
较高的网络带宽可以提高 GPU 实例的性能,以支持在 Compute Engine 上运行的分布式工作负载。
Compute Engine 上挂接了 GPU 的实例可用的最大网络带宽如下所示:
- 对于 A4X 加速器优化实例,您可以获得高达 2,000 Gbps 的最大网络带宽,具体取决于机器类型。
- 对于 A4 和 A3 加速器优化实例,您可以获得高达 3,600 Gbps 的最大网络带宽,具体取决于机器类型。
- 对于 G4 加速器优化型实例,您可以获得高达 400 Gbps 的最大网络带宽,具体取决于机器类型。
- 对于 A2 和 G2 加速器优化实例,您可以获得高达 100 Gbps 的最大网络带宽,具体取决于机器类型。
- 对于挂接了 P100 和 P4 GPU 的 N1 通用实例,可用的最大网络带宽为 32 Gbps。这与没有挂接 GPU 的 N1 实例可用的最大速率类似。如需详细了解网络带宽,请参阅出站数据速率上限。
- 对于挂接了 T4 和 V100 GPU 的 N1 通用实例,您可以获得高达 100 Gbps 的最大网络带宽,具体取决于 GPU 和 vCPU 的数量组合。
查看网络带宽和 NIC 配置
请参阅以下部分,查看每种 GPU 机器类型的网络配置和带宽速度。
A4X 机器类型
A4X 机器类型挂接了 NVIDIA GB200 超级芯片。这些超级芯片具有 NVIDIA B200 GPU。
此机器类型具有 4 个 NVIDIA ConnectX-7 (CX-7) 网络接口卡 (NIC) 和 2 个 Titanium NIC。4 个 CX-7 NIC 可提供 1,600 Gbps 的总网络带宽。这些 CX-7 专用于高带宽 GPU 到 GPU 通信,无法用于其他网络需求(例如访问公共互联网)。这两个 Titanium NIC 是智能 NIC,可提供额外的 400 Gbps 网络带宽来满足通用网络要求。这些网络接口卡组合为这些机器提供的总网络带宽上限为 2,000 Gbps。
A4X 是基于 NVIDIA GB200 NVL72 机架级架构的艾级平台,并引入了 NVIDIA Grace Hopper 超级芯片架构,该架构可提供 NVIDIA Hopper GPU 和 NVIDIA Grace CPU,通过高带宽 NVIDIA NVLink 芯片间 (C2C) 互连进行连接。
A4X 网络架构采用轨道对齐设计,这是一种拓扑,其中一个 Compute Engine 实例的相应网卡连接到另一个实例的网卡。每个实例上的四个 CX-7 NIC 在四向轨道对齐的网络拓扑上实现物理隔离,使 A4X 能够以 72 个 GPU 为一组进行横向扩容,从而在单个无阻塞集群中实现数千个 GPU。这种硬件集成方法可提供可预测的低延迟性能,这对于大规模分布式工作负载至关重要。
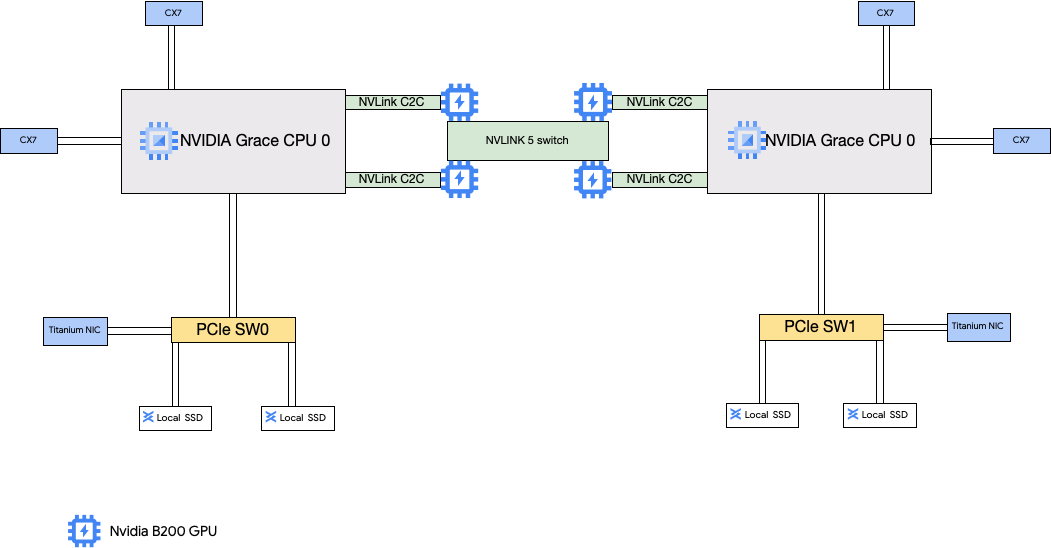
如需使用这多个 NIC,您需要创建 3 个虚拟私有云网络,如下所示:
- 2 个 VPC 网络:每个 gVNIC 都必须连接到不同的 VPC 网络
- 1 个采用 RDMA 网络配置文件的 VPC 网络:所有 4 个 CX-7 NIC 共享同一个 VPC 网络
如需设置这些网络,请参阅 AI Hypercomputer 文档中的创建 VPC 网络。
| 挂接了 NVIDIA GB200 Grace Blackwell 超级芯片 | |||||||
|---|---|---|---|---|---|---|---|
| 机器类型 | vCPU 数量1 | 实例内存 (GB) | 已挂接的本地 SSD (GiB) | 物理 NIC 数量 | 网络带宽上限 (Gbps)2 | GPU 数量 | GPU 内存3 (GB HBM3e) |
a4x-highgpu-4g |
140 | 884 | 12,000 | 6 | 2,000 | 4 | 744 |
1每个 vCPU 是在其中一个可用的 CPU 平台上以单个硬件超线程的形式实现的。
2 出站流量带宽上限不能超过给定的数量。实际的出站带宽取决于目的地 IP 地址和其他因素。如需详细了解网络带宽,请参阅网络带宽。
3GPU 内存是 GPU 设备上的内存,可用于临时存储数据。它与实例的内存分开,专门用于处理图形密集型工作负载的更高带宽需求。
A4 和 A3 Ultra 机器类型
A4 机器类型挂接了 NVIDIA B200 GPU,A3 Ultra 机器类型挂接了 NVIDIA H200 GPU。
这些机器类型提供 8 个 NVIDIA ConnectX-7 (CX-7) 网络接口卡 (NIC) 和 2 个 Google 虚拟 NIC (gVNIC)。8 个 CX-7 NIC 可提供 3,200 Gbps 的总网络带宽。这些 NIC 专用于高带宽 GPU 到 GPU 通信,无法用于其他网络需求(例如访问公共互联网)。如下图所示,每个 CX-7 NIC 都与一个 GPU 对齐,以优化非统一内存访问 (NUMA)。所有 8 个 GPU 都可以使用连接它们的全互连 NVLink 桥接器快速相互通信。另外 2 个 gVNIC 网络接口卡是智能 NIC,可提供额外的 400 Gbps 网络带宽来实现通用网络要求。这些网络接口卡组合为这些机器提供的总网络带宽上限为 3,600 Gbps。
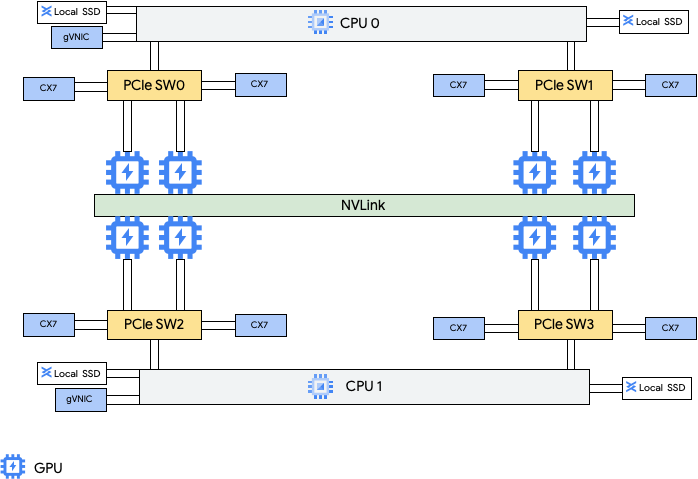
如需使用这多个 NIC,您需要创建 3 个虚拟私有云网络,如下所示:
- 2 个常规 VPC 网络:每个 gVNIC 都必须连接到不同的 VPC 网络
- 1 个 RoCE VPC 网络:所有 8 个 CX-7 NIC 共享同一个 RoCE VPC 网络
如需设置这些网络,请参阅 AI Hypercomputer 文档中的创建 VPC 网络。
A4 虚拟机
| 挂接的 NVIDIA B200 Blackwell GPU | |||||||
|---|---|---|---|---|---|---|---|
| 机器类型 | vCPU 数量1 | 实例内存 (GB) | 已挂接的本地 SSD (GiB) | 物理 NIC 数量 | 网络带宽上限 (Gbps)2 | GPU 数量 | GPU 内存3 (GB HBM3e) |
a4-highgpu-8g |
224 | 3,968 | 12,000 | 10 | 3600 | 8 | 1,440 |
A3 Ultra 虚拟机
| 挂接了 NVIDIA H200 GPU | |||||||
|---|---|---|---|---|---|---|---|
| 机器类型 | vCPU 数量1 | 实例内存 (GB) | 已挂接的本地 SSD (GiB) | 物理 NIC 数量 | 网络带宽上限 (Gbps)2 | GPU 数量 | GPU 内存3 (GB HBM3e) |
a3-ultragpu-8g |
224 | 2,952 | 12,000 | 10 | 3600 | 8 | 1128 |
A3 Mega、A3 High 和 A3 Edge 机器类型
这些机器类型挂接了 H100 GPU。其中每种机器类型都有固定的 GPU 数量、vCPU 数量和内存大小。
- 单 NIC A3 虚拟机:对于挂接了 1 到 4 个 GPU 的 A3 虚拟机,仅提供一个物理网络接口卡 (NIC)。
- 多 NIC A3 虚拟机:对于挂接了 8 个 GPU 的 A3 虚拟机,提供多个物理 NIC。对于这些 A3 机器类型,NIC 在外围设备组件互连高速 (PCIe) 总线上的排列方式如下:
- 对于 A3 Mega 机器类型:可使用 8+1 NIC 排列。采用这种排列时,8 个 NIC 共享同一 PCIe 总线,1 个 NIC 位于单独的 PCIe 总线上。
- 对于 A3 High 机器类型:可使用 4+1 NIC 排列。 采用这种排列时,4 个 NIC 共享同一 PCIe 总线,而 1 个NIC 位于单独的 PCIe 总线上。
- 对于 A3 Edge 机器类型:可使用 4+1 NIC 排列。 采用这种排列时,4 个 NIC 共享同一 PCIe 总线,而 1 个NIC 位于单独的 PCIe 总线上。 这 5 个 NIC 为每个虚拟机提供的总网络带宽为 400 Gbps。
共用同一 PCIe 总线的 NIC 采用非统一内存访问 (NUMA) 对齐方式,即每两个 NVIDIA H100 GPU 对应一个 NIC。这些 NIC 非常适合专用高带宽 GPU 到 GPU 通信。位于单独 PCIe 总线上的物理 NIC 非常适合其他网络需求。 如需了解如何为 A3 High 和 A3 Edge 虚拟机设置网络,请参阅设置巨型帧 MTU 网络。
A3 Mega
| 挂接了 NVIDIA H100 GPU | |||||||
|---|---|---|---|---|---|---|---|
| 机器类型 | vCPU 数量1 | 实例内存 (GB) | 已挂接的本地 SSD (GiB) | 物理 NIC 数量 | 网络带宽上限 (Gbps)2 | GPU 数量 | GPU 内存3 (GB HBM3) |
a3-megagpu-8g |
208 | 1,872 | 6000 | 9 | 1800 | 8 | 640 |
A3 High
| 挂接了 NVIDIA H100 GPU | |||||||
|---|---|---|---|---|---|---|---|
| 机器类型 | vCPU 数量1 | 实例内存 (GB) | 已挂接的本地 SSD (GiB) | 物理 NIC 数量 | 网络带宽上限 (Gbps)2 | GPU 数量 | GPU 内存3 (GB HBM3) |
a3-highgpu-1g |
26 | 234 | 750 | 1 | 25 | 1 | 80 |
a3-highgpu-2g |
52 | 468 | 1,500 | 1 | 50 | 2 | 160 |
a3-highgpu-4g |
104 | 936 | 3000 | 1 | 100 | 4 | 320 |
a3-highgpu-8g |
208 | 1,872 | 6000 | 5 | 1000 | 8 | 640 |
A3 Edge
| 挂接了 NVIDIA H100 GPU | |||||||
|---|---|---|---|---|---|---|---|
| 机器类型 | vCPU 数量1 | 实例内存 (GB) | 已挂接的本地 SSD (GiB) | 物理 NIC 数量 | 网络带宽上限 (Gbps)2 | GPU 数量 | GPU 内存3 (GB HBM3) |
a3-edgegpu-8g |
208 | 1,872 | 6000 | 5 |
|
8 | 640 |
1每个 vCPU 是在其中一个可用的 CPU 平台上以单个硬件超线程的形式实现的。
2 出站流量带宽上限不能超过给定的数量。实际的出站带宽取决于目的地 IP 地址和其他因素。如需详细了解网络带宽,请参阅网络带宽。
3GPU 内存是 GPU 设备上的内存,可用于临时存储数据。它与实例的内存分开,专门用于处理图形密集型工作负载的更高带宽需求。
