
Anda dapat memeriksa kondisi volume Persistent Disk atau Google Cloud Hyperdisk dengan meninjau metrik status performa disk. Metrik ini menunjukkan apakah performa disk berpotensi terpengaruh oleh peristiwa buruk dalam Compute Engine.
Masalah yang memengaruhi status performa disk juga dapat terlihat di dasbor Personal Service Health (PSH) project Anda atau dasbor Cloud de Confiance by S3NS Service Health.
Dokumen ini membahas status performa disk dan cara menggunakannya untuk memecahkan masalah performa.
Kapan harus memeriksa kesehatan disk
Jika Anda melihat masalah performa pada disk, periksa kondisi disk dengan meninjau metrik status performa disk. Metrik status performa disk diperbarui setiap menit dan menunjukkan performa disk selama satu menit sebelumnya. Untuk mengetahui langkah-langkah memeriksa kondisi disk, lihat melihat status performa disk.
Tabel berikut meringkas kemungkinan nilai status performa disk.
| Status | Arti |
|---|---|
Healthy |
Performa disk sesuai yang diharapkan. |
Degraded |
Anda mungkin sementara mengamati latensi I/O yang lebih tinggi dari yang diperkirakan. |
Severely degraded |
Terjadi latensi I/O yang tinggi atau error lainnya. |
Jika status performa bukan Healthy, lihat Memahami setiap status
untuk mengetahui langkah selanjutnya.
Jika status performa adalah Healthy, disk berfungsi normal dan Anda perlu memeriksa penyebab lain masalah performa.
Anda harus memeriksa error aplikasi atau sistem operasi dan memastikan disk Anda dioptimalkan dengan benar. Untuk mengetahui panduan pengoptimalan, lihat Mengoptimalkan Hyperdisk dan Mengoptimalkan Persistent Disk.
Hubungan kesehatan disk dengan metrik performa disk lainnya
Kondisi disk seperti yang ditunjukkan oleh metrik status performa menampilkan
status internal disk dari perspektif Google. Jika status disk adalah
Degraded atau Severely Degraded, penyebab utamanya selalu berada dalam
infrastruktur Compute Engine.
Anda umumnya tidak dapat mengubah kondisi disk dengan mengubah beban kerja. Namun, dalam kasus yang jarang terjadi, perubahan pada workload dapat memicu masalah internal, sehingga masalah dapat diatasi dengan mengubah workload.
Untuk mempelajari metrik performa disk lainnya yang tersedia, lihat Meninjau metrik performa disk.
Skenario yang tidak memengaruhi status performa disk
Status performa disk tidak terkait dengan masalah performa yang disebabkan oleh faktor berikut:
- Pengoptimalan disk tidak lengkap atau tidak memadai
- Batas performa yang terkait dengan jenis disk dan mesin (jika jenis mesin yang dipilih tidak dapat memenuhi persyaratan performa workload Anda)
- Peningkatan beban pada disk karena traffic beban kerja
- Error pengguna, aplikasi, atau sistem operasi
- Disk penuh atau rusak
- Untuk volume Hyperdisk dan Extreme Persistent Disk, IOPS atau throughput yang disediakan tidak mencukupi.
Dalam situasi ini, Anda bertanggung jawab untuk meningkatkan performa, seperti dengan mengoptimalkan disk, meningkatkan skala beban kerja, mengubah jenis mesin, dan menyediakan lebih banyak kapasitas, IOPS, atau throughput.
Melihat kondisi disk di Cloud Monitoring
Untuk melihat kondisi disk, buat diagram di Metrics Explorer.
Peran dan izin yang diperlukan
Untuk mendapatkan izin yang Anda perlukan guna memeriksa metrik status performa disk, minta administrator untuk memberi Anda peran IAM berikut pada project:
- Monitoring Viewer (
roles/monitoring.viewer) -
Untuk menyimpan diagram ke dasbor:
Monitoring Editor (
roles/monitoring.editor)
Untuk mengetahui informasi selengkapnya tentang pemberian peran, lihat Mengelola akses ke project, folder, dan organisasi.
Anda mungkin juga bisa mendapatkan izin yang diperlukan melalui peran khusus atau peran bawaan lainnya.
Membuat diagram di Metrics Explorer
Untuk membuat diagram, buat kueri dengan antarmuka berbasis menu atau PromQL.
Antarmuka berbasis menu
Untuk melihat kondisi satu atau beberapa disk pada diagram, ikuti petunjuk berikut.
-
Di konsol Cloud de Confiance , buka halaman leaderboard Metrics explorer:
Jika Anda menggunakan kotak penelusuran untuk menemukan halaman ini, pilih hasil yang subjudulnya adalah Monitoring.
- Di toolbar konsol Cloud de Confiance , pilih project Cloud de Confiance Anda. Untuk konfigurasi App Hub, pilih project host App Hub atau project pengelolaan folder yang mendukung aplikasi.
- Pada elemen Metrik, luaskan menu Pilih metrik, masukkan
VM Instancedi panel filter, lalu gunakan submenu untuk memilih jenis dan metrik resource tertentu:- Di menu Active resources, pilih VM Instance.
- Di menu Active metric category, pilih Instance.
- Di menu Metrik aktif, pilih Status performa disk.
- Klik Terapkan.
compute.googleapis.com/instance/disk/performance_status. Untuk menambahkan filter, yang menghapus deret waktu dari hasil kueri, gunakan elemen Filter.
- Konfigurasi cara data dilihat.
Nonaktifkan agregasi. Pastikan di elemen Aggregation, menu pertama ditetapkan ke Unaggregated dan menu kedua ditetapkan ke None.
Untuk melihat kondisi disk tertentu, filter menurutdevice_name.
Untuk informasi selengkapnya tentang cara mengonfigurasi diagram, lihat Memilih metrik saat menggunakan Metrics Explorer.
PromQL
Buka editor kueri: ikuti langkah-langkah di Menulis Kueri PromQL.
Masukkan kueri Anda di editor kueri. Misalnya, untuk melihat status performa disk tertentu, masukkan kueri berikut:
last_over_time
(compute_googleapis_com:instance_disk_performance_status
{monitored_resource="gce_instance",
project_id ="PROJECT_ID",
device_name="DISK_NAME"}[${__interval}])
Ganti DISK_NAME dengan nama disk, misalnya,
disk-1.
Jika Anda melihat hasilnya dalam diagram, akan ada 3 garis untuk setiap disk, satu untuk setiap kemungkinan status. Demikian pula, jika Anda melihat hasil kueri dalam tabel, maka tabel tersebut memiliki 3 baris untuk setiap disk.
Jika Anda membuat kueri dengan PromQL, setiap baris atau garis akan memiliki nilai 1 atau 0. Untuk kueri yang dibuat dengan menu, nilai untuk
adalah 100% atau 0.
Kondisi disk saat ini diwakili oleh baris atau garis yang nilainya adalah 100%
atau 1.
Misalnya, screenshot berikut menampilkan diagram untuk disk bernama a-test-VM,
yang statusnya adalah Healthy:
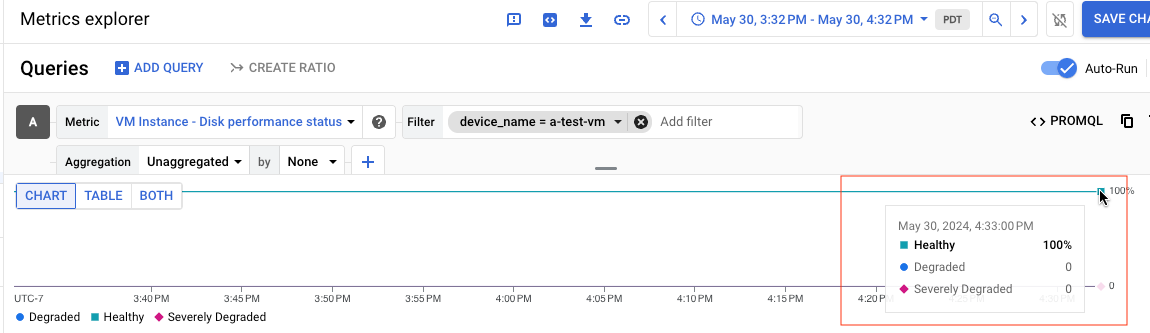
Jika Anda melihat hasil kueri sebagai tabel, tabel berikut adalah contoh
hasil untuk disk yang Healthy:
| performance_status | nilai |
|---|---|
Healthy |
1 |
Degraded |
0 |
Severely Degraded |
0 |
Screenshot berikut menunjukkan diagram untuk disk bernama replica-23509 yang statusnya Menurun:
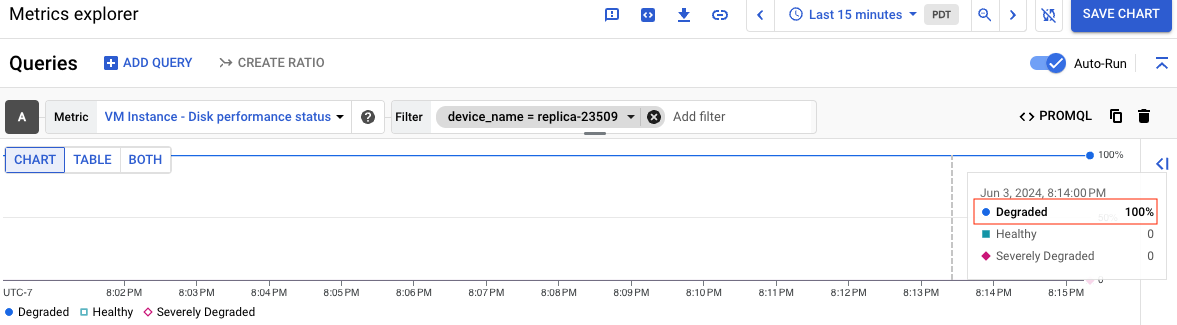
Untuk mengetahui informasi tentang arti setiap status performa, lihat artikel Memahami setiap status. Setelah membuat diagram, Anda dapat menyimpan diagram ke dasbor untuk digunakan di masa mendatang.
Hasil pecahan
Jika kueri Anda menyertakan hasil pecahan seperti pada tabel berikut, hal ini biasanya disebabkan oleh periode tampilan yang dipilih terlalu lama. Akibatnya, Cloud Monitoring mengagregasi data dari waktu ke waktu.
Nilai 77% untuk status Healthy berarti status disk adalah Healthy
77% dari periode tampilan yang dipilih.
| performance_status | nilai |
|---|---|
Healthy |
77% |
Degraded |
23% |
Severely Degraded |
0 |
Untuk melihat kesehatan disk yang lebih terperinci, gunakan periode tampilan beberapa jam atau beberapa menit.
Memahami setiap status
Bagian ini membahas arti setiap status dan kapan Anda mungkin perlu mengambil tindakan lebih lanjut.
Healthy
Status Healthy menunjukkan bahwa dari perspektif Google, disk berfungsi normal.
Jika disk Healthy mengalami masalah performa, jangan hubungi dukungan. Sebagai gantinya,
pecahkan masalah disk menggunakan beberapa saran berikut:
- Tinjau metrik performa disk, seperti latensi dan kedalaman antrean.
- Periksa log dan metrik beban kerja Anda untuk mengetahui anomali dan hambatan.
- Jika Anda menggunakan Persistent Disk, pastikan kapasitas yang disediakan dapat memenuhi kebutuhan performa disk. Jika Anda menggunakan volume Hyperdisk atau Extreme Persistent Disk, pastikan Anda telah menyediakan IOPS dan throughput yang cukup.
- Pastikan Anda telah mengikuti panduan untuk mengoptimalkan disk. Untuk mengetahui informasi selengkapnya, lihat Mengoptimalkan Hyperdisk dan Mengoptimalkan Persistent Disk.
Degraded
Anda biasanya tidak perlu menghubungi dukungan jika status disk Anda adalah Degraded. Degraded status umumnya disebabkan oleh pemeliharaan internal normal pada infrastruktur Compute Engine.
Anda mungkin tidak melihat dampak apa pun pada performa disk saat statusnya
Degraded. Jika masalah performa dan status Degraded berkorelasi dari waktu ke waktu, masalah performa mungkin masih tidak terkait dengan status Degraded.
Jika masalah performa disebabkan oleh status Degraded, dampaknya biasanya bersifat sementara. Status disk akan kembali ke Healthy dalam beberapa menit.
Anda dapat mengabaikan status Degraded dengan aman jika tidak ada masalah performa pada disk.
Tindakan yang harus dilakukan jika ada masalah performa
Jika status performa disk Anda adalah Degraded, dan Anda mengamati masalah performa, ikuti langkah-langkah berikut:
- Periksa dasbor PSH untuk melihat apakah ada insiden yang memengaruhi disk. Jika terjadi insiden, jangan hubungi dukungan karena Google sudah mengetahui dan sedang berupaya menyelesaikan masalah tersebut.
- Jika tidak ada masalah umum, tunggu setidaknya 5 menit hingga masalah performa teratasi dengan sendirinya.
Jika setelah 5 menit, masalah performa belum terselesaikan dan statusnya masih
Degraded, pastikan masalah performa bukan karena disk tidak dioptimalkan dengan baik. Misalnya, periksa latensi dan kedalaman antrean disk. Mungkin masalah performa dan statusDegradedtidak terkait dan hanya kebetulan. Untuk melakukannya, tinjau metrik disk dan panduan pengoptimalan performa.Jika masalah performa berlanjut dan semua kondisi berikut terpenuhi, Anda dapat menghubungi dukungan untuk mendapatkan bantuan:
- Status disk adalah
Degradedselama lebih dari 5 menit - Anda cukup yakin bahwa ini bukan masalah beban kerja karena Anda telah mengoptimalkan disk dan memverifikasi bahwa tidak ada masalah lain seperti hambatan atau aplikasi yang kelebihan beban
- Tidak ada pemberitahuan di dasbor PSH
- Status disk adalah
Google tidak merekomendasikan pembuatan pemberitahuan untuk status Degraded secara langsung, tetapi membuat pemberitahuan tentang status aplikasi tingkat yang lebih tinggi dan menggunakan metrik ini untuk men-debug masalah.
Severely Degraded
Disk yang status performanya Severely Degraded sedang mengalami masalah performa. Masalah ini dapat disebabkan oleh insiden atau error dan mungkin
sudah terlihat di dasbor PSH
atau dasbor Cloud de Confiance by S3NS kesehatan layanan.
Yang harus dilakukan
Jika status performa disk Anda adalah Severely Degraded, ikuti langkah-langkah berikut:
- Periksa dasbor PSH dan dasbor kesehatan umum untuk mengetahui insiden yang memengaruhi disk. Cloud de Confiance by S3NS Jika terjadi insiden, jangan hubungi dukungan karena Google sudah mengetahui dan sedang berupaya menyelesaikan masalah tersebut.
- Jika tidak ada masalah umum di kedua dasbor, hubungi dukungan untuk mendapatkan bantuan.
Pohon keputusan
Diagram berikut menggambarkan cara melanjutkan jika disk mengalami masalah performa dan merangkum informasi di bagian sebelumnya.

Seperti yang ditunjukkan dalam diagram alur, Anda hanya boleh menghubungi dukungan jika tidak ada pemberitahuan yang diketahui di dasbor layanan Cloud dan PSH, serta status disk adalah Severely Degraded. Jika disknya Degraded, hubungi dukungan hanya jika semua kondisi berikut telah terpenuhi:
- Disk telah
Degradedselama lebih dari 5 menit - Anda telah mengecualikan error atau kesalahan konfigurasi workload (seperti masalah jaringan)
- Tidak ada pengoptimalan tambahan yang dapat dilakukan di tingkat aplikasi, beban kerja, atau disk
- Anda telah meninjau semua metrik disk
- Anda telah memeriksa log workload dan virtual machine (VM)
Langkah berikutnya
- Pelajari lebih lanjut cara membuat diagram dengan Metric Explorer dan cara mempersempit hasil kueri dengan menambahkan filter ke diagram.
- Periksa peristiwa status layanan yang aktif dan sebelumnya di dasbor Personal Service Health dan Google Service Health
- Untuk panduan pengoptimalan performa, lihat Mengoptimalkan Hyperdisk dan Mengoptimalkan Persistent Disk.