
Este documento explica o ciclo de vida de uma instância do Compute Engine, abrangendo os vários estados pelos quais pode passar desde a criação até à eliminação. Para saber como verificar o estado de uma ou mais instâncias, consulte o seguinte:
Compreender o ciclo de vida de uma instância permite-lhe fazer o seguinte de forma mais eficaz:
Resolva problemas de instâncias.
Faça a gestão dos recursos de instâncias.
Planeie migrações de instâncias.
Estados da instância
Uma instância de computação pode passar por diferentes estados como parte do respetivo ciclo de vida. Quando cria uma instância, o Compute Engine aprovisiona recursos para a iniciar. Depois, a instância passa para a fase de preparação e prepara-se para o primeiro arranque. Depois de a instância ser iniciada, considera-se que está em execução. Pode parar e reiniciar repetidamente uma instância em execução, ou suspendê-la e retomá-la, até à respetiva eliminação.
O diagrama seguinte mostra os diferentes estados que o Compute Engine pode definir para uma instância:
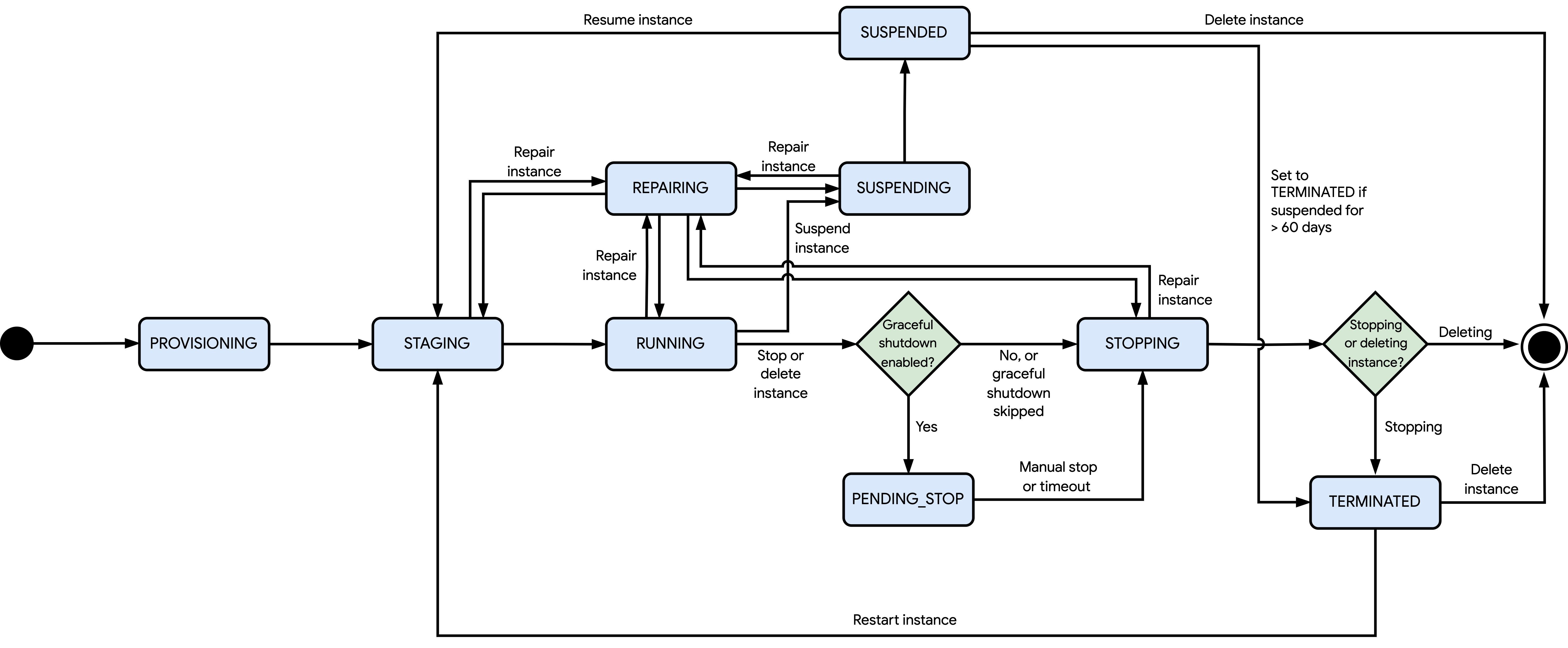
Os estados apresentados no diagrama anterior são os seguintes:
PENDING: depois de criar uma VM de início flexível com um tempo de espera (requestValidForDuration) de 90 segundos ou mais, o estado da VM muda paraPENDING. Neste estado, o Compute Engine tenta adquirir os recursos necessários para iniciar a VM até que o tempo de espera termine. Se o Compute Engine adquirir os recursos dentro deste período e tiver quota suficiente para esses recursos, o estado da VM muda paraPROVISIONING. Caso contrário, ocorre um erro e o Compute Engine elimina a VM de início flexível. Opcionalmente, pode eliminar a VM de início flexível antes do fim do tempo de espera se já não precisar da VM.PROVISIONING: depois de criar, reiniciar ou retomar uma instância, o Compute Engine atribui recursos à instância.STAGING: o Compute Engine está a preparar a instância para o primeiro arranque devido a um dos seguintes motivos:O Compute Engine ainda está a criar e configurar a instância.
