
In dieser Anleitung erfahren Sie, wie Sie ein multivariates Zeitreihenmodell verwenden, um den zukünftigen Wert für eine bestimmte Spalte basierend auf dem historischen Wert mehrerer Eingabe-Features vorherzusagen.
In dieser Anleitung werden Prognosen für mehrere Zeitreihen erstellt. Die prognostizierten Werte werden für jeden Zeitpunkt und für jeden Wert in einer oder mehreren angegebenen Spalten berechnet. Wenn Sie beispielsweise das Wetter vorhersagen möchten und eine Spalte mit Bundesstaatsdaten angeben, enthalten die prognostizierten Daten Vorhersagen für alle Zeitpunkte für Bundesstaat A, dann prognostizierte Werte für alle Zeitpunkte für Bundesstaat B usw. Wenn Sie das Wetter vorhersagen möchten und Spalten mit Bundesstaat- und Stadtdaten angegeben haben, enthalten die vorhergesagten Daten Vorhersagen für alle Zeitpunkte für Bundesstaat A und Stadt A, dann vorhergesagte Werte für alle Zeitpunkte für Bundesstaat A und Stadt B usw.
In dieser Anleitung werden Daten aus den öffentlichen Tabellen bigquery-public-data.iowa_liquor_sales.sales und bigquery-public-data.covid19_weathersource_com.postal_code_day_history verwendet. Die Tabelle bigquery-public-data.iowa_liquor_sales.sales enthält Daten zum Spirituosenverkauf, die in mehreren Städten im Bundesstaat Iowa erhoben wurden. Die Tabelle bigquery-public-data.covid19_weathersource_com.postal_code_day_history enthält historische Wetterdaten wie Temperatur und Luftfeuchtigkeit aus aller Welt.
Bevor Sie diese Anleitung lesen, sollten Sie unbedingt Prognosen für einzelne Zeitachsen mit einem multivariaten Modell erstellen lesen.
Ziele
In dieser Anleitung werden Sie durch die folgenden Aufgaben geführt:
- Erstellen eines Zeitreihenmodells zur Prognose von Bestellungen in Spirituosengeschäften mit der Anweisung
CREATE MODEL. - Abrufen der prognostizierten Bestellwerte aus dem Modell mit der Funktion
ML.FORECAST. - Abrufen von Komponenten der Zeitreihe, z. B. Saisonalität, Trend und Feature-Attributionen, mithilfe der Funktion
ML.EXPLAIN_FORECAST. Sie können diese Zeitreihenkomponenten untersuchen, um die prognostizierten Werte zu erklären. - Bewerten Sie die Genauigkeit des Modells mit der Funktion
ML.EVALUATE. - Erkennen Sie Anomalien mit dem Modell und der Funktion
ML.DETECT_ANOMALIES.
Kosten
In dieser Anleitung werden kostenpflichtige Komponenten von Cloud de Confiance by S3NSverwendet, darunter:
- BigQuery
- BigQuery ML
Weitere Informationen zu den Kosten von BigQuery finden Sie auf der Seite BigQuery-Preise.
Weitere Informationen zu den Kosten für BigQuery ML finden Sie unter BigQuery ML-Preise.
Hinweis
-
In the Cloud de Confiance console, on the project selector page, select or create a Cloud de Confiance project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Cloud de Confiance project.
- BigQuery ist in neuen Projekten automatisch aktiviert.
Wenn Sie BigQuery in einem bestehenden Projekt aktivieren möchten, wechseln Sie zu
Aktivieren Sie die BigQuery API.
Rollen, die zum Aktivieren von APIs erforderlich sind
Zum Aktivieren von APIs benötigen Sie die IAM-Rolle „Service Usage-Administrator“ (
roles/serviceusage.serviceUsageAdmin), die die Berechtigungserviceusage.services.enableenthält. Weitere Informationen zum Zuweisen von Rollen
Dataset erstellen
Erstellen Sie ein BigQuery-Dataset zum Speichern Ihres ML-Modells.
Console
Rufen Sie in der Cloud de Confiance Console die Seite BigQuery auf.
Klicken Sie im Bereich Explorer auf den Namen Ihres Projekts.
Klicken Sie auf Aktionen ansehen > Dataset erstellen.
Führen Sie auf der Seite Dataset erstellen die folgenden Schritte aus:
Geben Sie unter Dataset-ID
bqml_tutorialein.Wählen Sie als Standorttyp die Option Multiregional und dann USA aus.
Übernehmen Sie die verbleibenden Standardeinstellungen unverändert und klicken Sie auf Dataset erstellen.
bq
Wenn Sie ein neues Dataset erstellen möchten, verwenden Sie den Befehl bq mk --dataset.
Erstellen Sie ein Dataset mit dem Namen
bqml_tutorialund legen Sie den Datenspeicherort aufUSfest.bq mk --dataset \ --location=US \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Prüfen Sie, ob das Dataset erstellt wurde:
bq ls
API
Rufen Sie die Methode datasets.insert mit einer definierten Dataset-Ressource auf.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
Tabelle mit Eingabedaten erstellen
Erstellen Sie eine Datentabelle, die Sie zum Trainieren und Bewerten des Modells verwenden können. In dieser Tabelle werden Spalten aus den Tabellen bigquery-public-data.iowa_liquor_sales.sales und bigquery-public-data.covid19_weathersource_com.postal_code_day_history kombiniert, um zu analysieren, wie sich das Wetter auf die Art und Anzahl der von Spirituosengeschäften bestellten Artikel auswirkt. Außerdem erstellen Sie die folgenden zusätzlichen Spalten, die Sie als Eingabevariablen für das Modell verwenden können:
date: das Datum der Bestellungstore_number: die eindeutige Nummer des Geschäfts, in dem die Bestellung aufgegeben wurdeitem_number: die eindeutige Nummer des bestellten Artikelsbottles_sold: die Anzahl der bestellten Flaschen des zugehörigen Artikelstemperature: die Durchschnittstemperatur am Standort des Geschäfts am Bestelldatumhumidity: die durchschnittliche Luftfeuchtigkeit am Standort des Geschäfts am Bestelldatum
So erstellen Sie die Eingabedatentabelle:
Rufen Sie in der Cloud de Confiance Console die Seite BigQuery auf.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
CREATE OR REPLACE TABLE `bqml_tutorial.iowa_liquor_sales_with_weather` AS WITH sales AS ( SELECT DATE, store_number, item_number, bottles_sold, SAFE_CAST(SAFE_CAST(zip_code AS FLOAT64) AS INT64) AS zip_code FROM `bigquery-public-data.iowa_liquor_sales.sales` AS sales WHERE SAFE_CAST(zip_code AS FLOAT64) IS NOT NULL ), aggregated_sales AS ( SELECT DATE, store_number, item_number, ANY_VALUE(zip_code) AS zip_code, SUM(bottles_sold) AS bottles_sold, FROM sales GROUP BY DATE, store_number, item_number ), weather AS ( SELECT DATE, SAFE_CAST(postal_code AS INT64) AS zip_code, avg_temperature_air_2m_f AS temperature, avg_humidity_specific_2m_gpkg AS humidity, FROM `bigquery-public-data.covid19_weathersource_com.postal_code_day_history` WHERE country = 'US' AND SAFE_CAST(postal_code AS INT64) IS NOT NULL ) SELECT aggregated_sales.date, aggregated_sales.store_number, aggregated_sales.item_number, aggregated_sales.bottles_sold, weather.temperature AS temperature, weather.humidity AS humidity FROM aggregated_sales LEFT JOIN weather ON aggregated_sales.zip_code=weather.zip_code AND aggregated_sales.DATE=weather.DATE;
Zeitachsenmodell erstellen
Erstellen Sie ein Zeitreihenmodell, um die Anzahl der verkauften Flaschen für jede Kombination aus Filial-ID und Artikel-ID für jedes Datum in der Tabelle bqml_tutorial.iowa_liquor_sales_with_weather vor dem 1. September 2022 zu prognostizieren. Verwenden Sie die durchschnittliche Temperatur und Luftfeuchtigkeit des Geschäftsstandorts an jedem Datum als Features für die Prognose. In der Tabelle bqml_tutorial.iowa_liquor_sales_with_weather gibt es etwa 1 Million eindeutige Kombinationen aus Artikelnummer und Filialnummer. Das bedeutet, dass 1 Million verschiedener Zeitreihen prognostiziert werden müssen.
So erstellen Sie das Modell:
Rufen Sie in der Cloud de Confiance Console die Seite BigQuery auf.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
CREATE OR REPLACE MODEL `bqml_tutorial.multi_time_series_arimax_model` OPTIONS( model_type = 'ARIMA_PLUS_XREG', time_series_id_col = ['store_number', 'item_number'], time_series_data_col = 'bottles_sold', time_series_timestamp_col = 'date' ) AS SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE < DATE('2022-09-01');
Die Abfrage dauert etwa 38 Minuten. Danach können Sie auf das Modell
multi_time_series_arimax_modelzugreifen. Da die Abfrage eineCREATE MODEL-Anweisung zum Erstellen eines Modells verwendet, werden keine Abfrageergebnisse ausgegeben.
Modell zum Vorhersagen von Daten verwenden
Mit der Funktion ML.FORECAST können Sie zukünftige Zeitachsenwerte prognostizieren.
In der folgenden GoogleSQL-Abfrage gibt die STRUCT(5 AS horizon, 0.8 AS confidence_level)-Klausel an, dass die Abfrage 5 zukünftige Zeitpunkte prognostiziert und ein Vorhersageintervall mit einem Konfidenzniveau von 80% generiert.
Die Datensignatur der Eingabedaten für die Funktion ML.FORECAST entspricht der Datensignatur der Trainingsdaten, die Sie zum Erstellen des Modells verwendet haben. Die Spalte bottles_sold ist nicht in der Eingabe enthalten, da dies die Daten sind, die das Modell vorhersagen soll.
So prognostizieren Sie Daten mit dem Modell:
Rufen Sie in der Cloud de Confiance Console die Seite BigQuery auf.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT * FROM ML.FORECAST ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (5 AS horizon, 0.8 AS confidence_level), ( SELECT * EXCEPT (bottles_sold) FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE>=DATE('2022-09-01') ) );
Die Antwort sollte in etwa so aussehen:
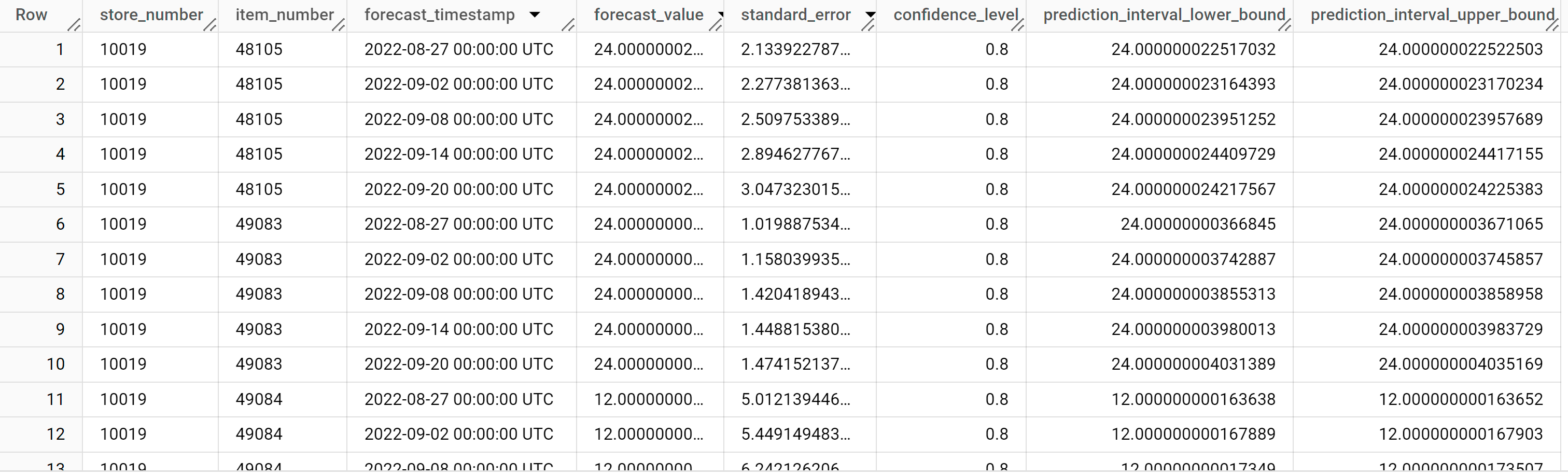
Die Ausgabezeilen werden nach dem Wert
store_number, dann nach dem Wertitem_IDund schließlich in chronologischer Reihenfolge nach dem Wert der Spalteforecast_timestampsortiert. In der Zeitachsenprognose ist das Vorhersageintervall, das durch die Spaltenwerteprediction_interval_lower_boundundprediction_interval_upper_bounddargestellt wird, genauso wichtig wie der Spaltenwertforecast_value. Derforecast_value-Wert ist der Mittelpunkt des Vorhersageintervalls. Das Vorhersageintervall hängt von den Spaltenwertenstandard_errorundconfidence_levelab.Weitere Informationen zu den Ausgabespalten finden Sie unter
ML.FORECAST.
Prognoseergebnisse erklären
Mit der Funktion ML.EXPLAIN_FORECAST können Sie neben Prognosedaten auch Messwerte zur Erklärbarkeit abrufen. Die Funktion ML.EXPLAIN_FORECAST prognostiziert zukünftige Zeitreihenwerte und gibt auch alle separaten Komponenten der Zeitreihe zurück.
Ähnlich wie bei der Funktion ML.FORECAST gibt die in der Funktion ML.EXPLAIN_FORECAST verwendete Klausel STRUCT(5 AS horizon, 0.8 AS confidence_level) an, dass die Abfrage 30 zukünftige Zeitpunkte prognostiziert und ein Vorhersageintervall mit einer Konfidenz von 80% generiert.
Die Funktion ML.EXPLAIN_FORECAST liefert sowohl Verlaufsdaten als auch Prognosedaten. Wenn Sie nur die Prognosedaten sehen möchten, fügen Sie der Abfrage die Option time_series_type hinzu und geben Sie forecast als Optionswert an.
So erklären Sie die Ergebnisse des Modells:
Rufen Sie in der Cloud de Confiance Console die Seite BigQuery auf.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT * FROM ML.EXPLAIN_FORECAST ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (5 AS horizon, 0.8 AS confidence_level), ( SELECT * EXCEPT (bottles_sold) FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
Die Antwort sollte in etwa so aussehen:
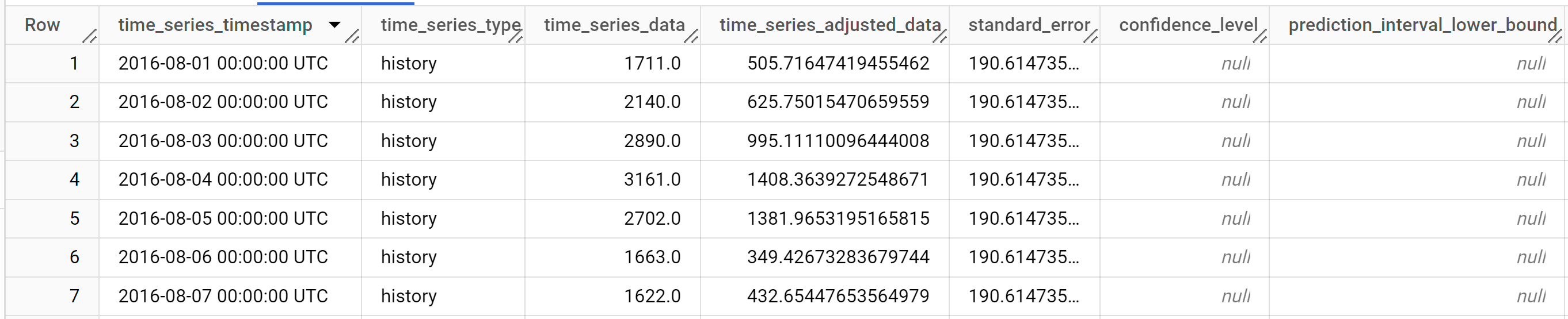
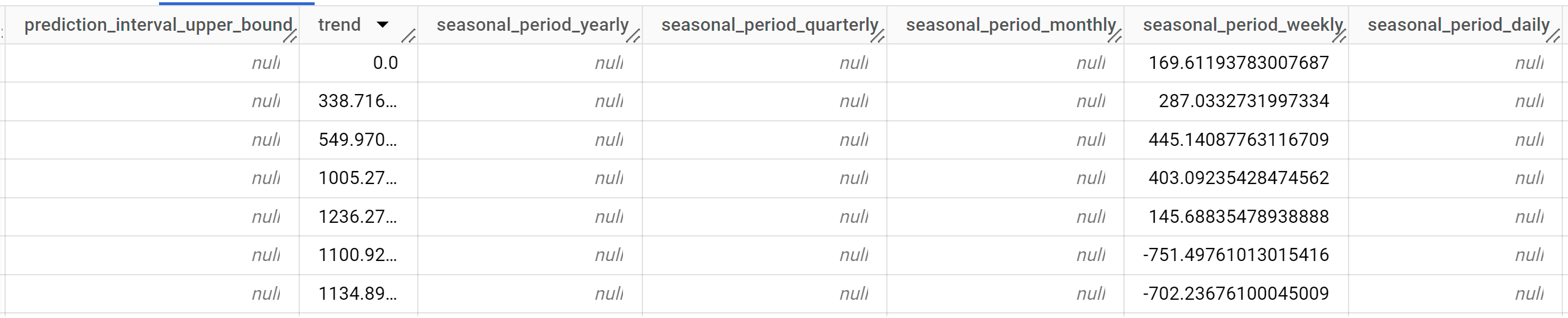
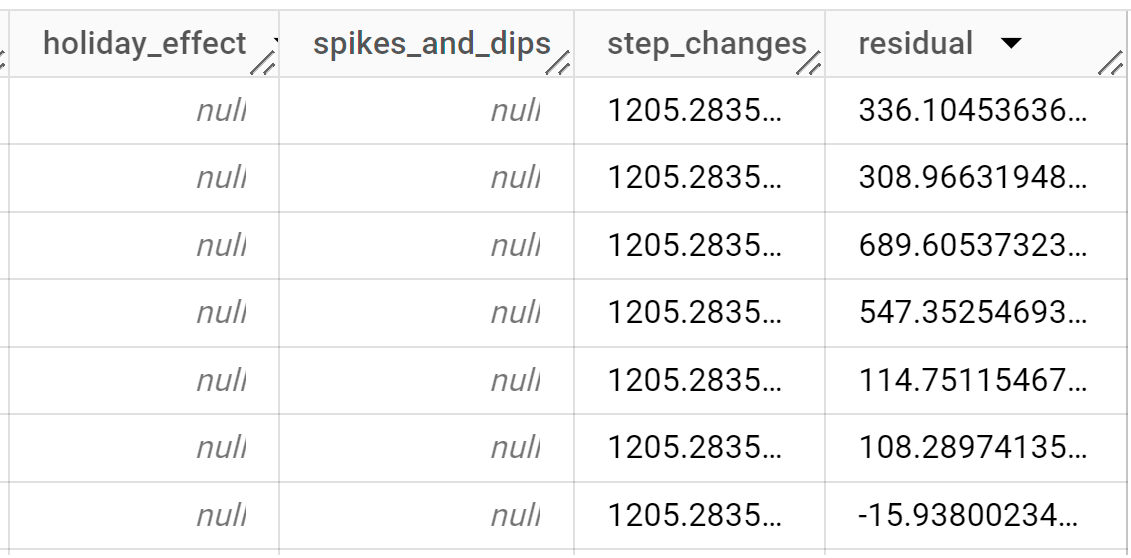
Die Ausgabezeilen werden chronologisch nach dem Spaltenwert
time_series_timestampsortiert.Weitere Informationen zu den Ausgabespalten finden Sie unter
ML.EXPLAIN_FORECAST.
Prognosegenauigkeit bewerten
