
In dieser Anleitung werden die verschiedenen Ansätze beschrieben, mit denen Sie eine Microsoft SQL Server-Datenbank in Amazon Elastic Compute Cloud (AWS EC2) zu Compute Engine migrieren können.
Auf dieser Seite werden die folgenden Ansätze beschrieben:
- Mit vollständiger Sicherung und Wiederherstellung migrieren
- Mit einer BACPAC-Datei migrieren
- Mit Always On-Verfügbarkeitsgruppen migrieren
- Migrieren mit verteilten Verfügbarkeitsgruppen
Jede Migrationsmethode hat unterschiedliche Vor- und Nachteile. Die am besten geeignete Migrationsstrategie hängt von Ihren spezifischen Umständen und Prioritäten ab. Wir empfehlen Ihnen, eine Migrationsmethode auszuwählen, die für Sie am besten geeignet ist. Berücksichtigen Sie dabei Folgendes:
Verfügbarkeit:Prüfen Sie, ob ein Migrationsansatz von allen Versionen und Lizenzen Ihrer SQL Server-Datenbank unterstützt wird.
Datenbankgröße:Die Größe der Datenbank kann sich erheblich auf die möglichen Migrationsoptionen auswirken, da für größere Datenbanken möglicherweise andere Strategien erforderlich sind als für kleinere. Berücksichtigen Sie bei der Auswahl eines Migrationsansatzes die Dauer der Datenübertragung, potenzielle Ausfallzeiten und Ressourcenanforderungen.
Toleranz für Ausfallzeiten:Das akzeptable Maß an Ausfallzeiten während der Migration ist ein entscheidender Faktor. Einige Methoden ermöglichen minimale bis hin zu praktisch keinen Ausfallzeiten, während andere längere Ausfallzeiten erfordern. Wählen Sie einen Migrationsansatz, der für Sie akzeptable Ausfallzeiten bietet.
Komplexität:Die Komplexität des Datenbankschemas, der Anwendungsabhängigkeiten und der Gesamtumgebung kann den Migrationsansatz beeinflussen. Achten Sie darauf, dass die von Ihnen gewählte Migrationsmethode die Migration von Nicht-Datenbankobjekten wie SQL-Agent-Jobs, verknüpften Servern, Berechtigungen und Nutzerobjekten unterstützt.
Kosten:Auch die finanziellen Aspekte der Migration können eine Rolle spielen. Für die verschiedenen Migrationsmethoden fallen unterschiedliche Kosten für Datenübertragung, Rechenressourcen und andere Dienste an. Wählen Sie eine Migrationsmethode aus, die am besten zu Ihnen passt.
Datensicherheit und Compliance:Achten Sie darauf, dass die gewählte Migrationsmethode Ihren Anforderungen an Datensicherheit und Compliance entspricht. Berücksichtigen Sie Datenverschlüsselung, Zugriffssteuerung und alle branchenspezifischen Anforderungen, die für Ihre Daten gelten.
Ziele
In dieser Anleitung erfahren Sie, wie Sie die folgenden Aufgaben ausführen, um Ihre SQL Server-Datenbank von AWS EC2 zu Compute Engine zu migrieren:
- SQL Server-Instanz in Compute Engine bereitstellen
- Mit Vollsicherung und ‑wiederherstellung migrieren
- Migration mit einer BACPAC-Datei
- Migration mit Always On-Verfügbarkeitsgruppen
- Migrieren mit verteilten Verfügbarkeitsgruppen
Kosten
In dieser Anleitung werden kostenpflichtige Komponenten von Cloud de Confiance by S3NSverwendet, darunter:
Sie können mithilfe des Preisrechners eine Kostenschätzung für Ihre voraussichtliche Nutzung erstellen.
Hinweis
Führen Sie die folgenden Aufgaben aus, bevor Sie beginnen:
-
Wählen Sie in der Cloud de Confiance Console auf der Seite für die Projektauswahl ein Cloud de Confiance -Projekt aus oder erstellen Sie eines.
Rollen, die zum Auswählen oder Erstellen eines Projekts erforderlich sind
- Projekt auswählen: Für die Auswahl eines Projekts ist keine bestimmte IAM-Rolle erforderlich. Sie können jedes Projekt auswählen, für das Ihnen eine Rolle zugewiesen wurde.
-
Projekt erstellen: Zum Erstellen eines Projekts benötigen Sie die Rolle „Projektersteller“ (
roles/resourcemanager.projectCreator), die die Berechtigungresourcemanager.projects.createenthält. Weitere Informationen zum Zuweisen von Rollen
-
Prüfen Sie, ob die Abrechnung für Ihr Cloud de Confiance Projekt aktiviert ist.
-
Aktivieren Sie Cloud Shell in der Cloud de Confiance Console.
Projekt und Netzwerk vorbereiten
So bereiten Sie Ihr Cloud de Confiance -Projekt und Ihre Virtual Private Cloud (VPC) für die Bereitstellung von SQL Server für die Migration vor:
Klicken Sie in der Cloud de Confiance Console auf Cloud Shell aktivieren
 , um Cloud Shell zu öffnen.
