
Visualiser des graphiques à l'aide de BigQuery DataFrames
Ce document explique comment tracer différents types de graphiques à l'aide de la bibliothèque de visualisation BigQuery DataFrames.
L'API bigframes.pandas fournit un écosystème complet d'outils pour Python. L'API accepte les opérations statistiques avancées et vous pouvez visualiser les agrégations générées à partir de BigQuery DataFrames. Vous pouvez également passer de BigQuery DataFrames à un DataFrame pandas avec des opérations d'échantillonnage intégrées.
Histogramme
L'exemple suivant lit les données de la table bigquery-public-data.ml_datasets.penguins pour représenter un histogramme de la distribution des profondeurs de bec des manchots :
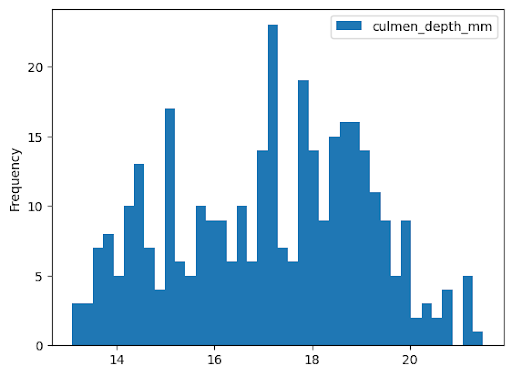
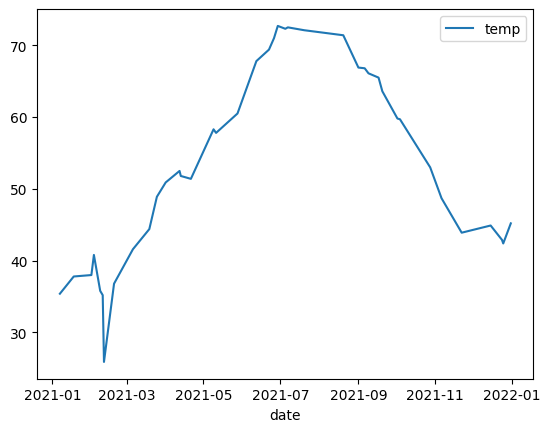
Graphique en courbes
L'exemple suivant utilise les données de la table bigquery-public-data.noaa_gsod.gsod2021 pour représenter un graphique en courbes des variations de température médiane tout au long de l'année :
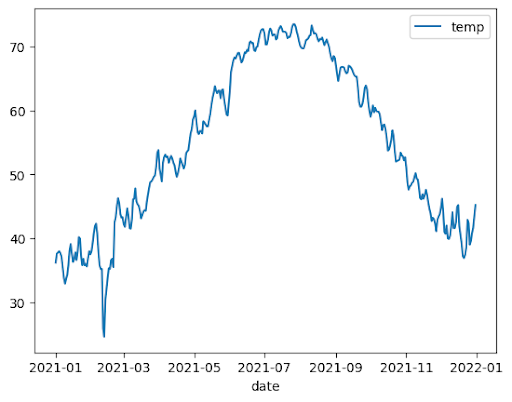
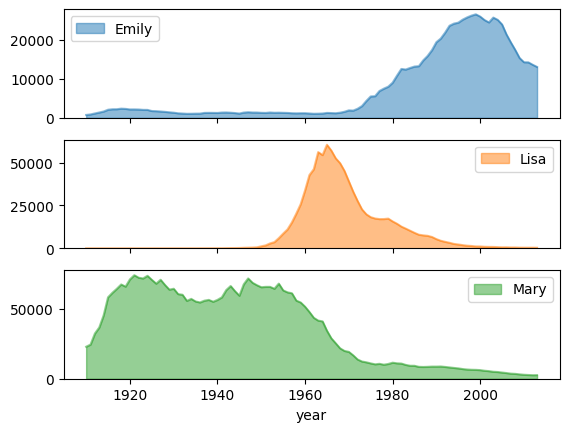
Graphique en aires
L'exemple suivant utilise la table bigquery-public-data.usa_names.usa_1910_2013 pour suivre la popularité des prénoms dans l'histoire des États-Unis et se concentre sur les prénoms Mary, Emily et Lisa :
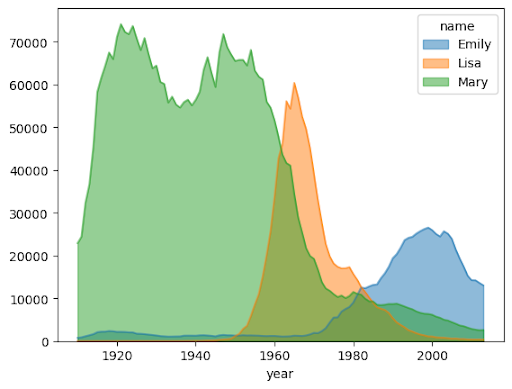
Graphique à barres
L'exemple suivant utilise la table bigquery-public-data.ml_datasets.penguins pour visualiser la répartition des sexes des manchots :
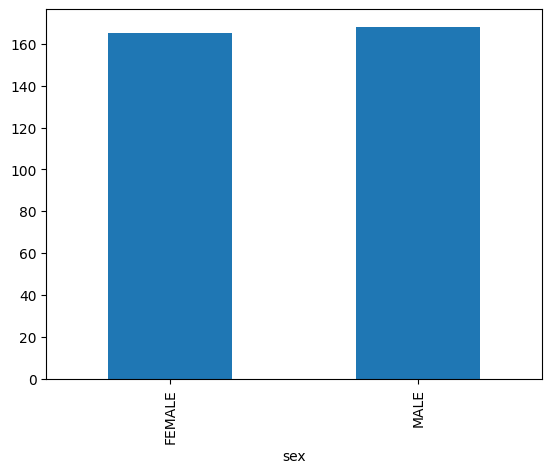
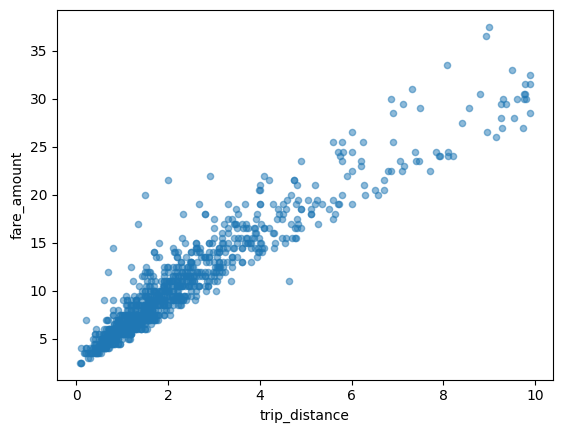
Graphique à nuage de points
L'exemple suivant utilise la table bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2021 pour explorer la relation entre les montants des courses en taxi et les distances parcourues :
Visualiser un grand ensemble de données
BigQuery DataFrames télécharge les données sur votre ordinateur local pour les visualiser. Par défaut,le nombre de points de données à télécharger est limité à 1 000. Si le nombre de points de données dépasse la limite, les DataFrames BigQuery échantillonnent aléatoirement le nombre de points de données égal à la limite.
Vous pouvez remplacer cette limite en définissant le paramètre sampling_n lorsque vous tracez un graphique, comme indiqué dans l'exemple suivant :
Représentation graphique avancée avec les paramètres pandas et Matplotlib
Vous pouvez transmettre d'autres paramètres pour affiner votre graphique, comme vous le feriez avec pandas, car la bibliothèque de graphiques de BigQuery DataFrames est optimisée par pandas et Matplotlib. Les sections suivantes décrivent des exemples.
Tendance de popularité des noms avec des sous-graphiques
En utilisant les données de l'historique des noms de l'exemple de graphique en aires, l'exemple suivant crée des graphiques individuels pour chaque nom en définissant subplots=True dans l'appel de la fonction plot.area() :
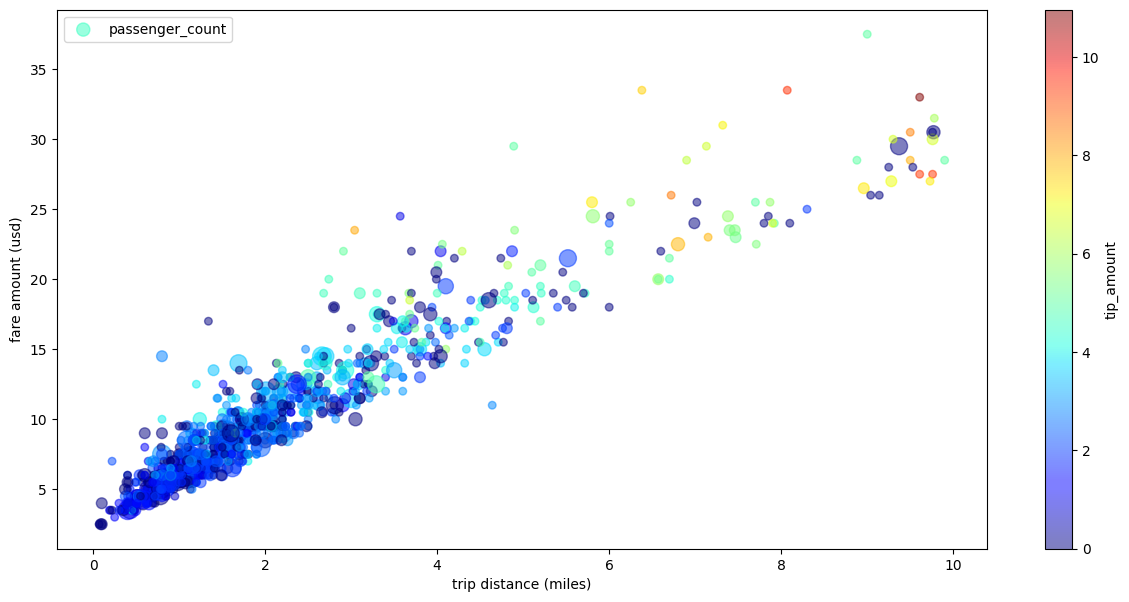
Graphique de dispersion des trajets en taxi avec plusieurs dimensions
En utilisant les données de l'exemple de nuage de points, l'exemple suivant renomme les libellés des axes X et Y, utilise le paramètre passenger_count pour la taille des points, utilise des points de couleur avec le paramètre tip_amount et redimensionne la figure :
Étapes suivantes
- En savoir plus sur BigQuery DataFrames
- Découvrez comment utiliser BigQuery DataFrames dans dbt.
- Explorez la documentation de référence de l'API BigQuery DataFrames.