
Ce tutoriel vous explique comment utiliser un modèle de série temporelle multivariée pour prévoir la valeur future d'une colonne donnée, en fonction de la valeur historique de plusieurs caractéristiques d'entrée.
Ce tutoriel effectue des prévisions pour plusieurs séries temporelles. Les valeurs prévues sont calculées pour chaque point temporel, pour chaque valeur d'une ou de plusieurs colonnes spécifiées. Par exemple, si vous souhaitez prévoir la météo et que vous spécifiez une colonne contenant des données sur les États, les données prévues contiendront des prévisions pour tous les points temporels de l'État A, puis des valeurs prévues pour tous les points temporels de l'État B, et ainsi de suite. Si vous souhaitez prévoir la météo et que vous avez spécifié des colonnes contenant des données sur l'état et la ville, les données prévisionnelles contiendront des prévisions pour tous les points temporels de l'état A et de la ville A, puis des valeurs prévisionnelles pour tous les points temporels de l'état A et de la ville B, et ainsi de suite.
Ce tutoriel utilise les données des tables publiques bigquery-public-data.iowa_liquor_sales.sales et bigquery-public-data.covid19_weathersource_com.postal_code_day_history. La table bigquery-public-data.iowa_liquor_sales.sales contient des données sur les ventes de boissons alcoolisées collectées dans plusieurs villes de l'État de l'Iowa. La table bigquery-public-data.covid19_weathersource_com.postal_code_day_history contient des données météorologiques historiques, telles que la température et l'humidité, provenant du monde entier.
Avant de lire ce tutoriel, nous vous recommandons vivement de consulter la page Prévoir une série temporelle unique avec un modèle multivarié.
Objectifs
Ce tutoriel vous guide à travers les tâches suivantes :
- Créer un modèle de série temporelle pour prévoir les commandes de magasins d'alcool à l'aide de l'instruction
CREATE MODEL. - Récupérer les valeurs de commandes prévues à partir du modèle à l'aide de la fonction
ML.FORECAST. - Récupérer les composants de la série temporelle, tels que la saisonnalité, la tendance et les attributions de caractéristiques, à l'aide de la fonction
ML.EXPLAIN_FORECAST. Vous pouvez inspecter ces composants de série temporelle pour expliquer les valeurs prévues. - Évaluez la précision du modèle à l'aide de la fonction
ML.EVALUATE. - Détectez les anomalies à l'aide du modèle avec la fonction
ML.DETECT_ANOMALIES.
Coûts
Ce tutoriel utilise des composants facturables de Cloud de Confiance by S3NS, y compris les suivants :
- BigQuery
- BigQuery ML
Pour plus d'informations sur les coûts de BigQuery, consultez la page Tarifs de BigQuery.
Pour en savoir plus sur les coûts associés à BigQuery ML, consultez la page Tarifs de BigQuery ML.
Avant de commencer
-
In the Cloud de Confiance console, on the project selector page, select or create a Cloud de Confiance project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Cloud de Confiance project.
- BigQuery est automatiquement activé dans les nouveaux projets.
Pour activer BigQuery dans un projet préexistant, accédez à
Activez l'API BigQuery.
Rôles requis pour activer les API
Pour activer les API, vous avez besoin du rôle IAM Administrateur Service Usage (
roles/serviceusage.serviceUsageAdmin), qui contient l'autorisationserviceusage.services.enable. Découvrez comment attribuer des rôles.
Créer un ensemble de données
Créez un ensemble de données BigQuery pour stocker votre modèle de ML.
Console
Dans la console Cloud de Confiance , accédez à la page BigQuery.
Dans le volet Explorateur, cliquez sur le nom de votre projet.
Cliquez sur Afficher les actions > Créer un ensemble de données.
Sur la page Créer un ensemble de données, procédez comme suit :
Dans le champ ID de l'ensemble de données, saisissez
bqml_tutorial.Pour Type d'emplacement, sélectionnez Multirégional, puis États-Unis.
Conservez les autres paramètres par défaut, puis cliquez sur Créer un ensemble de données.
bq
Pour créer un ensemble de données, utilisez la commande bq mk --dataset.
Créez un ensemble de données nommé
bqml_tutorialet définissez l'emplacement des données surUS.bq mk --dataset \ --location=US \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Vérifiez que l'ensemble de données a été créé :
bq ls
API
Appelez la méthode datasets.insert avec une ressource d'ensemble de données définie.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
Créer un tableau de données d'entrée
Créez un tableau de données que vous pouvez utiliser pour entraîner et évaluer le modèle. Ce tableau combine les colonnes des tables bigquery-public-data.iowa_liquor_sales.sales et bigquery-public-data.covid19_weathersource_com.postal_code_day_history pour analyser l'impact de la météo sur le type et le nombre d'articles commandés par les magasins d'alcool. Vous créez également les colonnes supplémentaires suivantes que vous pouvez utiliser comme variables d'entrée pour le modèle :
date: date de la commandestore_number: numéro unique du magasin qui a passé la commandeitem_number: numéro unique de l'article commandébottles_sold: nombre de bouteilles commandées pour l'article associétemperature: température moyenne à l'emplacement du magasin à la date de la commandehumidity: humidité moyenne à l'emplacement du magasin à la date de la commande
Pour créer le tableau de données d'entrée, procédez comme suit :
Dans la console Cloud de Confiance , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
CREATE OR REPLACE TABLE `bqml_tutorial.iowa_liquor_sales_with_weather` AS WITH sales AS ( SELECT DATE, store_number, item_number, bottles_sold, SAFE_CAST(SAFE_CAST(zip_code AS FLOAT64) AS INT64) AS zip_code FROM `bigquery-public-data.iowa_liquor_sales.sales` AS sales WHERE SAFE_CAST(zip_code AS FLOAT64) IS NOT NULL ), aggregated_sales AS ( SELECT DATE, store_number, item_number, ANY_VALUE(zip_code) AS zip_code, SUM(bottles_sold) AS bottles_sold, FROM sales GROUP BY DATE, store_number, item_number ), weather AS ( SELECT DATE, SAFE_CAST(postal_code AS INT64) AS zip_code, avg_temperature_air_2m_f AS temperature, avg_humidity_specific_2m_gpkg AS humidity, FROM `bigquery-public-data.covid19_weathersource_com.postal_code_day_history` WHERE country = 'US' AND SAFE_CAST(postal_code AS INT64) IS NOT NULL ) SELECT aggregated_sales.date, aggregated_sales.store_number, aggregated_sales.item_number, aggregated_sales.bottles_sold, weather.temperature AS temperature, weather.humidity AS humidity FROM aggregated_sales LEFT JOIN weather ON aggregated_sales.zip_code=weather.zip_code AND aggregated_sales.DATE=weather.DATE;
Créer le modèle de série temporelle
Créez un modèle de série temporelle pour prévoir le nombre de bouteilles vendues pour chaque combinaison d'ID de magasin et d'ID de l'article, pour chaque date du tableau bqml_tutorial.iowa_liquor_sales_with_weather avant le 1er septembre 2022. Utilisez la température et l'humidité moyennes du magasin à chaque date comme caractéristiques à évaluer lors de la prévision. La table bqml_tutorial.iowa_liquor_sales_with_weather contient environ un million de combinaisons distinctes de numéros d'articles et de magasins, ce qui signifie qu'il existe un million de séries temporelles différentes à prévoir.
Pour créer le modèle, procédez comme suit :
Dans la console Cloud de Confiance , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
CREATE OR REPLACE MODEL `bqml_tutorial.multi_time_series_arimax_model` OPTIONS( model_type = 'ARIMA_PLUS_XREG', time_series_id_col = ['store_number', 'item_number'], time_series_data_col = 'bottles_sold', time_series_timestamp_col = 'date' ) AS SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE < DATE('2022-09-01');
L'exécution de la requête prend environ 38 minutes, après quoi vous pourrez accéder au modèle
multi_time_series_arimax_model. Étant donné que la requête utilise une instructionCREATE MODELpour créer un modèle, les résultats de la requête ne sont pas affichés.
Utiliser le modèle pour prévoir des données
Prévoyez les valeurs futures des séries temporelles à l'aide de la fonction ML.FORECAST.
Dans la requête GoogleSQL suivante, la clause STRUCT(5 AS horizon, 0.8 AS confidence_level) indique que la requête prévoit cinq points temporels futurs et génère un intervalle de prédiction avec un niveau de confiance de 80 %.
La signature de données des données d'entrée de la fonction ML.FORECAST est identique à celle des données d'entraînement que vous avez utilisées pour créer le modèle. La colonne bottles_sold n'est pas incluse dans l'entrée, car il s'agit des données que le modèle tente de prévoir.
Pour prévoir des données avec le modèle, procédez comme suit :
Dans la console Cloud de Confiance , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
SELECT * FROM ML.FORECAST ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (5 AS horizon, 0.8 AS confidence_level), ( SELECT * EXCEPT (bottles_sold) FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE>=DATE('2022-09-01') ) );
Le résultat doit ressembler à ce qui suit :
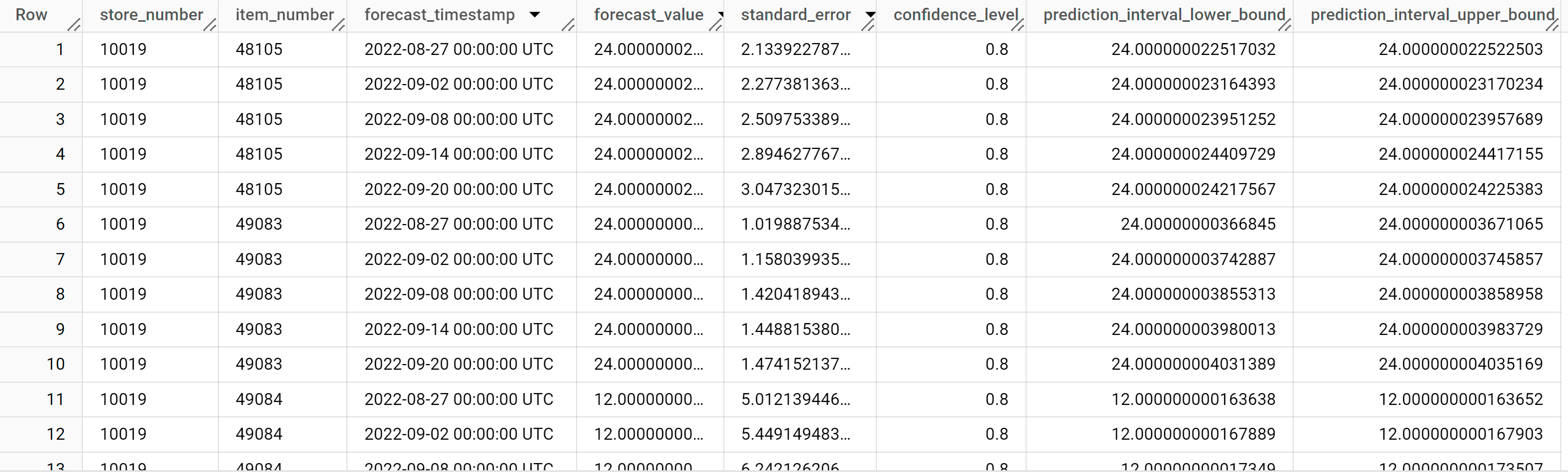
Les lignes de sortie sont triées par valeur
store_number, puis par valeuritem_ID, puis par ordre chronologique de la valeur de la colonneforecast_timestamp. Dans les prévisions de séries temporelles, l'intervalle de prédiction, tel qu'il est représenté par les valeurs des colonnesprediction_interval_lower_boundetprediction_interval_upper_bound, est aussi important que la valeur de la colonneforecast_value. La valeurforecast_valueest le point central de l'intervalle de prédiction. L'intervalle de prédiction dépend des valeurs des colonnesstandard_erroretconfidence_level.Pour en savoir plus sur les colonnes de sortie, consultez
ML.FORECAST.
Expliquer les résultats des prévisions
Vous pouvez obtenir des métriques d'explicabilité en plus des données de prévision à l'aide de la fonction ML.EXPLAIN_FORECAST. La fonction ML.EXPLAIN_FORECAST prédit les valeurs futures des séries temporelles et renvoie également tous les composants distincts de la série temporelle.
Comme la fonction ML.FORECAST, la clause STRUCT(5 AS horizon, 0.8 AS confidence_level) utilisée dans la fonction ML.EXPLAIN_FORECAST indique que la requête prévoit 30 points temporels futurs et génère un intervalle de prédiction avec un indice de confiance de 80 %.
La fonction ML.EXPLAIN_FORECAST fournit à la fois des données historiques et des données de prévision. Pour n'afficher que les données de prévision, ajoutez l'option time_series_type à la requête et spécifiez forecast comme valeur d'option.
Pour expliquer les résultats du modèle, procédez comme suit :
Dans la console Cloud de Confiance , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
SELECT * FROM ML.EXPLAIN_FORECAST ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (5 AS horizon, 0.8 AS confidence_level), ( SELECT * EXCEPT (bottles_sold) FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
Le résultat doit ressembler à ce qui suit :
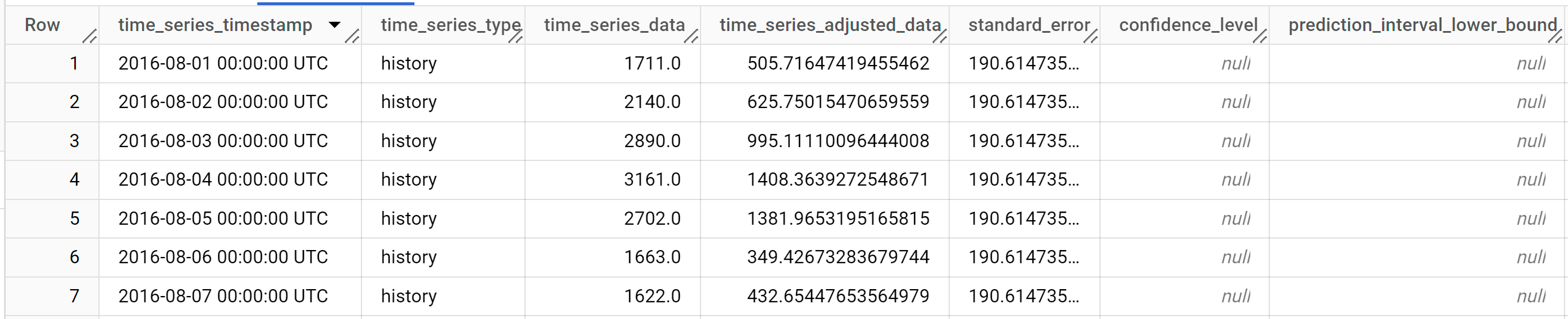
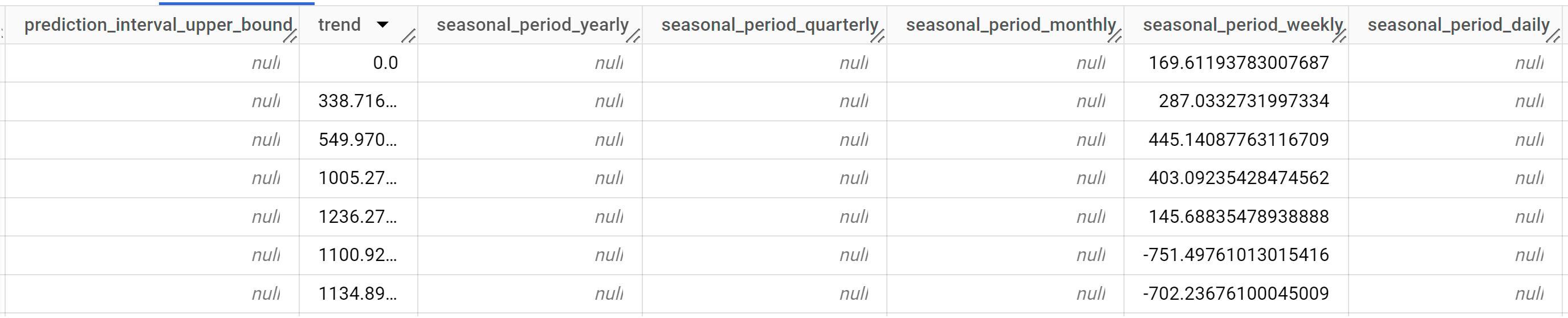
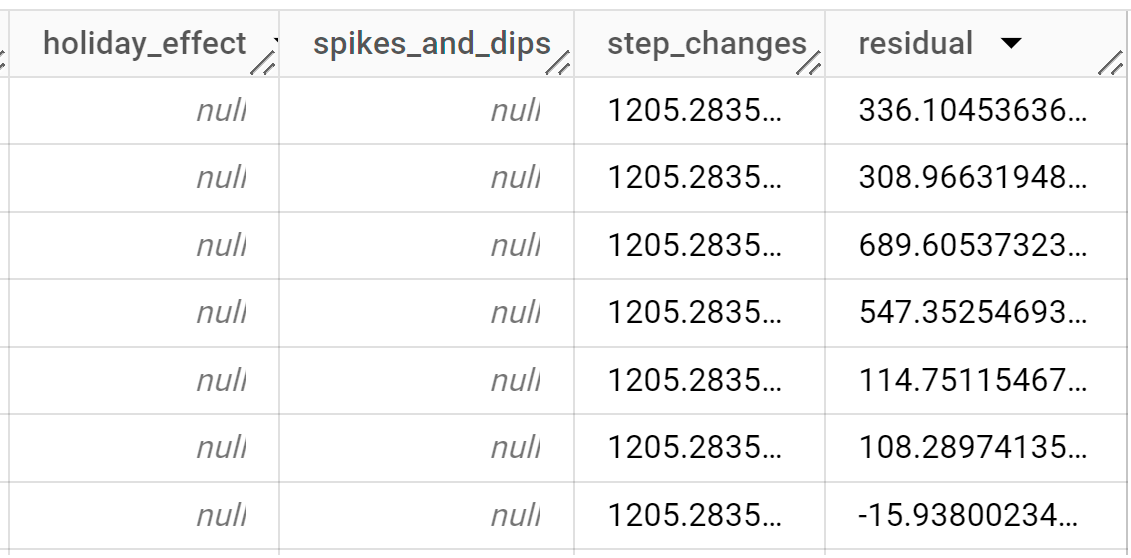
Les lignes de sortie sont triées par ordre chronologique en fonction de la valeur de la colonne
time_series_timestamp.Pour en savoir plus sur les colonnes de sortie, consultez
ML.EXPLAIN_FORECAST.
Évaluer la précision des prévisions
Évaluez la précision des prévisions du modèle en l'exécutant sur des données sur lesquelles il n'a pas été entraîné. Pour ce faire, utilisez la fonction ML.EVALUATE. La fonction ML.EVALUATE évalue chaque série temporelle de manière indépendante.
Dans la requête GoogleSQL suivante, la deuxième instruction SELECT fournit les données avec les caractéristiques futures, qui permettent de prévoir les valeurs futures à comparer aux données réelles.
Pour évaluer la précision du modèle, procédez comme suit :
Dans la console Cloud de Confiance , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
SELECT * FROM ML.EVALUATE ( model `bqml_tutorial.multi_time_series_arimax_model`, ( SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
Le résultat doit ressembler à ce qui suit :
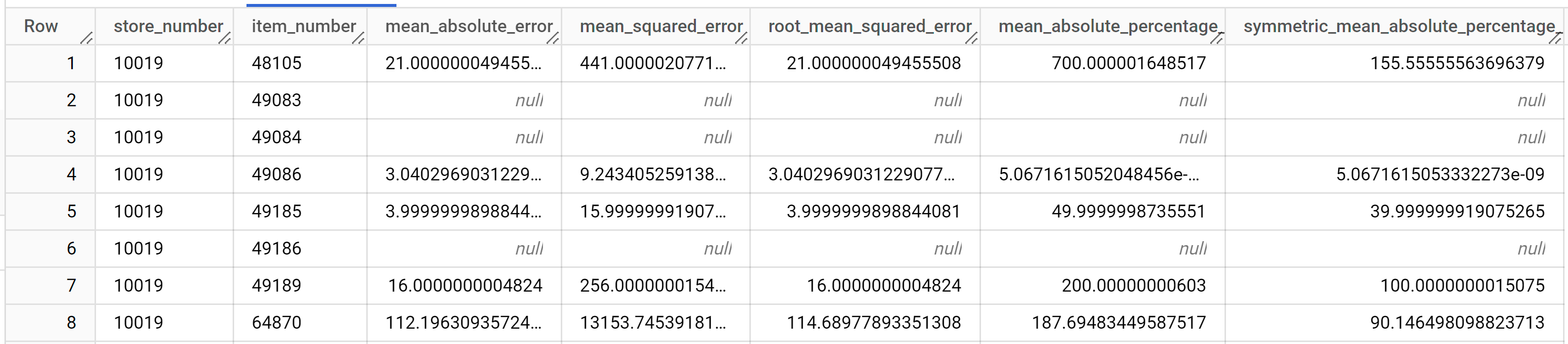
Pour en savoir plus sur les colonnes de sortie, consultez
ML.EVALUATE.
