניית הקונטיינר באמצעות RoutineBuildStatus ב-API.
יצירת פונקציה מוגדרת על ידי המשתמש (UDF) ב-Python עם וקטוריזציה
אפשר להטמיע את פונקציית ה-UDF של Python כדי לעבד קבוצה של שורות במקום שורה אחת, באמצעות וקטוריזציה. הפיכת נתונים לווקטורים יכולה לשפר את ביצועי השאילתות. אפשר ליצור פונקציה בהגדרת המשתמש (UDF) עם וקטוריזציה באמצעות Pandas או Apache Arrow.
כדי לשלוט בהתנהגות של העיבוד באצווה, מציינים את המספר המקסימלי של שורות בכל אצווה באמצעות האפשרות max_batching_rows ברשימת האפשרויות CREATE OR REPLACE FUNCTION. אם מציינים את max_batching_rows, BigQuery קובע את מספר השורות בחבילה, עד למגבלה של max_batching_rows.
אם לא מציינים את max_batching_rows, מספר השורות שיצורפו לחבילה נקבע באופן אוטומטי.
שימוש ב-Pandas
לפונקציית UDF וקטורית של Python יש ארגומנט יחיד pandas.DataFrame שחייב להיות עם הערה. לארגומנט pandas.DataFrame יש אותו מספר עמודות כמו לפרמטרים של פונקציית ה-UDF ב-Python שהוגדרו בהצהרה CREATE FUNCTION. לשמות העמודות בארגומנט pandas.DataFrame יש שמות זהים לפרמטרים של הפונקציה המוגדרת על ידי המשתמש.
הפונקציה צריכה להחזיר pandas.Series או pandas.DataFrame עם מספר שורות זהה למספר השורות של הקלט.
בדוגמה הבאה נוצרת פונקציית UDF וקטורית של Python בשם multiplyInputs עם שני פרמטרים – x ו-y:
עוברים לדף BigQuery.
בעורך השאילתות, מזינים את ההצהרה הבאה של
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyVectorized(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS(runtime_version="python-3.11", entry_point="vectorized_multiply") AS r''' import pandas as pd def vectorized_multiply(df: pd.DataFrame): return df['x'] * df['y'] ''';
החלפה של PROJECT_ID.DATASET_ID במזהה הפרויקט ובמזהה מערך הנתונים.
הקריאה לפונקציה UDF זהה לקריאה בדוגמה הקודמת.
לוחצים על הפעלה.
שימוש ב-Apache Arrow
בדוגמה הבאה נעשה שימוש בממשק RecordBatch של Apache Arrow. כשמשתמשים בממשק RecordBatch, הפונקציה מעבירה לנקודת הכניסה אצווה של שורות של עמודות באורך שווה.
בדוגמה הבאה נעשה שימוש ב-Apache Arrow כדי ליצור פונקציית UDF וקטורית של Python בשם multiplyVectorizedArrow.
עוברים לדף BigQuery.
בעורך השאילתות, מזינים את ההצהרה הבאה של
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyVectorizedArrow(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS( runtime_version="python-3.11", entry_point="vectorized_multiply_arrow" ) AS r''' import pyarrow as pa import pyarrow.compute as pc def vectorized_multiply_arrow(batch: pa.RecordBatch): # Access columns directly from the Arrow RecordBatch x = batch.column('x') y = batch.column('y') # Use pyarrow.compute for vectorized operations return pc.multiply(x, y) ''';
החלפה של PROJECT_ID.DATASET_ID במזהה הפרויקט ובמזהה מערך הנתונים.
הקריאה לפונקציה המוגדרת על ידי המשתמש זהה לדוגמאות הקודמות.
לוחצים על הפעלה.
קריאה לפונקציה מוגדרת על ידי המשתמש (UDF) ב-Python
אם יש לכם הרשאה להפעיל UDF של Python, אתם יכולים לקרוא לה כמו לכל פונקציה אחרת. כדי להשתמש בפונקציה שמוגדרת בפרויקט אחר, צריך להשתמש בשם המלא של הפונקציה. לדוגמה, כדי להפעיל פונקציה לחילוץ XML בשם cw_xml_extract בפרויקט אחר, מבצעים את השלבים הבאים.
המסוף
עוברים לדף BigQuery.
בעורך השאילתות, מזינים את הדוגמה הבאה:
SELECT `PROJECT_ID.DATASET_ID`.`cw_xml_extract`(xml, '//title/text()') AS `title` FROM UNNEST([ STRUCT('''<book id="1"> <title>The Great Gatsby</title> <author>F. Scott Fitzgerald</author> </book>''' AS xml), STRUCT('''<book id="2"> <title>1984</title> <author>George Orwell</author> </book>''' AS xml), STRUCT('''<book id="3"> <title>Brave New World</title> <author>Aldous Huxley</author> </book>''' AS xml) ])לוחצים על הפעלה.
