
En este tutorial interactivo se muestra cómo usar la reparación automática para crear aplicaciones de alta disponibilidad en Compute Engine.
Las aplicaciones de alta disponibilidad están diseñadas para satisfacer las necesidades de los clientes con una latencia y un tiempo de inactividad mínimos. La disponibilidad se ve comprometida cuando una aplicación falla o se bloquea. Los clientes de una aplicación vulnerada pueden experimentar una latencia alta o un tiempo de inactividad.
La reparación automática te permite reiniciar automáticamente las aplicaciones que se hayan visto comprometidas. Detecta rápidamente las instancias de máquinas virtuales (VMs) que han fallado y las vuelve a crear automáticamente para que se pueda volver a atender a los clientes. Con la reparación automática, ya no es necesario volver a poner en funcionamiento una aplicación manualmente después de un fallo.
Objetivos
- Configura una comprobación del estado y una política de reparación automática.
- Configura un servicio web de demostración en un grupo de instancias gestionado.
- Simula fallos en las comprobaciones del estado y observa el proceso de recuperación de la reparación automática.
Costes
En este tutorial se usan componentes facturables de Cloud de Confiance by S3NS , entre los que se incluyen los siguientes:- Compute Engine
Antes de empezar
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles. - Comprobación del estado: una política de comprobación del estado HTTP que usa el autohealer para detectar las VMs que han fallado.
- Reglas de cortafuegos: Cloud de Confiance las reglas de cortafuegos te permiten permitir o denegar el tráfico a tus VMs.
- Grupo de instancias gestionado: un grupo de VMs que ejecutan el mismo servicio web de demostración.
- Plantilla de instancia: plantilla que se usa para crear cada VM del grupo de instancias.
Crea una comprobación del estado.
En la Cloud de Confiance consola, ve a la página Crear comprobación del estado.
En el campo Name (Nombre), introduce
autohealer-check.Define el ámbito en
Regional.En el desplegable Región, selecciona
europe-west1.En Protocolo, selecciona
HTTP.Asigna el valor
/healtha Ruta de solicitud. Indica la ruta HTTP que usa la comprobación de estado. En este tutorial, el servidor web de demostración define la ruta/healthpara devolver una respuestaHTTP 200 (OK)cuando el estado sea correcto o una respuestaHTTP 500 (Internal Server Error)cuando el estado no sea correcto.Defina los criterios de estado:
- Asigna el valor
10a Intervalo de comprobación. Define el tiempo que transcurre desde el inicio de una sonda hasta el inicio de la siguiente. - Define Tiempo de espera en
5. Define el tiempo queCloud de Confiance espera una respuesta a una petición. Este valor debe ser inferior o igual al intervalo de comprobación. - Define el Umbral en buen estado en
2. Define el número de sondeos secuenciales que deben completarse correctamente para que la VM se considere en buen estado. - Define Umbral en mal estado en
3. Define el número de sondeos secuenciales que deben fallar para que la VM se considere en mal estado.
- Asigna el valor
Deje los valores predeterminados de las demás opciones.
En la parte inferior, haz clic en Crear.
Crea una regla de cortafuegos para permitir que las sondas de comprobación del estado hagan solicitudes HTTP.
En la Cloud de Confiance consola, ve a la página Crear regla de cortafuegos.
En Nombre, escribe
default-allow-http-health-check.En Red, selecciona
default.En Objetivos, selecciona
All instances in the network.En Filtro de origen, selecciona
IPv4 ranges.En Intervalos IPv4 de origen, introduce
130.211.0.0/22, 35.191.0.0/16.En Protocolos y puertos, selecciona TCP e introduce
80.Deje los valores predeterminados de las demás opciones.
Haz clic en Crear.
Crea una comprobación del estado con el comando
health-checks create http.gcloud compute health-checks create http autohealer-check \ --region europe-west1 \ --check-interval 10 \ --timeout 5 \ --healthy-threshold 2 \ --unhealthy-threshold 3 \ --request-path "/health"check-intervaldefine el tiempo que transcurre desde el inicio de una comprobación hasta el inicio de la siguiente.timeoutdefine el tiempo que Cloud de Confiance espera una respuesta a una petición. Este valor debe ser inferior o igual al intervalo de comprobación.healthy-thresholddefine el número de sondeos secuenciales que deben realizarse correctamente para que la VM se considere en buen estado.unhealthy-thresholddefine el número de sondeos secuenciales que deben fallar para que la VM se considere en mal estado.request-pathindica qué ruta HTTP usa la comprobación de estado. En este tutorial, el servidor web de demostración define la ruta/healthpara devolver una respuestaHTTP 200 (OK)cuando está en buen estado o una respuestaHTTP 500 (Internal Server Error)cuando no lo está.
