
סקירה כללית על אחסון ב-BigQuery
בדף הזה מוסבר על רכיב האחסון של BigQuery.
האחסון ב-BigQuery מותאם להרצת שאילתות אנליטיות על מערכי נתונים גדולים. הוא תומך גם בהטמעת עדכונים בזמן אמת עם תפוקה גבוהה ובקריאות עם תפוקה גבוהה. הבנת האחסון ב-BigQuery יכולה לעזור לכם לבצע אופטימיזציה של עומסי העבודה.
סקירה כללית
אחת התכונות המרכזיות בארכיטקטורה של BigQuery היא ההפרדה בין אחסון לבין מחשוב. כך BigQuery יכול להרחיב את האחסון ואת המחשוב בנפרד, בהתאם לביקוש.

כשמריצים שאילתה, מנוע השאילתות מחלק את העבודה במקביל בין כמה עובדים, שסורקים את הטבלאות הרלוונטיות באחסון, מעבדים את השאילתה ואז אוספים את התוצאות. מערכת BigQuery מריצה שאילתות באופן מלא בזיכרון, באמצעות רשת פטה-ביט כדי להבטיח שהנתונים יועברו במהירות רבה לצמתי העובדים.
אלה כמה מהתכונות העיקריות של אחסון ב-BigQuery:
מנוהל. אחסון ב-BigQuery הוא שירות מנוהל לחלוטין. אין צורך להקצות משאבי אחסון או לשריין יחידות אחסון. מערכת BigQuery מקצה לכם באופן אוטומטי נפח אחסון כשאתם טוענים נתונים למערכת. משלמים רק על נפח האחסון שבו משתמשים. במודל התמחור של BigQuery, החיוב על מחשוב ואחסון מתבצע בנפרד. פרטים על התמחור זמינים במאמר תמחור ב-BigQuery.
Durable. האחסון ב-BigQuery מתוכנן לספק עמידות שנתית של 99.999999999% (11 ספרות 9). BigQuery משכפל את הנתונים שלכם בכמה אזורי זמינות כדי להגן עליהם מפני אובדן נתונים כתוצאה מכשלים ברמת המכונה או מכשלים אזוריים. מידע נוסף זמין במאמר מהימנות: תכנון התאוששות מאסון.
מוצפן. ב-BigQuery כל הנתונים מוצפנים באופן אוטומטי לפני שהם נכתבים בדיסק. אתם יכולים לספק מפתח הצפנה משלכם או לאפשר ל-Google לנהל את מפתח ההצפנה. מידע נוסף זמין במאמר בנושא הצפנה במנוחה.
יעיל. האחסון ב-BigQuery משתמש בפורמט קידוד יעיל שעבר אופטימיזציה לעומסי עבודה אנליטיים.
נתונים מהטבלה
רוב הנתונים שאתם מאחסנים ב-BigQuery הם נתונים של טבלאות. נתוני הטבלה כוללים טבלאות רגילות, שיבוטים של טבלאות, תמונות מצב של טבלאות ותצוגות חומריות. אתם מחויבים על האחסון שבו אתם משתמשים עבור המשאבים האלה. מידע נוסף זמין במאמר בנושא תמחור של אחסון.
טבלאות רגילות מכילות נתונים מובְנים. לכל טבלה יש סכימה, ולכל עמודה בסכימה יש סוג נתונים. BigQuery מאחסן נתונים בפורמט עמודתי. במאמר הזה מוסבר על פריסת האחסון.
שיבוטים של טבלאות הם עותקים קלים וניתנים לכתיבה של טבלאות רגילות. ב-BigQuery מאוחסן רק הדלתא בין שיבוט של טבלה לבין טבלת הבסיס שלה.
תמונות מצב של טבלאות הן עותקים של טבלאות שנוצרו בנקודת זמן מסוימת. תמונות מצב של טבלאות הן לקריאה בלבד, אבל אפשר לשחזר טבלה מתמונת מצב של טבלה. ב-BigQuery מאוחסן רק הדלתא בין תמונת מצב של טבלה לבין טבלת הבסיס שלה.
תצוגות מהותיות הן תצוגות שמחושבות מראש ושומרות במטמון את התוצאות של שאילתת התצוגה באופן תקופתי. התוצאות שנשמרו במטמון מאוחסנות ב-BigQuery.
בנוסף, תוצאות של שאילתות שנשמרו במטמון נשמרות כטבלאות זמניות. לא נחייב אתכם על תוצאות של שאילתות במטמון שנשמרות בטבלאות זמניות.
טבלאות חיצוניות הן סוג מיוחד של טבלאות שבהן הנתונים נמצאים במאגר נתונים חיצוני ל-BigQuery, כמו Cloud Storage. לטבלה חיצונית יש סכימת טבלה, בדיוק כמו לטבלה רגילה, אבל הגדרת הטבלה מצביעה על מאגר הנתונים החיצוני. במקרה כזה, רק המטא-נתונים של הטבלה נשמרים באחסון של BigQuery. ב-BigQuery לא מחייבים על אחסון טבלאות חיצוניות, אבל יכול להיות שמאגר הנתונים החיצוני יחייב על אחסון.
ב-BigQuery, הטבלאות ומשאבים אחרים מאורגנים במאגרי נתונים לוגיים שנקראים מערכי נתונים. האופן שבו מקבצים את המשאבים ב-BigQuery משפיע על ההרשאות, המכסות, החיוב והיבטים אחרים של עומסי העבודה (workloads) ב-BigQuery. מידע נוסף ושיטות מומלצות זמינים במאמר ארגון משאבים ב-BigQuery.
מדיניות שמירת הנתונים שמשמשת לטבלה נקבעת לפי ההגדרה של מערך הנתונים שמכיל את הטבלה. מידע נוסף זמין במאמר שמירת נתונים עם תכונות של Time Travel ו-Fail-safe.
מטא-נתונים
בנוסף, באחסון ב-BigQuery נשמרים מטא-נתונים על משאבי BigQuery. אנחנו לא גובים תשלום על אחסון מטא-נתונים.
כשיוצרים ישות קבועה ב-BigQuery, כמו טבלה, תצוגה או פונקציה מוגדרת על ידי המשתמש (UDF), BigQuery מאחסן מטא-נתונים לגבי הישות. זה נכון גם לגבי משאבים שלא מכילים נתוני טבלה, כמו פונקציות מוגדרות על ידי המשתמש ותצוגות לוגיות.
המטא-נתונים כוללים מידע כמו סכימת הטבלה, מפרטים של חלוקה למחיצות ושל אשכולות, זמני התפוגה של הטבלה ומידע נוסף. סוג המטא-נתונים הזה גלוי למשתמש, ואפשר להגדיר אותו כשיוצרים את המשאב. בנוסף, BigQuery מאחסן מטא-נתונים שמשמשים אותו באופן פנימי לאופטימיזציה של שאילתות. המשתמשים לא יכולים לראות את המטא-נתונים האלה באופן ישיר.
פריסת האחסון
במערכות מסורתיות רבות של מסדי נתונים, הנתונים מאוחסנים בפורמט של שורות, כלומר השורות מאוחסנות יחד, והשדות בכל שורה מופיעים ברצף בדיסק. במסדי נתונים מבוססי-שורות, יעיל לחפש רשומות ספציפיות. עם זאת, יכול להיות שהן פחות יעילות בביצוע פונקציות אנליטיות על פני רשומות רבות, כי המערכת צריכה לקרוא כל שדה כשניגשים לרשומה.
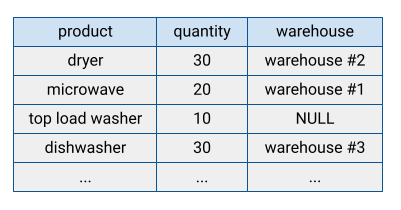
נתוני הטבלה ב-BigQuery מאוחסנים בפורמט עמודות, כלומר כל עמודה מאוחסנת בנפרד. מסדי נתונים מבוססי-עמודות יעילים במיוחד בסריקה של עמודות נפרדות על פני מערך נתונים שלם.
מסדי נתונים מבוססי-עמודות מותאמים לעומסי עבודה אנליטיים שמצטברים נתונים על מספר גדול מאוד של רשומות. לרוב, שאילתה אנליטית צריכה לקרוא רק כמה עמודות מטבלה. לדוגמה, אם רוצים לחשב את הסכום של עמודה מסוימת מתוך מיליוני שורות, BigQuery יכול לקרוא את הנתונים של העמודה הזו בלי לקרוא כל שדה בכל שורה.
יתרון נוסף של מסדי נתונים מבוססי-עמודות הוא שבדרך כלל יש יותר נתונים עודפים בעמודה מאשר בשורה. המאפיין הזה מאפשר דחיסה טובה יותר של הנתונים באמצעות טכניקות כמו קידוד אורך רצף (RLE), שיכול לשפר את ביצועי הקריאה.
מודלים לחיוב על אחסון
החיוב על אחסון נתונים ב-BigQuery יכול להתבצע לפי בייטים לוגיים או פיזיים (דחוסים), או לפי שילוב של שניהם. מודל החיוב על האחסון שבוחרים קובע את תמחור האחסון. מודל החיוב של נפח האחסון שתבחרו לא משפיע על הביצועים של BigQuery. לא משנה באיזה מודל חיוב תבחרו, הנתונים שלכם מאוחסנים כבייטים פיזיים.
מודל החיוב על אחסון מוגדר ברמת מערך הנתונים. אם לא מציינים מודל חיוב לאחסון כשיוצרים מערך נתונים, ברירת המחדל היא חיוב על אחסון לוגי. עם זאת, אפשר לשנות את מודל החיוב של האחסון של מערך נתונים אחרי שיוצרים אותו. אם משנים את מודל החיוב של האחסון של מערך נתונים, צריך לחכות 14 ימים לפני שאפשר לשנות שוב את מודל החיוב של האחסון.
כשמשנים את מודל החיוב של מערך נתונים, חולפות 24 שעות עד שהשינוי נכנס לתוקף. אם משנים את מודל החיוב של מערך נתונים, טבלאות או מחיצות של טבלאות באחסון לטווח ארוך לא מאופסות לאחסון פעיל. שינוי מודל החיוב של מערך נתונים לא משפיע על ביצועי השאילתות ועל זמן האחזור של השאילתות.
במערכי נתונים נעשה שימוש במסע בזמן ובאחסון בטוח לשמירת נתונים. כשמשתמשים בחיוב על נפח אחסון פיזי, יש חיוב נפרד על תכונות כמו Time travel (חזרה בזמן) ואחסון בטוח, לפי תעריפי האחסון הפעיל. אבל כשמשתמשים בחיוב על נפח אחסון לוגי, התכונות האלה כלולות בתעריף הבסיסי. אתם יכולים לשנות את חלון הזמן של Time Travel שבו אתם משתמשים במערך נתונים כדי לאזן בין עלויות האחסון הפיזי לבין שמירת הנתונים. אי אפשר לשנות את חלון ההגנה מפני כשל. מידע נוסף על שמירת נתונים במערכי נתונים זמין במאמר שמירת נתונים באמצעות Time Travel ו-Fail-safe. למידע נוסף על תחזית עלויות האחסון, אפשר לעיין במאמר בנושא תחזית החיובים על אחסון.
אופטימיזציה של האחסון
אופטימיזציה של האחסון ב-BigQuery משפרת את ביצועי השאילתות ומאפשרת שליטה בעלויות. כדי לראות את המטא-נתונים של אחסון הטבלה, שולחים שאילתה לתצוגות הבאות של INFORMATION_SCHEMA:
מידע על אופטימיזציה של אחסון זמין במאמר אופטימיזציה של אחסון ב-BigQuery.
טעינת נתונים
יש כמה דפוסים בסיסיים להעברת נתונים ל-BigQuery.
טעינת אצווה: טעינת נתוני המקור לטבלה ב-BigQuery בפעולת אצווה אחת. אפשר לבצע את הפעולה הזו פעם אחת או להגדיר אותה כך שתתבצע באופן אוטומטי לפי לוח זמנים. פעולת טעינה באצווה יכולה ליצור טבלה חדשה או לצרף נתונים לטבלה קיימת.
סטרימינג: הזרמה מתמשכת של קבוצות קטנות יותר של נתונים, כך שהנתונים זמינים להרצת שאילתות כמעט בזמן אמת.
נתונים שנוצרו: אפשר להשתמש בהצהרות SQL כדי להוסיף שורות לטבלה קיימת או לכתוב את תוצאות השאילתה בטבלה.
מידע נוסף על המקרים שבהם כדאי לבחור בכל אחת משיטות ההטמעה האלה זמין במאמר מבוא לטעינת נתונים. למידע על מחירים אפשר לעיין במאמר בנושא תמחור של הטמעת נתונים.
קריאת נתונים מאחסון BigQuery
ברוב המקרים, מאחסנים נתונים ב-BigQuery כדי להריץ עליהם שאילתות אנליטיות. עם זאת, לפעמים כדאי לקרוא רשומות ישירות מטבלה. יש כמה דרכים לקרוא נתונים מטבלה ב-BigQuery:
BigQuery API: גישה מסונכרנת עם חלוקה לדפים באמצעות השיטה
tabledata.list. הנתונים נקראים באופן סדרתי, דף אחד בכל הפעלה. מידע נוסף זמין במאמר בנושא עיון בנתונים בטבלה.BigQuery Storage API: גישה להזרמת נתונים עם תפוקה גבוהה, שתומכת גם בהקרנה ובסינון של עמודות בצד השרת. אפשר להקביל קריאות בין הרבה קוראים על ידי חלוקה שלהן לכמה זרמים נפרדים.
Export: העתקה אסינכרונית של נתונים בנפח גבוה אל Google Cloud Storage, באמצעות משימות חילוץ או הצהרת
EXPORT DATA. אם אתם צריכים להעתיק נתונים ב-Cloud Storage, אתם יכולים לייצא את הנתונים באמצעות משימת חילוץ או באמצעות הצהרתEXPORT DATA.העתקה: העתקה אסינכרונית של מערכי נתונים ב-BigQuery. ההעתקה מתבצעת באופן לוגי כשהמיקום של המקור והיעד זהה.
למידע על מחירים אפשר לעיין בתמחור של חילוץ נתונים.
בהתאם לדרישות של האפליקציה, אפשר לקרוא את נתוני הטבלה:
- קריאה והעתקה: אם אתם צריכים עותק במצב מנוחה ב-Cloud Storage, אתם יכולים לייצא את הנתונים באמצעות משימת חילוץ או באמצעות הצהרת
EXPORT DATA. אם רוצים רק לקרוא את הנתונים, צריך להשתמש ב-BigQuery Storage API. אם רוצים ליצור עותק ב-BigQuery, משתמשים במשימת העתקה. - מדרגיות: BigQuery API היא השיטה הכי פחות יעילה, ולא מומלץ להשתמש בה לקריאות של נפחים גדולים. אם אתם צריכים לייצא יותר מ-50 טרה-בייט של נתונים ביום, אתם יכולים להשתמש בהצהרת
EXPORT DATAאו ב-BigQuery Storage API. - הזמן שנדרש להחזרת השורה הראשונה: BigQuery API היא השיטה הכי מהירה להחזרת השורה הראשונה, אבל צריך להשתמש בה רק כדי לקרוא כמויות קטנות של נתונים. החזרת השורה הראשונה ב-BigQuery Storage API לוקחת יותר זמן, אבל קצב העברת הנתונים שלו גבוה בהרבה. הייצוא וההעתקה צריכים להסתיים לפני שאפשר לקרוא שורות כלשהן, ולכן הזמן עד לשורה הראשונה עבור סוגי העבודות האלה יכול להיות בסדר גודל של דקות.
מחיקה
כשמוחקים טבלה, הנתונים נשמרים למשך פרק הזמן של חלון הנסיעה בזמן לפחות.
חלק מפעולות המחיקה, כמו הצהרת DROP COLUMN,
הן פעולות שמתייחסות רק למטא-נתונים. במקרה כזה, נפח האחסון יתפנה בפעם הבאה שתשנו את השורות הרלוונטיות. אם לא משנים את הטבלה, אין זמן מובטח שבו נפח האחסון יתפנה.