
קבלת תובנות לגבי הביצועים של שאילתות
גרף ההפעלה של שאילתה הוא ייצוג חזותי של השלבים ש-BigQuery מבצע כדי להריץ את השאילתה. במאמר הזה מוסבר איך משתמשים בתרשים ההפעלה של שאילתות כדי לאבחן בעיות בביצועים שלהן ואיך מקבלים ממנו תובנות לגבי ביצועים של שאילתות.
ביצועי השאילתות ב-BigQuery טובים מאוד, אבל זו גם מערכת מורכבת ומבוזרת עם הרבה גורמים פנימיים וחיצוניים שיכולים להשפיע על מהירות השאילתות. האופי הדקלרטיבי של SQL יכול גם להסתיר את המורכבות של ביצוע השאילתה. המשמעות היא שאם השאילתות שלכם פועלות לאט יותר מהצפוי או לאט יותר מהפעלה קודמת, יכול להיות שיהיה לכם קשה להבין מה קרה.
תרשים ההפעלה של השאילתות מספק ממשק גרפי דינמי לבדיקה של תוכנית השאילתות ופרטי הביצועים שלהן. אפשר לבדוק את תרשים הביצוע של השאילתה לכל שאילתה שפועלת או שהסתיימה.
אפשר גם להשתמש בתרשים ההפעלה של שאילתות כדי לקבל תובנות לגבי הביצועים של שאילתות. התובנות לגבי הביצועים כוללות הצעות שעוזרות לשפר את הביצועים של השאילתות. הביצועים של שאילתות הם מורכבים, ולכן התובנות לגבי הביצועים עשויות לספק רק תמונה חלקית של הביצועים הכוללים של השאילתה.
ההרשאות הנדרשות
כדי להשתמש בתרשים של ביצוע השאילתות, צריכות להיות לכם ההרשאות הבאות:
bigquery.jobs.getbigquery.jobs.listAll
ההרשאות האלה זמינות דרך התפקידים המוגדרים מראש הבאים של ניהול הזהויות והרשאות הגישה (IAM) ב-BigQuery:
roles/bigquery.adminroles/bigquery.resourceAdminroles/bigquery.resourceEditorroles/bigquery.resourceViewer
מבנה של תרשים ביצוע
בתרשים של ביצוע השאילתה מוצג תצוגה גרפית של תוכנית השאילתה במסוף. כל תיבה מייצגת שלב בתוכנית השאילתה, כמו השלבים הבאים:
- קלט: קריאת נתונים מטבלה או בחירה של עמודות ספציפיות
- צירוף: מיזוג נתונים משתי טבלאות על סמך התנאי
JOIN - סיכום: ביצוע חישובים כמו
SUM - מיון: סידור התוצאות
שלבים מורכבים מפעולות שמתארות את הפעולות הנפרדות שכל עובד מבצע בשלב מסוים. אפשר ללחוץ על שלב כדי לפתוח אותו ולראות את השלבים שלו. השלבים כוללים גם מידע על התזמון היחסי והמוחלט.
שמות השלבים מסכמים את הפעולות שהמשתמשים מבצעים. לדוגמה, שלב עם join בשם שלו מציין שהפעולה העיקרית בשלב היא JOIN. אם שם השלב מסתיים ב-+, המשמעות היא שהשלב כולל פעולות חשובות נוספות. לדוגמה, שלב עם JOIN+ בשם שלו מציין שהשלב מבצע פעולת איחוד ושלבים חשובים אחרים.
הקווים שמחברים בין השלבים מייצגים את חילופי הנתונים הביניים בין השלבים. BigQuery מאחסן את נתוני הביניים בזיכרון של פעולת ה-Shuffle בזמן שהשלבים מתבצעים. המספרים בקצוות מציינים את מספר השורות המשוער שהועברו בין השלבים. מכסת הזיכרון של פעולת ה-Shuffle קשורה למספר המשבצות שהוקצו לחשבון. אם חורגים ממכסת ה-shuffle, הזיכרון של ה-shuffle יכול לעבור לדיסק ולגרום להאטה משמעותית בביצועי השאילתה.
הצגת תובנות לגבי הביצועים של שאילתות
המסוף
כדי לראות תובנות לגבי ביצועי השאילתות:
פותחים את הדף BigQuery במסוף Cloud de Confiance .
בחלונית הימנית, לוחצים על כלי הניתוחים:

אם החלונית הימנית לא מוצגת, לוחצים על הרחבת החלונית הימנית כדי לפתוח אותה.
בחלונית Explorer, לוחצים על Job history.
לוחצים על היסטוריה אישית או על היסטוריית הפרויקט.
ברשימת המשרות, מזהים את משרת השאילתה שמעניינת אתכם. לוחצים על פעולות ובוחרים באפשרות הצגת המשרה בכלי העריכה.
לוחצים על הכרטיסייה Execution graph כדי לראות ייצוג גרפי של כל שלב בשאילתה:
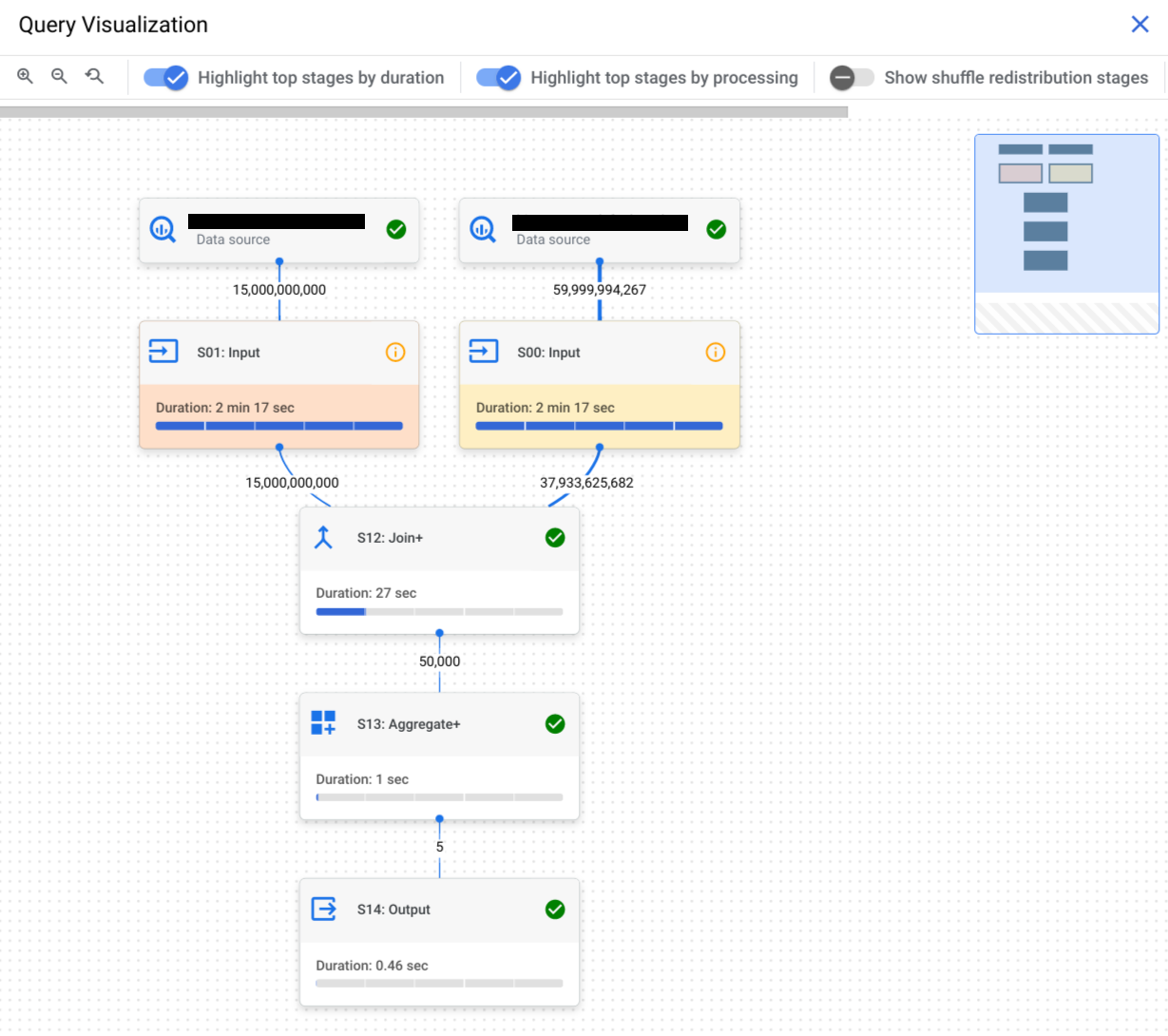
כדי לדעת אם יש תובנות לגבי הביצועים בשלב של שאילתה, צריך להסתכל על הסמל שמוצג. בשלבים שמופיע בהם סמל המידע יש תובנות לגבי הביצועים. בשלבים שמופיע בהם סמל וי לא צריך לעשות כלום.
לוחצים על שלב כדי לפתוח את חלונית הפרטים של השלב, שבה אפשר לראות את המידע הבא:
- מידע על תוכנית השאילתה עבור השלב.
- השלבים שבוצעו בשלב.
- כל התובנות הרלוונטיות לגבי הביצועים.

אופציונלי: אם בודקים שאילתה שפועלת, לוחצים על סנכרון כדי לעדכן את תרשים הביצוע כך שישקף את הסטטוס הנוכחי של השאילתה.

אופציונלי: כדי להדגיש בתרשים את השלבים המובילים לפי משך השלב, לוחצים על הדגשת השלבים המובילים לפי משך הזמן.

אופציונלי: כדי להדגיש את השלבים העיקריים לפי זמן השימוש במשבצת בגרף, לוחצים על הדגשת השלבים העיקריים לפי עיבוד.

אופציונלי: כדי לכלול את שלבי החלוקה מחדש של הנתונים בגרף, לוחצים על הצגת שלבי החלוקה מחדש של הנתונים.

אפשר להשתמש באפשרות הזו כדי להציג את שלבי החלוקה מחדש והמיזוג שמוסתרים בתרשים הביצוע שמוגדר כברירת מחדל.
שלבי החלוקה מחדש והמיזוג מוצגים בזמן שהשאילתה פועלת, והם משמשים לשיפור חלוקת הנתונים בין העובדים שמבצעים את השאילתה. מכיוון שהשלבים האלה לא קשורים לטקסט של השאילתה, הם מוסתרים כדי לפשט את תוכנית השאילתה שמוצגת.
לכל שאילתה שבה יש בעיות של רגרסיה בביצועים, תובנות לגבי הביצועים מוצגות גם בכרטיסייה Job Information של השאילתה:

SQL
במסוף Cloud de Confiance , עוברים לדף BigQuery.
מזינים את ההצהרה הבאה בעורך השאילתות:
SELECT `bigquery-public-data`.persistent_udfs.job_url( project_id || ':us.' || job_id) AS job_url, query_info.performance_insights FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS_BY_PROJECT WHERE DATE(creation_time) >= CURRENT_DATE - 30 -- scan 30 days of query history AND job_type = 'QUERY' AND state = 'DONE' AND error_result IS NULL AND statement_type != 'SCRIPT' AND EXISTS ( -- Only include queries which had performance insights SELECT 1 FROM UNNEST( query_info.performance_insights.stage_performance_standalone_insights ) WHERE slot_contention OR insufficient_shuffle_quota OR bi_engine_reasons IS NOT NULL OR high_cardinality_joins IS NOT NULL OR partition_skew IS NOT NULL UNION ALL SELECT 1 FROM UNNEST( query_info.performance_insights.stage_performance_change_insights ) WHERE input_data_change.records_read_diff_percentage IS NOT NULL );
לוחצים על הפעלה.
מידע נוסף על הרצת שאילתות זמין במאמר הרצת שאילתה אינטראקטיבית.
API
כדי לקבל תובנות לגבי ביצועי השאילתות בפורמט לא גרפי, אפשר לקרוא לשיטת ה-API jobs.list ולבדוק את המידע שמוחזר JobStatistics2.
הסבר על התובנות לגבי ביצועי השאילתות
בקטע הזה מוסבר מה המשמעות של תובנות לגבי הביצועים ואיך לטפל בהן.
התובנות לגבי הביצועים מיועדות לשני סוגי קהלים:
מנתחי נתונים: אתם מריצים שאילתות בפרויקט. אתם רוצים לדעת למה שאילתה שהפעלתם בעבר פועלת לאט יותר מהצפוי, ולקבל טיפים לשיפור הביצועים של שאילתה. יש לכם את ההרשאות שמתוארות בקטע הרשאות נדרשות.
אדמינים של אגמי נתונים או מחסני נתונים: אתם מנהלים את המשאבים וההזמנות של BigQuery בארגון. יש לכם את ההרשאות שמשויכות לתפקיד אדמין ב-BigQuery.
בכל אחד מהקטעים הבאים מפורטות הנחיות לגבי הפעולות שאפשר לבצע כדי לטפל בתובנות לגבי הביצועים שקיבלתם, בהתאם לתפקיד שלכם.
תחרות על יחידות קיבולת
כשמריצים שאילתה, מערכת BigQuery מנסה לפצל את העבודה שנדרשת בשאילתה למשימות. משימה היא פרוסת נתונים יחידה שמוזנת לשלב ומופקת ממנו. משבצת אחת קולטת משימה ומבצעת את פרוסת הנתונים הזו בשלב. באופן אידיאלי, משבצות של BigQuery מבצעות את המשימות האלה במקביל כדי להשיג ביצועים גבוהים. התחרות על משבצות מתרחשת כשיש לשאילתה שלכם הרבה משימות שמוכנות להתחלה, אבל ל-BigQuery אין מספיק משבצות פנויות כדי להריץ אותן.
מה עושים אם אתם אנליסטים
כדי לצמצם את הנתונים שמעובדים בשאילתה, אפשר לפעול לפי ההנחיות במאמר צמצום הנתונים שמעובדים בשאילתות.
מה עושים אם יש לכם הרשאת אדמין
כדי להגדיל את הזמינות של משבצות הזמן או להקטין את השימוש בהן, אפשר לבצע את הפעולות הבאות:
- אם אתם משתמשים בתמחור לפי דרישה של BigQuery, השאילתות שלכם משתמשות במאגר משותף של משבצות. מומלץ לעבור לתמחור ניתוח נתונים על בסיס קיבולת על ידי רכישת הזמנות. הזמנות מאפשרות לכם לשריין משבצות זמן ייעודיות לשאילתות של הארגון.
אם אתם משתמשים בהזמנות ב-BigQuery, ודאו שיש מספיק משבצות בהזמנה שהוקצתה לפרויקט שבו הופעלה השאילתה. יכול להיות שלא יהיו מספיק משבצות בהזמנה בתרחישים הבאים:
- יש משרות אחרות שצורכות משבצות בהזמנה. אפשר להשתמש בתרשימי משאבים לאדמינים כדי לראות איך הארגון משתמש בהזמנה.
- בהזמנה אין מספיק משבצות שהוקצו כדי להריץ שאילתות במהירות מספקת. אתם יכולים להשתמש בכלי להערכת משבצות זמן כדי לקבל הערכה לגבי גודל ההזמנות שצריך לבצע כדי לעבד את המשימות של השאילתות בצורה יעילה.
כדי לפתור את הבעיה, אפשר לנסות אחד מהפתרונות הבאים:
- להוסיף עוד משבצות (משבצות בסיסיות או משבצות מקסימליות להזמנה) להזמנה.
- יוצרים הזמנה נוספת ומקצים אותה לפרויקט שבו מופעלת השאילתה.
- כדאי לפצל שאילתות שדורשות הרבה משאבים, או לאורך זמן במסגרת הזמנה או בין הזמנות שונות.
מוודאים שהטבלאות שאתם שולחים להן שאילתות הן טבלאות מקובצות. האשכולות עוזרים להבטיח ש-BigQuery יוכל לקרוא במהירות עמודות עם נתונים שקשורים זה לזה.
מוודאים שהטבלאות שאתם שולחים להן שאילתות מחולקות למחיצות. בטבלאות שלא חולקו למחיצות, BigQuery קורא את כל הטבלה. חלוקת הטבלאות למחיצות עוזרת לוודא שאתם מבצעים שאילתות רק על קבוצת המשנה של הטבלאות שמעניינת אתכם.
מכסת הערבוב לא מספיקה
לפני שמריצים את השאילתה, BigQuery מפרק את הלוגיקה של השאילתה לשלבים. משבצות BigQuery מבצעות את המשימות בכל שלב. כשמשבצת זמן מסיימת את ההרצה של משימות בשלב מסוים, היא מאחסנת את התוצאות הזמניות בערבוב. בשלבים הבאים של השאילתה, הנתונים נקראים מהערבוב כדי להמשיך את הביצוע של השאילתה. חריגה ממכסת ה-Shuffle מתרחשת כשיש יותר נתונים שצריך לכתוב ל-Shuffle מאשר קיבולת ה-Shuffle.
מה עושים אם אתם אנליסטים
בדומה למצב של תחרות על משבצות, צמצום כמות הנתונים שהשאילתה מעבדת עשוי להפחית את השימוש בערבול. כדי לעשות את זה, פועלים לפי ההנחיות במאמר הפחתת כמות הנתונים שמעובדים בשאילתות.
פעולות מסוימות ב-SQL נוטות להשתמש בערבוב באופן נרחב יותר, במיוחד פעולות JOIN וסעיפים של GROUP BY.
במקרים שבהם אפשר, צמצום כמות הנתונים בפעולות האלה עשוי להפחית את השימוש בערבוב.
מה עושים אם יש לכם הרשאת אדמין
כדי לצמצם את התחרות על מכסת הערבוב, אפשר לבצע את הפעולות הבאות:
- בדומה למצב של תחרות על משבצות, אם אתם משתמשים בתמחור על פי דרישה של BigQuery, השאילתות שלכם משתמשות במאגר משותף של משבצות. מומלץ לעבור לתמחור ניתוח נתונים על בסיס קיבולת על ידי רכישת הזמנות. הזמנות מאפשרות לכם להקצות משבצות ייעודיות ולשנות את הקיבולת של השאילתות בפרויקטים.
אם אתם משתמשים בהזמנות של BigQuery, יחידות הקיבולת (Slot) מגיעות עם קיבולת ייעודית לערבוב נתונים. אם בהזמנה שלכם מופעלות כמה שאילתות שמשתמשות באופן נרחב בערבוב, יכול להיות ששאילתות אחרות שמופעלות במקביל לא יקבלו מספיק קיבולת ערבוב. כדי לזהות אילו משימות משתמשות בקיבולת של shuffle באופן נרחב, אפשר להריץ שאילתה בעמודה
period_shuffle_ram_usage_ratioבתצוגהINFORMATION_SCHEMA.JOBS_TIMELINE.כדי לפתור את הבעיה, אפשר לנסות אחד או יותר מהפתרונות הבאים:
- להוסיף עוד משבצות להזמנה.
- יוצרים הזמנה נוספת ומקצים אותה לפרויקט שבו מופעלת השאילתה.
- כדאי לפצל שאילתות שדורשות הרבה פעולות ערבוב, או לאורך זמן במסגרת הזמנה או בין הזמנות שונות.
מידע נוסף על פתרון בעיות זמין במאמר שגיאות שקשורות למגבלת הגודל של פעולת ה-Shuffle בדף פתרון הבעיות של BigQuery.
שינוי בקנה המידה של קלט הנתונים
אם התובנה הזו לגבי הביצועים מופיעה, סימן שהשאילתה קוראת לפחות 50% יותר נתונים מטבלת קלט נתונה בהשוואה להרצה האחרונה של השאילתה. אפשר להשתמש בהיסטוריית השינויים בטבלה כדי לראות אם הגודל של אחת מהטבלאות שמשמשות בשאילתה גדל לאחרונה.
מה עושים אם אתם אנליסטים
כדי לצמצם את הנתונים שמעובדים בשאילתה, אפשר לפעול לפי ההנחיות במאמר צמצום הנתונים שמעובדים בשאילתות.
שאילתת איחוד בעוצמה גבוהה
כששאילתה מכילה פעולת איחוד עם מפתחות לא ייחודיים בשני הצדדים של האיחוד, גודל טבלת הפלט יכול להיות גדול משמעותית מגודל כל אחת מטבלאות הקלט. התובנה הזו מצביעה על כך שיש יחס גבוה בין מספר השורות של הפלט לבין מספר השורות של הקלט, ומספקת מידע על מספרי השורות האלה.
מה עושים אם אתם אנליסטים
בודקים את תנאי הצירוף כדי לוודא שהגידול בגודל של טבלת הפלט צפוי. לא מומלץ להשתמש ב-cross joins.
אם אתם חייבים להשתמש בשאילתת איחוד (cross join), נסו להשתמש בפסוקית GROUP BY כדי לצבור מראש את התוצאות, או להשתמש בפונקציה אנליטית (window function). מידע נוסף מפורט במאמר בנושא צמצום הנתונים לפני השימוש ב-JOIN.
החלוקה למחיצות לא מאוזנת
כדי לשלוח משוב או לבקש תמיכה בנוגע לתכונה הזו, אפשר לשלוח אימייל אל
bq-query-inspector-feedback@google.com.
הטיה בהתפלגות הנתונים עלולה לגרום להרצת שאילתות איטית. כשמריצים שאילתה, BigQuery מפצל את הנתונים למחיצות קטנות לעיבוד מקביל. הטיה מתרחשת כשהנתונים לא מחולקים באופן שווה בין המחיצות האלה, לרוב בגלל ערכים שמופיעים לעיתים קרובות במפתחות של הצטרפות או קיבוץ, וכתוצאה מכך חלק מהמחיצות גדולות משמעותית מאחרות. מכיוון שמשבצת זמן אחת מעבדת מחיצה שלמה ולא יכולה לחלוק את העבודה, מחיצה גדולה מדי עלולה להאט את העיבוד, לגרום לשגיאות של חריגה ממכסת המשאבים ובמקרים קיצוניים לגרום לקריסת משבצת הזמן.
במהלך הפעלת פעולת JOIN, מערכת BigQuery מחלקת את הנתונים בצד ימין ובצד שמאל של האיחוד למחיצות, על סמך מפתחות האיחוד. אם מחיצה גדולה מדי, מערכת BigQuery מנסה לאזן מחדש את הנתונים. אם ההטיה חמורה מדי ואי אפשר לאזן אותה באופן מלא, תובנה לגבי הטיית מחיצה מתווספת לשלב JOIN בתרשים הביצוע.
זיהוי הטיה של מחיצות
משתמשים בכרטיסייה Execution graph ב-BigQuery Studio כדי לגלות באיזה שלב של השאילתה יש הטיה בחלוקה למחיצות. התובנה מסומנת בשלב. מפרטי השלב אפשר לזהות את החלק הרלוונטי של טקסט השאילתה ואת הטבלאות שעוברות עיבוד. מידע נוסף זמין במאמר הסבר על השלבים באמצעות טקסט של שאילתה.
דוגמה
השאילתה הבאה מצטרפת למידע על מאגר עם מידע על קובץ. הטיה יכולה להתרחש אם בחלק מהמאגרים יש הרבה יותר קבצים מאשר באחרים.
SELECT r.repo_name, COUNT(f.path) AS file_count
FROM `bigquery-public-data.github_repos.sample_repos` AS r
JOIN `bigquery-public-data.github_repos.sample_files` AS f
ON r.repo_name = f.repo_name
WHERE r.watch_count > 10
GROUP BY r.repo_name
מַפְתח האיחוד (join) הוא repo_name. בטבלה sample_repos, הערך repo_name אמור להיות ייחודי. עם זאת, בsample_files הטבלה, repo_name יכול להופיע הרבה פעמים. אם כמה ערכים של repo_name מופיעים בתדירות גבוהה באופן לא פרופורציונלי ב-sample_files, נוצרת הטיה בנתונים.
כדי לוודא אם קיימת חלוקת נתונים לא מאוזנת (partition skew), צריך לנתח את ההתפלגות של מפתח שאילתת האיחוד (join) בטבלה הגדולה יותר (sample_files במקרה הזה). מריצים את השאילתה הבאה כדי להעריך את ההתפלגות של repo_name:
SELECT repo_name, COUNT(*) AS occurrences
FROM `bigquery-public-data.github_repos.sample_files`
GROUP BY repo_name
ORDER BY occurrences DESC
בטבלאות גדולות מאוד, אפשר להשתמש בפונקציה APPROX_TOP_COUNT כדי להעריך ביעילות את הערכים הכי נפוצים.
SELECT APPROX_TOP_COUNT(repo_name, 100)
FROM `bigquery-public-data.github_repos.sample_files`
אם הספירות של הערכים המובילים גדולות בסדרי גודל מאלה של ערכים אחרים, יש חלוקת נתונים לא מאוזנת.
איך מצמצמים את ההטיה של המחיצה
אפשר להשתמש בשיטות הבאות כדי לטפל בהטיה של מחיצות:
- סינון הנתונים בשלב מוקדם. כדי לצמצם את כמות הנתונים שעוברים עיבוד, כדאי להחיל מסננים בשלב מוקדם ככל האפשר בשאילתה. כך אפשר להקטין את מספר השורות שמשויכות למפתחות מוטים לפני שהן מגיעות לפעולות כמו
JOINאוGROUP BY. פיצול השאילתה כדי לבודד מקשים מוטים. אם ההטיה נגרמת בגלל כמה ערכי מפתח ספציפיים, בדומה לשדה
repo_nameבדוגמה הקודמת, כדאי לפצל את השאילתה. מעבדים את הנתונים של המפתחות עם ההטיה בנפרד משאר הנתונים, ואז משלבים את התוצאות באמצעותUNION ALL.דוגמה: בידוד של מקש שנמצא בשימוש לעיתים קרובות.
-- Query for the skewed key SELECT r.repo_name, COUNT(f.path) AS file_count FROM `bigquery-public-data.github_repos.sample_repos` AS r JOIN `bigquery-public-data.github_repos.sample_files` AS f ON r.repo_name = f.repo_name WHERE r.watch_count > 10 AND r.repo_name = 'popular_repo' GROUP BY r.repo_name UNION ALL -- Query for all other keys SELECT r.repo_name, COUNT(f.path) AS file_count FROM `bigquery-public-data.github_repos.sample_repos` AS r JOIN `bigquery-public-data.github_repos.sample_files` AS f ON r.repo_name = f.repo_name WHERE r.watch_count > 10 AND r.repo_name != 'popular_repo' GROUP BY r.repo_nameטיפול בערכי
NULLובערכי ברירת מחדל: סיבה נפוצה להטיה היא מספר גדול של שורות עם ערכים שלNULLאו מחרוזת ריקה בעמודות מפתח. אם אתם לא צריכים את השורות האלה לניתוח, אתם יכולים לסנן אותן באמצעות פסוקיתWHEREלפניJOINאוGROUP BY.פעולות של שינוי סדר: בשאילתות עם כמה הצטרפויות, הסדר יכול להיות חשוב. אם אפשר, כדאי לבצע הצטרפויות שמצמצמות באופן משמעותי את מספר השורות בשלב מוקדם יותר בשאילתה.
שימוש בפונקציות משוערות: כשמבצעים צבירה של נתונים מוטים, כדאי לשקול אם תוצאה משוערת מקובלת. פונקציות כמו
APPROX_COUNT_DISTINCTסובלניות יותר לחלוקת נתונים לא מאוזנת מאשר פונקציות מדויקות כמוCOUNT(DISTINCT).
הסבר על מידע לגבי שלב בשאילתה
בנוסף לשימוש בתובנות לגבי ביצועים של שאילתות, אפשר גם להשתמש בהנחיות הבאות כשבודקים את הפרטים של שלב בשאילתה, כדי להבין אם יש בעיה בשאילתה:
- אם הערך של Wait ms בשלב אחד או יותר גבוה בהשוואה להרצות קודמות של השאילתה:
- בודקים אם יש לכם מספיק משבצות זמן פנויות כדי להכיל את עומס העבודה. אם לא, כדאי לבצע איזון עומסים כשמריצים שאילתות שדורשות הרבה משאבים, כדי שהן לא יתחרו זו בזו.
- אם הערך של Wait ms גבוה יותר רק בשלב אחד, כדאי לבדוק את השלב הקודם כדי לראות אם נוצר בו צוואר בקבוק. דברים כמו שינויים משמעותיים בנתונים או בסכימה של הטבלאות שמשתתפות בשאילתה עשויים להשפיע על ביצועי השאילתה.
- אם הערך של Shuffle output bytes בשלב מסוים גבוה בהשוואה להרצות קודמות של השאילתה, או בהשוואה לשלב קודם, כדאי לבדוק את השלבים שבוצעו בשלב הזה כדי לראות אם אחד מהם יוצר כמויות גדולות של נתונים באופן לא צפוי. אחת הסיבות הנפוצות לכך היא כששלב מעבד
INNER JOINשבו יש מפתחות כפולים בשני הצדדים של הצירוף. הפעולה הזו עלולה להחזיר כמות גדולה באופן לא צפוי של נתונים. - אפשר להשתמש בתרשים הביצוע כדי לראות את השלבים העיקריים לפי משך ועיבוד. כדאי לבדוק את כמות הנתונים שהם מייצרים ואם היא תואמת לגודל הטבלאות שאליהן מתייחסת השאילתה. אם לא, כדאי לעיין בשלבים האלה כדי לראות אם אחד מהם עלול להפיק כמות בלתי צפויה של נתוני ביניים.
המאמרים הבאים
- כדאי לעיין בהנחיות לאופטימיזציה של שאילתות כדי לקבל טיפים לשיפור ביצועי השאילתות.