Utiliser le modèle pour détecter les anomalies
Détectez les anomalies dans les données d'entraînement à l'aide de la fonction ML.DETECT_ANOMALIES.
Dans la requête suivante, la clause STRUCT(0.95 AS anomaly_prob_threshold) permet à la fonction ML.DETECT_ANOMALIES d'identifier les points de données anormaux avec un niveau de confiance de 95 %.
Pour détecter les anomalies dans les données d'entraînement, procédez comme suit :
Dans la console Cloud de Confiance , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
SELECT * FROM ML.DETECT_ANOMALIES ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (0.95 AS anomaly_prob_threshold) );
Le résultat doit ressembler à ce qui suit :
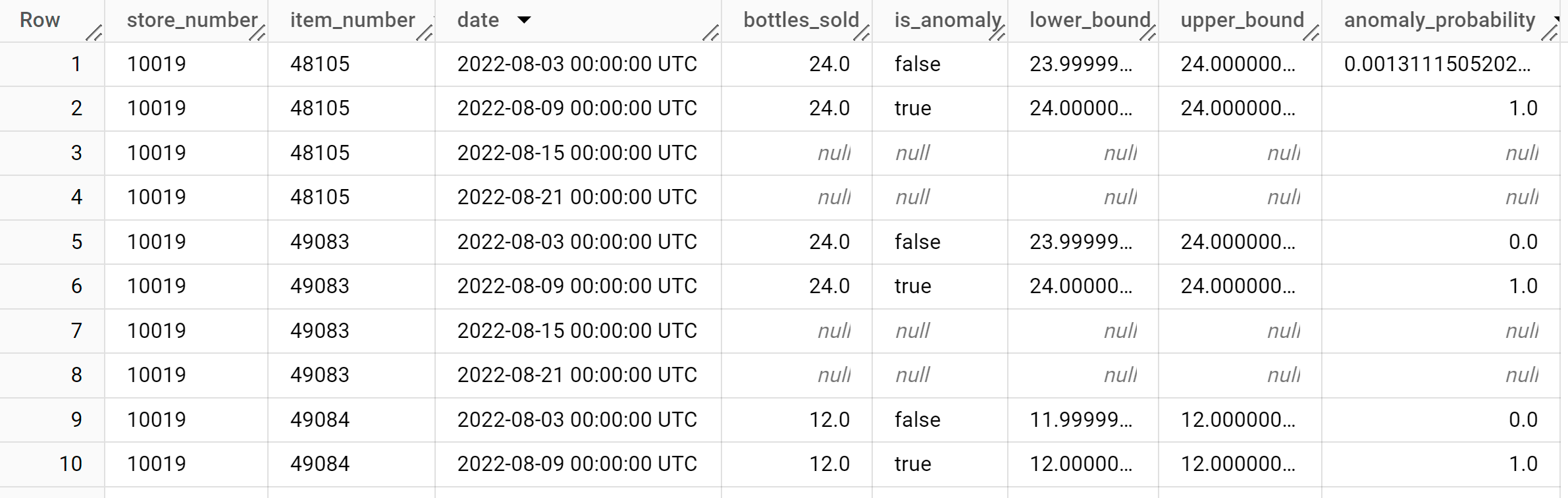
La colonne
anomaly_probabilitydes résultats identifie la probabilité qu'une valeur de colonnebottles_solddonnée soit anormale.Pour en savoir plus sur les colonnes de sortie, consultez
ML.DETECT_ANOMALIES.