Bewerten Sie die Vorhersagegenauigkeit des Modells, indem Sie es mit Daten ausführen, mit denen es nicht trainiert wurde. Dazu können Sie die Funktion ML.EVALUATE verwenden. Die Funktion ML.EVALUATE wertet jede Zeitreihe unabhängig aus.
In der folgenden GoogleSQL-Abfrage enthält die zweite SELECT-Anweisung die Daten mit den zukünftigen Features, die für die Prognose der zukünftigen Werte verwendet werden, um sie mit den tatsächlichen Daten zu vergleichen.
So bewerten Sie die Genauigkeit des Modells:
Rufen Sie in der Cloud de Confiance Console die Seite BigQuery auf.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT * FROM ML.EVALUATE ( model `bqml_tutorial.multi_time_series_arimax_model`, ( SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
Die Antwort sollte in etwa so aussehen:
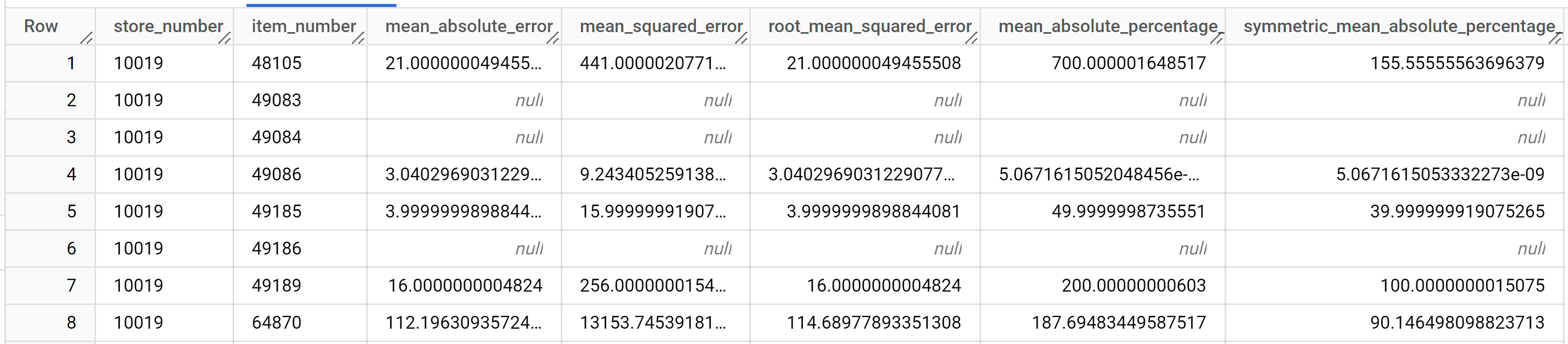
Weitere Informationen zu den Ausgabespalten finden Sie unter
ML.EVALUATE.
Mit dem Modell Anomalien erkennen
Anomalien in den Trainingsdaten mit der Funktion ML.DETECT_ANOMALIES erkennen
In der folgenden Abfrage bewirkt die STRUCT(0.95 AS anomaly_prob_threshold)-Klausel, dass die ML.DETECT_ANOMALIES-Funktion anomale Datenpunkte mit einem Konfidenzniveau von 95% identifiziert.
So erkennen Sie Anomalien in den Trainingsdaten:
Rufen Sie in der Cloud de Confiance Console die Seite BigQuery auf.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT * FROM ML.DETECT_ANOMALIES ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (0.95 AS anomaly_prob_threshold) );
Die Antwort sollte in etwa so aussehen:
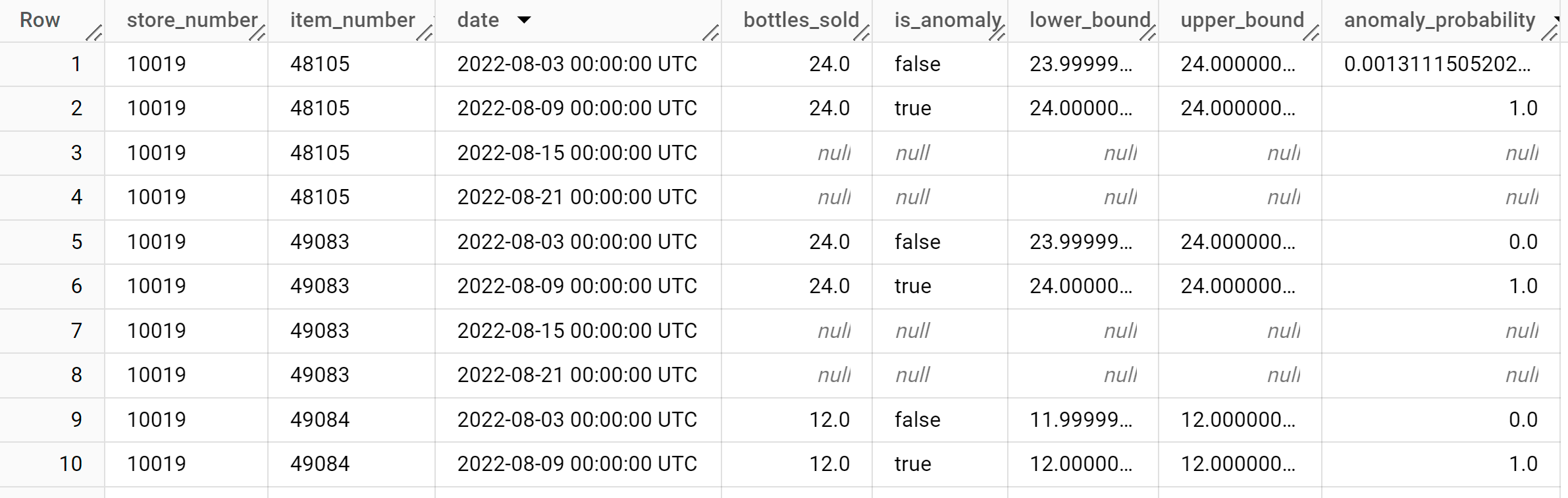
In der Spalte
anomaly_probabilityder Ergebnisse wird die Wahrscheinlichkeit angegeben, dass ein bestimmter Wert der Spaltebottles_soldanomal ist.Weitere Informationen zu den Ausgabespalten finden Sie unter
ML.DETECT_ANOMALIES.
Anomalien in neuen Daten erkennen
Erkennen Sie Anomalien in den neuen Daten, indem Sie Eingabedaten für die ML.DETECT_ANOMALIES-Funktion bereitstellen. Die neuen Daten müssen dieselbe Datensignatur wie die Trainingsdaten haben.
So erkennen Sie Anomalien in neuen Daten:
Rufen Sie in der Cloud de Confiance Console die Seite BigQuery auf.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT * FROM ML.DETECT_ANOMALIES ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (0.95 AS anomaly_prob_threshold), ( SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
Die Antwort sollte in etwa so aussehen:
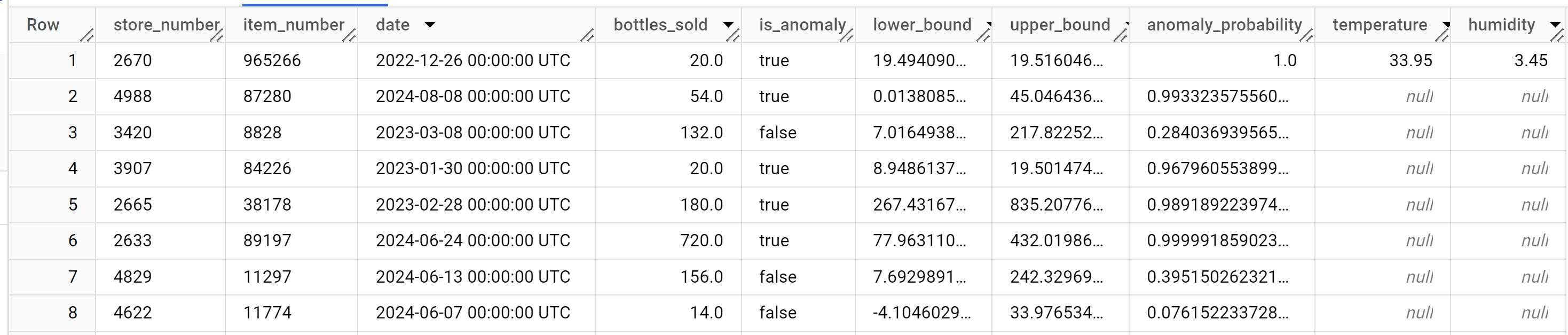
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
- Sie können das von Ihnen erstellte Projekt löschen.
- Sie können das Projekt aber auch behalten und das Dataset löschen.
Dataset löschen
Wenn Sie Ihr Projekt löschen, werden alle Datasets und Tabellen entfernt. Wenn Sie das Projekt wieder verwenden möchten, können Sie das in dieser Anleitung erstellte Dataset löschen:
Rufen Sie, falls erforderlich, die Seite „BigQuery“ in derCloud de Confiance Console auf.
Wählen Sie im Navigationsbereich das Dataset bqml_tutorial aus, das Sie erstellt haben.
Klicken Sie rechts im Fenster auf Delete dataset (Dataset löschen). Dadurch werden das Dataset, die Tabelle und alle Daten gelöscht.
Bestätigen Sie im Dialogfeld Dataset löschen den Löschbefehl. Geben Sie dazu den Namen des Datasets (
bqml_tutorial) ein und klicken Sie auf Löschen.
Projekt löschen
So löschen Sie das Projekt:
- Wechseln Sie in der Cloud de Confiance -Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
Nächste Schritte
- Weitere Informationen zum Prognostizieren einer einzelnen Zeitreihe mit einem univariaten Modell
- Mehrere Zeitreihen mit einem univariaten Modell prognostizieren
- Informationen zum Skalieren eines univariaten Modells bei der Prognose mehrerer Zeitreihen über viele Zeilen hinweg
- Hierarchische Prognosen für mehrere Zeitachsen mit einem univariaten Modell erstellen
- Eine Übersicht über BigQuery ML finden Sie unter Einführung in KI und ML in BigQuery.