A2 机器类型
每种 A2 机器类型都挂接了固定数量的 NVIDIA A100 40GB 或 NVIDIA A100 80 GB GPU。每种机器类型还具有固定的 vCPU 数量和内存大小。
A2 机器系列有两种类型:
- A2 Ultra:这些机器类型挂接了 A100 80GB GPU 和本地 SSD 磁盘。
- A2 标准:这些机器类型挂接了 A100 40GB GPU
A2 Ultra
| 挂接了 NVIDIA A100 80GB GPU | ||||||
|---|---|---|---|---|---|---|
| 机器类型 | vCPU 数量1 | 实例内存 (GB) | 已挂接的本地 SSD (GiB) | 网络带宽上限 (Gbps)2 | GPU 数量 | GPU 内存3 (GB HBM2e) |
a2-ultragpu-1g |
12 | 170 | 375 | 24 | 1 | 80 |
a2-ultragpu-2g |
24 | 340 | 750 | 32 | 2 | 160 |
a2-ultragpu-4g |
48 | 680 | 1500 | 50 | 4 | 320 |
a2-ultragpu-8g |
96 | 1,360 | 3000 | 100 | 8 | 640 |
A2 标准
| 挂接了 NVIDIA A100 40GB GPU | ||||||
|---|---|---|---|---|---|---|
| 机器类型 | vCPU 数量1 | 实例内存 (GB) | 支持本地 SSD | 网络带宽上限 (Gbps)2 | GPU 数量 | GPU 内存3 (GB HBM2) |
a2-highgpu-1g |
12 | 85 | 是 | 24 | 1 | 40 |
a2-highgpu-2g |
24 | 170 | 是 | 32 | 2 | 80 |
a2-highgpu-4g |
48 | 340 | 是 | 50 | 4 | 160 |
a2-highgpu-8g |
96 | 680 | 是 | 100 | 8 | 320 |
a2-megagpu-16g |
96 | 1,360 | 是 | 100 | 16 | 640 |
1每个 vCPU 是在其中一个可用的 CPU 平台上以单个硬件超线程的形式实现的。
2 出站流量带宽上限不能超过给定的数量。实际的出站带宽取决于目的地 IP 地址和其他因素。如需详细了解网络带宽,请参阅网络带宽。
3GPU 内存是 GPU 设备上的内存,可用于临时存储数据。它与实例的内存分开,专门用于处理图形密集型工作负载的更高带宽需求。
G4 机器类型
G4 加速器优化型机器类型使用 NVIDIA RTX PRO 6000 Blackwell 服务器版 GPU (nvidia-rtx-pro-6000),适用于 NVIDIA Omniverse 模拟工作负载、图形密集型应用、视频转码和虚拟桌面。与 A 系列机器类型相比,G4 机器类型还提供了一种低成本解决方案来执行单主机推理和模型调优。
| 挂接了 NVIDIA RTX PRO 6000 GPU | |||||||
|---|---|---|---|---|---|---|---|
| 机器类型 | vCPU 数量1 | 实例内存 (GB) | 支持的最大 Titanium SSD (GiB)2 | 物理 NIC 数量 | 网络带宽上限 (Gbps)3 | GPU 数量 | GPU 内存4 (GB GDDR7) |
g4-standard-48 |
48 | 180 | 1,500 | 1 | 50 | 1 | 96 |
g4-standard-96 |
96 | 360 | 3000 | 1 | 100 | 2 | 192 |
g4-standard-192 |
192 | 720 | 6000 | 1 | 200 | 4 | 384 |
g4-standard-384 |
384 | 1,440 | 12,000 | 2 | 400 | 8 | 768 |
1每个 vCPU 是在其中一个可用的 CPU 平台上以单个硬件超线程的形式实现的。
2您可以在创建 G4 实例时添加 Titanium SSD 磁盘。如需了解可挂接的磁盘数量,请参阅需要您选择本地 SSD 磁盘数量的机器类型。
3出站带宽上限不能超过给定的数量。实际的出站带宽取决于目的地 IP 地址和其他因素。请参阅网络带宽。
4GPU 内存是 GPU 设备上的内存,可用于临时存储数据。它与实例的内存分开,专门用于处理图形密集型工作负载的更高带宽需求。
G2 机器类型
G2 加速器优化机器类型挂接了 NVIDIA L4 GPU,非常适合注重成本效益的推理、图形密集型和高性能计算工作负载。
每种 G2 机器类型还具有默认内存和自定义内存范围。自定义内存范围定义了您可以为每种机器类型分配的实例内存量。您还可以在创建 G2 实例时添加本地 SSD 磁盘。如需了解可挂接的磁盘数量,请参阅需要您选择本地 SSD 磁盘数量的机器类型。
如需为大多数 GPU 实例获得更高的网络带宽速度(50 Gbps 或更高),建议您使用 Google 虚拟 NIC (gVNIC)。如需详细了解如何创建使用 gVNIC 的 GPU 实例,请参阅创建使用更高带宽的 GPU 实例。
| 挂接了 NVIDIA L4 GPU | |||||||
|---|---|---|---|---|---|---|---|
| 机器类型 | vCPU 数量1 | 默认实例内存 (GB) | 自定义实例内存范围 (GB) | 支持的最大本地 SSD (GiB) | 网络带宽上限 (Gbps)2 | GPU 数量 | GPU 内存3 (GB GDDR6) |
g2-standard-4 |
4 | 16 | 16 - 32 | 375 | 10 | 1 | 24 |
g2-standard-8 |
8 | 32 | 32 - 54 | 375 | 16 | 1 | 24 |
g2-standard-12 |
12 | 48 | 48 - 54 | 375 | 16 | 1 | 24 |
g2-standard-16 |
16 | 64 | 54 - 64 | 375 | 32 | 1 | 24 |
g2-standard-24 |
24 | 96 | 96 - 108 | 750 | 32 | 2 | 48 |
g2-standard-32 |
32 | 128 | 96 - 128 | 375 | 32 | 1 | 24 |
g2-standard-48 |
48 | 192 | 192 - 216 | 1500 | 50 | 4 | 96 |
g2-standard-96 |
96 | 384 | 384 - 432 | 3000 | 100 | 8 | 192 |
1每个 vCPU 是在其中一个可用的 CPU 平台上以单个硬件超线程的形式实现的。
2 出站流量带宽上限不能超过给定的数量。实际的出站带宽取决于目的地 IP 地址和其他因素。如需详细了解网络带宽,请参阅网络带宽。
3GPU 内存是 GPU 设备上的内存,可用于临时存储数据。它与实例的内存分开,专门用于处理图形密集型工作负载的更高带宽需求。
N1 + GPU 机器类型
对于挂接了 T4 和 V100 GPU 的 N1 通用实例,您可以获得高达 100 Gbps 的最大网络带宽,具体取决于 GPU 和 vCPU 的数量组合。如需了解所有其他 N1 GPU 实例,请参阅概览。
请参阅以下部分,根据 GPU 型号、vCPU 和 GPU 数量计算可用于 T4 和 V100 实例的最大网络带宽。
少于 5 个 vCPU
对于具有 5 个或更少 vCPU 的 T4 和 V100 实例,可用的最大网络带宽为 10 Gbps。
超过 5 个 vCPU
对于具有超过 5 个 vCPU 的 T4 和 V100 实例,最大网络带宽根据该虚拟机的 vCPU 和 GPU 数量计算得出。
如需为大多数 GPU 实例获得更高的网络带宽速度(50 Gbps 或更高),建议您使用 Google 虚拟 NIC (gVNIC)。如需详细了解如何创建使用 gVNIC 的 GPU 实例,请参阅创建使用更高带宽的 GPU 实例。
| GPU 模型 | GPU 数量 | 最大网络带宽计算 |
|---|---|---|
| NVIDIA V100 | 1 | min(vcpu_count * 2, 32) |
| 2 | min(vcpu_count * 2, 32) |
|
| 4 | min(vcpu_count * 2, 50) |
|
| 8 | min(vcpu_count * 2, 100) |
|
| NVIDIA T4 | 1 | min(vcpu_count * 2, 32) |
| 2 | min(vcpu_count * 2, 50) |
|
| 4 | min(vcpu_count * 2, 100) |
MTU 设置和 GPU 机器类型
如需最大限度地提高网络带宽,请为 VPC 网络设置较高的最大传输单元 (MTU) 值。较高的 MTU 值会增加数据包大小并降低数据包标头开销,从而增加载荷数据吞吐量。
对于 GPU 机器类型,建议按下表配置 VPC 网络的 MTU 设置。
| GPU 机器类型 | 建议的 MTU(以字节为单位) | |
|---|---|---|
| VPC 网络 | 采用 RDMA 配置文件的 VPC 网络 | |
|
8896 | 8896 |
|
8244 | 不适用 |
|
8896 | 不适用 |
设置 MTU 值时,请注意以下事项:
- 8192 值对应两个 4 KB 页面。
- 对于启用了标头拆分的 GPU NIC,建议在 A3 Mega、A3 High 和 A3 Edge 虚拟机中使用 8244 值。
- 除非表格中另有说明,否则请使用 8896 值。
创建高带宽 GPU 机器
如需创建使用更高网络带宽的 GPU 实例,请根据机器类型使用以下方法之一:
如需创建使用更高网络带宽的 A2、G2 和 N1 实例,请参阅为 A2、G2 和 N1 实例使用更高的网络带宽。如需测试或验证这些机器的带宽速度,您可以使用基准化分析测试。如需了解详情,请参阅检查网络带宽。
如需创建使用更高网络带宽的 A3 Mega 实例,请参阅部署 A3 Mega Slurm 集群以用于机器学习训练。如需测试或验证这些机器的带宽速度,请按照检查网络带宽中的步骤进行基准化分析测试。
对于使用更高网络带宽的 A3 High 和 A3 Edge 实例,请参阅创建启用了 GPUDirect-TCPX 的 A3 虚拟机。如需测试或验证这些机器的带宽速度,您可以使用基准化分析测试。如需了解详情,请参阅检查网络带宽。
对于其他加速器优化机器类型,无需执行任何操作即可使用更高的网络带宽;按照文档中的说明创建实例时已使用高网络带宽。如需了解如何为其他加速器优化机器类型创建实例,请参阅创建挂接了 GPU 的虚拟机。
后续步骤
- 详细了解 GPU 平台。
- 了解如何创建挂接了 GPU 的实例。
- 了解如何使用更高的网络带宽。
- 了解 GPU 价格。