, um Cloud Shell zu öffnen.Legen Sie Ihre standardmäßige Projekt-ID fest:
gcloud config set project
PROJECT_IDErsetzen Sie
PROJECT_IDdurch die ID Ihres Cloud de Confiance Projekts.Legen Sie Ihre Standardregion fest:
gcloud config set compute/region
REGIONErsetzen Sie
REGIONdurch die ID der Region, in der die Bereitstellung erfolgen soll.Legen Sie Ihre Standardzone fest:
gcloud config set compute/zone
ZONEErsetzen Sie
ZONEdurch die ID der Zone, in der die Bereitstellung erfolgen soll. Achten Sie darauf, dass die Zone in der Region, die Sie im vorherigen Schritt angegeben haben, gültig ist.
SQL Server-Instanz in Compute Engine erstellen
Bevor Sie Ihre SQL Server-Datenbank zu Compute Engine migrieren können, müssen Sie eine virtuelle Maschine (VM) in Compute Engine erstellen, auf der sie gehostet werden kann.
Verwenden Sie den folgenden Befehl, um eine SQL Server-Instanz in Compute Engine zu erstellen:
2022 Standard
gcloud compute instances create sql-server-std-migrate-vm \ --project=PROJECT_ID\ --zoneZONE\ --machine-type n4-standard-8 \ --subnetSUBNET_NAME\ --create-disk=auto-delete=yes,boot=yes,device-name=node-1,image=projects/windows-sql-cloud/global/images/sql-2022-standard-windows-2022-dc-v20250213,mode=rw,size=50,type=projects/PROJECT_ID/zones/ZONE/diskTypes/pd-balanced \ --scopes=https://www.googleapis.com/auth/compute,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly,https://www.googleapis.com/auth/logging.write,https://www.googleapis.com/auth/monitoring.write,https://www.googleapis.com/auth/trace.append,https://www.googleapis.com/auth/devstorage.read_write
Ersetzen Sie Folgendes:
PROJECT_ID:die ID Ihres Cloud de Confiance -Projekts.ZONE:die ID der Zone.SUBNET_NAMEmit dem Namen Ihres VPC-Subnetzes.
2022 Enterprise
gcloud compute instances create sql-server-ent-migrate-vm \ --project=PROJECT_ID\ --zoneZONE\ --machine-type n4-standard-8 \ --subnetSUBNET_NAME\ --create-disk=auto-delete=yes,boot=yes,device-name=node-1,image=projects/windows-sql-cloud/global/images/sql-2022-enterprise-windows-2022-dc-v20250213,mode=rw,size=50,type=projects/PROJECT_ID/zones/ZONE/diskTypes/pd-balanced \ --scopes=https://www.googleapis.com/auth/compute,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly,https://www.googleapis.com/auth/logging.write,https://www.googleapis.com/auth/monitoring.write,https://www.googleapis.com/auth/trace.append,https://www.googleapis.com/auth/devstorage.read_write
Ersetzen Sie Folgendes:
PROJECT_ID:die ID Ihres Cloud de Confiance -Projekts.ZONE:die ID der Zone.SUBNET_NAMEmit dem Namen Ihres VPC-Subnetzes.
Weitere Informationen zum Erstellen von SQL Server-Instanzen auf Compute Engine finden Sie unter SQL Server-Instanz erstellen.
SQL Server-VM konfigurieren und eine Verbindung herstellen
So konfigurieren Sie Ihre SQL Server-VM und stellen eine Verbindung zu ihr her:
Legen Sie das anfängliche Windows-Passwort für Ihr Konto fest:
Rufen Sie in der Cloud de Confiance Console die Seite VM-Instanzen auf.
Klicken Sie auf den Namen der SQL Server-VM.
Klicken Sie auf den Button Windows-Passwort festlegen.
Geben Sie ein Passwort ein und klicken Sie auf Festlegen, wenn Sie aufgefordert werden, das neue Windows-Passwort festzulegen.
Speichern Sie den Nutzernamen und das Passwort.
Stellen Sie eine Verbindung zur SQL Server-VM her:
Verwenden Sie die öffentliche IP-Adresse der SQL Server-VM von der Seite VM-Instanzen und die im vorherigen Schritt gespeicherten Anmeldedaten, um mit Microsoft Remote Desktop (RDP) eine Verbindung zu Ihrer SQL Server-VM herzustellen.
Führen Sie SQL Server Management Studio (SSMS) als Administrator aus.
Prüfen Sie, ob das Kästchen Serverzertifikat vertrauen aktiviert ist, und klicken Sie auf Verbinden.
Ihre SQL Server-VM kann jetzt für die Datenbankmigration verwendet werden. Informationen zum Erstellen neuer Nutzeranmeldungen zum Herstellen einer Verbindung zu Ihrer SQL Server-VM und zum Verwalten dieser VM finden Sie unter Anmeldung erstellen.
Vollständige Datenbanksicherung und ‑wiederherstellung
Eine vollständige Sicherung und Wiederherstellung der Datenbank ist die gängigste und einfachste Methode zur Datenbankmigration. Bei diesem Ansatz wird eine vollständige Sicherung der SQL Server-Datenbank in der Quellumgebung erstellt und dann in der Zielumgebung Cloud de Confiance by S3NS wiederhergestellt. Diese Methode ist zwar relativ einfach, kann aber bei großen Datenbanken zeitaufwendig sein, da das Erstellen und Wiederherstellen der Sicherung Zeit in Anspruch nimmt.
In diesem Abschnitt wird beschrieben, wie Sie Ihre SQL Server-Datenbank mit SSMS exportieren. Dabei wird die Beispieldatenbank AdventureWorks2022 verwendet.
Vollständige Datenbanksicherung erstellen
So erstellen Sie eine vollständige Datenbanksicherung:
Melden Sie sich über Microsoft RDP bei Ihrer AWS EC2-VM an.
Stellen Sie mit SSMS eine Verbindung zu SQL Server her.
Maximieren Sie im Objekt-Explorer den Ordner „Datenbanken“.
Klicken Sie mit der rechten Maustaste auf den Datenbanknamen und dann im Menü auf Aufgaben.
Klicken Sie auf Sichern, um den Assistenten für die Datenbanksicherung zu öffnen.
Prüfen Sie, ob der Name der zu sichernden Datenbank und der Sicherungstyp auf „Vollständig“ festgelegt sind.
Klicken Sie unter dem Ziel für das vollständige Backup auf Hinzufügen.
Klicken Sie auf das Dreipunkt-Menü (...), um den Ordner und den Namen der Sicherungsdatei auszuwählen.
Klicken Sie auf OK, um den Dateinamen festzulegen, und noch einmal auf OK, um das Ziel festzulegen.
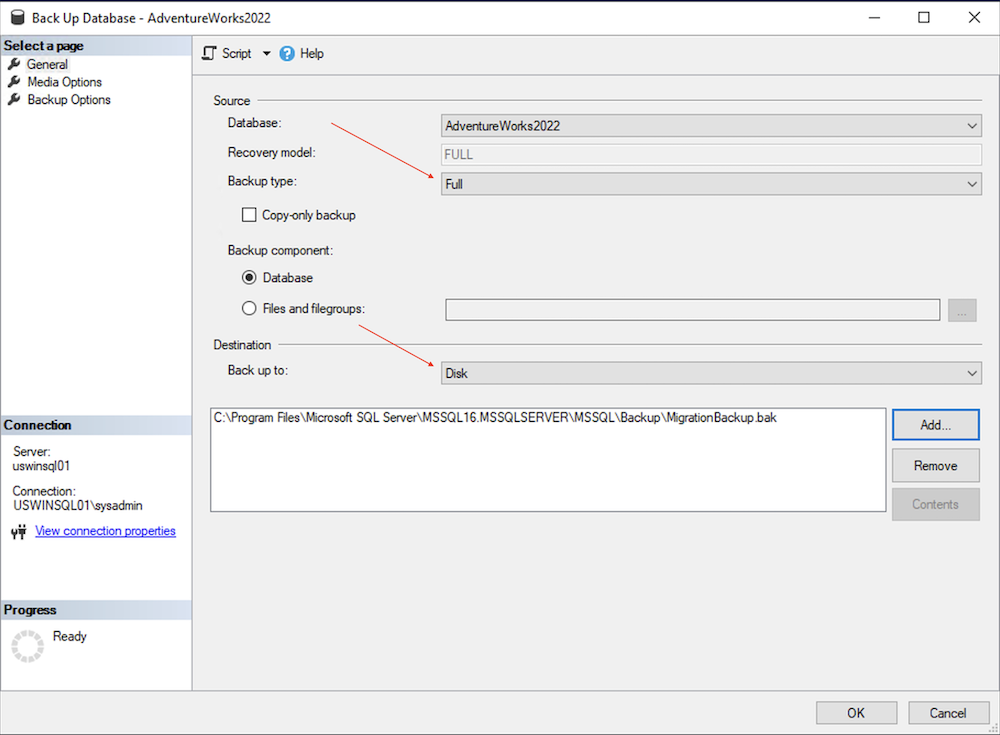
Klicken Sie auf OK, um die Datenbanksicherung zu starten, und warten Sie, bis die Sicherung abgeschlossen ist.
Nach Abschluss des Sicherungsvorgangs wird eine Sicherungsdatei erstellt. Sie können diese Sicherungsdatei jetzt verwenden, um die Datenbankinhalte auf eine Compute Engine-VM zu migrieren.
Klicken Sie auf OK, um den Assistenten für die Datenbanksicherung zu beenden.
Sicherungsdatei auf eine Compute Engine-VM übertragen
Wenn Sie den Inhalt Ihrer SQL Server-Datenbank migrieren möchten, müssen Sie die im vorherigen Schritt erstellte Sicherungsdatei auf die von Ihnen erstellte Compute Engine-VM übertragen. Informationen zu den verschiedenen Übertragungsoptionen finden Sie unter Dateien auf Windows-VMs übertragen.
SQL Server-Datenbank aus der Sicherungsdatei wiederherstellen
So stellen Sie die Datenbank aus der Sicherungsdatei wieder her:
Melden Sie sich über RDP bei Ihrer Compute Engine-VM an.
Stellen Sie mit SSMS eine Verbindung zu SQL Server her.
Klicken Sie im Objekt-Explorer mit der rechten Maustaste auf den Ordner Datenbanken und dann auf Datenbank wiederherstellen.
Klicken Sie für die Quelle auf Gerät und das Dreipunkt-Menü (...), um die Seite „Sicherungsgerät auswählen“ zu öffnen.
Prüfen Sie, ob der Sicherungsmedientyp auf „Datei“ festgelegt ist, und klicken Sie auf Hinzufügen, um die Sicherungsdatei auszuwählen.
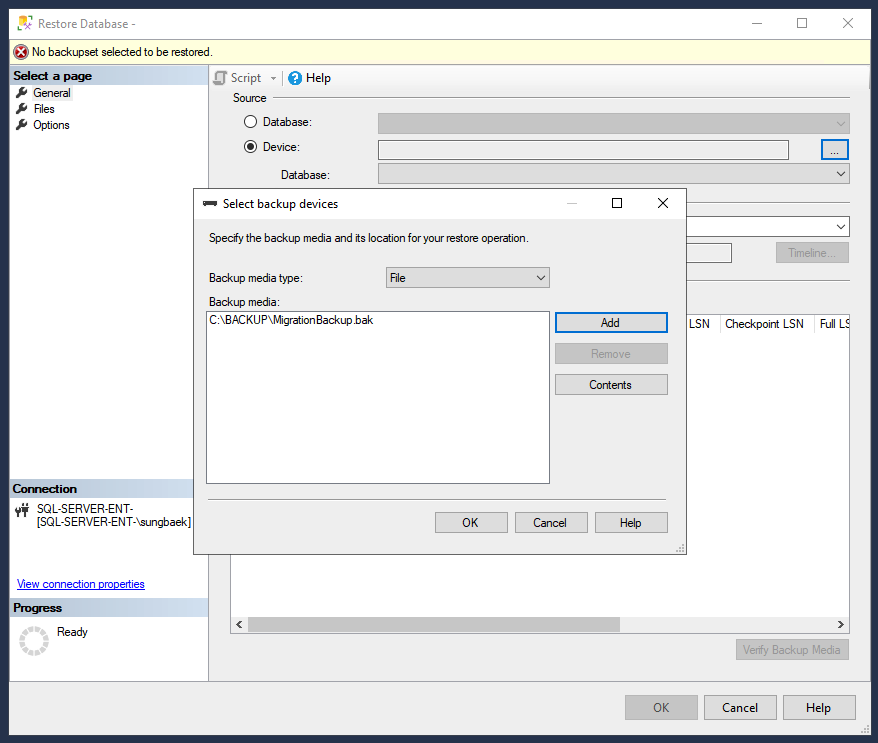
Klicken Sie auf OK, um die Sicherungsdatei als Wiederherstellungsgerät festzulegen.
Klicken Sie auf OK, um die Datenbank wiederherzustellen.
Wenn der Vorgang abgeschlossen ist, wird Ihre Datenbank zum Ziel-SQL Server in Compute Engine migriert.
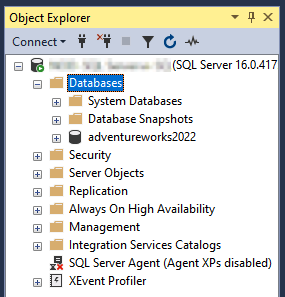
Um zu prüfen, ob der Vorgang erfolgreich abgeschlossen wurde, können Sie im Object Explorer den Ordner Databases (Datenbanken) maximieren und prüfen, ob die migrierte Datenbank angezeigt wird.
Mit einer BACPAC-Datei migrieren
Eine BACPAC-Datei (Backup Package) ist eine logische Darstellung einer SQL Server-Datenbank. Sie kann aus der AWS-Quellumgebung exportiert und dann in die Cloud de Confiance by S3NS -Zielumgebung importiert werden. Diese Methode ist in der Regel schneller als eine vollständige Sicherung und Wiederherstellung für kleinere Datenbanken, eignet sich jedoch möglicherweise nicht für sehr große Datenbanken oder solche mit komplexen Abhängigkeiten.
Im folgenden Abschnitt wird beschrieben, wie Sie Ihre SQL Server-Datenbank mithilfe einer BACPAC-Datei migrieren können.
BACPAC-Export erstellen
So erstellen Sie einen BACPAC-Export:
Melden Sie sich mit Microsoft RDP bei der AWS EC2-VM an.
Stellen Sie mit SSMS eine Verbindung zu SQL Server her.
Maximieren Sie im Objekt-Explorer den Ordner Databases (Datenbanken).
Klicken Sie mit der rechten Maustaste auf den Datenbanknamen und dann auf Tasks.
Klicken Sie auf Data-tier-Anwendung exportieren, um den Export-Assistenten zu öffnen.
Klicken Sie auf Weiter.
Klicken Sie bei der Option Auf lokaler Festplatte speichern auf Durchsuchen und wählen Sie die BACPAC-Datei aus.
Klicken Sie auf den Tab Erweitert und wählen Sie die Schemas aus, die Sie exportieren möchten.
Klicken Sie auf Weiter, um zur Zusammenfassung zu gelangen.
Klicken Sie auf Fertigstellen, um die BACPAC-Datei zu exportieren, und warten Sie, bis der Export abgeschlossen ist.
Klicken Sie auf Schließen, um den Assistenten zu beenden.
Übertragen Sie die in den vorherigen Schritten erstellte BACPAC-Datei auf die Ziel-VM in Compute Engine. Informationen zu den Übertragungsoptionen finden Sie unter Dateien auf Windows-VMs übertragen.
SQL Server-Datenbank aus einer BACPAC-Datei wiederherstellen
So stellen Sie die Datenbank aus der BACPAC-Datei wieder her:
Melden Sie sich über RDP bei der Compute Engine-VM an.
Stellen Sie mit SSMS eine Verbindung zu SQL Server her.
Klicken Sie im Objekt-Explorer mit der rechten Maustaste auf den Ordner Datenbanken und dann auf Data-tier-Anwendung importieren.
Klicken Sie auf Weiter.
Klicken Sie auf Durchsuchen, wählen Sie die BACPAC-Datei aus, die Sie wiederherstellen möchten, und klicken Sie dann auf Weiter.
Prüfen Sie den Namen der neuen Datenbank und klicken Sie auf Weiter.
Klicken Sie auf Fertigstellen und warten Sie, bis der Import abgeschlossen ist.
Klicken Sie auf Schließen, um den Assistenten zu beenden.
Um zu prüfen, ob der Vorgang erfolgreich abgeschlossen wurde, können Sie im Object Explorer den Ordner Databases (Datenbanken) maximieren und prüfen, ob die migrierte Datenbank angezeigt wird.
Mit Always On-Verfügbarkeitsgruppen migrieren
Eine AOAG ist eine Funktion von SQL Server für Hochverfügbarkeit und Notfallwiederherstellung. Sie können eine AOAG verwenden, um vorhandene AOAG-Cluster, eigenständige SQL-Server und Windows Server-Failover-Cluster (WSFC) zu migrieren. Bei dieser Methode wird ein Replikat der Datenbank in der Zielumgebung Cloud de Confiance by S3NS erstellt und die Daten werden zwischen Quelle und Ziel synchronisiert. Sobald die Synchronisierung abgeschlossen ist, kann das Replikat in der Zielumgebung Cloud de Confiance by S3NS als primär festgelegt werden. Diese Methode minimiert die Ausfallzeiten, erfordert jedoch zusätzliche Konfiguration und Einrichtung. Für einfache Migrationen mit einer erheblichen Toleranz für Ausfallzeiten sind andere Methoden möglicherweise einfacher und kostengünstiger.
Hinweis
Achten Sie vor Beginn der Migration auf Folgendes:
Um einen sicheren und nahtlosen Übergang von Daten zu gewährleisten, stellen Sie eine Peering-Verbindung zwischen AWS und Cloud de Confiance by S3NSher. Weitere Informationen finden Sie unter HA VPN-Verbindungen zwischen Cloud de Confiance by S3NS und AWS erstellen.
Die Quelldatenbank muss im Standalone-Modus ausgeführt werden und sowohl der Quell- als auch der Zielserver müssen mit einem Active Directory (AD) verbunden sein. Wenn die Quelldatenbank bereits Teil eines WSFC-Clusters mit einer AOAG ist, lesen Sie den Abschnitt Mit verteilten Verfügbarkeitsgruppen migrieren.
Achten Sie darauf, dass alle Verschlüsselungsschlüssel in der Quell-SQL Server-Datenbank auf allen SQL Server-Instanzen installiert sind, die der AOAG beitreten.
SQL Server für die Teilnahme an einer AOAG vorbereiten
Wenn Sie einer AOAG SQL-Server hinzufügen möchten, müssen Sie die AOAG-Funktion für alle SQL-Server-Instanzen aktivieren, die Sie der Gruppe hinzufügen möchten.
So aktivieren Sie die AOAG-Funktion auf allen SQL Server-VMs, die Sie einer AOAG hinzufügen möchten:
Aktivieren Sie AOAG auf Ihrem SQL Server.
Melden Sie sich über RDP bei Ihrer SQL Server-VM an.
Öffnen Sie PowerShell im Administratormodus.
Führen Sie den folgenden Befehl aus, um AOAG auf Ihrem SQL Server zu aktivieren.
Enable-SqlAlwaysOn -ServerInstance $env:COMPUTERNAME -Force
Führen Sie den folgenden Befehl aus, um einen Firewallport für die Datenreplikation zu öffnen.
netsh advfirewall firewall add rule name="Allow SQL Server replication" dir=in action=allow protocol=TCP localport=5022
Wiederholen Sie Schritt 1 für alle SQL Server-VMs, die Sie der AOAG hinzufügen möchten.
Erstellen Sie einen neuen Nutzer für Ihre SQL Server-Instanz in Ihrem AD.
$Credential = Get-Credential -UserName sql_server -Message 'Enter password' New-ADUser ` -Name "sql_server" ` -Description "SQL Admin account." ` -AccountPassword $Credential.Password ` -Enabled $true -PasswordNeverExpires $true
Führen Sie die folgenden Schritte für alle SQL Server-Instanzen aus, die Teil der AOAG sind:
- Öffnen Sie den SQL Server-Konfigurations-Manager.
- Wählen Sie im Navigationsbereich die Option SQL Server-Dienste aus.
- Klicken Sie in der Liste der Dienste mit der rechten Maustaste auf SQL Server (MSSQLSERVER) und wählen Sie Eigenschaften aus.
- Ändern Sie unter Anmeldung als das Konto so:
- Kontoname:
DOMAIN\sql_server, wobei DOMAIN der NetBIOS-Name Ihrer AD-Domain ist. - Passwort:Geben Sie das Passwort ein, das Sie im vorherigen Schritt 2 dieses Abschnitts ausgewählt haben.
- Kontoname:
Klicken Sie auf OK.
Wenn Sie aufgefordert werden, SQL Server neu zu starten, wählen Sie Ja.
Ihre SQL Server-Instanz wird jetzt unter einem Domainnutzerkonto ausgeführt.
Spiegelungsendpunkt für Ihre SQL Server-Datenbank einrichten
So erstellen Sie den Endpunkt für Ihre AOAG:
Wenn die Quell-SQL Server-Datenbank mit Transparent Data Encryption (TDE) verschlüsselt ist, führen Sie diesen Schritt aus, um die Zertifikate und Schlüssel zu sichern, zu übertragen und in der Ziel-SQL Server-Instanz zu installieren.
Melden Sie sich mit SSMS bei der Quelldatenbank in AWS an.
Führen Sie den folgenden T-SQL-Befehl aus, um den Endpunkt für die Verfügbarkeitsgruppe zu erstellen.
USE [master] GO CREATE LOGIN [
NET_DOMAIN\sql_server] FROM WINDOWS GO USE [DATABASE_NAME] GO CREATE USER [NET_DOMAIN\sql_server] FOR LOGIN [NET_DOMAIN\sql_server] GO USE [master] GO CREATE ENDPOINT migration_endpoint STATE=STARTED AS TCP (LISTENER_PORT=5022) FOR DATABASE_MIRRORING (ROLE=ALL); GO GRANT CONNECT ON ENDPOINT::[migration_endpoint] TO [NET_DOMAIN\sql_server] GOErsetzen Sie
NET_DOMAINdurch den NetBIOS-Namen Ihrer AD-Domain undDATABASE_NAMEdurch den Namen der zu migrierenden Datenbank.Stellen Sie mit SSMS eine Verbindung zum Ziel-SQL Server auf Cloud de Confiance by S3NS her und führen Sie den folgenden T-SQL-Befehl aus, um den Datenbankspiegelungsendpunkt zu erstellen.
CREATE LOGIN [
NET_DOMAIN\sql_server] FROM WINDOWS GO CREATE ENDPOINT migration_endpoint STATE=STARTED AS TCP (LISTENER_PORT=5022) FOR DATABASE_MIRRORING (ROLE=ALL); GO GRANT CONNECT ON ENDPOINT::[migration_endpoint] TO [NET_DOMAIN\sql_server] GOErsetzen Sie
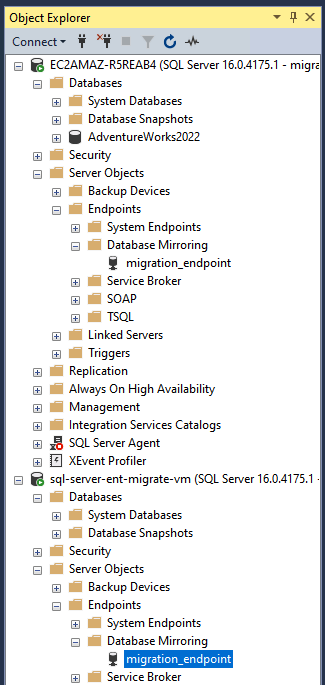
NET_DOMAINdurch den NetBIOS-Namen Ihrer AD-Domain.Prüfen Sie die Endpunkte, indem Sie im Objekt-Explorer in SSMS zu Serverobjekte > Endpunkte > Datenbankspiegelung navigieren.
AOAG erstellen
So erstellen Sie eine AOAG:
Melden Sie sich mit SSMS bei der Quelldatenbank in AWS an.
Führen Sie den folgenden T-SQL-Befehl aus, um den Datenbankwiederherstellungsmodus auf „Vollständig“ festzulegen und eine vollständige Sicherung zu erstellen.
USE [master] GO ALTER DATABASE [
DATABASE_NAME] SET RECOVERY FULL; BACKUP DATABASE [DATABASE_NAME] TO DISK = N'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\Backup\DATABASE_NAME.bak';Ersetzen Sie
DATABASE_NAMEdurch den Namen der zu migrierenden Datenbank.Führen Sie den folgenden T-SQL-Befehl aus, um die AOAG zu erstellen.
USE [master] GO CREATE AVAILABILITY GROUP [migration-ag] WITH ( AUTOMATED_BACKUP_PREFERENCE = SECONDARY, DB_FAILOVER = OFF, DTC_SUPPORT = NONE, REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0 ) FOR DATABASE [DATABASE_NAME] REPLICA ON N'SOURCE_SERVERNAME' WITH ( ENDPOINT_URL = 'TCP://SOURCE_HOSTNAME:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, BACKUP_PRIORITY = 50, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = READ_ONLY) ), N'DEST_SERVERNAME' WITH ( ENDPOINT_URL = 'TCP://DEST_HOSTNAME:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, BACKUP_PRIORITY = 50, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = READ_ONLY) ); GOErsetzen Sie Folgendes:
DATABASE_NAME:Name der zu migrierenden Datenbank.SOURCE_SERVERNAME:Der Servername der Quelldatenbank.DEST_SERVERNAME:Der Servername der Zieldatenbank.SOURCE_HOSTNAME:mit dem voll qualifizierten Domainnamen (Fully Qualified Domain Name, FQDN) der Quelle.DEST_HOSTNAME:mit dem FQDN des Ziels.
Führen Sie den folgenden T-SQL-Befehl in der Zieldatenbank aus, um sie der AOAG hinzuzufügen.
USE [master] GO ALTER AVAILABILITY GROUP [migration-ag] JOIN WITH (CLUSTER_TYPE = EXTERNAL); ALTER AVAILABILITY GROUP [migration-ag] GRANT CREATE ANY DATABASE; GO
Prüfen Sie die neu erstellte AOAG und den Datenbankstatus im Objekt-Explorer oder durch Ausführen des folgenden T-SQL-Befehls.
SELECT * FROM sys.dm_hadr_availability_group_states GO
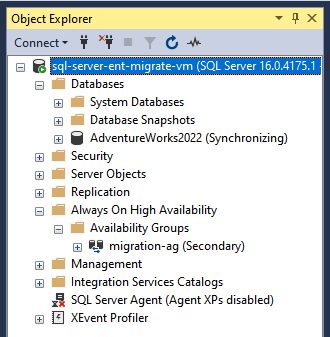
Die SQL Server-AOAG ist jetzt konfiguriert und wird zwischen AWS und Cloud de Confiance by S3NSsynchronisiert. Als Nächstes müssen Sie einen WSFC und einen Listener für Hochverfügbarkeit und Notfallwiederherstellung konfigurieren. Weitere Informationen finden Sie unter Windows Server Failover Clustering mit SQL Server und Was ist ein Verfügbarkeitsgruppenlistener?.
Mit verteilten Verfügbarkeitsgruppen migrieren
Eine verteilte Verfügbarkeitsgruppe ist ein besonderer Typ von Verfügbarkeitsgruppe, die zwei separate Verfügbarkeitsgruppen umfasst. Sie ist darauf ausgelegt, Hochverfügbarkeit und Notfallwiederherstellung an geografisch verteilten Standorten zu ermöglichen. Diese Architektur ermöglicht eine nahtlose Datenreplikation und ein nahtloses Failover zwischen der primären und der sekundären Verfügbarkeitsgruppe, was ideal für die Datenmigration ist. Weitere Informationen finden Sie unter Verteilte Verfügbarkeitsgruppen.
.In den folgenden Abschnitten wird beschrieben, wie Sie Ihre SQL Server-Datenbank mithilfe von verteilten Verfügbarkeitsgruppen migrieren können.
Hinweis
Sie benötigen einen WSFC mit SQL Server, der eine Verfügbarkeitsgruppe mit einem VNN-Listener (Virtual Network Name) verwendet und auf AWS ausgeführt wird.
Zielumgebung vorbereiten
So bereiten Sie die Zielumgebung vor:
Informationen zum Konfigurieren eines WSFC mit SQL Server mithilfe einer Verfügbarkeitsgruppe mit einem internen Load-Balancer auf Cloud de Confiance by S3NSfinden Sie unter SQL Server AlwaysOn-Verfügbarkeitsgruppen mit synchronem Commit mithilfe eines internen Load-Balancers konfigurieren.
Prüfen Sie im Objekt-Explorer, ob
bookshelf-agerstellt wurde und die Datenbankbookshelfrepliziert. Nach der Bestätigung führen Sie die nächsten Schritte aus, um sowohl die Verfügbarkeitsgruppe als auch die Datenbank von beiden Knoten in Ihrem Failovercluster zu entfernen.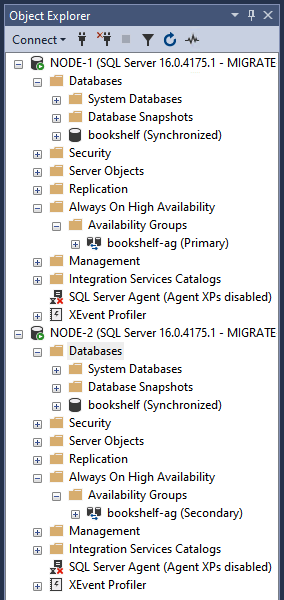
Stellen Sie in SSMS eine Verbindung zu
node-1her und speichern Sie die IP-Adresse desbookshelf-Listeners.SELECT * FROM sys.availability_group_listeners
Führen Sie den folgenden T-SQL-Befehl aus, um die Verfügbarkeitsgruppe
bookshelf-agund die Datenbankbookshelfzu entfernen.USE master GO DROP AVAILABILITY GROUP [bookshelf-ag] GO ALTER DATABASE [bookshelf] SET SINGLE_USER WITH ROLLBACK IMMEDIATE GO DROP DATABASE [bookshelf] GO
Führen Sie den folgenden T-SQL-Befehl in SSMS für
node-2aus, um die replizierte Datenbank zu entfernen.USE master GO DROP DATABASE [bookshelf] GO
Verteilte Verfügbarkeitsgruppe erstellen
So erstellen Sie eine neue Verfügbarkeitsgruppe für die verteilte Verfügbarkeitsgruppe:
Führen Sie den folgenden T-SQL-Befehl in
node-1aus.USE master GO CREATE AVAILABILITY GROUP [gcp-dest-ag] FOR REPLICA ON N'NODE-1' WITH ( ENDPOINT_URL = N'TCP://NODE-1:5022', FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO), SEEDING_MODE = AUTOMATIC ), N'NODE-2' WITH ( ENDPOINT_URL = N'TCP://NODE-2:5022', FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO), SEEDING_MODE = AUTOMATIC ); GOListener erstellen
USE master; GO ALTER AVAILABILITY GROUP [gcp-dest-ag] ADD LISTENER N'gcp-dest-lsnr' ( WITH IP ( (N'
LISTENER_IP', N'255.255.255.0') ), PORT = 1433); GOErsetzen Sie
LISTENER_IPdurch die IP-Adresse des Listeners.Stellen Sie mit SSMS eine Verbindung zu
node-2her und führen Sie den folgenden T-SQL-Befehl aus, um sie der Verfügbarkeitsgruppegcp-dest-aghinzuzufügen.USE master GO ALTER AVAILABILITY GROUP [gcp-dest-ag] JOIN; ALTER AVAILABILITY GROUP [gcp-dest-ag] GRANT CREATE ANY DATABASE;
Stellen Sie mit SSMS eine Verbindung zum primären Replikat der Quell-SQL Server-Instanz auf AWS her und führen Sie den folgenden T-SQL-Befehl aus, um eine verteilte Verfügbarkeitsgruppe zu erstellen.
USE [master] GO CREATE AVAILABILITY GROUP [distributed-ag] WITH (DISTRIBUTED) AVAILABILITY GROUP ON '
AWS_AG' WITH ( LISTENER_URL = 'tcp://AWS_LISTENER:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ), 'gcp-dest-ag' WITH ( LISTENER_URL = 'tcp://gcp-dest-lsnr:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ) GOErsetzen Sie
AWS_AGdurch den Namen der Verfügbarkeitsgruppe in AWS undAWS_LISTENERdurch den Listener der AWS-Verfügbarkeitsgruppe.Führen Sie den folgenden T-SQL-Befehl in SSMS auf
node-1aus, um ihn der verteilten Verfügbarkeitsgruppe hinzuzufügen.USE [master] GO ALTER AVAILABILITY GROUP [distributed-ag] JOIN AVAILABILITY GROUP ON '
AWS_AG' WITH ( LISTENER_URL = 'tcp://AWS_LISTENER:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ), 'gcp-dest-ag' WITH ( LISTENER_URL = 'tcp://gcp-dest-lsnr:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ) GOErsetzen Sie
AWS_AGdurch den Namen der Verfügbarkeitsgruppe in AWS undAWS_LISTENERdurch den Listener der AWS-Verfügbarkeitsgruppe.Führen Sie den folgenden T-SQL-Befehl auf „node-1“ aus, um zu prüfen, ob alle Verfügbarkeitsgruppen fehlerfrei sind und in der verteilten Verfügbarkeitsgruppe in den neuen SQL Server-Cluster auf Cloud de Confiance by S3NSrepliziert werden.
SELECT * FROM sys.dm_hadr_availability_group_states GO
Bereinigen
Nachdem Sie die Anleitung abgeschlossen haben, können Sie die erstellten Ressourcen bereinigen, damit sie keine Kontingente mehr nutzen und keine Gebühren mehr anfallen. In den folgenden Abschnitten erfahren Sie, wie Sie diese Ressourcen löschen oder deaktivieren.
Projekt löschen
Am einfachsten vermeiden Sie weitere Kosten, wenn Sie das zum Ausführen der Anleitung erstellte Projekt löschen.
So löschen Sie das Projekt:
- Wechseln Sie in der Cloud de Confiance -Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.