Você ou uma operação agendada pediram para reiniciar ou retomar a instância.
Neste estado, a instância ainda não está em execução.
RUNNING: o Compute Engine está a arrancar a instância ou a instância está em execução. Neste estado, pode parar, suspender ou eliminar a instância. Além disso, o Compute Engine pode parar ou eliminar a instância para operações agendadas, ou reparar a instância se ocorrer um erro de hardware e a instância fizer parte de um grupo de instâncias geridas (GIG).PENDING_STOP: a instância está a ser encerrada de forma controlada. Este processo de encerramento só ocorre se tiver ativado o encerramento controlado e tiver pedido para parar ou eliminar a instância, ou o Compute Engine o estiver a fazer automaticamente para uma paragem ou eliminação agendada. O estado da instância muda paraSTOPPINGquando ocorre uma das seguintes situações:Terminar manualmente o encerramento controlado.
O período de encerramento controlado expira. Se ainda estiverem a ser executadas tarefas, o Compute Engine força a respetiva paragem.
STOPPING: a instância está a encerrar o SO convidado, o que acontece nos seguintes cenários:A instância foi parada ou eliminada por si ou por uma operação agendada.
Ocorreu um erro de hardware.
A menos que configure a instância para ignorar o encerramento do SO convidado, o tempo de encerramento depende do tipo de instância. No entanto, se a instância parar devido a um erro de hardware, o tempo de encerramento pode diferir da duração esperada. Depois de o SO convidado ser encerrado e, com base na operação em execução, o Compute Engine faz uma das seguintes ações:
O Compute Engine conclui a operação de paragem e altera o estado da instância para
TERMINATED.O Compute Engine elimina a instância e todos os recursos anexados.
TERMINATED: o Compute Engine concluiu a operação de paragem. Os recursos anexados permanecem anexados, a menos que os desanexe. Neste estado, a instância permanece parada até a reiniciar ou eliminar. Se pedir para reiniciar a instância, mas o Compute Engine não conseguir atribuir os recursos pedidos, o pedido de reinício falha e a instância permanece no estadoTERMINATED. Caso contrário, o pedido de reinício é bem-sucedido e o estado da instância muda paraPROVISIONING.REPAIRING: o Compute Engine está a reparar a instância. O Compute Engine repara uma instância se encontrar um erro interno ou se o servidor anfitrião da instância estiver indisponível devido a manutenção. Enquanto uma instância está em reparação, acontece o seguinte:Não pode usar a instância.
O contrato de nível de serviço (SLA) não abrange a instância.
Se o Compute Engine reparar a instância com êxito, o estado da instância é reposto para o estado original antes do início da operação de reparação. Este estado pode ser
STAGING,RUNNING,SUSPENDINGouSTOPPING. Se a sua instância estiver configurada para reiniciar automaticamente (automaticRestart) após a conclusão da operação de reparação, pode optar por parar a instância durante o processo de reparação. Esta ação impede o reinício automático da instância após a conclusão da reparação, deixando a instância no estadoTERMINATED.SUSPENDING: o Compute Engine iniciou a operação de suspensão da instância depois de ter pedido a suspensão. Neste estado, só pode aguardar a conclusão da operação de suspensão.SUSPENDED: o Compute Engine concluiu a operação de suspensão. Neste estado, pode retomar ou eliminar a instância. Se pedir para retomar a instância, mas o Compute Engine não conseguir atribuir os recursos pedidos, o pedido de retoma falha e a instância permanece no estadoSUSPENDED. Caso contrário, o pedido de retoma é bem-sucedido e o estado da instância é alterado paraPROVISIONING. A instância pode permanecer no estadoSUSPENDEDdurante um máximo de 60 dias. Após esse período, o Compute Engine altera o estado da instância paraTERMINATED.
Falha de hardware
Raramente, uma instância de computação pode falhar devido a uma interrupção inesperada, um erro de hardware ou outro problema do sistema. A Google recomenda a mitigação de falhas de hardware através da utilização de volumes de armazenamento persistentes, da realização de cópias de segurança dos seus dados de forma rotineira e da conceção do seu sistema de modo que uma única falha de instância não seja catastrófica. Para mais informações, veja como conceber sistemas robustos.
Se uma instância falhar, o Compute Engine reinicia automaticamente a instância com o mesmo disco de arranque, metadados e definições da instância. Para modificar o comportamento de reinício automático de uma instância, consulte o artigo Defina a política de manutenção do anfitrião para uma instância de computação.
Preços
A cobrança de uma instância de computação é feita da seguinte forma:
Para a utilização da CPU, a cobrança é feita quando a instância se encontra nos seguintes estados:
RUNNINGPENDING_STOP
Para a utilização de memória, é-lhe cobrado um valor quando a instância se encontra nos seguintes estados:
RUNNINGPENDING_STOPSUSPENDINGSUSPENDED
Para recursos anexados, como discos ou endereços IP externos, é cobrado um valor até que os recursos existam, independentemente do estado da instância.
Para mais informações, consulte os preços das instâncias de VM.
O que se segue?
Para ver o estado de uma ou mais instâncias de computação, faça o seguinte: