
Utiliser BigQuery DataFrames dans dbt
dbt (data build tool) est un framework de ligne de commande Open Source conçu pour la transformation de données dans les entrepôts de données modernes. dbt facilite les transformations de données modulaires en créant des modèles réutilisables basés sur SQL et Python. L'outil orchestre l'exécution de ces transformations dans l'entrepôt de données cible, en se concentrant sur l'étape de transformation du pipeline ELT. Pour en savoir plus, consultez la documentation dbt.
Dans dbt, un modèle Python est une transformation de données définie et exécutée à l'aide de code Python dans votre projet dbt. Au lieu d'écrire du code SQL pour la logique de transformation, vous écrivez des scripts Python que dbt orchestre ensuite pour qu'ils s'exécutent dans l'environnement de l'entrepôt de données. Un modèle Python vous permet d'effectuer des transformations de données qui peuvent être complexes ou inefficaces à exprimer en SQL. Cela exploite les capacités de Python tout en bénéficiant de la structure de projet, de l'orchestration, de la gestion des dépendances, des tests et des fonctionnalités de documentation de dbt. Pour en savoir plus, consultez Modèles Python.
L'adaptateur dbt-bigquery permet d'exécuter du code Python défini dans les DataFrames BigQuery. Cette fonctionnalité est disponible dans dbt Cloud et dbt Core.
Vous pouvez également obtenir cette fonctionnalité en clonant la dernière version de l'adaptateur dbt-bigquery.
Avant de commencer
Pour utiliser l'adaptateur dbt-bigquery, activez les API suivantes dans votre projet :
- API BigQuery (
bigquery.googleapis.com) - API Cloud Storage (
storage.googleapis.com) - API Compute Engine (
compute.googleapis.com) - API Dataform (
dataform.googleapis.com) - API Identity and Access Management (
iam.googleapis.com) - API Vertex AI (
aiplatform.googleapis.com)
Rôles requis pour activer les API
Pour activer les API, vous avez besoin du rôle IAM Administrateur Service Usage (roles/serviceusage.serviceUsageAdmin), qui contient l'autorisation serviceusage.services.enable. Découvrez comment attribuer des rôles.
Rôles requis
L'adaptateur dbt-bigquery est compatible avec l'authentification basée sur OAuth et sur un compte de service. Les sections suivantes décrivent les rôles requis en fonction de la méthode d'authentification que vous prévoyez d'utiliser.
OAuth
Si vous prévoyez de vous authentifier auprès de l'adaptateur dbt-bigquery à l'aide d'OAuth, demandez à votre administrateur de vous accorder les rôles suivants :
- Rôle Utilisateur BigQuery
(
roles/bigquery.user) sur le projet - Rôle Éditeur de données BigQuery (
roles/bigquery.dataEditor) sur le projet ou l'ensemble de données dans lequel les tables sont enregistrées - Rôle Utilisateur Colab Enterprise
(
roles/colabEnterprise.user) sur le projet - Rôle Administrateur de l'espace de stockage (
roles/storage.admin) sur le bucket Cloud Storage de préproduction pour le code et les journaux de préproduction
Compte de service
Si vous prévoyez de vous authentifier auprès de l'adaptateur dbt-bigquery à l'aide d'un compte de service dans votre projet, demandez à votre administrateur d'attribuer les rôles suivants au compte de service que vous prévoyez d'utiliser :
- Rôle Utilisateur BigQuery
(
roles/bigquery.user) - Rôle Éditeur de données BigQuery
(
roles/bigquery.dataEditor) - Rôle "Utilisateur Colab Enterprise"
(
roles/colabEnterprise.user) - Rôle Administrateur de l'espace de stockage
(
roles/storage.admin)
Si vous vous authentifiez à l'aide d'un compte de service, assurez-vous également que le rôle Utilisateur du compte de service (roles/iam.serviceAccountUser) est attribué au compte de service que vous prévoyez d'utiliser.
Emprunter l'identité d'un compte de service
Si vous prévoyez de vous authentifier auprès de l'adaptateur dbt-bigquery à l'aide d'OAuth, mais que vous souhaitez que le traitement des données et l'exécution du notebook se fassent sous l'identité d'un compte de service dans le même projet que celui dans lequel les jobs sont exécutés, demandez à votre administrateur de vous accorder les rôles suivants :
- Rôle Créateur de jetons du compte de service (
roles/iam.serviceAccountTokenCreator) - Utilisateur du compte de service
(
roles/iam.serviceAccountUser)
Le compte de service dont l'identité est empruntée doit également disposer de tous les rôles requis pour l'authentification.
Comptes de service multiprojets
Si vous prévoyez de vous authentifier auprès de l'adaptateur dbt-bigquery à l'aide d'un compte de service dans un autre projet (le projet d'identifiants, à partir duquel les jobs sont exécutés, le projet d'exécution), demandez à votre administrateur de procéder comme suit :
- Désactivez la contrainte
constraints/iam.disableCrossProjectServiceAccountUsagedans le projet d'identifiants. En plus de tous les rôles requis pour l'authentification du compte de service, attribuez les rôles suivants au compte de service dans le projet d'identifiants :
- Rôle Agent de service Vertex AI (roles/aiplatform.serviceAgent) à
service-PROJECT_NUMBER@gcp-sa-aiplatform.s3ns-system.iam.gserviceaccount.com - Rôle Agent de service Vertex AI Colab (roles/aiplatform.colabServiceAgent) à
service-PROJECT_NUMBER@gcp-sa-vertex-nb.s3ns-system.iam.gserviceaccount.com - Rôle d'agent de service Compute Engine (roles/compute.serviceAgent) à
service-PROJECT_NUMBER@compute-system.s3ns-system.iam.gserviceaccount.com
- Rôle Agent de service Vertex AI (roles/aiplatform.serviceAgent) à
Si vous prévoyez de vous authentifier auprès de l'adaptateur dbt-bigquery à l'aide d'OAuth, mais que vous souhaitez que le traitement des données et l'exécution du notebook se fassent sous l'identité d'un compte de service dans un projet différent de celui à partir duquel les jobs sont exécutés, demandez à votre administrateur de procéder comme suit :
- Suivez les étapes décrites précédemment pour les comptes de service inter-projets pour le compte de service dans un autre projet.
- Attribuez-vous, ainsi qu'au compte de service, les rôles requis pour l'emprunt d'identité d'un compte de service.
VPC partagé
Si vous utilisez Colab Enterprise dans un environnement VPC partagé, demandez à votre administrateur de vous accorder les rôles et autorisations suivants :
Autorisation
compute.subnetworks.use: accordez cette autorisation au compte de service utilisé par l'environnement d'exécution Colab Enterprise sur le projet hôte ou sur des sous-réseaux spécifiques. Cette autorisation est incluse dans le rôle Utilisateur de réseau Compute (roles/compute.networkUser).Autorisation
compute.subnetworks.get: accordez cette autorisation au compte de service utilisé par l'environnement d'exécution Colab Enterprise sur le projet hôte ou sur des sous-réseaux spécifiques. Cette autorisation est incluse dans le rôle Lecteur de réseau Compute (roles/compute.networkViewer).Rôle Utilisateur de réseau Compute (
roles/compute.networkUser) : accordez ce rôle à l'agent de service Gemini Enterprise Agent Platform,service-PROJECT_NUMBER@gcp-sa-aiplatform.s3ns-system.iam.gserviceaccount.com, sur le projet hôte de VPC partagé.Rôle Utilisateur de réseau Compute (
roles/compute.networkUser) : si la fonctionnalité d'exécution des jobs de notebook est utilisée, accordez ce rôle à l'agent de service Colab Enterprise,service-PROJECT_NUMBER@gcp-sa-vertex-nb.s3ns-system.iam.gserviceaccount.com, sur le projet hôte de VPC partagé.
Pour en savoir plus sur l'attribution de rôles, consultez Gérer l'accès aux projets, aux dossiers et aux organisations.
Vous pouvez également obtenir les autorisations requises via des rôles personnalisés ou d'autres rôles prédéfinis.
Environnement d'exécution Python
L'adaptateur dbt-bigquery utilise le service d'exécution de notebooks Colab Enterprise pour exécuter le code Python BigQuery DataFrames. Un notebook Colab Enterprise est automatiquement créé et exécuté par l'adaptateur dbt-bigquery pour chaque modèle Python. Vous pouvez choisir le projetCloud de Confiance dans lequel exécuter le notebook. Le notebook exécute le code Python du modèle, qui est converti en code SQL BigQuery par la bibliothèque BigQuery DataFrames. Le code BigQuery SQL est ensuite exécuté dans le projet configuré. Le schéma suivant présente le flux de contrôle :
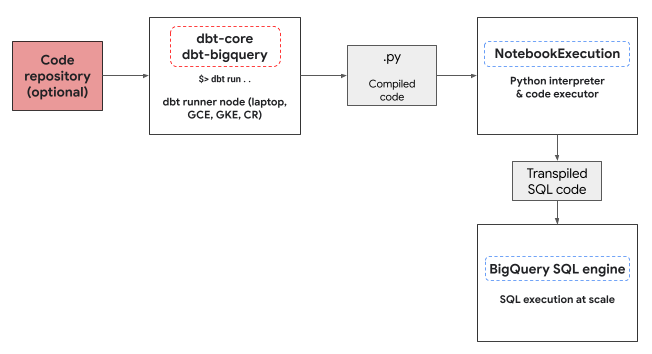
Si aucun modèle de notebook n'est déjà disponible dans le projet et que l'utilisateur exécutant le code dispose des autorisations nécessaires pour créer le modèle, l'adaptateur dbt-bigquery crée et utilise automatiquement le modèle de notebook par défaut. Vous pouvez également spécifier un autre modèle de notebook à l'aide d'une configuration dbt.
L'exécution du notebook nécessite un bucket Cloud Storage intermédiaire pour stocker le code et les journaux. Toutefois, l'adaptateur dbt-bigquery copie les journaux dans les journaux dbt. Vous n'avez donc pas besoin de parcourir le bucket.
Fonctionnalités compatibles
L'adaptateur dbt-bigquery est compatible avec les fonctionnalités suivantes pour les modèles dbt Python exécutant BigQuery DataFrames :
- Charger des données à partir d'une table BigQuery existante avec la macro
dbt.source(). - Charger des données à partir d'autres modèles dbt avec la macro
dbt.ref()pour créer des dépendances et des graphes orientés acycliques (DAG) avec des modèles Python. - Spécifier et utiliser des packages Python de PyPi pouvant être utilisés avec l'exécution de code Python. Pour en savoir plus, consultez Configurations.
- Spécifier un modèle d'environnement d'exécution de notebook personnalisé pour vos modèles BigQuery DataFrames.
L'adaptateur dbt-bigquery est compatible avec les stratégies de matérialisation suivantes :
- Matérialisation de table, où les données sont reconstruites sous forme de tableau à chaque exécution.
- Matérialisation incrémentielle avec une stratégie de fusion, où les données nouvelles ou mises à jour sont ajoutées à une table existante, souvent à l'aide d'une stratégie de fusion pour gérer les modifications.
Configurer dbt pour utiliser BigQuery DataFrames
Si vous utilisez dbt Core, vous devez utiliser un fichier profiles.yml pour l'utiliser avec BigQuery DataFrames.
L'exemple suivant utilise la méthode oauth :
your_project_name:
outputs:
dev:
compute_region: us-central1
dataset: your_bq_dateset
gcs_bucket: your_gcs_bucket
job_execution_timeout_seconds: 300
job_retries: 1
location: US
method: oauth
priority: interactive
project: your_gcp_project
threads: 1
type: bigquery
target: dev
Si vous utilisez dbt Cloud, vous pouvez vous connecter à votre plate-forme de données directement dans l'interface dbt Cloud. Dans ce scénario, vous n'avez pas besoin de fichier profiles.yml. Pour en savoir plus, consultez À propos de profiles.yml.
Voici un exemple de configuration au niveau du projet pour le fichier dbt_project.yml :
# Name your project! Project names should contain only lowercase characters
# and underscores. A good package name should reflect your organization's
# name or the intended use of these models.
name: 'your_project_name'
version: '1.0.0'
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the config(...) macro.
models:
your_project_name:
submission_method: bigframes
notebook_template_id: 7018811640745295872
packages: ["scikit-learn", "mlflow"]
timeout: 3000
# Config indicated by + and applies to all files under models/example/
example:
+materialized: view
Certains paramètres peuvent également être configurés à l'aide de la méthode dbt.config dans votre code Python. Si ces paramètres entrent en conflit avec votre fichier dbt_project.yml, les configurations avec dbt.config seront prioritaires.
Pour en savoir plus, consultez Configurations de modèle et dbt_project.yml.
Configurations
Vous pouvez configurer les éléments suivants à l'aide de la méthode dbt.config dans votre modèle Python. Ces configurations remplacent celles au niveau du projet.
| Configuration | Obligatoire | Utilisation |
|---|---|---|
submission_method |
Oui | submission_method=bigframes |
notebook_template_id |
Non | Si aucun modèle n'est spécifié, un modèle par défaut est créé et utilisé. |
packages |
Non | Spécifiez la liste supplémentaire des packages Python, si nécessaire. |
timeout |
Non | Facultatif : Prolongez le délai avant expiration de l'exécution du job. |
Exemples de modèles Python
Les sections suivantes présentent des exemples de scénarios et de modèles Python.
Charger des données à partir d'une table BigQuery
Pour utiliser les données d'une table BigQuery existante comme source dans votre modèle Python, vous devez d'abord définir cette source dans un fichier YAML. L'exemple suivant est défini dans un fichier source.yml.
version: 2
sources:
- name: my_project_source # A custom name for this source group
database: bigframes-dev # Your Google Cloud project ID
schema: yyy_test_us # The BigQuery dataset containing the table
tables:
- name: dev_sql1 # The name of your BigQuery table
Ensuite, vous créez votre modèle Python, qui peut utiliser les sources de données configurées dans ce fichier YAML :
def model(dbt, session):
# Configure the model to use BigFrames for submission
dbt.config(submission_method="bigframes")
# Load data from the 'dev_sql1' table within 'my_project_source'
source_data = dbt.source('my_project_source', 'dev_sql1')
# Example transformation: Create a new column 'id_new'
source_data['id_new'] = source_data['id'] * 10
return source_data
Référencer un autre modèle
Vous pouvez créer des modèles qui dépendent de la sortie d'autres modèles dbt, comme illustré dans l'exemple suivant. Cette fonctionnalité est utile pour créer des pipelines de données modulaires.
def model(dbt, session):
# Configure the model to use BigFrames
dbt.config(submission_method="bigframes")
# Reference another dbt model named 'dev_sql1'.
# It assumes you have a model defined in 'dev_sql1.sql' or 'dev_sql1.py'.
df_from_sql = dbt.ref("dev_sql1")
# Example transformation on the data from the referenced model
df_from_sql['id'] = df_from_sql['id'] * 100
return df_from_sql
Spécifier une dépendance de package
Si votre modèle Python nécessite des bibliothèques tierces spécifiques telles que MLflow ou Boto3, vous pouvez déclarer le package dans la configuration du modèle, comme indiqué dans l'exemple suivant. Ces packages sont installés dans l'environnement d'exécution.
def model(dbt, session):
# Configure the model for BigFrames and specify required packages
dbt.config(
submission_method="bigframes",
packages=["mlflow", "boto3"] # List the packages your model needs
)
# Import the specified packages for use in your model
import mlflow
import boto3
# Example: Create a DataFrame showing the versions of the imported packages
data = {
"mlflow_version": [mlflow.__version__],
"boto3_version": [boto3.__version__],
"note": ["This demonstrates accessing package versions after import."]
}
bdf = bpd.DataFrame(data)
return bdf
Spécifier un modèle autre que celui par défaut
Pour mieux contrôler l'environnement d'exécution ou utiliser des paramètres préconfigurés, vous pouvez spécifier un modèle de notebook non défini par défaut pour votre modèle BigQuery DataFrames, comme illustré dans l'exemple suivant.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# ID of your pre-created notebook template
notebook_template_id="857350349023451yyyy",
)
data = {"int": [1, 2, 3], "str": ['a', 'b', 'c']}
return bpd.DataFrame(data=data)
Matérialiser les tables
Lorsque dbt exécute vos modèles Python, il doit savoir comment enregistrer les résultats dans votre entrepôt de données. C'est ce qu'on appelle la matérialisation.
Pour la matérialisation standard des tables, dbt crée ou remplace entièrement une table dans votre entrepôt par la sortie de votre modèle à chaque exécution. Cela se fait par défaut ou en définissant explicitement la propriété materialized='table', comme indiqué dans l'exemple suivant.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# Instructs dbt to create/replace this model as a table
materialized='table',
)
data = {"int_column": [1, 2], "str_column": ['a', 'b']}
return bpd.DataFrame(data=data)
La matérialisation incrémentielle avec une stratégie de fusion permet à dbt de mettre à jour votre table uniquement avec les lignes nouvelles ou modifiées. Cela est utile pour les grands ensembles de données, car la reconstruction complète d'une table à chaque fois peut être inefficace. La stratégie de fusion est une méthode courante pour gérer ces mises à jour.
Cette approche intègre intelligemment les modifications en procédant comme suit :
- Mise à jour des lignes existantes qui ont été modifiées.
- Ajouter des lignes
- Facultatif, selon la configuration : suppression des lignes qui ne sont plus présentes dans la source.
Pour utiliser la stratégie de fusion, vous devez spécifier une propriété unique_key que dbt peut utiliser pour identifier les lignes correspondantes entre la sortie de votre modèle et la table existante, comme illustré dans l'exemple suivant.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
materialized='incremental',
incremental_strategy='merge',
unique_key='int', # Specifies the column to identify unique rows
)
# In this example:
# - Row with 'int' value 1 remains unchanged.
# - Row with 'int' value 2 has been updated.
# - Row with 'int' value 4 is a new addition.
# The 'merge' strategy will ensure that only the updated row ('int 2')
# and the new row ('int 4') are processed and integrated into the table.
data = {"int": [1, 2, 4], "str": ['a', 'bbbb', 'd']}
return bpd.DataFrame(data=data)
Dépannage
Vous pouvez observer l'exécution Python dans les journaux dbt.
Vous pouvez également afficher le code et les journaux (y compris les exécutions précédentes) sur la page Exécutions Colab Enterprise.
Accéder aux exécutions Colab Enterprise
Facturation
Lorsque vous utilisez l'adaptateur dbt-bigquery avec BigQuery DataFrames, des frais Cloud de Confiance by S3NS sont facturés pour les éléments suivants :
Exécution de notebooks : l'exécution de l'environnement d'exécution du notebook vous est facturée. Pour en savoir plus, consultez Tarifs des environnements d'exécution de notebooks.
Exécution des requêtes BigQuery : dans le notebook, BigQuery DataFrames convertit Python en SQL et exécute le code dans BigQuery. Vous êtes facturé en fonction de la configuration de votre projet et de votre requête, comme décrit dans les tarifs de BigQuery DataFrames.
Vous pouvez utiliser le libellé de facturation suivant dans la console de facturation BigQuery pour filtrer le rapport sur la facturation pour l'exécution de notebooks et pour les exécutions BigQuery déclenchées par l'adaptateur dbt-bigquery :
- Libellé d'exécution BigQuery :
bigframes-dbt-api
Étapes suivantes
- Pour en savoir plus sur dbt et BigQuery DataFrames, consultez Utiliser BigQuery DataFrames avec les modèles Python dbt.
- Pour en savoir plus sur les modèles Python dbt, consultez Modèles Python et Configuration des modèles Python.
- Pour en savoir plus sur les notebooks Colab Enterprise, consultez Créer un notebook Colab Enterprise à l'aide de la console Cloud de Confiance .
- Pour en savoir plus sur les partenaires Cloud de Confiance by S3NS , consultez Cloud de Confiance by S3NS Ready – Partenaires BigQuery.