Détecter les anomalies dans les nouvelles données
Détectez les anomalies dans les nouvelles données en fournissant des données d'entrée à la fonction ML.DETECT_ANOMALIES. Les nouvelles données doivent avoir la même signature de données que les données d'entraînement.
Pour détecter des anomalies dans de nouvelles données, procédez comme suit :
Dans la console Cloud de Confiance , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
SELECT * FROM ML.DETECT_ANOMALIES ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (0.95 AS anomaly_prob_threshold), ( SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
Le résultat doit ressembler à ce qui suit :
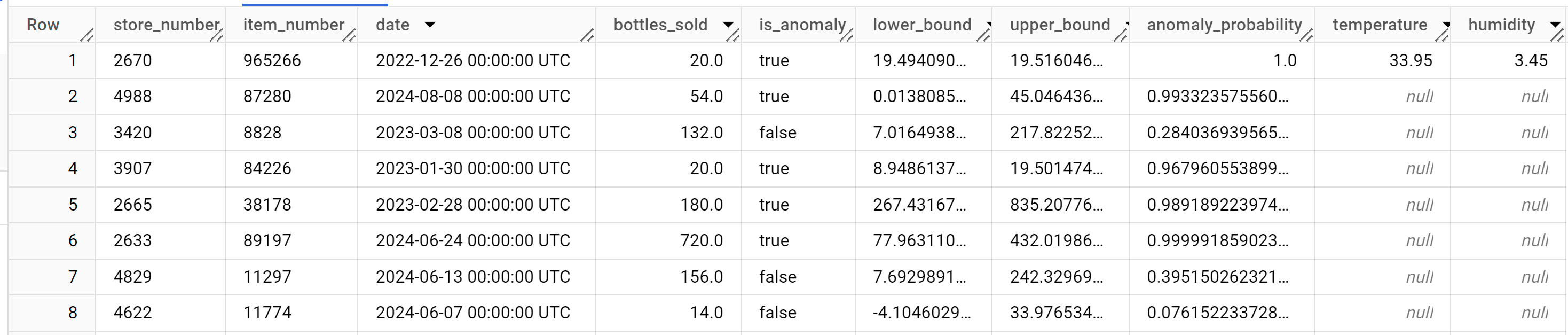
Effectuer un nettoyage
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
- Supprimez le projet que vous avez créé.
- Ou conservez le projet et supprimez l'ensemble de données.
Supprimer l'ensemble de données
Si vous supprimez votre projet, tous les ensembles de données et toutes les tables qui lui sont associés sont également supprimés. Si vous préférez réutiliser le projet, vous pouvez supprimer l'ensemble de données que vous avez créé dans ce tutoriel :
Si nécessaire, ouvrez la page BigQuery dans la consoleCloud de Confiance .
Dans le panneau de navigation, cliquez sur l'ensemble de données bqml_tutorial que vous avez créé.
Cliquez sur Delete dataset (Supprimer l'ensemble de données) dans la partie droite de la fenêtre. Cette action supprime l'ensemble de données, la table et toutes les données.
Dans la boîte de dialogue Supprimer l'ensemble de données, confirmez la commande de suppression en saisissant le nom de votre ensemble de données (
bqml_tutorial), puis cliquez sur Supprimer.
Supprimer votre projet
Pour supprimer le projet :
- Dans la console Cloud de Confiance , accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
Étapes suivantes
- Découvrez comment prévoir une seule série temporelle avec un modèle univarié.
- Découvrez comment prévoir plusieurs séries temporelles avec un modèle univarié.
- Découvrez comment mettre à l'échelle un modèle univarié lorsque vous prévoyez plusieurs séries temporelles sur plusieurs lignes.
- Découvrez comment prévoir hiérarchiquement plusieurs séries temporelles avec un modèle univarié.
- Pour obtenir plus d'informations sur BigQuery ML, consultez la présentation de l'IA et du ML dans BigQuery.