Crea una regla de cortafuegos para permitir que las sondas de comprobación del estado hagan solicitudes HTTP.
gcloud compute firewall-rules create default-allow-http-health-check \ --network default \ --allow tcp:80 \ --source-ranges 130.211.0.0/22,35.191.0.0/16unhealthy-threshold. Debe ser superior a1. Lo ideal es que este valor sea3o más. De esta forma, se protege frente a fallos poco frecuentes, como la pérdida de paquetes de red.healthy-threshold. Un valor de2es suficiente para la mayoría de las aplicaciones.timeout. Asigna a este valor de tiempo una cantidad generosa (cinco veces o más que el tiempo de respuesta esperado). De esta forma, se evitan retrasos inesperados, como instancias ocupadas o una conexión de red lenta.check-interval. Este valor debe estar entre 1 segundo y el doble del tiempo de espera (no debe ser demasiado largo ni demasiado corto). Cuando un valor es demasiado largo, no se detecta una instancia fallida con la suficiente antelación. Si un valor es demasiado corto, las instancias y la red pueden estar muy ocupadas, dado el gran número de sondeos de comprobación de estado que se envían cada segundo.Crea una plantilla de instancia. Incluye una secuencia de comandos de inicio que inicie el servidor web de demostración.
En la Cloud de Confiance consola, ve a la página Crear plantilla de instancia.
Asigna el valor
webserver-templatea Nombre.En la sección Ubicación, en el menú desplegable Región, selecciona europe-west1.
En la sección Configuración de la máquina, en el menú desplegable Tipo de máquina, selecciona e2-medium.
En la sección Cortafuegos, selecciona la casilla Permitir el tráfico HTTP.
Expande la sección Opciones avanzadas para ver la configuración avanzada. Aparecerán varias subsecciones.
En la sección Management (Gestión), busca Automation (Automatización) e introduce la siguiente Startup script (Secuencia de comandos de inicio):
apt-get update apt-get -y install git python3-pip python3-venv git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git python3 -m venv venv ./venv/bin/pip3 install -Ur ./python-docs-samples/compute/managed-instances/demo/requirements.txt ./venv/bin/pip3 install gunicorn ./venv/bin/gunicorn --bind 0.0.0.0:80 app:app --daemon --chdir ./python-docs-samples/compute/managed-instances/demo
Deje los valores predeterminados de las demás opciones.
Haz clic en Crear.
Despliega el servidor web como un grupo de instancias gestionado.
En la Cloud de Confiance consola, ve a la página Crear grupo de instancias.
Asigna el valor
webserver-groupa Nombre.En Plantilla de instancia, selecciona
webserver-template.En Región, selecciona
europe-west1.En Zona, selecciona
europe-west1-b.En la sección Autoescalado, en Modo de autoescalado, selecciona Desactivado: no autoescalar.
Vuelve al campo Número de instancias y asigna el valor
3.En la sección Autorreparación, haga lo siguiente:
- En el menú desplegable Comprobación del estado, selecciona
autohealer-check. Define Retraso inicial en
300.
- En el menú desplegable Comprobación del estado, selecciona
Deje los valores predeterminados de las demás opciones.
Haz clic en Crear.
Crea una regla de cortafuegos que permita las solicitudes HTTP a los servidores web.
En la Cloud de Confiance consola, ve a la página Crear regla de cortafuegos.
En Nombre, escribe
default-allow-http.En Red, selecciona
default.En Objetivos, selecciona
Specified target tags.En Etiquetas de destino, introduzca
http-server.En Filtro de origen, selecciona
IPv4 ranges.En Intervalos de IPv4 de origen, introduzca
0.0.0.0/0para permitir el acceso a todas las direcciones IP.En Protocolos y puertos, selecciona TCP e introduce
80.Deje los valores predeterminados de las demás opciones.
Haz clic en Crear.
Crea una plantilla de instancia. Incluye una secuencia de comandos de inicio que inicie el servidor web de demostración.
gcloud compute instance-templates create webserver-template \ --instance-template-region europe-west1 \ --machine-type e2-medium \ --tags http-server \ --metadata startup-script=' apt-get update apt-get -y install git python3-pip python3-venv git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git python3 -m venv venv ./venv/bin/pip3 install -Ur ./python-docs-samples/compute/managed-instances/demo/requirements.txt ./venv/bin/pip3 install gunicorn ./venv/bin/gunicorn --bind 0.0.0.0:80 app:app --daemon --chdir ./python-docs-samples/compute/managed-instances/demo'Crea un grupo de instancias gestionado.
gcloud compute instance-groups managed create webserver-group \ --zone europe-west1-b \ --template projects/PROJECT_ID/regions/europe-west1/instanceTemplates/webserver-template \ --size 3 \ --health-check projects/PROJECT_ID/regions/europe-west1/healthChecks/autohealer-check \ --initial-delay 300Crea una regla de cortafuegos que permita las solicitudes HTTP a los servidores web.
gcloud compute firewall-rules create default-allow-http \ --network default \ --allow tcp:80 \ --target-tags http-serverVe a una VM de servidor web.
En la consola de Cloud de Confiance , ve a la página Instancias de VM.
En cualquier VM
webserver-group, en la columna IP externa, haz clic en la dirección IP. Se abrirá una nueva pestaña en tu navegador web. Si se agota el tiempo de espera de la solicitud o la página web no está disponible, espera un minuto para que el servidor termine de configurarse y vuelve a intentarlo.
El servidor web de demostración muestra una página similar a la siguiente:
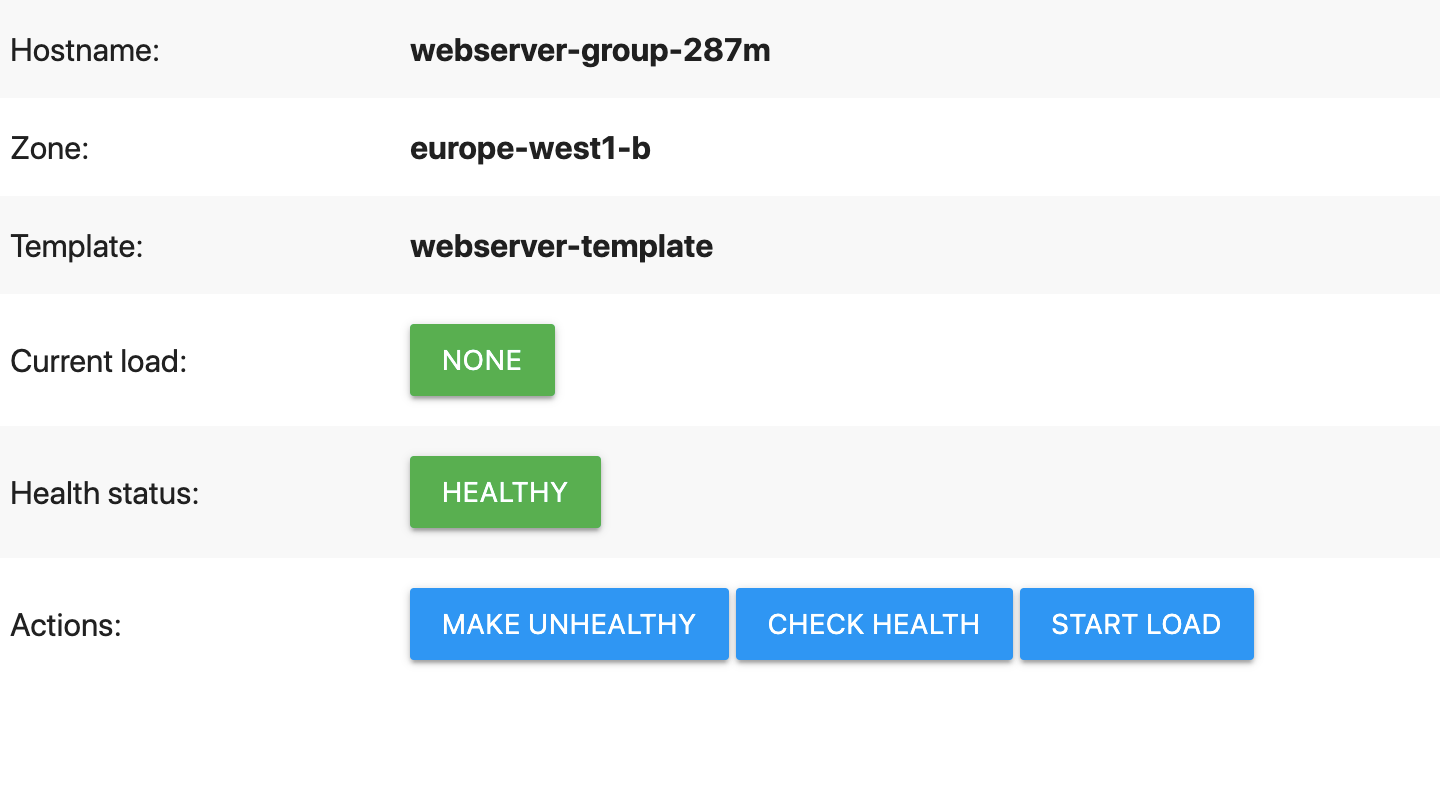
En la página web de demostración, haz clic en Make unhealthy (Hacer que no esté en buen estado)
Esto provoca que el servidor web no supere la comprobación del estado. En concreto, el servidor web hace que la ruta
/healthdevuelva unHTTP 500 (Internal Server Error). Puedes comprobarlo tú mismo haciendo clic rápidamente en el botón Comprobar estado (deja de funcionar después de que el proceso de reparación automática haya empezado a reiniciar la VM).Espera a que el sanador automático actúe.
En la consola de Cloud de Confiance , ve a la página Instancias de VM.
Espera a que cambie el estado de la VM del servidor web. La marca de verificación verde situada junto al nombre de la VM debería cambiar a un cuadrado gris, lo que indica que el autocomprobador ha empezado a reiniciar la VM en mal estado.
Haz clic en Actualizar en la parte superior de la página periódicamente para ver el estado más reciente.
El proceso de reparación automática finaliza cuando el cuadrado gris vuelve a ser una marca de verificación verde, lo que indica que la VM vuelve a estar en buen estado.
Monitoriza el estado del grupo de instancias gestionado. Cuando hayas terminado, detén la grabación pulsando
Ctrl+C.while : ; do gcloud compute instance-groups managed list-instances webserver-group \ --zone europe-west1-b sleep 5 # Wait for 5 seconds done
NAME: webserver-group-0zx6 ZONE: europe-west1-b STATUS: RUNNING HEALTH_STATE: HEALTHY ACTION: NONE INSTANCE_TEMPLATE: webserver-template VERSION_NAME: LAST_ERROR: NAME: webserver-group-4qbx ZONE: europe-west1-b STATUS: RUNNING HEALTH_STATE: HEALTHY ACTION: NONE INSTANCE_TEMPLATE: webserver-template VERSION_NAME: LAST_ERROR: NAME: webserver-group-m5v5 ZONE: europe-west1-b STATUS: RUNNING HEALTH_STATE: HEALTHY ACTION: NONE INSTANCE_TEMPLATE: webserver-template VERSION_NAME: LAST_ERROR:
Todas las máquinas virtuales del grupo deben mostrar
STATUS: RUNNINGyACTION: NONE. Si no es así, espera unos minutos para que las VMs terminen de configurarse y vuelve a intentarlo.Abre una nueva sesión de Cloud Shell con Google Cloud CLI instalado.
Obtén la dirección de una VM de servidor web.
gcloud compute instances list --filter webserver-group
En la columna
EXTERNAL_IP, copia la dirección IP de cualquier servidor web VM y guárdala como una variable bash local.export IP_ADDRESS=EXTERNAL_IP_ADDRESS
Comprueba que el servidor web haya terminado de configurarse. El servidor devuelve una respuesta
HTTP 200 OK.curl --head $IP_ADDRESS/health
HTTP/1.1 200 OK Server: gunicorn ...
Si aparece un error
Connection refused, espera un minuto para que el servidor termine de configurarse y vuelve a intentarlo.Hacer que el servidor web no esté en buen estado.
curl $IP_ADDRESS/makeUnhealthy > /dev/null
Esto provoca que el servidor web no supere la comprobación del estado. En concreto, el servidor web hace que la ruta
/healthdevuelva unHTTP 500 INTERNAL SERVER ERROR. Puedes comprobarlo tú mismo haciendo una solicitud rápida a/health(dejará de funcionar después de que el autorreparador haya empezado a reiniciar la VM).curl --head $IP_ADDRESS/health
HTTP/1.1 500 INTERNAL SERVER ERROR Server: gunicorn ...
Vuelve a la primera sesión de shell para monitorizar el grupo de instancias gestionado y espera a que el reparador automático actúe.
Cuando se inicia el proceso de reparación automática, se actualizan las columnas
STATUSyACTION, lo que indica que el reparador automático ha empezado a reiniciar la VM en mal estado.NAME: webserver-group-0zx6 ZONE: europe-west1-b STATUS: STOPPING HEALTH_STATE: UNHEALTHY ACTION: RECREATING INSTANCE_TEMPLATE: webserver-template VERSION_NAME: LAST_ERROR: ...
El proceso de reparación automática habrá finalizado cuando la VM vuelva a informar de un
STATUSdeRUNNINGy de unACTIONdeNONE, lo que indica que la VM se ha reiniciado correctamente.NAME: webserver-group-0zx6 ZONE: europe-west1-b STATUS: RUNNING HEALTH_STATE: HEALTHY ACTION: NONE INSTANCE_TEMPLATE: webserver-template VERSION_NAME: LAST_ERROR: ...
Cuando hayas terminado de monitorizar el grupo de instancias gestionado, detente pulsando
Ctrl+C.
¿Qué ocurre si todas las máquinas virtuales no están en buen estado al mismo tiempo? Para obtener más información sobre el comportamiento de la reparación automática durante los fallos simultáneos, consulta Comportamiento de la reparación automática.
¿Puedes actualizar la configuración de la comprobación de estado para reparar las VMs lo más rápido posible? En la práctica, deberías definir los parámetros de comprobación del estado para usar valores conservadores, tal como se explica en este tutorial. De lo contrario, corres el riesgo de que las VMs se eliminen y reinicien por error cuando no haya ningún problema real.
El grupo de instancias gestionado tiene un ajuste de configuración
initial delay. ¿Puedes determinar el retraso mínimo necesario para este servidor web de demostración? En la práctica, deberías definir un tiempo de espera algo más largo (entre un 10 y un 20 %) del que tarda una VM en iniciarse y empezar a atender solicitudes de la aplicación. De lo contrario, la VM podría quedarse atascada en un bucle de arranque de reparación automática.- In the Cloud de Confiance console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- In the Cloud de Confiance console, go to the Instance groups page.
-
Select the checkbox for
your
webserver-groupinstance group. - To delete the instance group, click Delete.
En la Cloud de Confiance consola, ve a la página Plantillas de instancia.
Haga clic en la casilla situada junto a la plantilla de instancia.
En la parte superior de la página, haz clic en Eliminar. En la nueva ventana, haz clic en Eliminar para confirmar la acción.
En la Cloud de Confiance consola, ve a la página Comprobaciones de estado.
Haga clic en la casilla situada junto a la comprobación de estado.
En la parte superior de la página, haz clic en Eliminar. En la nueva ventana, haz clic en Eliminar para confirmar la acción.
En la Cloud de Confiance consola, ve a la página Reglas de cortafuegos.
Haga clic en las casillas situadas junto a las reglas de cortafuegos llamadas
default-allow-httpydefault-allow-http-health-check.En la parte superior de la página, haz clic en Eliminar. En la nueva ventana, haz clic en Eliminar para confirmar la acción.
- Prueba otro tutorial:
- Más información sobre los grupos de instancias gestionados
- Consulta más información sobre cómo diseñar sistemas sólidos.
- Consulta más información sobre cómo crear aplicaciones web escalables y resilientes en Cloud de Confiance.
In the Cloud de Confiance console, on the project selector page, select or create a Cloud de Confiance project.
Roles required to select or create a project
Verify that billing is enabled for your Cloud de Confiance project.
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
Si prefieres trabajar desde la línea de comandos, instala la CLI de Google Cloud.
Instala Google Cloud CLI y, a continuación, inicia sesión en gcloud CLI con tu identidad federada. Después de iniciar sesión, inicializa la CLI de Google Cloud ejecutando el siguiente comando:
gcloud initArquitectura de la aplicación
La aplicación incluye los siguientes componentes de Compute Engine:
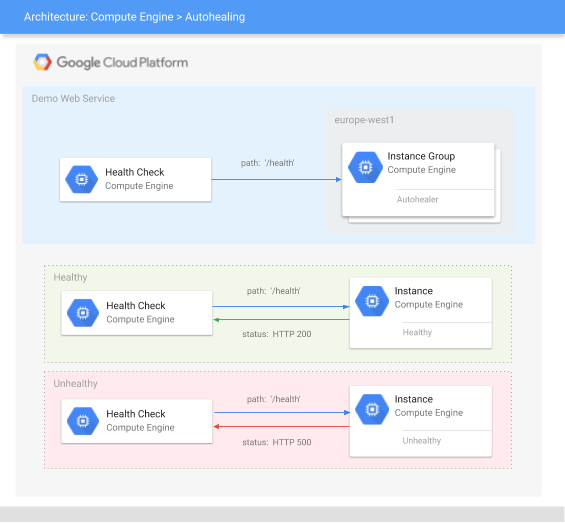
Cómo comprueba el estado la sonda del servicio web de demostración
Una comprobación de estado envía solicitudes de sondeo a una VM mediante un protocolo especificado, como HTTP(S), SSL o TCP. Para obtener más información, consulta cómo funcionan las comprobaciones del estado y las categorías, protocolos y puertos de las comprobaciones del estado.
La comprobación del estado de este tutorial es una comprobación del estado de HTTP que comprueba la ruta HTTP /health en el puerto 80. En el caso de las comprobaciones del estado HTTP, la solicitud de sondeo solo se completa si la ruta devuelve una respuesta HTTP 200 (OK). En este tutorial, el servidor web de demostración define la ruta /health para devolver una respuesta HTTP 200 (OK) cuando está en buen estado o una respuesta HTTP 500 (Internal Server Error) cuando no lo está.
Para obtener más información, consulta los criterios de éxito de HTTP, HTTPS y HTTP/2.
Crea la comprobación del estado
Para configurar la reparación automática, crea una comprobación del estado personalizada y configura el cortafuegos de red para permitir las sondas de comprobación del estado.
En este tutorial, creará una comprobación del estado regional. Para la reparación automática, puedes usar una comprobación del estado regional o global. Las comprobaciones del estado regionales reducen las dependencias entre regiones y ayudan a conseguir la residencia de datos. Las comprobaciones del estado globales son útiles si quieres usar la misma comprobación del estado para MIGs de varias regiones.
Consola
gcloud
Qué hace que una comprobación del estado de reparación automática sea buena
Las comprobaciones del estado que se usan para la reparación automática deben ser conservadoras para que no eliminen y vuelvan a crear tus instancias de forma preventiva. Si una comprobación del estado de la reparación automática es demasiado agresiva, es posible que la reparación automática confunda las instancias ocupadas con las instancias fallidas y las reinicie innecesariamente, lo que reducirá la disponibilidad.
Configurar el servicio web
En este tutorial se usa una aplicación web almacenada en GitHub. Si quieres obtener más información sobre cómo se ha implementado la aplicación, consulta el repositorio de GitHub GoogleCloudPlatform/python-docs-samples.
Para configurar el servicio web de demostración, crea una plantilla de instancia que inicie el servidor web de demostración al iniciarse. A continuación, usa esta plantilla de instancia para desplegar un grupo de instancias gestionado y habilita la reparación automática.
Consola
gcloud
Espera unos minutos a que el grupo de instancias gestionadas cree y verifique sus VMs.
Simular fallos en las comprobaciones del estado
Para simular errores en las comprobaciones del estado, el servidor web de demostración te ofrece formas de forzar un error en una comprobación del estado.
Consola
gcloud
Puedes repetir este ejercicio. A continuación, te ofrecemos algunas ideas:
Ver el historial de Autohealer (opcional)
Para ver el historial de operaciones de reparación automática, usa el siguiente comando gcloud:
gcloud compute operations list --filter='operationType~compute.instances.repair.*'
Para obtener más información, consulta cómo ver el historial de operaciones de reparación automática.
Limpieza
Cuando termines el tutorial, puedes eliminar los recursos que has creado para que dejen de usar cuota y generar cargos. En las siguientes secciones se explica cómo eliminar o desactivar dichos recursos.
Si has creado un proyecto independiente para este tutorial, elimínalo por completo. De lo contrario, si el proyecto tiene recursos que quieres conservar, elimina solo los recursos específicos que has creado en este tutorial.
Eliminar el proyecto
Eliminar recursos específicos
Si no puedes eliminar el proyecto que has usado en este tutorial, elimina los recursos del tutorial de forma individual.
Eliminar el grupo de instancias
consola
gcloud
gcloud compute instance-groups managed delete webserver-group --zone europe-west1-b -q
Eliminar la plantilla de instancia
consola
gcloud
gcloud compute instance-templates delete webserver-template -q \
--region=europe-west1
Eliminar la comprobación del estado
consola
gcloud
gcloud compute health-checks delete autohealer-check -q \
--region=europe-west1
Eliminar las reglas de cortafuegos
consola
gcloud
gcloud compute firewall-rules delete default-allow-http default-allow-http-health-check -q