
使用 ARIMA_PLUS 單變數模型預測階層式時間序列
本教學課程說明如何使用ARIMA_PLUS單變數時間序列模型預測階層式時間序列。這項功能會根據指定資料欄的歷史值,預測該資料欄的未來值,並計算該資料欄中一或多個感興趣維度的匯總值。
系統會針對每個時間點,以及一或多個指定感興趣維度的資料欄中的每個值,計算預測值。舉例來說,如果您想預測每日交通事件,並指定包含州別資料的維度資料欄,預測資料會包含州別 A 每天的值,然後是州別 B 每天的值,依此類推。如果您想預測每日交通事件,並指定包含州和城市資料的維度資料欄,預測資料會包含 A 州和 A 市每天的值,然後是 A 州和 B 市每天的值,依此類推。在階層式時間序列模型中,階層式對帳用於匯總每個子項時間序列,並與其父項對帳。舉例來說,A 州所有城市的預測值總和,必須等於 A 州的預測值。
在本教學課程中,您將使用相同資料建立兩個時間序列模型,一個使用階層式預測,另一個則否。這項功能可讓您比較模型傳回的結果。
本教學課程使用公開資料表中的資料。bigquery-public-data.iowa_liquor.sales.sales這份表格使用愛荷華州公開的酒類銷售資料,包含不同商店中超過 100 萬種酒類產品的資訊。
閱讀本教學課程前,強烈建議您先參閱「使用單變數模型預測多個時間序列」。
所需權限
如要建立資料集,您需要
bigquery.datasets.create身分與存取權管理 (IAM) 權限。如要建立模型,您必須具備下列權限:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
如要執行推論,您需要下列權限:
bigquery.models.getDatabigquery.jobs.create
如要進一步瞭解 BigQuery 中的 IAM 角色和權限,請參閱「IAM 簡介」。
目標
在本教學課程中,您會使用下列項目:
- 使用
CREATE MODEL陳述式,建立多個時間序列模型和多個階層式時間序列模型,預測瓶裝飲料的銷售值。 - 使用
ML.FORECAST函式從模型擷取預測的瓶裝水銷售值。
費用
本教學課程使用 Cloud de Confiance by S3NS的計費元件,包括:
- BigQuery
- BigQuery ML
如要進一步瞭解 BigQuery 費用,請參閱 BigQuery 定價頁面。
如要進一步瞭解 BigQuery ML 費用,請參閱 BigQuery ML 定價。
-
In the Cloud de Confiance console, on the project selector page, select or create a Cloud de Confiance project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Cloud de Confiance project.
- 新專案會自動啟用 BigQuery。如要在現有的專案中啟用 BigQuery,請前往
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. 前往 Cloud de Confiance 控制台的「BigQuery」頁面。
在「Explorer」窗格中,按一下專案名稱。
依序點按 「View actions」(查看動作) >「Create dataset」(建立資料集)
在「建立資料集」頁面中,執行下列操作:
在「Dataset ID」(資料集 ID) 中輸入
bqml_tutorial。針對「位置類型」選取「多區域」,然後選取「美國 (多個美國地區)」。
其餘設定請保留預設狀態,然後按一下「建立資料集」。
建立名為「
bqml_tutorial」的資料集,並將資料位置設為「US」,說明則設為「BigQuery ML tutorial dataset」:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
這個指令採用
-d捷徑,而不是使用--dataset旗標。如果您省略-d和--dataset,該指令預設會建立資料集。確認資料集已建立完成:
bq ls前往 Cloud de Confiance 控制台的「BigQuery」頁面。
在查詢編輯器中貼上以下查詢,然後點選「執行」:
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast` OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COL = 'date', TIME_SERIES_DATA_COL = 'total_bottles_sold', TIME_SERIES_ID_COL = ['store_number', 'zip_code', 'city', 'county'], HOLIDAY_REGION = 'US') AS SELECT store_number, zip_code, city, county, date, SUM(bottles_sold) AS total_bottles_sold FROM `bigquery-public-data.iowa_liquor_sales.sales` WHERE date BETWEEN DATE('2015-01-01') AND DATE('2015-12-31') AND county IN ('POLK', 'LINN', 'SCOTT') GROUP BY store_number, date, city, zip_code, county;
查詢作業約需 37 秒才能完成,完成後您就能存取
liquor_forecast模型。由於查詢是使用CREATE MODEL陳述式建立模型,因此不會有查詢結果。前往 Cloud de Confiance 控制台的「BigQuery」頁面。
在查詢編輯器中貼上以下查詢,然後點選「執行」:
SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.liquor_forecast`, STRUCT(20 AS horizon, 0.8 AS confidence_level)) ORDER BY store_number, county, city, zip_code, forecast_timestamp;
結果應如下所示:
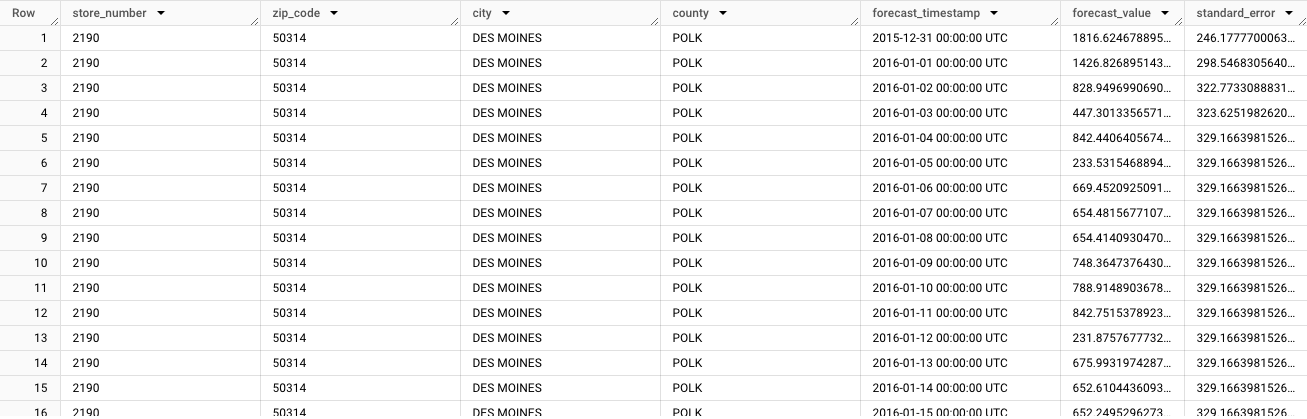
輸出內容會先顯示第一個時間序列的預測資料;
store_number=2190、zip_code=50314、city=DES MOINES、county=POLK。捲動瀏覽資料時,您會看到每個後續不重複時間序列的預測結果。如要產生不同維度的總計預測,例如特定縣市的預測,您必須產生階層式預測。前往 Cloud de Confiance 控制台的「BigQuery」頁面。
在查詢編輯器中貼上以下查詢,然後點選「執行」:
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast_hierarchical` OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COL = 'date', TIME_SERIES_DATA_COL = 'total_bottles_sold', TIME_SERIES_ID_COL = ['store_number', 'zip_code', 'city', 'county'], HIERARCHICAL_TIME_SERIES_COLS = ['zip_code', 'store_number'], HOLIDAY_REGION = 'US') AS SELECT store_number, zip_code, city, county, date, SUM(bottles_sold) AS total_bottles_sold FROM `bigquery-public-data.iowa_liquor_sales.sales` WHERE date BETWEEN DATE('2015-01-01') AND DATE('2015-12-31') AND county IN ('POLK', 'LINN', 'SCOTT') GROUP BY store_number, date, city, zip_code, county;
查詢作業約需 45 秒才能完成,之後即可在「Explorer」窗格中存取
bqml_tutorial.liquor_forecast_hierarchical模型。由於查詢使用CREATE MODEL陳述式建立模型,因此不會有查詢結果。前往 Cloud de Confiance 控制台的「BigQuery」頁面。
在查詢編輯器中貼上以下查詢,然後點選「執行」:
SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.liquor_forecast_hierarchical`, STRUCT(30 AS horizon, 0.8 AS confidence_level)) WHERE city = 'LECLAIRE' ORDER BY county, city, zip_code, store_number, forecast_timestamp;
結果應如下所示:
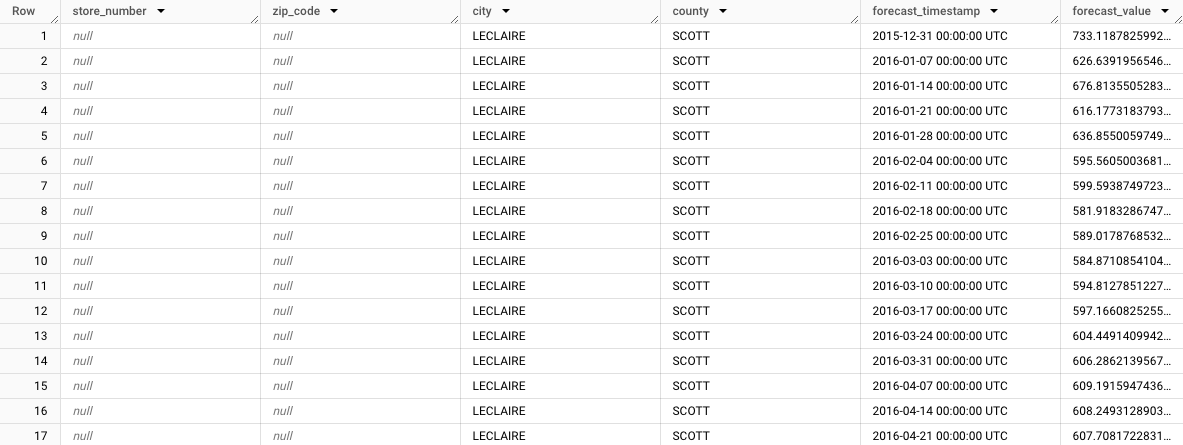
請注意,系統會顯示 LeClaire 市的匯總預測,
store_number=NULL、zip_code=NULL、city=LECLAIRE、county=SCOTT。查看其餘資料列時,請注意其他子群組的預測結果。舉例來說,下圖顯示郵遞區號52753、store_number=NULL、zip_code=52753、city=LECLAIRE、county=SCOTT的匯總預報: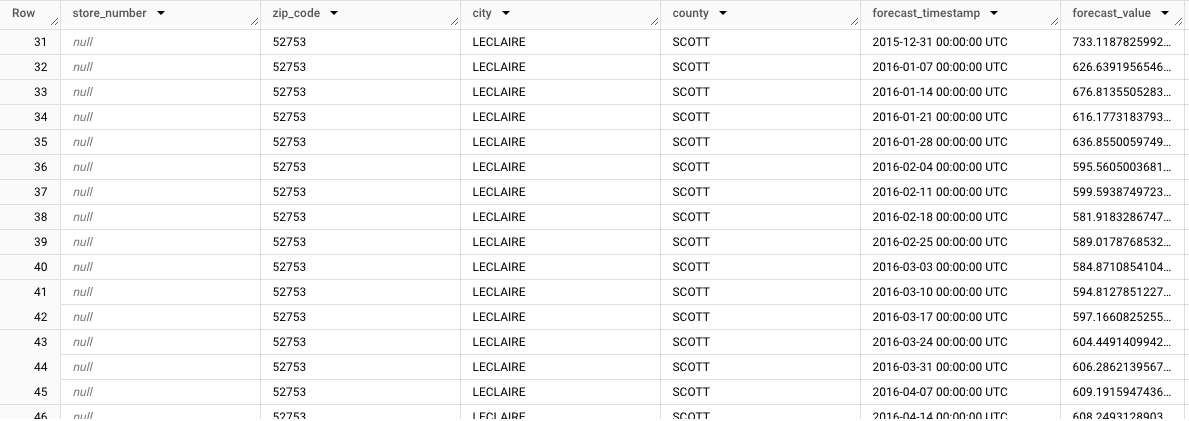
- 您可以刪除建立的專案。
- 或者您可以保留專案並刪除資料集。
如有必要,請在Cloud de Confiance 控制台中開啟 BigQuery 頁面。
在導覽窗格中,按一下您建立的 bqml_tutorial 資料集。
按一下視窗右側的「刪除資料集」。 這個動作將會刪除資料集、資料表,以及所有資料。
在「Delete dataset」(刪除資料集) 對話方塊中,輸入資料集的名稱 (
bqml_tutorial),然後按一下「Delete」(刪除) 來確認刪除指令。- In the Cloud de Confiance console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- 瞭解如何使用單變數模型預測單一時間序列
- 瞭解如何使用單變數模型預測多個時間序列
- 瞭解如何在預測多個資料列的時間序列時,擴展單變數模型。
- 瞭解如何使用多變數模型預測單一時間序列
- 如需 BigQuery ML 的總覽,請參閱 BigQuery 中的 AI 和 ML 簡介。
建立資料集
建立 BigQuery 資料集來儲存機器學習模型。
控制台
bq
如要建立新的資料集,請使用 bq mk 指令,搭配 --location 旗標。如需可能的完整參數清單,請參閱 bq mk --dataset 指令參考資料。
API
請呼叫 datasets.insert 方法,搭配已定義的資料集資源。
