
Prevedi serie temporali gerarchiche con un modello univariato ARIMA_PLUS
Questo tutorial ti insegna a utilizzare un
modello di serie temporale univariata ARIMA_PLUS
per prevedere serie temporali gerarchiche. Prevede il valore futuro
per una determinata colonna, in base ai valori storici di quella colonna,
e calcola anche i valori di roll-up per quella colonna per una o più dimensioni di
interesse.
I valori previsti vengono calcolati per ogni punto temporale, per ogni valore in una o più colonne che specificano le dimensioni di interesse. Ad esempio, se vuoi prevedere gli incidenti stradali giornalieri e hai specificato una colonna delle dimensioni contenente i dati statali, i dati previsti conterranno i valori per ogni giorno per lo stato A, poi i valori per ogni giorno per lo stato B e così via. Se volessi prevedere gli incidenti stradali giornalieri e avessi specificato colonne delle dimensioni contenenti dati su stato e città, i dati previsti conterrebbero valori per ogni giorno per lo stato A e la città A, poi valori per ogni giorno per lo stato A e la città B e così via. Nei modelli di serie temporali gerarchiche, il riconciliamento gerarchico viene utilizzato per aggregare e riconciliare ogni serie temporale secondaria con la relativa serie temporale principale. Ad esempio, la somma dei valori previsti per tutte le città dello stato A deve essere uguale al valore previsto per lo stato A.
In questo tutorial, creerai due modelli di serie temporali sugli stessi dati, uno che utilizza la previsione gerarchica e uno che non la utilizza. In questo modo puoi confrontare i risultati restituiti dai modelli.
Questo tutorial utilizza i dati della tabella pubblica
bigquery-public-data.iowa_liquor.sales.sales. Questa tabella contiene informazioni su oltre 1 milione di prodotti alcolici in
diversi negozi utilizzando i dati pubblici sulle vendite di alcolici in Iowa.
Prima di leggere questo tutorial, ti consigliamo vivamente di leggere Previsione di più serie temporali con un modello univariato.
Autorizzazioni richieste
Per creare il set di dati, devi disporre dell'autorizzazione IAM
bigquery.datasets.create.Per creare il modello, devi disporre delle seguenti autorizzazioni:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
Per eseguire l'inferenza, devi disporre delle seguenti autorizzazioni:
bigquery.models.getDatabigquery.jobs.create
Per saperne di più sui ruoli e sulle autorizzazioni IAM in BigQuery, consulta Introduzione a IAM.
Obiettivi
In questo tutorial utilizzi quanto segue:
- Creazione di un modello di serie temporali multiple e di un modello di serie temporali gerarchiche multiple per prevedere i valori delle vendite di bottiglie utilizzando l'istruzione
CREATE MODEL. - Recuperare i valori delle vendite di bottiglie previsti dai modelli utilizzando la
funzione
ML.FORECAST.
Costi
Questo tutorial utilizza componenti fatturabili di Cloud de Confiance by S3NS, tra cui:
- BigQuery
- BigQuery ML
Per ulteriori informazioni sui costi di BigQuery, consulta la pagina Prezzi di BigQuery.
Per ulteriori informazioni sui costi di BigQuery ML, consulta Prezzi di BigQuery ML.
-
In the Cloud de Confiance console, on the project selector page, select or create a Cloud de Confiance project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Cloud de Confiance project.
- BigQuery viene attivato automaticamente nei nuovi progetti.
Per attivare BigQuery in un progetto preesistente, vai a
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Nella console Cloud de Confiance , vai alla pagina BigQuery.
Nel riquadro Explorer, fai clic sul nome del progetto.
Fai clic su Visualizza azioni > Crea set di dati.
Nella pagina Crea set di dati:
In ID set di dati, inserisci
bqml_tutorial.Per Tipo di località, seleziona Multi-regione e poi Stati Uniti (più regioni negli Stati Uniti).
Lascia invariate le restanti impostazioni predefinite e fai clic su Crea set di dati.
Crea un set di dati denominato
bqml_tutorialcon la località dei dati impostata suUSe una descrizione diBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Anziché utilizzare il flag
--dataset, il comando utilizza la scorciatoia-d. Se ometti-de--dataset, il comando crea per impostazione predefinita un dataset.Verifica che il set di dati sia stato creato:
bq lsNella console Cloud de Confiance , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast` OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COL = 'date', TIME_SERIES_DATA_COL = 'total_bottles_sold', TIME_SERIES_ID_COL = ['store_number', 'zip_code', 'city', 'county'], HOLIDAY_REGION = 'US') AS SELECT store_number, zip_code, city, county, date, SUM(bottles_sold) AS total_bottles_sold FROM `bigquery-public-data.iowa_liquor_sales.sales` WHERE date BETWEEN DATE('2015-01-01') AND DATE('2015-12-31') AND county IN ('POLK', 'LINN', 'SCOTT') GROUP BY store_number, date, city, zip_code, county;
Il completamento della query richiede circa 37 secondi, dopodiché puoi accedere al modello
liquor_forecast. Poiché la query utilizza un'istruzioneCREATE MODELper creare un modello, non sono presenti risultati della query.Nella console Cloud de Confiance , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.liquor_forecast`, STRUCT(20 AS horizon, 0.8 AS confidence_level)) ORDER BY store_number, county, city, zip_code, forecast_timestamp;
I risultati dovrebbero essere simili ai seguenti:
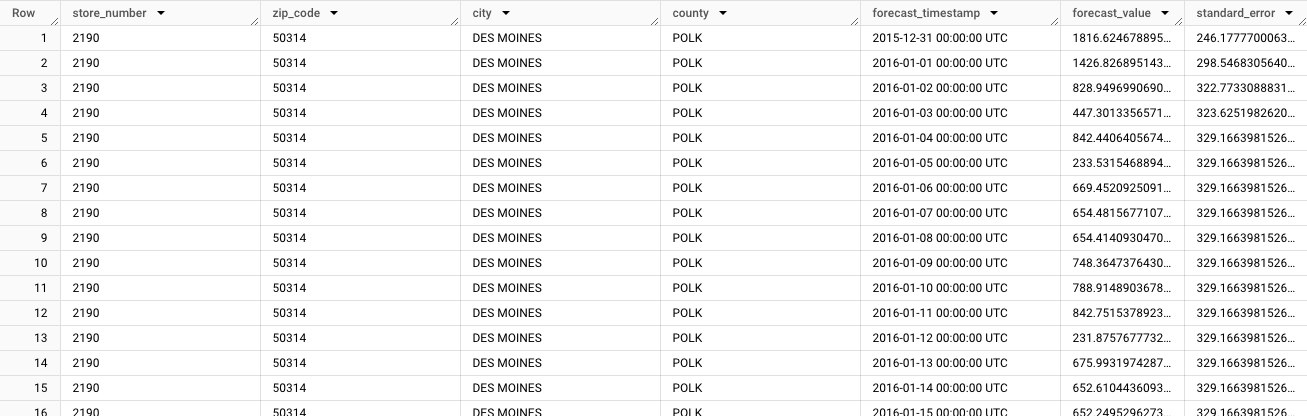
L'output inizia con i dati previsti per la prima serie temporale:
store_number=2190,zip_code=50314,city=DES MOINES,county=POLK. Man mano che scorri i dati, visualizzi le previsioni per ogni serie temporale univoca successiva. Per generare previsioni che aggregano i totali per dimensioni diverse, ad esempio le previsioni per una contea specifica, devi generare una previsione gerarchica.Nella console Cloud de Confiance , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast_hierarchical` OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COL = 'date', TIME_SERIES_DATA_COL = 'total_bottles_sold', TIME_SERIES_ID_COL = ['store_number', 'zip_code', 'city', 'county'], HIERARCHICAL_TIME_SERIES_COLS = ['zip_code', 'store_number'], HOLIDAY_REGION = 'US') AS SELECT store_number, zip_code, city, county, date, SUM(bottles_sold) AS total_bottles_sold FROM `bigquery-public-data.iowa_liquor_sales.sales` WHERE date BETWEEN DATE('2015-01-01') AND DATE('2015-12-31') AND county IN ('POLK', 'LINN', 'SCOTT') GROUP BY store_number, date, city, zip_code, county;
Il completamento della query richiede circa 45 secondi, dopodiché è possibile accedere al modello
bqml_tutorial.liquor_forecast_hierarchicalnel riquadro Explorer. Poiché la query utilizza un'istruzioneCREATE MODELper creare un modello, non ci sono risultati della query.Nella console Cloud de Confiance , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.liquor_forecast_hierarchical`, STRUCT(30 AS horizon, 0.8 AS confidence_level)) WHERE city = 'LECLAIRE' ORDER BY county, city, zip_code, store_number, forecast_timestamp;
I risultati dovrebbero essere simili ai seguenti:
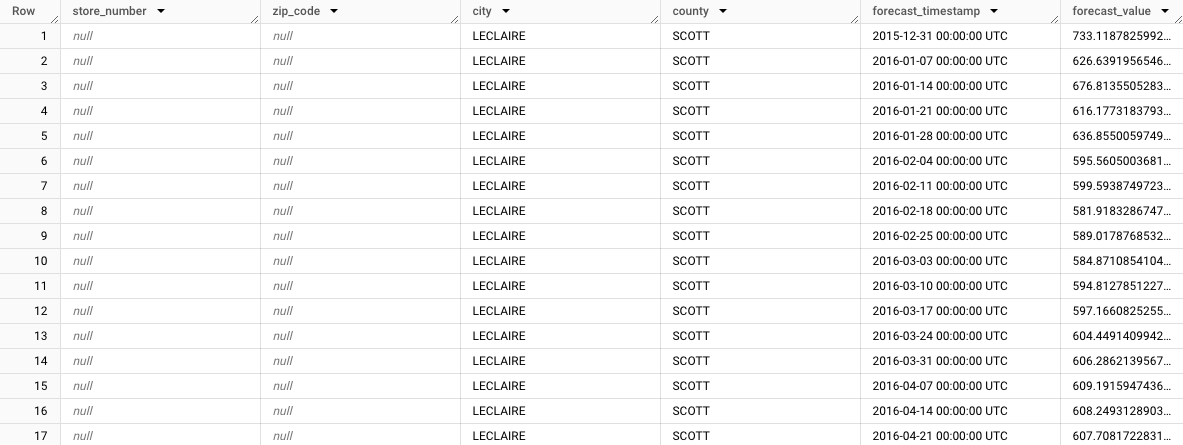
Nota come viene visualizzata la previsione aggregata per la città di LeClaire,
store_number=NULL,zip_code=NULL,city=LECLAIRE,county=SCOTT. Man mano che esamini le altre righe, nota le previsioni per gli altri sottogruppi. Ad esempio, l'immagine seguente mostra le previsioni aggregate per il codice postale52753,store_number=NULL,zip_code=52753,city=LECLAIRE,county=SCOTT: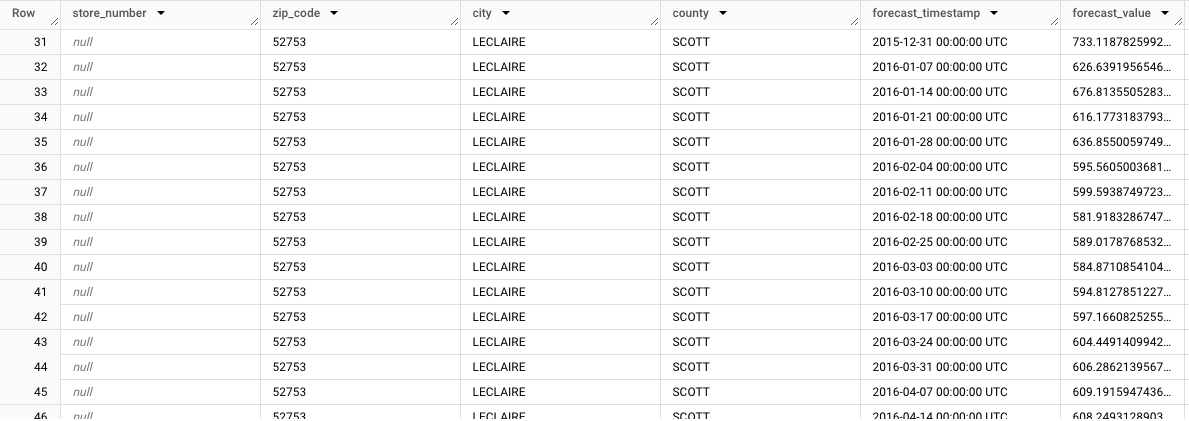
- Puoi eliminare il progetto che hai creato.
- In alternativa, puoi conservare il progetto ed eliminare il set di dati.
Se necessario, apri la pagina BigQuery nella consoleCloud de Confiance .
Nella navigazione, fai clic sul set di dati bqml_tutorial che hai creato.
Fai clic su Elimina set di dati sul lato destro della finestra. Questa azione elimina il set di dati, la tabella e tutti i dati.
Nella finestra di dialogo Elimina set di dati, conferma il comando di eliminazione digitando il nome del set di dati (
bqml_tutorial) e poi fai clic su Elimina.- In the Cloud de Confiance console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Scopri come prevedere una singola serie temporale con un modello univariato
- Scopri come prevedere più serie temporali con un modello univariato
- Scopri come scalare un modello univariato quando prevedi più serie temporali su più righe.
- Scopri come prevedere una singola serie temporale con un modello multivariato.
- Per una panoramica di BigQuery ML, consulta Introduzione all'AI e al ML in BigQuery.
Crea un set di dati
Crea un set di dati BigQuery per archiviare il tuo modello ML.
Console
bq
Per creare un nuovo set di dati, utilizza il
comando bq mk
con il flag --location. Per un elenco completo dei possibili parametri, consulta la
documentazione di riferimento del
comando bq mk --dataset.
API
Chiama il metodo datasets.insert con una risorsa dataset definita.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
Crea un modello di serie temporale
Crea un modello di serie temporale utilizzando i dati sulle vendite di alcolici in Iowa.
La seguente query GoogleSQL crea un modello che prevede il numero totale giornaliero di bottiglie vendute nel 2015 nelle contee di Polk, Linn e Scott.
Nella seguente query, la clausola
OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...)
indica che stai creando un modello di serie temporale basato su
ARIMA. Utilizzi l'opzione
TIME_SERIES_ID
dell'istruzione CREATE MODEL per specificare una o più colonne nei dati di input
per cui vuoi ottenere le previsioni. L'opzione
auto_arima_max_order
dell'istruzione CREATE MODEL controlla lo
spazio di ricerca per l'ottimizzazione degli iperparametri nell'algoritmo auto.ARIMA. L'opzione decompose_time_series dell'istruzione CREATE MODEL è impostata su TRUE per impostazione predefinita, in modo che le informazioni sui dati delle serie temporali vengano restituite quando valuti il modello nel passaggio successivo.
La clausola OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...)
indica che stai creando un
modello di serie temporali
basato su ARIMA. Per impostazione predefinita,
auto_arima=TRUE,
in modo che l'algoritmo auto.ARIMA ottimizzi automaticamente gli iperparametri nei
modelli ARIMA_PLUS. L'algoritmo adatta decine di modelli candidati e sceglie
il modello migliore, ovvero quello con il più basso
criterio di informazione di Akaike (AIC).
L'impostazione dell'opzione
holiday_region
su US consente una modellazione più accurata di questi punti temporali delle festività negli Stati Uniti
se nella serie temporale sono presenti pattern delle festività negli Stati Uniti.
Per creare il modello:
Utilizzare il modello per prevedere i dati
Prevedi i valori futuri delle serie temporali utilizzando la funzione ML.FORECAST.
Nella seguente query, la
clausola STRUCT(20 AS horizon, 0.8 AS confidence_level) indica che la
query prevede 20 punti temporali futuri e genera un intervallo di previsione
con un livello di confidenza dell'80%.
Per prevedere i dati con il modello:
Crea un modello di serie temporali gerarchiche
Crea una previsione di serie temporali gerarchica utilizzando i dati sulle vendite di alcolici in Iowa.
La seguente query GoogleSQL crea un modello che genera previsioni gerarchiche per il numero totale giornaliero di bottiglie vendute nel 2015 nelle contee di Polk, Linn e Scott.
Nella seguente query, l'opzione HIERARCHICAL_TIME_SERIES_COLS nell'istruzione
CREATE MODEL indica che stai creando una previsione gerarchica
basata su un insieme di colonne che specifichi. Ciascuna di queste colonne viene raggruppata
e aggregata. Ad esempio, dalla query precedente, ciò significa che il valore della colonna store_number viene aggregato per mostrare le previsioni per ogni valore di county, city e zip_code. Separatamente, i valori di zip_code e store_number
vengono aggregati anche per mostrare le previsioni per ciascun valore di county e city.
L'ordine delle colonne è importante perché definisce la struttura della gerarchia.
Per creare il modello:
Utilizzare il modello gerarchico per prevedere i dati
Recupera i dati di previsione gerarchica dal modello utilizzando la funzione ML.FORECAST.
Per prevedere i dati con il modello:
Esegui la pulizia
Per evitare che al tuo account Cloud de Confiance by S3NS vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Elimina il set di dati
L'eliminazione del progetto rimuove tutti i set di dati e tutte le tabelle nel progetto. Se preferisci riutilizzare il progetto, puoi eliminare il set di dati creato in questo tutorial:
Elimina il progetto
Per eliminare il progetto: