
Puoi utilizzare la privacy differenziale con BigQuery per proteggere le informazioni personali nei tuoi dati mentre esegui ancora calcoli e ottieni approfondimenti. Questo standard di privacy limita le informazioni personali rivelate dagli output dei dati, consentendoti di condividere i dati e fare inferenze sui gruppi senza esporre i singoli individui. La privacy differenziale è particolarmente utile quando esiste un rischio di reidentificazione o quando devi quantificare il compromesso tra rischio per la privacy e utilità analitica.
Per i dettagli della sintassi, consulta la clausola sulla privacy differenziale. Per un elenco di funzioni che puoi utilizzare con questa sintassi, consulta Funzioni aggregate con privacy differenziale.
Esempio di caso d'uso per la privacy differenziale
Per comprendere meglio la privacy differenziale, vediamo un esempio semplice.
Questo grafico a barre mostra l'affluenza in un piccolo ristorante in una particolare serata. Molti ospiti arrivano alle 19:00 e il ristorante è completamente vuoto all'1:00:
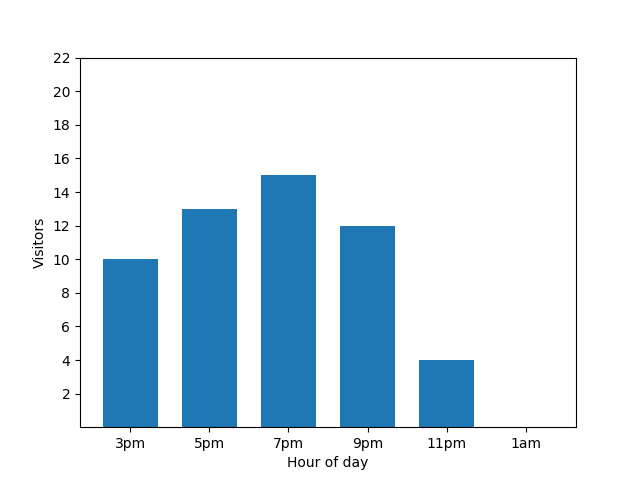
Questo grafico sembra utile, ma c'è un problema. Quando arriva un nuovo ospite, questo viene immediatamente rivelato dal grafico a barre. Nel grafico seguente è chiaro che è arrivato un nuovo ospite, intorno all'1:00:
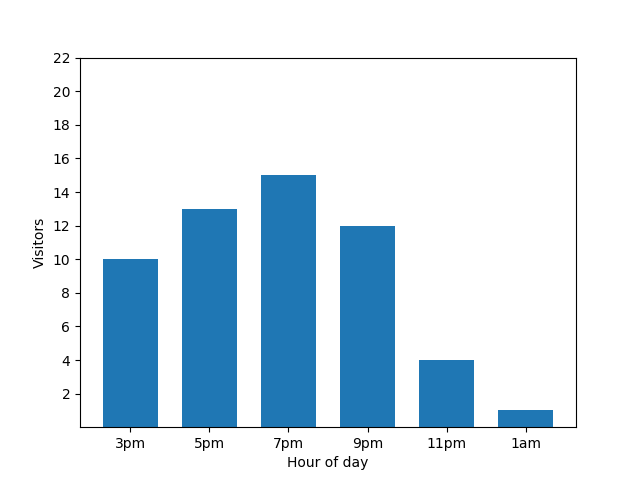
Mostrare questo dettaglio non è ideale dal punto di vista della privacy, in quanto le statistiche anonimizzate non devono rivelare i contributi individuali. Se metti i due grafici uno accanto all'altro, la differenza è ancora più evidente: il grafico a barre arancione ha un ospite in più che è arrivato intorno all'1:00:
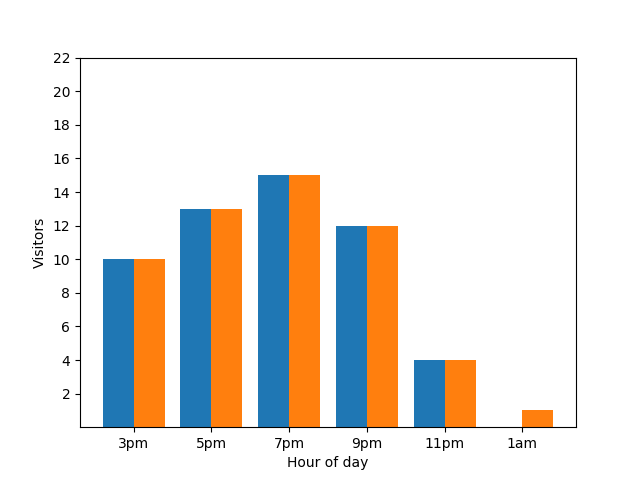
Anche in questo caso, non è il massimo. Per evitare questo tipo di problema di privacy, puoi aggiungere rumore casuale ai grafici a barre utilizzando la privacy differenziale. Nel seguente grafico comparativo, i risultati sono anonimizzati e non rivelano più i singoli contributi.
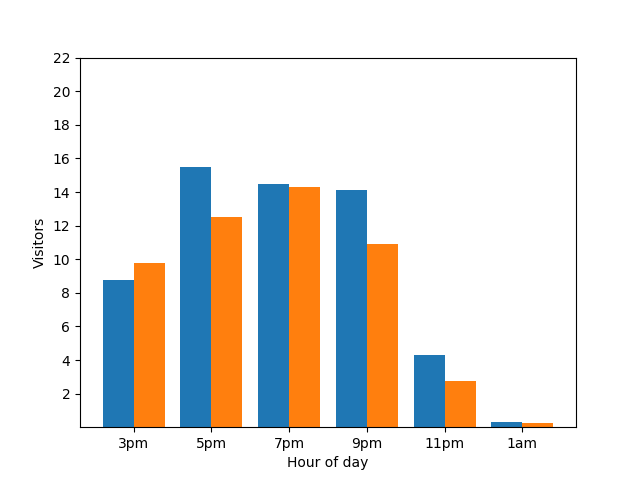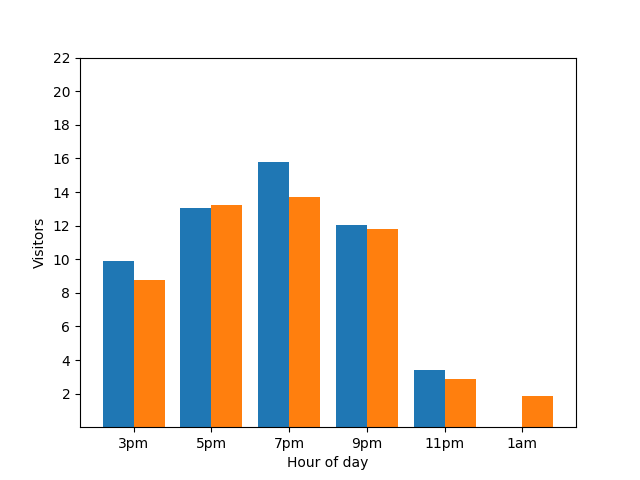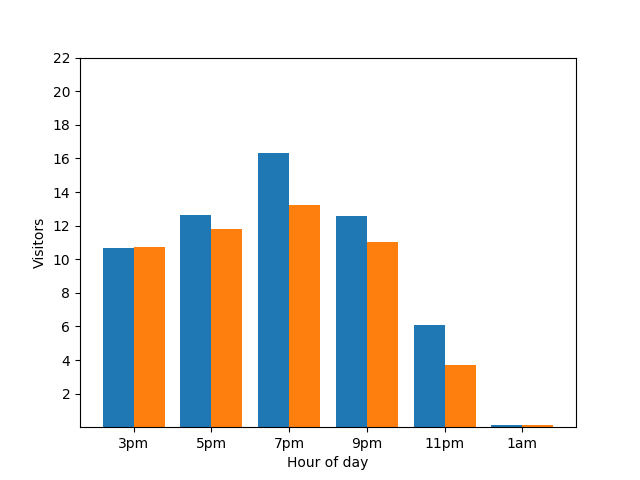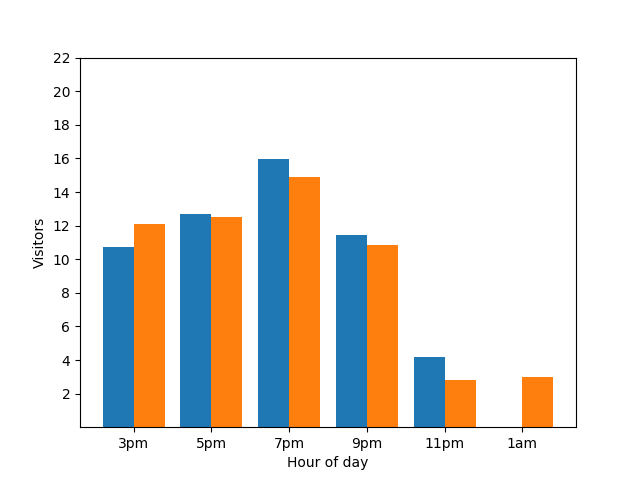
Come funziona la privacy differenziale nelle query
L'obiettivo della privacy differenziale è mitigare il rischio di divulgazione, ovvero il rischio che qualcuno possa ottenere informazioni su un'entità in un set di dati. La privacy differenziale bilancia la necessità di salvaguardare la privacy con la necessità di utilità analitica statistica. Man mano che la privacy aumenta, l'utilità dell'analisi statistica diminuisce e viceversa.
Con GoogleSQL per BigQuery, puoi trasformare i risultati di una query con aggregazioni differenzialmente private. Quando viene eseguita la query, vengono eseguite le seguenti operazioni:
- Calcola le aggregazioni per entità per ogni gruppo se i gruppi sono specificati con
una clausola
GROUP BY. Limita il numero di gruppi a cui ogni entità può contribuire, in base al parametro di privacy differenzialemax_groups_contributed. - Limita il contributo aggregato per entità in modo che rientri nei limiti di troncamento. Se i limiti di troncamento non sono specificati, vengono calcolati implicitamente in modo differenzialmente privato.
- Aggrega i contributi aggregati bloccati per entità per ogni gruppo.
- Aggiunge rumore al valore aggregato finale per ogni gruppo. La scala del rumore casuale è una funzione di tutti i limiti fissati e dei parametri della privacy.
- Calcola un conteggio delle entità con rumore per ogni gruppo ed elimina i gruppi con poche entità. Un conteggio delle entità con rumore contribuisce a eliminare un insieme non deterministico di gruppi.
Il risultato finale è un set di dati in cui ogni gruppo dispone di risultati aggregati sul rumore, mentre i gruppi piccoli vengono eliminati.
Per ulteriori informazioni su che cos'è la privacy differenziale e sui suoi casi d'uso, consulta i seguenti articoli:
- Un'introduzione semplice e non tecnica alla privacy differenziale
- SQL con privacy differenziale con contributo utente limitato
- Privacy differenziale su Wikipedia
Produci una query di privacy differenziale valida
Per essere valida, la query con privacy differenziale deve soddisfare le seguenti regole:
- È definita una colonna unità privacy.
- L'elenco
SELECTcontiene una clausola di privacy differenziale. - Solo le funzioni aggregate con privacy differenziale sono
nell'elenco
SELECTcon la clausola di privacy differenziale.
Definisci una colonna unità privacy
Un'unità di privacy è l'entità di un set di dati che viene protetta utilizzando la privacy differenziale. Un'entità può essere una persona, un'azienda, una sede o qualsiasi colonna tu scelga.
Una query con privacy differenziale deve includere una sola colonna unità privacy. Una colonna unità privacy è un identificatore univoco per un'unità privacy e può esistere in più gruppi. Poiché sono supportati più gruppi, il tipo di dati per la colonna unità privacy deve essere raggruppabile.
Puoi definire una colonna unità privacy nella clausola OPTIONS di una
clausola di privacy differenziale con l'identificatore univoco privacy_unit_column.
Negli esempi seguenti, una colonna unità privacy viene aggiunta a una
clausola di privacy differenziale. id rappresenta una colonna che ha origine da una
tabella denominata students.
SELECT WITH DIFFERENTIAL_PRIVACY
OPTIONS (epsilon=10, delta=.01, privacy_unit_column=id)
item,
COUNT(*, contribution_bounds_per_group=>(0, 100))
FROM students;
SELECT WITH DIFFERENTIAL_PRIVACY
OPTIONS (epsilon=10, delta=.01, privacy_unit_column=members.id)
item,
COUNT(*, contribution_bounds_per_group=>(0, 100))
FROM (SELECT * FROM students) AS members;
Rimuovere il rumore da una query con privacy differenziale
Nella sezione "Sintassi della query", vedi Rimuovi rumore.
Aggiungere rumore a una query con privacy differenziale
Nella sezione "Sintassi della query", consulta Aggiungi rumore.
Limitare i gruppi in cui può esistere un ID unità di privacy
Nella sezione "Sintassi delle query", consulta Limitare i gruppi in cui può esistere un ID unità di privacy.
Limitazioni
Questa sezione descrive le limitazioni della privacy differenziale.
Implicazioni per il rendimento della privacy differenziale
Le query con privacy differenziale vengono eseguite più lentamente rispetto alle query standard
perché viene eseguita l'aggregazione per entità e viene applicata la limitazione max_groups_contributed. La limitazione dei limiti di contributo può contribuire a migliorare il rendimento
delle query con privacy differenziale.
I profili di rendimento delle seguenti query non sono simili:
SELECT
WITH DIFFERENTIAL_PRIVACY OPTIONS(epsilon=1, delta=1e-10, privacy_unit_column=id)
column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
SELECT column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
Il motivo della differenza di rendimento è che per le query con privacy differenziale viene eseguito un livello di raggruppamento aggiuntivo con granularità più fine, perché deve essere eseguita anche l'aggregazione per entità.
I profili di rendimento delle seguenti query dovrebbero essere simili, anche se la query con privacy differenziale è leggermente più lenta:
SELECT
WITH DIFFERENTIAL_PRIVACY OPTIONS(epsilon=1, delta=1e-10, privacy_unit_column=id)
column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
SELECT column_a, id, COUNT(column_b)
FROM table_a
GROUP BY column_a, id;
La query con privacy differenziale viene eseguita più lentamente perché ha un numero elevato di valori distinti per la colonna dell'unità di privacy.
Limitazioni implicite del riquadro di selezione per i set di dati di piccole dimensioni
Il bounding implicito funziona meglio se calcolato utilizzando set di dati di grandi dimensioni. Il bounding implicito può non riuscire con set di dati che contengono un numero ridotto di unità di privacy, senza restituire risultati. Inoltre, il bounding implicito su un set di dati con un numero ridotto di unità di privacy può bloccare una gran parte dei non outlier, il che comporta aggregazioni sottostimate e risultati più alterati dal blocco che dal rumore aggiunto. I set di dati con un numero ridotto di unità di privacy o con partizioni sottili devono utilizzare un clamping esplicito anziché implicito.
Vulnerabilità di privacy
Qualsiasi algoritmo di privacy differenziale, incluso questo, comporta il rischio di una perdita di dati privati quando un analista agisce in malafede, soprattutto quando calcola statistiche di base come le somme, a causa di limitazioni aritmetiche.
Limitazioni delle garanzie di privacy
Sebbene la privacy differenziale di BigQuery applichi l'algoritmo di privacy differenziale, non garantisce le proprietà di privacy del set di dati risultante.
Errori di runtime
Un analista che agisce in malafede con la possibilità di scrivere query o controllare i dati di input potrebbe attivare un errore di runtime sui dati privati.
Rumore in virgola mobile
Prima di utilizzare la privacy differenziale, è necessario considerare le vulnerabilità relative all'arrotondamento, all'arrotondamento ripetuto e agli attacchi di riordino. Queste vulnerabilità sono particolarmente preoccupanti quando un malintenzionato può controllare alcuni contenuti di un set di dati o l'ordine dei contenuti in un set di dati.
Le aggiunte di rumore con privacy differenziale sui tipi di dati in virgola mobile sono soggette alle vulnerabilità descritte in Widespread Underestimation of Sensitivity in Differentially Private Libraries and How to Fix It. Le aggiunte di rumore ai tipi di dati interi non sono soggette alle vulnerabilità descritte nel documento.
Rischi di attacchi di temporizzazione
Un analista che agisce in malafede potrebbe eseguire una query sufficientemente complessa per fare un'inferenza sui dati di input in base alla durata di esecuzione di una query.
Classificazione errata
La creazione di una query di privacy differenziale presuppone che i dati siano in una struttura nota e comprensibile. Se applichi la privacy differenziale agli identificatori sbagliati, ad esempio a uno che rappresenta un ID transazione anziché l'ID di una persona, potresti esporre dati sensibili.
Se hai bisogno di aiuto per comprendere i tuoi dati, valuta la possibilità di utilizzare servizi e strumenti come i seguenti:
Prezzi
L'utilizzo della privacy differenziale non comporta costi aggiuntivi, ma si applicano i prezzi standard di BigQuery per l'analisi.