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
在嘗試這個範例之前,請按照使用 BigQuery DataFrames 的 BigQuery 快速入門導覽課程中的 BigQuery DataFrames 設定說明操作。 詳情請參閱 BigQuery DataFrames 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定 ADC」。
建立時間序列模型
使用愛荷華州酒類銷售資料建立時間序列模型。
下列 GoogleSQL 查詢會建立模型,預測 2015 年在 Polk、Linn 和 Scott 郡售出的瓶裝水總數。
在下列查詢中,OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) 子句表示您要建立以 ARIMA 為基礎的時間序列模型。您可以使用 CREATE MODEL 陳述式的 TIME_SERIES_ID 選項,指定要取得預測結果的輸入資料中一或多個資料欄。CREATE MODEL 陳述式的 auto_arima_max_order 選項會控管 auto.ARIMA 演算法中超參數調整的搜尋空間。CREATE MODEL 陳述式的 decompose_time_series 選項預設為 TRUE,因此在下一個步驟中評估模型時,系統會傳回時間序列資料的相關資訊。
OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) 子句代表您要建立以 ARIMA 為基礎的時間序列模型。根據預設,auto_arima=TRUE,因此 auto.ARIMA 演算法會自動調整 ARIMA_PLUS 模型中的超參數。演算法會套用數十個候選模型,並選擇最佳模型,也就是赤池訊息量準則 (AIC) 最低的模型。如果時間序列中存在美國節慶模式,將 holiday_region 選項設為 US,即可更準確地模擬這些美國節慶時間點。
請按照下列步驟建立模型:
使用模型預測資料
使用 ML.FORECAST 函式預測未來時間序列值。
在下列查詢中,STRUCT(20 AS horizon, 0.8 AS confidence_level) 子句表示查詢會預測 20 個未來時間點,並產生信賴水準為 80% 的預測間隔。
如要使用模型預測資料,請按照下列步驟操作:
建立階層式時間序列模型
使用愛荷華州酒類銷售資料,建立階層式時間序列預測。
下列 GoogleSQL 查詢會建立模型,針對 Polk、Linn 和 Scott 郡 2015 年每日銷售的瓶子總數,產生階層式預測。
在下列查詢中,CREATE MODEL 陳述式中的 HIERARCHICAL_TIME_SERIES_COLS 選項表示您要根據指定的一組資料欄建立階層式預測。這些資料欄都會經過彙整和匯總。舉例來說,在先前的查詢中,這表示 store_number 資料欄值會匯總,以顯示每個 county、city 和 zip_code 值的預測結果。此外,系統也會分別匯總 zip_code 和 store_number 值,顯示每個 county 和 city 值的預測結果。欄的順序很重要,因為這會定義階層結構。
請按照下列步驟建立模型:
使用階層式模型預測資料
使用 ML.FORECAST 函式從模型擷取階層式預測資料。
如要使用模型預測資料,請按照下列步驟操作:
清除所用資源
如要避免系統向您的 Cloud de Confiance by S3NS 帳戶收取本教學課程所用資源的費用,請刪除含有相關資源的專案,或者保留專案但刪除個別資源。
刪除資料集
刪除專案將移除專案中所有的資料集與資料表。若您希望重新使用專案,您可以刪除本教學課程中所建立的資料集。
刪除專案
如要刪除專案,請進行以下操作: