
本教學課程將說明如何使用ARIMA_PLUS單變數時間序列模型,根據特定資料欄的歷來值,預測該資料欄的未來值。
本教學課程會預測單一時間序列。系統會針對輸入資料中的每個時間點計算一次預測值。
本教學課程使用公開的bigquery-public-data.google_analytics_sample.ga_sessions範例資料表資料。這份表格包含 Google 商品網路商店的模糊處理電子商務資料。
建立資料集
建立 BigQuery 資料集來儲存機器學習模型。
控制台
前往 Cloud de Confiance 控制台的「BigQuery」頁面。
在「Explorer」窗格中,按一下專案名稱。
依序點按 「View actions」(查看動作) >「Create dataset」(建立資料集)。
在「建立資料集」頁面中,執行下列操作:
在「Dataset ID」(資料集 ID) 中輸入
bqml_tutorial。針對「Location type」(位置類型) 選取「Multi-region」(多區域),然後選取「US (multiple regions in United States)」(us (多個美國區域))。
其餘設定請保留預設狀態,然後按一下「建立資料集」。
bq
如要建立新的資料集,請使用 bq mk 指令搭配 --location 旗標。如需可能的完整參數清單,請參閱 bq mk --dataset 指令參考資料。
建立名為「
bqml_tutorial」的資料集,並將資料位置設為「US」,說明則設為「BigQuery ML tutorial dataset」:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
這個指令採用
-d捷徑,而不是使用--dataset旗標。如果您省略-d和--dataset,該指令預設會建立資料集。確認資料集已建立完成:
bq ls
API
請呼叫 datasets.insert 方法,搭配已定義的資料集資源。
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
在嘗試這個範例之前,請按照使用 BigQuery DataFrames 的 BigQuery 快速入門導覽課程中的 BigQuery DataFrames 設定說明操作。 詳情請參閱 BigQuery DataFrames 參考說明文件。
如要驗證 BigQuery,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定 ADC」。
以視覺化方式呈現輸入資料
建立模型前,您可以選擇將輸入的時間序列資料視覺化,瞭解資料分布情形。您可以使用 Looker Studio 執行這項操作。
請按照下列步驟,以視覺化方式呈現時間序列資料:
SQL
在下列 GoogleSQL 查詢中,SELECT 陳述式會將輸入資料表中的 date 欄剖析為 TIMESTAMP 類型,並重新命名為 parsed_date,然後使用 SUM(...) 子句和 GROUP BY date 子句建立每日 totals.visits 值。
前往 Cloud de Confiance 控制台的「BigQuery」頁面。
在查詢編輯器中貼上以下查詢,然後點選「執行」:
SELECT PARSE_TIMESTAMP("%Y%m%d", date) AS parsed_date, SUM(totals.visits) AS total_visits FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` GROUP BY date;
查詢完成後,依序點按「探索資料」>「透過 Looker Studio 探索」。Looker Studio 會在新分頁中開啟,在新分頁中完成下列步驟。
在 Looker Studio 中,依序點選「插入」>「時間序列圖表」。
在「圖表」窗格中,選擇「設定」分頁。
在「指標」專區中,新增「total_visits」欄位,並移除預設的「Record Count」指標。產生的圖表看起來類似下列內容:
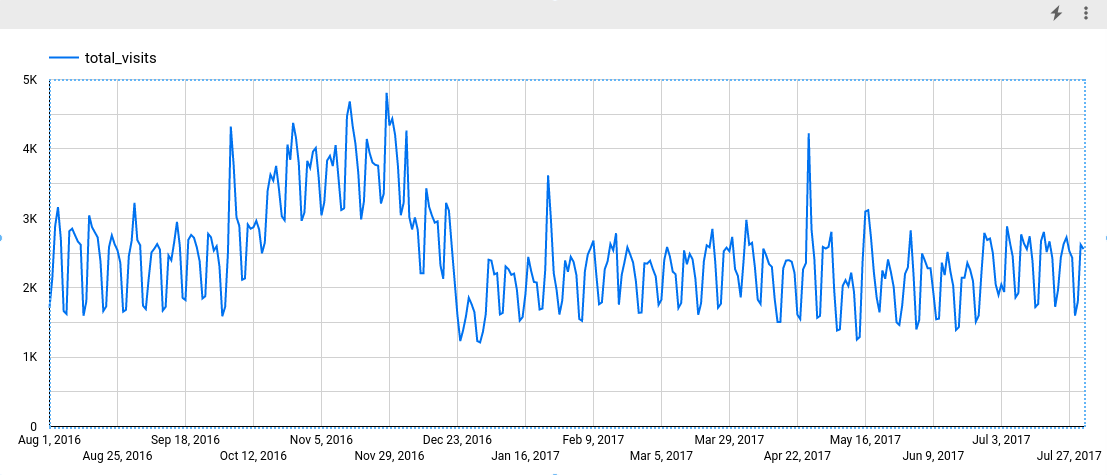
從圖表可以看出,輸入時間序列具有每週季節性模式。
BigQuery DataFrames
在嘗試這個範例之前,請按照使用 BigQuery DataFrames 的 BigQuery 快速入門導覽課程中的 BigQuery DataFrames 設定說明操作。 詳情請參閱 BigQuery DataFrames 參考說明文件。
如要驗證 BigQuery,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定 ADC」。
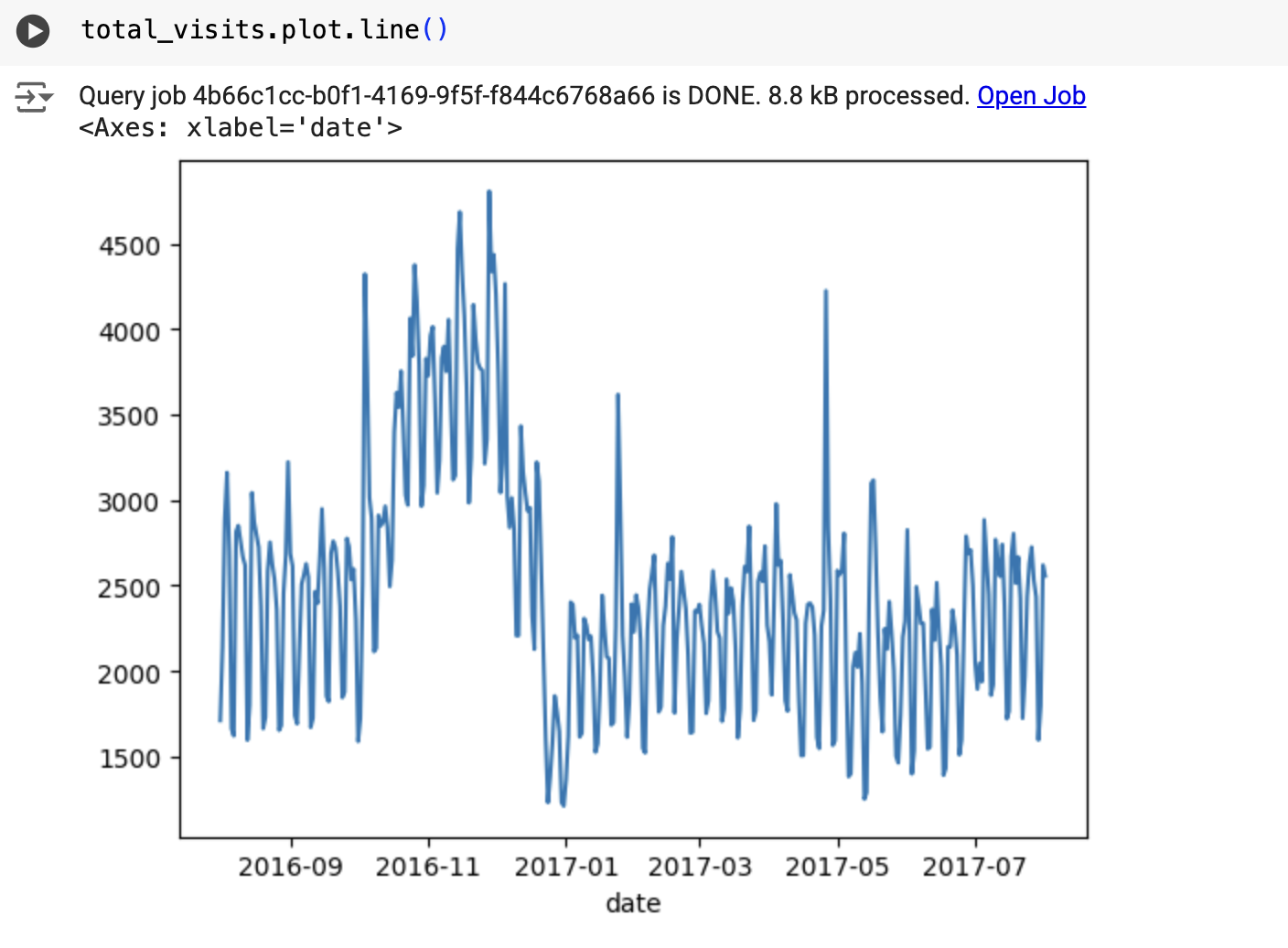
結果會類似如下:
建立時間序列模型
建立時間序列模型,預測以 totals.visits 欄表示的網站總造訪次數,並使用 Google Analytics 360 資料訓練模型。
SQL
在下列查詢中,OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) 子句表示您要建立以 ARIMA 為基礎的時間序列模型。CREATE MODEL 陳述式的 auto_arima 選項預設為 TRUE,因此 auto.ARIMA 演算法會自動調整模型中的超參數。演算法會套用數十個候選模型,並選擇最佳模型,也就是赤池訊息量準則 (AIC) 最低的模型。CREATE MODEL 陳述式的data_frequency 選項預設為 AUTO_FREQUENCY,因此訓練程序會自動推斷輸入時間序列的資料頻率。CREATE MODEL 陳述式的 decompose_time_series 選項預設為 TRUE,因此在下一個步驟中評估模型時,系統會傳回時間序列資料的相關資訊。
請按照下列步驟建立模型:
前往 Cloud de Confiance 控制台的「BigQuery」頁面。
在查詢編輯器中貼上以下查詢,然後點選「執行」:
CREATE OR REPLACE MODEL `bqml_tutorial.ga_arima_model` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'parsed_date', time_series_data_col = 'total_visits', auto_arima = TRUE, data_frequency = 'AUTO_FREQUENCY', decompose_time_series = TRUE ) AS SELECT PARSE_TIMESTAMP("%Y%m%d", date) AS parsed_date, SUM(totals.visits) AS total_visits FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` GROUP BY date;
查詢作業約需 4 秒才能完成,完成後您即可存取
ga_arima_model模型。由於查詢是使用CREATE MODEL陳述式建立模型,因此您看不到查詢結果。
BigQuery DataFrames
在嘗試這個範例之前,請按照使用 BigQuery DataFrames 的 BigQuery 快速入門導覽課程中的 BigQuery DataFrames 設定說明操作。 詳情請參閱 BigQuery DataFrames 參考說明文件。
如要驗證 BigQuery,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定 ADC」。
評估候選模型
SQL
使用 ML.ARIMA_EVALUATE 函式評估時間序列模型。ML.ARIMA_EVALUATE 函式會顯示自動超參數調整程序中評估的所有候選模型的評估指標。
請按照下列步驟評估模型:
前往 Cloud de Confiance 控制台的「BigQuery」頁面。
在查詢編輯器中貼上以下查詢,然後點選「執行」:
SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.ga_arima_model`);
結果應如下所示:

BigQuery DataFrames
在嘗試這個範例之前,請按照使用 BigQuery DataFrames 的 BigQuery 快速入門導覽課程中的 BigQuery DataFrames 設定說明操作。 詳情請參閱 BigQuery DataFrames 參考說明文件。
如要驗證 BigQuery,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定 ADC」。
non_seasonal_p、non_seasonal_d、non_seasonal_q 和 has_drift 輸出資料欄會在訓練管道中定義 ARIMA 模型。log_likelihood、AIC 和 variance 輸出資料欄與 ARIMA 模型擬合程序相關。
auto.ARIMA 演算法會使用 KPSS 檢定,判斷 non_seasonal_d 的最佳值,在本例中為 1。當 non_seasonal_d 為 1 時,auto.ARIMA 演算法會平行訓練 42 個不同的候選 ARIMA 模型。在本例中,所有 42 個候選模型都有效,因此輸出內容包含 42 個資料列,每個候選 ARIMA 模型各佔一列;如果部分模型無效,則會從輸出內容中排除。這些候選模型會依 AIC 遞增順序傳回。第一列中的模型 AIC 最低,因此視為最佳模型。最佳模型會儲存為最終模型,並在您對模型呼叫 ML.FORECAST 等函式時使用
seasonal_periods 欄包含時間序列資料中識別出的季節性模式相關資訊。這與 ARIMA 建模無關,因此所有輸出資料列的值都相同。這份報表顯示每週模式,與您選擇將輸入資料視覺化時看到的結果一致。
只有在 decompose_time_series=TRUE 時,系統才會填入 has_holiday_effect、has_spikes_and_dips 和 has_step_changes 欄。這些資料欄也會反映輸入時間序列資料的相關資訊,與 ARIMA 模型無關。所有輸出資料列的這些資料欄值也相同。
「error_message」欄會顯示在auto.ARIMA調整過程中發生的任何錯誤。如果所選的 non_seasonal_p、non_seasonal_d、non_seasonal_q 和 has_drift 欄無法穩定時間序列,就可能發生錯誤。如要擷取所有候選模型的錯誤訊息,請在建立模型時,將 show_all_candidate_models 選項設為 TRUE。
如要進一步瞭解輸出資料欄,請參閱 ML.ARIMA_EVALUATE 函式。
檢查模型的係數
SQL
使用 ML.ARIMA_COEFFICIENTS 函式檢查時間序列模型的係數。
請按照下列步驟擷取模型的係數:
前往 Cloud de Confiance 控制台的「BigQuery」頁面。
在查詢編輯器中貼上以下查詢,然後點選「執行」:
SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.ga_arima_model`);
ar_coefficients 輸出資料欄會顯示 ARIMA 模型自迴歸 (AR) 部分的模型係數。同樣地,ma_coefficients 輸出資料欄會顯示 ARIMA 模型移動平均 (MA) 部分的模型係數。這兩個資料欄都包含陣列值,長度分別等於 non_seasonal_p 和 non_seasonal_q。您在 ML.ARIMA_EVALUATE 函式的輸出內容中看到,最佳模型的 non_seasonal_p 值為 2,non_seasonal_q 值為 3。因此,在 ML.ARIMA_COEFFICIENTS 輸出內容中,ar_coefficients 值是 2 元素陣列,而 ma_coefficients 值是 3 元素陣列。intercept_or_drift 值是 ARIMA 模型中的常數項。
如要進一步瞭解輸出資料欄,請參閱 ML.ARIMA_COEFFICIENTS 函式。
BigQuery DataFrames
使用 coef_ 函式檢查時間序列模型的係數。
在嘗試這個範例之前,請按照使用 BigQuery DataFrames 的 BigQuery 快速入門導覽課程中的 BigQuery DataFrames 設定說明操作。 詳情請參閱 BigQuery DataFrames 參考說明文件。
如要驗證 BigQuery,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定 ADC」。
ar_coefficients 輸出資料欄會顯示 ARIMA 模型自迴歸 (AR) 部分的模型係數。同樣地,ma_coefficients 輸出資料欄會顯示 ARIMA 模型移動平均 (MA) 部分的模型係數。這兩個資料欄都包含陣列值,長度分別等於 non_seasonal_p 和 non_seasonal_q。
使用模型預測資料
SQL
使用 ML.FORECAST 函式預測未來時間序列值。
在下列 GoogleSQL 查詢中,STRUCT(30 AS horizon, 0.8 AS confidence_level) 子句表示查詢會預測未來 30 個時間點,並產生信賴水準為 80% 的預測間隔。
如要使用模型預測資料,請按照下列步驟操作:
前往 Cloud de Confiance 控制台的「BigQuery」頁面。
在查詢編輯器中貼上以下查詢,然後點選「執行」:
SELECT * FROM ML.FORECAST(MODEL `bqml_tutorial.ga_arima_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level));
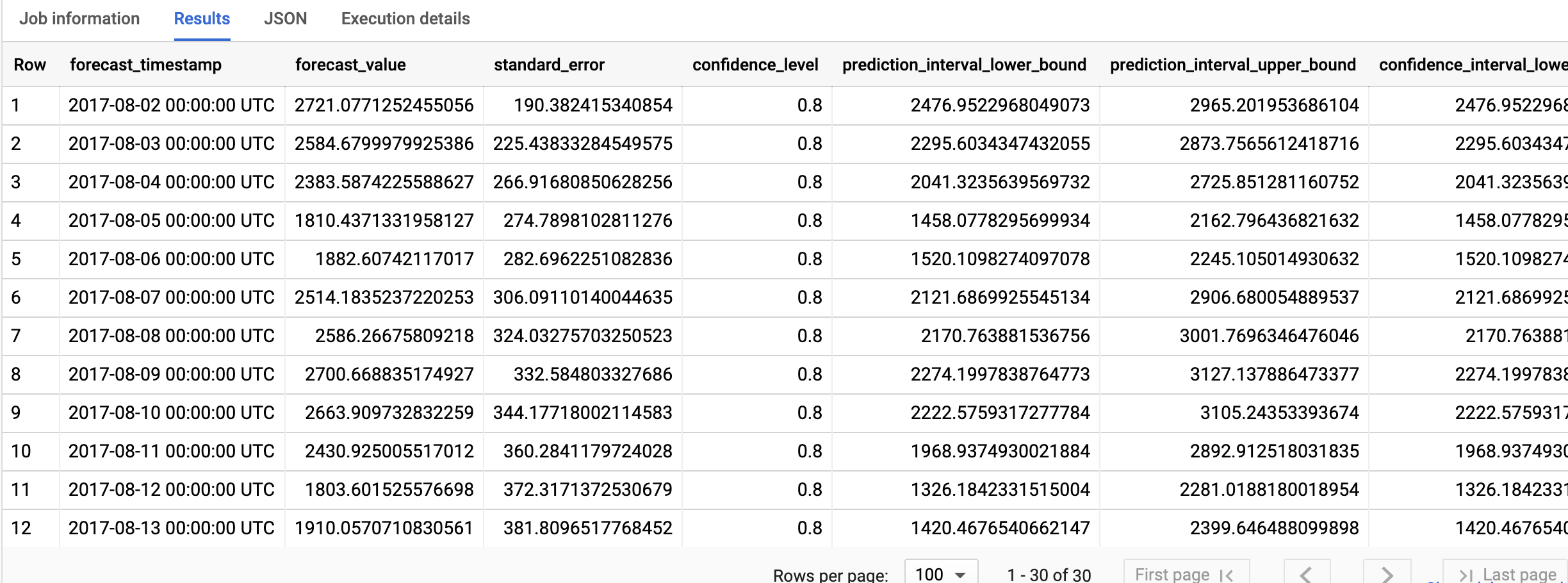
結果應如下所示:
BigQuery DataFrames
使用 predict 函式預測未來時間序列值。
在嘗試這個範例之前,請按照使用 BigQuery DataFrames 的 BigQuery 快速入門導覽課程中的 BigQuery DataFrames 設定說明操作。 詳情請參閱 BigQuery DataFrames 參考說明文件。
如要驗證 BigQuery,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定 ADC」。
輸出資料列會依 forecast_timestamp 欄值依時間順序排列。在時間序列預測中,預測間隔 (以 prediction_interval_lower_bound 和 prediction_interval_upper_bound 欄值表示) 與 forecast_value 欄值同樣重要。forecast_value 值是預測間隔的中間點。預測區間取決於 standard_error 和 confidence_level 欄的值。
如要進一步瞭解輸出資料欄,請參閱 ML.FORECAST 函式。
說明預測結果
SQL
您可以使用 ML.EXPLAIN_FORECAST 函式,除了取得預測資料,還能取得可解釋性指標。ML.EXPLAIN_FORECAST 函式會預測未來時間序列值,並傳回時間序列的所有個別元件。
與 ML.FORECAST 函式類似,ML.EXPLAIN_FORECAST 函式中使用的 STRUCT(30 AS horizon, 0.8 AS confidence_level) 子句表示查詢會預測未來 30 個時間點,並產生信賴度為 80% 的預測間隔。
請按照下列步驟說明模型的結果:
前往 Cloud de Confiance 控制台的「BigQuery」頁面。
在查詢編輯器中貼上以下查詢,然後點選「執行」:
SELECT * FROM ML.EXPLAIN_FORECAST(MODEL `bqml_tutorial.ga_arima_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level));
結果應如下所示:
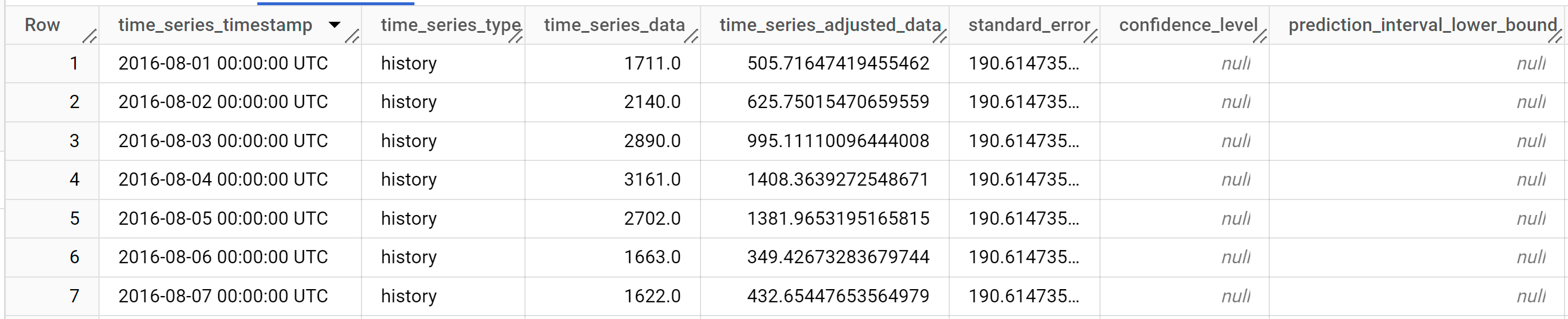
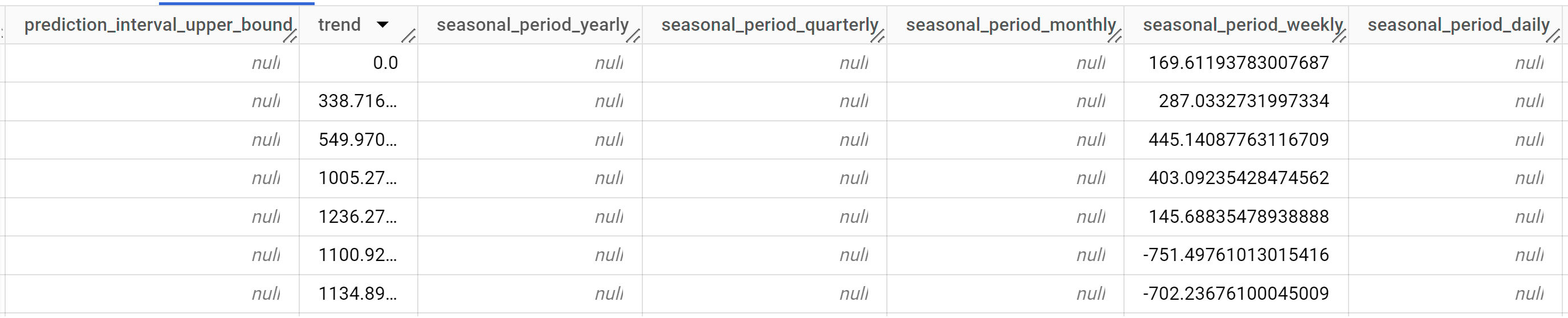
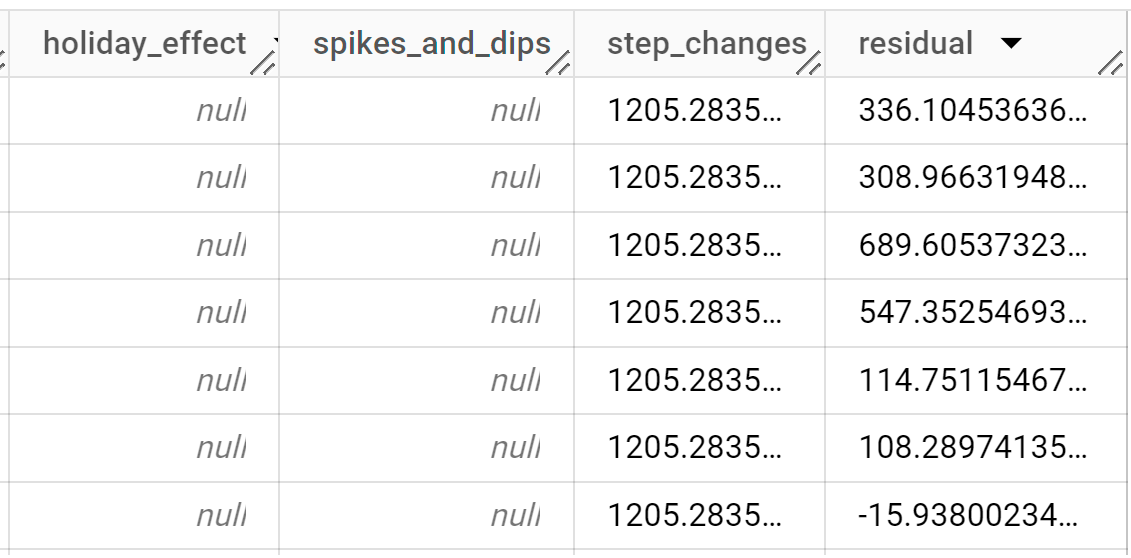
輸出資料列會依
time_series_timestamp資料欄值的時間順序排序。如要進一步瞭解輸出資料欄,請參閱
ML.EXPLAIN_FORECAST函式。
BigQuery DataFrames
您可以使用 predict_explain 函式,除了取得預測資料,還能取得可解釋性指標。predict_explain 函式會預測未來時間序列值,並傳回時間序列的所有個別元件。
與 predict 函式類似,predict_explain 函式中使用的 horizon=30, confidence_level=0.8 子句表示查詢會預測未來 30 個時間點,並產生信賴度為 80% 的預測間隔。
在嘗試這個範例之前,請按照使用 BigQuery DataFrames 的 BigQuery 快速入門導覽課程中的 BigQuery DataFrames 設定說明操作。 詳情請參閱 BigQuery DataFrames 參考說明文件。
如要驗證 BigQuery,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定 ADC」。
如要以視覺化方式呈現結果,請按照「以視覺化方式呈現輸入資料」一節的說明,使用 Looker Studio 建立圖表,並將下列資料欄做為指標:
time_series_dataprediction_interval_lower_boundprediction_interval_upper_boundtrendseasonal_period_weeklystep_changes