הדוגמה הזו יוצרת את הפלט הבא:
+--------------------------+ | title | +--------------------------+ | The Great Gatsby | | 1984 | | Brave New World | +--------------------------+
BigQuery DataFrames
בדוגמה הבאה נעשה שימוש בשיטות BigQuery
DataFrames
sql_scalar,
read_gbq_function,
ו-apply כדי לקרוא ל-UDF של Python:
סוגי נתונים נתמכים של פונקציות מוגדרות על ידי המשתמש (UDF) ב-Python
בטבלה הבאה מוגדר המיפוי בין סוגי נתונים ב-BigQuery, סוגי נתונים ב-Python וסוגי נתונים ב-Pandas:
| סוג נתונים ב-BigQuery | סוג נתונים מובנה ב-Python שמשמש פונקציות מוגדרות על ידי המשתמש (UDF) | סוג הנתונים של Pandas שמשמש את פונקציית ה-UDF הווקטורית | סוג הנתונים של PyArrow שמשמש ל-ARRAY ול-STRUCT בפונקציות מוגדרות על ידי המשתמש (UDF) שעברו וקטוריזציה |
|---|---|---|---|
BOOL |
bool |
BooleanDtype |
DataType(bool) |
INT64 |
int |
Int64Dtype |
DataType(int64) |
FLOAT64 |
float |
FloatDtype |
DataType(double) |
STRING |
str |
StringDtype |
DataType(string) |
BYTES |
bytes |
binary[pyarrow] |
DataType(binary) |
TIMESTAMP |
פרמטר של פונקציה: ערך ההחזרה של הפונקציה: |
פרמטר של פונקציה: הערך המוחזר של הפונקציה: |
TimestampType(timestamp[us]), עם אזור זמן |
DATE |
datetime.date |
date32[pyarrow] |
DataType(date32[day]) |
TIME |
datetime.time |
time64[pyarrow] |
Time64Type(time64[us]) |
DATETIME |
datetime.datetime (ללא אזור זמן) |
timestamp[us][pyarrow] |
TimestampType(timestamp[us]), בלי אזור זמן |
ARRAY |
list |
list<...>[pyarrow], כאשר סוג הנתונים של הרכיב הוא pandas.ArrowDtype |
ListType |
STRUCT |
dict |
struct<...>[pyarrow], כאשר סוג הנתונים של השדה הוא pandas.ArrowDtype |
StructType |
גרסאות זמן ריצה נתמכות
פונקציות UDF ב-Python ב-BigQuery תומכות בסביבת זמן הריצה python-3.11. גרסת Python הזו כוללת כמה חבילות נוספות שהותקנו מראש. בספריות מערכת, בודקים את תמונת הבסיס של זמן הריצה.
| גרסת זמן ריצה | גרסת Python | כולל |
|---|---|---|
| python-3.11 | Python 3.11 | numpy 1.26.3 pyarrow 14.0.2 pandas 2.1.4 python-dateutil 2.8.2 absl-py 2.0.0 pytz 2023.3.post1 tzdata 2023.4 six 1.16.0 |
שימוש בחבילות של צד שלישי
אפשר להשתמש ברשימת האפשרויות CREATE FUNCTION כדי להשתמש במודולים אחרים מאלה שסופקו על ידי ספריית התקנים של Python וחבילות שהותקנו מראש.
אפשר להתקין חבילות מאינדקס החבילות של Python (PyPI), או לייבא קובצי Python מ-Cloud Storage.
התקנת חבילה מאינדקס חבילות Python
כשמתקינים חבילה, צריך לציין את שם החבילה, ואפשר גם לציין את גרסת החבילה באמצעות מצייני גרסאות של חבילות Python.
אם החבילה נמצאת בסביבת זמן הריצה, נעשה בה שימוש אלא אם צוינה גרסה מסוימת ברשימת האפשרויות של CREATE FUNCTION. אם לא מציינים גרסת חבילה, והחבילה לא נמצאת בסביבת זמן הריצה, המערכת משתמשת בגרסה העדכנית ביותר שזמינה. יש תמיכה רק בחבילות בפורמט הבינארי wheels.
בדוגמה הבאה אפשר לראות איך יוצרים פונקציית UDF ב-Python שמתקינה את חבילת scipy באמצעות רשימת האפשרויות CREATE OR REPLACE FUNCTION:
עוברים לדף BigQuery.
בעורך השאילתות, מזינים את ההצהרה הבאה של
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.area(radius FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS (entry_point='area_handler', runtime_version='python-3.11', packages=['scipy==1.15.3']) AS r""" import scipy def area_handler(radius): return scipy.constants.pi*radius*radius """; SELECT `PROJECT_ID.DATASET_ID`.area(4.5);
החלפה של PROJECT_ID.DATASET_ID במזהה הפרויקט ובמזהה מערך הנתונים.
לוחצים על הפעלה.
ייבוא קובצי Python נוספים כספריות
אפשר להרחיב את הפונקציות המוגדרות על ידי המשתמש ב-Python באמצעות רשימת האפשרויות של הפונקציה על ידי ייבוא קובצי Python מ-Cloud Storage.
בקוד Python של פונקציית UDF, אפשר לייבא את קובצי Python מ-Cloud Storage כמודולים באמצעות הצהרת הייבוא, ואחריה הנתיב לאובייקט Cloud Storage. לדוגמה, אם מייבאים את gs://BUCKET_NAME/path/to/lib1.py, הצהרת הייבוא תהיה import
path.to.lib1.
שם הקובץ ב-Python צריך להיות מזהה Python. כל שם של folder בשם האובייקט (אחרי /) צריך להיות מזהה תקין של Python. בטווח ASCII (U+0001..U+007F), אפשר להשתמש בתווים הבאים במזהים:
- אותיות רישיות וקטנות באנגלית, מ-A עד Z.
- קווים תחתונים.
- הספרות אפס עד תשע, אבל מספר לא יכול להופיע כתו הראשון במזהה.
בדוגמה הבאה מוצג איך ליצור פונקציית UDF ב-Python שמייבאת את חבילת ספריית הלקוח lib1.py מקטגוריה של Cloud Storage בשם my_bucket:
עוברים לדף BigQuery.
בעורך השאילתות, מזינים את ההצהרה הבאה של
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.myFunc(a FLOAT64, b STRING) RETURNS STRING LANGUAGE python OPTIONS ( entry_point='compute', runtime_version='python-3.11', library=['gs://BUCKET_NAME/PATH/lib1.py']) AS r""" import path.to.lib1 as lib1 def compute(a, b): # doInterestingStuff is a function defined in # gs://BUCKET_NAME/PATH/lib1.py return lib1.doInterestingStuff(a, b); """;
מחליפים את מה שכתוב בשדות הבאים:
- PROJECT_ID: מזהה הפרויקט.
- DATASET_ID: מזהה מערך הנתונים.
- BUCKET_NAME: השם של קטגוריית Cloud Storage שמכילה את
lib1.py. - PATH: הנתיב לקטגוריה של Cloud Storage.
לוחצים על הפעלה.
הגדרת מגבלות קונטיינר לפונקציות מוגדרות על ידי משתמש (UDF) ב-Python
אפשר להשתמש ברשימת האפשרויות CREATE FUNCTION כדי לציין את מגבלות המקבילות של בקשות לקונטיינרים שמריצים פונקציות Python UDF, מבחינת מעבד, זיכרון וקונטיינר.
כברירת מחדל, המשאבים הבאים מוקצים למאגרי תגים:
- הזיכרון שהוקצה הוא
512Mi. - המעבד שהוקצה הוא
1.0vCPU. - מגבלת הבו-זמניות (concurrency) של בקשות למאגר היא
80.
בדוגמה הבאה נוצרת פונקציה מוגדרת על ידי המשתמש (UDF) ב-Python באמצעות האפשרות CREATE FUNCTION list כדי לציין מגבלות של קונטיינר:
עוברים לדף BigQuery.
בעורך השאילתות, מזינים את ההצהרה הבאה של
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.square_area(length FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS (entry_point='square_area', runtime_version='python-3.11', container_memory='CONTAINER_MEMORY', container_cpu=CONTAINER_CPU, container_request_concurrency=CONTAINER_REQUEST_CONCURRENCY) AS r""" def square_area(length): return length*length """; SELECT `PROJECT_ID.DATASET_ID`.square_area(4.5);
מחליפים את מה שכתוב בשדות הבאים:
- PROJECT_ID.DATASET_ID: מזהה הפרויקט ומזהה מערך הנתונים.
- CONTAINER_MEMORY: ערך הזיכרון בפורמט הבא:
<integer_number><unit>. היחידה חייבת להיות אחת מהערכים הבאים:Mi(MiB),M(MB),Gi(GiB) אוG(GB). לדוגמה,2Gi. - CONTAINER_CPU: ערך ה-CPU. פונקציות UDF ב-Python תומכות בערכי מעבד חלקיים בין
0.33ל-1.0ובערכי מעבד לא חלקיים של1,2ו-4. - CONTAINER_REQUEST_CONCURRENCY: המספר המקסימלי של בקשות בו-זמניות לכל מופע של קונטיינר של פונקציה מוגדרת על ידי המשתמש (UDF) ב-Python. הערך צריך להיות מספר שלם בין
1ל-1000.
לוחצים על הפעלה.
ערכי מעבד נתמכים
פונקציות UDF ב-Python תומכות בערכי CPU חלקיים בין 0.33 ל-1.0 ובערכי CPU לא חלקיים של 1, 2 ו-4. אפשר להגדיר קונטיינרים שמריצים פונקציות מוגדרות על ידי המשתמש (UDF) ב-Python עד 4 vCpu. ערך ברירת המחדל הוא 1.0. ערכי קלט חלקיים מעוגלים לשתי ספרות אחרי הנקודה העשרונית לפני שהם מוחלים על מאגר התגים.
ערכי זיכרון נתמכים
קונטיינרים של פונקציות מוגדרות על ידי המשתמש ב-Python תומכים בערכי זיכרון בפורמט הבא:
<integer_number><unit>. היחידה צריכה להיות אחת מהערכים הבאים: Mi, M, Gi, G. כמות הזיכרון המינימלית שאפשר להגדיר היא 256Mi. הכמות המקסימלית של הזיכרון שאפשר להגדיר היא 16Gi.
בהתאם לערך הזיכרון שתבחרו, תצטרכו גם לציין כמות מתאימה של CPU. בטבלה הבאה מוצגים ערכי המינימום והמקסימום של מעבד לכל ערך זיכרון:
| זיכרון | מעבד מינימלי | מעבד מקסימלי |
|---|---|---|
256Mi עד 512Mi |
0.33 |
2 |
גדול מ-512Mi וקטן מ-1Gi או שווה לו |
0.5 |
2 |
גדול מ-1Gi וקטן מ-2Gi |
1 |
2 |
2Gi עד 4Gi |
1 |
4 |
יותר מ-4Gi ועד 8Gi |
2 |
4 |
יותר מ-8Gi ועד 16Gi |
4 |
4 |
לחלופין, אם קבעתם את כמות ה-CPU שהקציתם, תוכלו להשתמש בטבלה הבאה כדי לקבוע את טווח הזיכרון המתאים:
| CPU | זיכרון מינימלי | זיכרון מקסימלי |
|---|---|---|
פחות מ-0.5 |
256Mi |
512Mi |
0.5 פחות מ-1 |
256Mi |
1Gi |
1 |
256Mi |
4Gi |
2 |
256Mi |
8Gi |
4 |
2Gi |
16Gi |
התקשרות Cloud de Confiance by S3NS לשירותים באינטרנט בקוד Python
פונקציית UDF ב-Python ניגשת ל Cloud de Confiance by S3NS שירות או לשירות חיצוני באמצעות חשבון השירות של חיבור למשאב ב-Cloud. צריך להעניק לחשבון השירות של החיבור הרשאות גישה לשירות. ההרשאות הנדרשות משתנות בהתאם לשירות שאליו ניגשים ולממשקי ה-API שמבוצעות להם קריאות מקוד Python.
אם יוצרים פונקציית UDF ב-Python בלי להשתמש בקישור למשאבים ב-Cloud, הפונקציה מופעלת בסביבה שחוסמת גישה לרשת. אם ה-UDF שלכם ניגש לשירותים אונליין, אתם צריכים ליצור את ה-UDF עם חיבור למשאב Cloud. אם לא, הגישה של ה-UDF לרשת תיחסם עד שיגיע פסק זמן פנימי לחיבור. כשמשתמשים בקישור למשאבים ב-Cloud, צריך להטמיע את הפעולות הבאות:
חסימות זמניות. כשמבצעים קריאות לרשת בפונקציות מוגדרות על ידי המשתמש ב-Python, צריך תמיד לכלול פסק זמן סביר. כך נמנע מצב שבו ה-UDF נתקע ללא הגבלת זמן אם השירות החיצוני מגיב באיטיות או שלא ניתן להגיע אליו.
שימוש בטיפול בשגיאות. כדאי להוסיף את הקוד של קריאת הרשת לבלוק
try...exceptכדי לטפל בצורה נכונה בשגיאות פוטנציאליות, כמו שגיאות חיבור, פסק זמן או קודי סטטוס של שגיאות HTTP. כך הפונקציה המוגדרת על ידי המשתמש יכולה להחזיר שגיאה משמעותית או ערך חלופי במקום לגרום לשאילתה להיכשל או להפסיק להגיב.
בדוגמה הבאה אפשר לראות איך ניגשים לשירות Cloud Translation מפונקציית UDF של Python. בדוגמה הזו יש שני פרויקטים – פרויקט בשם my_query_project שבו יוצרים את הפונקציה המוגדרת על ידי המשתמש ואת קישור למשאבים ב-Cloud, ופרויקט שבו מפעילים את Cloud Translation בשם my_translate_project.
יצירת קישור למשאבים ב-Cloud
קודם כול, יוצרים קישור למשאבים ב-Cloud ב-my_query_project. כדי ליצור את החיבור למשאב בענן, פועלים לפי השלבים הבאים.
המסוף
עוברים לדף BigQuery.
בחלונית הימנית, לוחצים על כלי הניתוחים:

אם החלונית הימנית לא מוצגת, לוחצים על הרחבת החלונית הימנית כדי לפתוח אותה.
בחלונית Explorer מרחיבים את שם הפרויקט ואז לוחצים על Connections.
בדף Connections (חיבורים), לוחצים על Create connection (יצירת חיבור).
בשדה Connection type (סוג החיבור), בוחרים באפשרות Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource) (מודלים מרוחקים של Vertex AI, פונקציות מרוחקות, BigLake ו-Spanner (משאב בענן)).
בשדה מזהה החיבור, מזינים שם לחיבור.
בקטע Location type, בוחרים מיקום לחיבור. החיבור צריך להיות ממוקם יחד עם משאבים אחרים, כמו מערכי נתונים.
לוחצים על יצירת קישור.
לוחצים על מעבר לחיבור.
בחלונית Connection info (פרטי התחברות), מעתיקים את מזהה חשבון השירות לשימוש בשלב מאוחר יותר.
SQL
משתמשים בהצהרה CREATE CONNECTION:
במסוף Cloud de Confiance , עוברים לדף BigQuery.
מזינים את ההצהרה הבאה בעורך השאילתות:
CREATE CONNECTION [IF NOT EXISTS] `CONNECTION_NAME` OPTIONS ( connection_type = "CLOUD_RESOURCE", friendly_name = "FRIENDLY_NAME", description = "DESCRIPTION" );
מחליפים את מה שכתוב בשדות הבאים:
-
CONNECTION_NAME: השם של החיבור בפורמטPROJECT_ID.LOCATION.CONNECTION_ID,LOCATION.CONNECTION_IDאוCONNECTION_ID. אם לא מציינים את הפרויקט או המיקום, המערכת מסיקה אותם מהפרויקט והמיקום שבהם מופעלת ההצהרה. -
FRIENDLY_NAME(אופציונלי): שם תיאורי לחיבור. -
DESCRIPTION(אופציונלי): תיאור של הקישור.
-
לוחצים על הפעלה.
מידע נוסף על הרצת שאילתות זמין במאמר הרצת שאילתה אינטראקטיבית.
BQ
בסביבת שורת פקודה, יוצרים חיבור:
bq mk --connection --location=REGION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_ID
הפרמטר
--project_idמבטל את פרויקט ברירת המחדל.מחליפים את מה שכתוב בשדות הבאים:
REGION: אזור החיבור-
PROJECT_ID: מזהה הפרויקט ב- Cloud de Confiance -
CONNECTION_ID: מזהה לחיבור
כשיוצרים משאב חיבור, מערכת BigQuery יוצרת חשבון שירות ייחודי ומקשרת אותו לחיבור.
פתרון בעיות: אם מופיעה שגיאת החיבור הבאה, צריך לעדכן את Google Cloud SDK:
Flags parsing error: flag --connection_type=CLOUD_RESOURCE: value should be one of...
מאחזרים ומעתיקים את מזהה חשבון השירות כדי להשתמש בו בשלב מאוחר יותר:
bq show --connection PROJECT_ID.REGION.CONNECTION_ID
הפלט אמור להיראות כך:
name properties 1234.REGION.CONNECTION_ID {"serviceAccountId": "connection-1234-9u56h9@gcp-sa-bigquery-condel.s3ns-system.iam.gserviceaccount.com"}
Python
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Pythonהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Python API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
לפני שמריצים דוגמאות קוד, צריך להגדיר את משתנה הסביבה GOOGLE_CLOUD_UNIVERSE_DOMAIN לערך s3nsapis.fr.
Node.js
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Node.jsהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Node.js API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
לפני שמריצים דוגמאות קוד, צריך להגדיר את משתנה הסביבה GOOGLE_CLOUD_UNIVERSE_DOMAIN לערך s3nsapis.fr.
Terraform
משתמשים במשאב google_bigquery_connection.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
בדוגמה הבאה נוצר קישור למשאבים ב-Cloud בשם my_cloud_resource_connection באזור US:
כדי להחיל את הגדרות Terraform בפרויקט ב- Cloud de Confiance , מבצעים את השלבים בקטעים הבאים.
הכנת Cloud Shell
- מפעילים את Cloud Shell.
-
מגדירים את פרויקט ברירת המחדל שבו רוצים להחיל את ההגדרות של Terraform. Cloud de Confiance
תצטרכו להריץ את הפקודה הזו רק פעם אחת לכל פרויקט, ותוכלו לעשות זאת בכל ספרייה.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
אם תגדירו ערכים ספציפיים בקובץ התצורה של Terraform, הם יבטלו את ערכי ברירת המחדל של משתני הסביבה.
הכנת הספרייה
לכל קובץ תצורה של Terraform צריכה להיות ספרייה משלו (שנקראת גם מודול ברמה הבסיסית).
-
יוצרים ספרייה חדשה ב-Cloud Shell ובה יוצרים קובץ חדש. שם הקובץ חייב לכלול את הסיומת
.tf, למשלmain.tf. במדריך הזה, הקובץ נקראmain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
אם אתם עוקבים אחרי המדריך, תוכלו להעתיק את הקוד לדוגמה בכל קטע או שלב.
מעתיקים את הקוד לדוגמה בקובץ
main.tfהחדש שיצרתם.לחלופין, אפשר גם להעתיק את הקוד מ-GitHub. כדאי לעשות את זה כשקטע הקוד של Terraform הוא חלק מפתרון מקצה לקצה.
- בודקים את הפרמטרים לדוגמה ומשנים אותם בהתאם לסביבה שלכם.
- שומרים את השינויים.
-
מפעילים את Terraform. צריך לעשות זאת רק פעם אחת לכל ספרייה.
terraform init
אופציונלי: תוכלו לכלול את האפשרות
-upgrade, כדי להשתמש בגרסה העדכנית ביותר של הספק של Google:terraform init -upgrade
החלה של השינויים
-
בודקים את ההגדרות ומוודאים שהמשאבים שמערכת Terraform תיצור או תעדכן תואמים לציפיות שלכם:
terraform plan
מתקנים את ההגדרות לפי הצורך.
-
מריצים את הפקודה הבאה ומזינים
yesבהודעה שמופיעה, כדי להחיל את הגדרות Terraform:terraform apply
ממתינים עד שב-Terraform תוצג ההודעה "Apply complete!".
- פותחים את Cloud de Confiance הפרויקט כדי לראות את התוצאות. במסוף Cloud de Confiance , נכנסים למשאבים בממשק המשתמש כדי לוודא שהם נוצרו או עודכנו ב-Terraform.
הענקת גישה לחשבון השירות של החיבור
כדי להגדיר הרשאות לחיבור, צריך את מזהה חשבון השירות שהעתקתם קודם. כשיוצרים משאב חיבור, BigQuery יוצר חשבון שירות ייחודי של המערכת ומקשר אותו לחיבור.
כדי לתת לחשבון השירות של Cloud resource connection גישה לפרויקטים שלכם, צריך להקצות לחשבון השירות את התפקיד 'צרכן של שימוש בשירות' (roles/serviceusage.serviceUsageConsumer) ב-my_query_project ואת התפקיד 'משתמש ב-Cloud Translation API' (roles/cloudtranslate.user) ב-my_translate_project.
המסוף
עוברים לדף IAM.
מוודאים שהאפשרות
my_query_projectנבחרה.לוחצים על Grant Access.
בשדה New principals, מזינים את מזהה חשבון השירות של חיבור משאב Cloud שהעתקתם קודם.
בשדה Select a role (בחירת תפקיד), בוחרים באפשרות Service usage (שימוש בשירות) ואז באפשרות Service usage consumer (צרכן שימוש בשירות).
לוחצים על Save.
בוחרים פרויקט מתוך רשימת הפרויקטים.
my_translate_projectעוברים לדף IAM.
לוחצים על Grant Access.
בשדה New principals, מזינים את מזהה חשבון השירות של חיבור משאב Cloud שהעתקתם קודם.
בשדה Select a role (בחירת תפקיד), בוחרים באפשרות Cloud translation (תרגום בענן) ואז בוחרים באפשרות Cloud Translation API user (משתמש ב-Cloud Translation API).
לוחצים על Save.
SQL
משתמשים בהצהרה GRANT כדי להעניק לחשבון השירות ב-my_query_project את התפקיד Service usage consumer (roles/serviceusage.serviceUsageConsumer):
במסוף Cloud de Confiance , עוברים לדף BigQuery.
מזינים את ההצהרה הבאה בעורך השאילתות:
GRANT `roles/serviceusage.serviceUsageConsumer` ON PROJECT `my_query_project` TO "connection:SERVICE_ACCOUNT_ID";
מחליפים את
SERVICE_ACCOUNT_IDבמזהה של חשבון השירות שהעתקתם קודם.לוחצים על הפעלה.
מידע נוסף על הרצת שאילתות זמין במאמר הרצת שאילתה אינטראקטיבית.
משתמשים בהצהרה GRANT כדי להעניק את תפקיד המשתמש ב-Cloud Translation API (roles/cloudtranslate.user) ב-my_translate_project:
במסוף Cloud de Confiance , עוברים לדף BigQuery.
מזינים את ההצהרה הבאה בעורך השאילתות:
GRANT `roles/cloudtranslate.user` ON PROJECT `my_translate_project` TO "connection:SERVICE_ACCOUNT_ID";
מחליפים את
SERVICE_ACCOUNT_IDבמזהה של חשבון השירות שהעתקתם קודם.לוחצים על הפעלה.
מידע נוסף על הרצת שאילתות זמין במאמר הרצת שאילתה אינטראקטיבית.
יצירת פונקציית UDF ב-Python שקוראת לשירות Cloud Translation
ב-my_query_project, יוצרים פונקציית UDF ב-Python שקוראת לשירות Cloud Translation באמצעות הקישור למשאבים ב-Cloud.
במסוף Cloud de Confiance , עוברים לדף BigQuery.
מזינים את הצהרת
CREATE FUNCTIONהבאה בעורך השאילתות:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.translate_to_es(x STRING) RETURNS STRING LANGUAGE python WITH CONNECTION `PROJECT_ID.REGION.CONNECTION_ID` OPTIONS (entry_point='do_translate', runtime_version='python-3.11', packages=['google-cloud-translate>=3.11', 'google-api-core']) AS r""" from google.api_core.retry import Retry from google.cloud import translate project = "my_translate_project" translate_client = translate.TranslationServiceClient() def do_translate(x : str) -> str: response = translate_client.translate_text( request={ "parent": f"projects/PROJECT_ID/locations/us-central1", "contents": [x], "target_language_code": "es", "mime_type": "text/plain", }, retry=Retry(), ) return response.translations[0].translated_text """; -- Call the UDF. WITH text_table AS (SELECT "Hello" AS text UNION ALL SELECT "Good morning" AS text UNION ALL SELECT "Goodbye" AS text) SELECT text, `PROJECT_ID.DATASET_ID`.translate_to_es(text) AS translated_text FROM text_table;
מחליפים את מה שכתוב בשדות הבאים:
-
PROJECT_ID: מזהה הפרויקט. -
DATASET_ID: מזהה קבוצת הנתונים. -
REGION: האזור של החיבור. -
CONNECTION_ID: מזהה החיבור.
-
לוחצים על הפעלה.
הפלט אמור להיראות כך:
+--------------------------+-------------------------------+ | text | translated_text | +--------------------------+-------------------------------+ | Hello | Hola | | Good morning | Buen dia | | Goodbye | Adios | +--------------------------+-------------------------------+
שימוש ב-VPC Service Controls
פונקציות UDF ב-Python מקבלות בירושה את גבולות הגזרה של VPC Service Controls של הפרויקט שמריץ את עבודת השאילתה. גבולות גזרה אלה מגנים על העבודות שלכם מפני חילוץ נתונים, ומבטיחים שהאינטראקציות עם השירות יהיו מאובטחות.
כשמפעילים פונקציית UDF של Python בתוך גבולות הגזרה של VPC Service Controls, יש לה את קישוריות הרשת הבאה:
- פונקציות UDF ב-Python שלא משתמשות בקישור למשאבים ב-Cloud מבודדות לחלוטין. כל התנועה היוצאת חסומה.
- פונקציות UDF ב-Python שמשתמשות בקישור למשאבים ב-Cloud חסומות לגישה לאינטרנט הציבורי. פונקציות UDF של Python יכולות לגשת רק לשירותים של Cloud de Confiance by S3NS תומכים ב-VPC Service Controls. תנועה יוצאת לכל יעד אחר חוץ מ-
restricted.googleapis.comנחסמת.
הגדרת פונקציות מוגדרות על ידי המשתמש (UDF) ב-Python כדי לגשת לשירותים בצורה מאובטחת בתוך VPC Service Controls Cloud de Confiance by S3NS
כדי לגשת לשירותים מ-UDF של Python תוך אכיפה של VPC Service Controls, פועלים לפי השלבים הבאים: Cloud de Confiance by S3NS
- יוצרים את פונקציית ה-UDF של Python באמצעות הסעיף
WITH CONNECTIONשל הצהרת CREATE FUNCTION. - כוללים את פרויקט BigQuery שבו מופעלת משימת השאילתה ואת פרויקט השירות של היעד בגבולות גזרה לשירות. אפשרות אחרת היא להגדיר גשר בין גבולות גזרה.
- מוסיפים את ה-API של שירות היעד להגדרת גבול הגזרה. לדוגמה,
translate.googleapis.comאם מתחברים ל-Cloud Translation API.
פרטים נוספים על הגדרת גבולות גזרה של VPC Service Controls זמינים במאמרים הבאים:
שיטות מומלצות
כשיוצרים פונקציות UDF ב-Python, מומלץ לפעול לפי השיטות המומלצות הבאות:
- אופטימיזציה של הלוגיקה של השאילתות כדי לאגד אותן. מבני שאילתות מורכבים יכולים להשבית את האפשרות של הוספה לאוסף. הפעולה הזו גורמת לעיבוד איטי של כל שורה בנפרד, מה שמגדיל באופן משמעותי את זמן האחזור במערכי נתונים גדולים.
- אופטימיזציה של מטען הנתונים. גודל השורות הבודדות יכול להשפיע על היעילות של התכונה 'הוספה של כמה שורות בבת אחת'. כדאי להקפיד שכל שורה תהיה קטנה ככל האפשר כדי למקסם את מספר השורות שאפשר לעבד באצווה אחת.
- הגדרת מגבלות על קונטיינרים בצורה יעילה. מדרגיות היא פונקציה של מעבד (CPU), זיכרון ובו-זמניות בקשות. כדאי לבדוק את מדדי המעקב כדי לשנות את הגדרות הקונטיינר.
אם ניצול המעבד גבוה, אפשר להגדיל את הקצאת המעבד באמצעות המגבלה
container_cpuאו להקטין את מקבילות הבקשות של הקונטיינר באמצעות המגבלהcontainer_request_concurrency. - כשמשתמשים בכוונון איטרטיבי, מתחילים עם ערכי ברירת מחדל. אם הביצועים לא אופטימליים, כדאי לנתח את מדדי הניטור כדי לזהות צווארי בקבוק ספציפיים.
- הטמעה של פסק זמן (timeout) ב-API. כשפונקציית Python UDF ניגשת לאינטרנט, צריך להגדיר זמן קצוב לתפוגה לקריאה ל-API כדי למנוע התנהגות לא צפויה. דוגמה לגישה לאינטרנט היא קריאה מקטגוריה של Cloud Storage.
הצגת מדדים של פונקציות מוגדרות על ידי המשתמש (UDF) ב-Python
פונקציות מוגדרות על ידי המשתמש (UDF) ב-Python מייצאות מדדים אל Cloud Monitoring. המדדים האלה עוזרים לכם לעקוב אחרי היבטים שונים של תקינות הפעולה וצריכת המשאבים של פונקציות מוגדרות על ידי המשתמש, ומספקים תובנות לגבי הביצועים וההתנהגות של מופעי הפונקציות המוגדרות על ידי המשתמש.
סוג המשאב למעקב
המדדים של פונקציות UDF ב-Python מדווחים בסוג המשאב הבא ב-Cloud Monitoring:
- Type (סוג):
bigquery.googleapis.com/ManagedRoutineInvocation - שם לתצוגה: BigQuery Managed Routine Invocation
- תוויות:
-
resource_container: מזהה הפרויקט שבו הופעלה משימת השאילתה. -
location: המיקום שבו משימת השאילתה הופעלה. -
query_job_id: המזהה של עבודת השאילתה שהפעילה את ה-UDF של Python. -
routine_project_id: מזהה הפרויקט שבו מאוחסנת הפרוצדורה שהופעלה. -
routine_dataset_id: מזהה מערך הנתונים שבו מאוחסנת הפרוצדורה שהופעלה. -
routine_id: המזהה של השגרה שהופעלה.
-
מדדים
המדדים הבאים זמינים עבור סוג המשאב bigquery.googleapis.com/ManagedRoutineInvocation:
| מדד | תיאור | יחידה | סוג הערך |
|---|---|---|---|
bigquery.googleapis.com/managed_routine/python/cpu_utilizations |
כשמפעילים פונקציית UDF של Python, המדד הזה מציג את חלוקת השימוש ביחידת העיבוד המרכזית (CPU) בכל המופעים של פונקציית UDF של Python עבור עבודת השאילתה. | ערך באחוזים | DISTRIBUTION |
bigquery.googleapis.com/managed_routine/python/memory_utilizations |
כשמפעילים פונקציית UDF של Python, המדד הזה מציג את התפלגות השימוש בזיכרון בכל המופעים של פונקציית UDF של Python עבור עבודת השאילתה. | ערך באחוזים | DISTRIBUTION |
bigquery.googleapis.com/managed_routine/python/max_request_concurrencies |
המדד הזה מציג את הפיזור של המספר המקסימלי של בקשות בו-זמניות שמוגשות על ידי כל מופע של פונקציית Python UDF. | ספירה | DISTRIBUTION |
הצגת המדדים
כדי לראות את המדדים של פונקציות UDF ב-Python, בוחרים באחת מהאפשרויות בקטעים הבאים.
פרטי משרה
כדי לראות את מדדי ה-UDF של Python עבור עבודת שאילתה ספציפית, פועלים לפי השלבים הבאים:
עוברים לדף BigQuery.
לוחצים על היסטוריית משרות.
בעמודה מזהה משימה, לוחצים על מזהה משימת השאילתה.
בדף פרטי עבודת השאילתה, לוחצים על לוח הבקרה של Cloud Monitoring. הקישור הזה מציג לוח בקרה עם סינון של מדדי פונקציית Python UDF של העבודה.
Metrics Explorer
כדי לראות את מדדי פונקציות UDF של Python ב-Metrics Explorer:
עוברים לדף Metrics Explorer ב-Cloud Monitoring.
לוחצים על Select a metric (בחירת מדד), ובשדה Filter (מסנן) מקלידים
BigQuery Managed Routine Invocationאוbigquery.googleapis.com/ManagedRoutineInvocation.בוחרים באפשרות Bigquery Managed Routine > Managed_routine.
לוחצים על אחד מהמדדים הזמינים, כמו:
- ניצול המעבד של מופע
- ניצול הזיכרון של המופע
- מספר מקסימלי של בקשות בו-זמנית
לוחצים על אישור.
כברירת מחדל, המדדים מוצגים בתרשים.
אפשר לסנן ולקבץ את המדדים באמצעות התוויות שמוגדרות בסוגי משאבים של Monitoring. כדי לסנן את המדדים:
בשדה Filter בוחרים סוג משאב כמו
query_job_idאוroutine_id.בשדה ערך, מזינים את מזהה המשימה או מזהה השגרה, או בוחרים אחד מהם מהרשימה.
לוחות בקרה של Cloud Monitoring
כדי לראות את מדדי הפונקציות המוגדרות על ידי המשתמש ב-Python באמצעות לוחות הבקרה של המעקב:
נכנסים לדף Dashboards ב-Cloud Monitoring.
לוחצים על מרכז הבקרה BigQuery Managed Routine Query Monitoring (מעקב אחרי שאילתות של שגרות מנוהלות ב-BigQuery).
לוח הבקרה הזה מספק סקירה כללית של מדדי מפתח בפונקציות שהוגדרו על ידי המשתמש.
כדי לסנן את מרכז הבקרה הזה:
לוחצים על סינון.
ברשימה Filter by resource, בוחרים באפשרות כמו מזהה פרויקט, מיקום, מזהה שגרה או מזהה משימה.
מיקומים נתמכים
פונקציות UDF ב-Python נתמכות בכל המיקומים במספר אזורים ובאזורים ב-BigQuery.
תמחור
החיוב על פונקציות UDF ב-Python מתבצע באמצעות מק"ט שירותי BigQuery.
החיובים כוללים את הפריטים הבאים:
יצירה או יצירה מחדש של קובץ האימג' של הקונטיינר של ה-UDF. החיוב הזה הוא יחסי למשך הזמן שנדרש לבניית התמונה המתאימה עם קוד הלקוח והתלות.
- אם אתם משתמשים ב-Routines API, משך הבנייה האחרון מופיע בשדה
BuildStatus. אפשר גם לראות את משך הבנייה בעמודהBuildStatusבתצוגהINFORMATION_SCHEMA.ROUTINES. - כדי לראות את העלות הכוללת של בנייה לכל פרויקט, אפשר לסנן את דוח החיוב באמצעות האפשרויות הבאות:
- מקרא:
goog-bq-feature-type - ערך:
MANAGED_ROUTINE_BUILD
- מקרא:
- אם אתם משתמשים ב-Routines API, משך הבנייה האחרון מופיע בשדה
לקוחות שמשתמשים בפונקציות מוגדרות על ידי המשתמש (UDF) ב-Python מחויבים גם בעלות של הפעלת פונקציות כאלה. החיוב הזה הוא יחסי לכמות המחשוב והזיכרון שנצרכו כשמפעילים את פונקציית Python UDF.
- כדי לראות את העלויות של פונקציות UDF ב-Python לכל שאילתה, אפשר להריץ שאילתה בשדה
ExternalServiceCostsבאמצעות Job API. אפשר גם לראות את העלויות לכל שאילתה בעמודהexternal_service_costsבתצוגהINFORMATION_SCHEMA.JOBSולהחיל את המסנן הבא:'external_service_costs.external_service="MANAGED_ROUTINE_EXECUTION"'. - כדי לראות את העלות הכוללת של הפעלת פונקציות מוגדרות על ידי המשתמש ב-Python לכל פרויקט, אפשר לסנן את דוח החיוב באמצעות הפרמטרים הבאים:
- מקרא:
goog-bq-feature-type - ערך:
MANAGED_ROUTINE_EXECUTION
- מקרא:
- כדי לראות את העלויות של פונקציות UDF ב-Python לכל שאילתה, אפשר להריץ שאילתה בשדה
אם פונקציות UDF של Python גורמות לתעבורת נתונים יוצאת ברשת חיצונית או באינטרנט, תראו גם חיוב על תעבורת נתונים יוצאת באינטרנט במסלול פרימיום, על סמך מק"טים של תעבורת נתונים יוצאת ב-BigQuery.