
Gemini でデータを準備する
このドキュメントでは、BigQuery でデータ準備用の SQL コードの候補を生成し、管理する方法について説明します。
詳細については、BigQuery データ準備の概要をご覧ください。
始める前に
BigQuery でデータ準備エディタを開く
BigQuery でデータ準備エディタを開くには、新しいデータ準備を作成するか、既存のテーブルまたは Cloud Storage ファイルから作成するか、あるいは既存のデータ準備を開きます。データ準備の作成時に発生する処理の詳細については、データ準備のエントリ ポイントをご覧ください。
[BigQuery] ページで、次の方法でデータ準備エディタに移動できます。
新規作成
BigQuery で新しいデータ準備を作成する手順は次のとおりです。
- Cloud de Confiance コンソールで、[BigQuery] ページに移動します。
BigQuery に移動 - [新規作成] リストに移動し、[データ準備] をクリックします。データ準備エディタが、新しい無題のデータ準備タブに表示されます。
- エディタの検索バーにテーブル名またはキーワードを入力し、テーブルを選択します。テーブルのデータ準備エディタが開き、[データ] タブにデータのプレビューと、Gemini からの最初のデータ準備の候補が表示されます。
- 省略可: 表示を簡素化するには、fullscreen(全画面表示)をクリックして全画面表示モードをオンにします。
省略可: データ準備の詳細の表示、バージョン履歴の表示、新しいコメントの追加、既存のコメントへの返信を行うには、ツールバーを使用します。
[コメント] ツールバー機能はプレビュー版です。この機能に関するフィードバックを提供する場合、またはサポートをリクエストする場合は、bqui-workspace-pod@google.com までメールでお送りください。
テーブルから作成する
既存のテーブルから新しいデータ準備を作成する手順は次のとおりです。
- Cloud de Confiance コンソールで、[BigQuery] ページに移動します。
BigQuery に移動 - 左側のペインで、 [エクスプローラ] をクリックします。
- [エクスプローラ] ペインでプロジェクトを開き、[データセット] をクリックして、データセットを選択します。
- テーブル名で、more_vert(アクション)> [開く] > [データ準備] をクリックします。テーブルのデータ準備エディタが開き、[データ] タブにデータのプレビューと、Gemini からの最初の一連のデータ準備の候補が表示されます。
- 省略可: 表示を簡素化するには、fullscreen(全画面表示)をクリックして全画面表示モードをオンにします。
省略可: データ準備の詳細の表示、バージョン履歴の表示、新しいコメントの追加、既存のコメントへの返信を行うには、ツールバーを使用します。
[コメント] ツールバー機能はプレビュー版です。この機能に関するフィードバックを提供する場合、またはサポートをリクエストする場合は、bqui-workspace-pod@google.com までメールでお送りください。
Cloud Storage ファイルから作成する
Cloud Storage のファイルから新しいデータ準備を作成する手順は次のとおりです。
ファイルを読み込む
- Cloud de Confiance コンソールで、[BigQuery] ページに移動します。
BigQuery に移動 - [新規作成] リストで、[データ準備] をクリックします。データ準備エディタが、新しい無題のデータ準備タブに表示されます。
- データソースのリストで、[Google Cloud Storage] をクリックします。[データを準備] ダイアログが開きます。
- [ソース] セクションで、Cloud Storage バケットからファイルを選択するか、ソースのパスを入力します。たとえば、CSV ファイルのパス(
STORAGE_BUCKET_NAME/FILE_NAME.csv)を入力します。*.csvなどのワイルドカード検索がサポートされています。
ファイル形式は自動的に検出されます。サポートされている形式は、Avro、CSV、JSONL、ORC、Parquet です。DAT、TSV、TXT などの他の互換性のあるファイル形式は、CSV 形式として読み取られます。 - ファイルをアップロードする外部ステージング テーブルを定義します。[ステージング テーブル] セクションで、新しいテーブルのプロジェクト名、データセット名、テーブル名を入力します。
- [スキーマ] セクションでスキーマを確認します。Gemini がファイル内の列名を確認します。見つからない場合は、候補が表示されます。
デフォルトでは、データ準備ファイルはデータを文字列として読み込みます。より具体的なデータ型は、ファイルデータを準備するときに定義できます。 - 省略可: [詳細オプション] で、ジョブが失敗する前に許容されるエラー数などの詳細情報を追加できます。Gemini は、ファイルの内容に基づいて追加のオプションを提供します。
- [作成] をクリックします。テーブルのデータ準備エディタが開き、[データ] タブにデータのプレビューと、Gemini からの最初のデータ準備の候補が表示されます。
- 省略可: 表示を簡素化するには、fullscreen(全画面表示)をクリックして全画面表示モードをオンにします。
省略可: データ準備の詳細の表示、バージョン履歴の表示、新しいコメントの追加、既存のコメントへの返信を行うには、ツールバーを使用します。
[コメント] ツールバー機能はプレビュー版です。この機能に関するフィードバックを提供する場合、またはサポートをリクエストする場合は、bqui-workspace-pod@google.com までメールでお送りください。
ファイルを準備する
データビューで、次の手順に沿って、読み込んだステージング済みの Cloud Storage データを準備します。
- 省略可: 変換候補の候補リストを参照するか、列を選択して候補を生成することで、関連する列により強力なデータ型を定義します。
- 省略可: 検証ルールを定義します。詳細については、エラーテーブルを構成して検証ルールを追加するをご覧ください。
- 宛先テーブルを追加します。
- Cloud Storage のデータを宛先テーブルに読み込むには、データ準備を実行します。
- 省略可: データ準備の実行をスケジュールします。
- 省略可: データを増分処理してデータ準備を最適化します。
既存のものを開く
既存のデータ準備用のエディタを開く手順は次のとおりです。
- Cloud de Confiance コンソールで、[BigQuery] ページに移動します。
BigQuery に移動 - 左側のペインで、 [エクスプローラ] をクリックします。
- [エクスプローラ] ペインで、プロジェクト名をクリックし、[データ準備] をクリックします。
- 既存のデータ準備を選択します。データ準備パイプラインのグラフビューが表示されます。
- グラフ内のいずれかのノードを選択します。テーブルのデータ準備エディタが開き、[データ] タブにデータのプレビューと、Gemini からの最初のデータ準備の候補が表示されます。
- 省略可: 表示を簡素化するには、fullscreen(全画面表示)をクリックして全画面表示モードをオンにします。
省略可: データ準備の詳細の表示、バージョン履歴の表示、新しいコメントの追加、既存のコメントへの返信を行うには、ツールバーを使用します。
[コメント] ツールバー機能はプレビュー版です。この機能に関するフィードバックを提供する場合、またはサポートをリクエストする場合は、bqui-workspace-pod@google.com までメールでお送りください。
データの準備ステップを追加する
データは段階的に準備します。Gemini が提案した手順をプレビューまたは適用できます。候補を改善したり、独自の手順を適用することもできます。
Gemini の候補を適用して改善する
テーブルのデータ準備エディタを開くと、Gemini は読み込んだテーブルのデータとスキーマを検査し、フィルタと変換の候補を生成します。候補は、[ステップ] リストのカードに表示されます。
次の図は、Gemini が提案したステップを適用して改善できる場所を示しています。
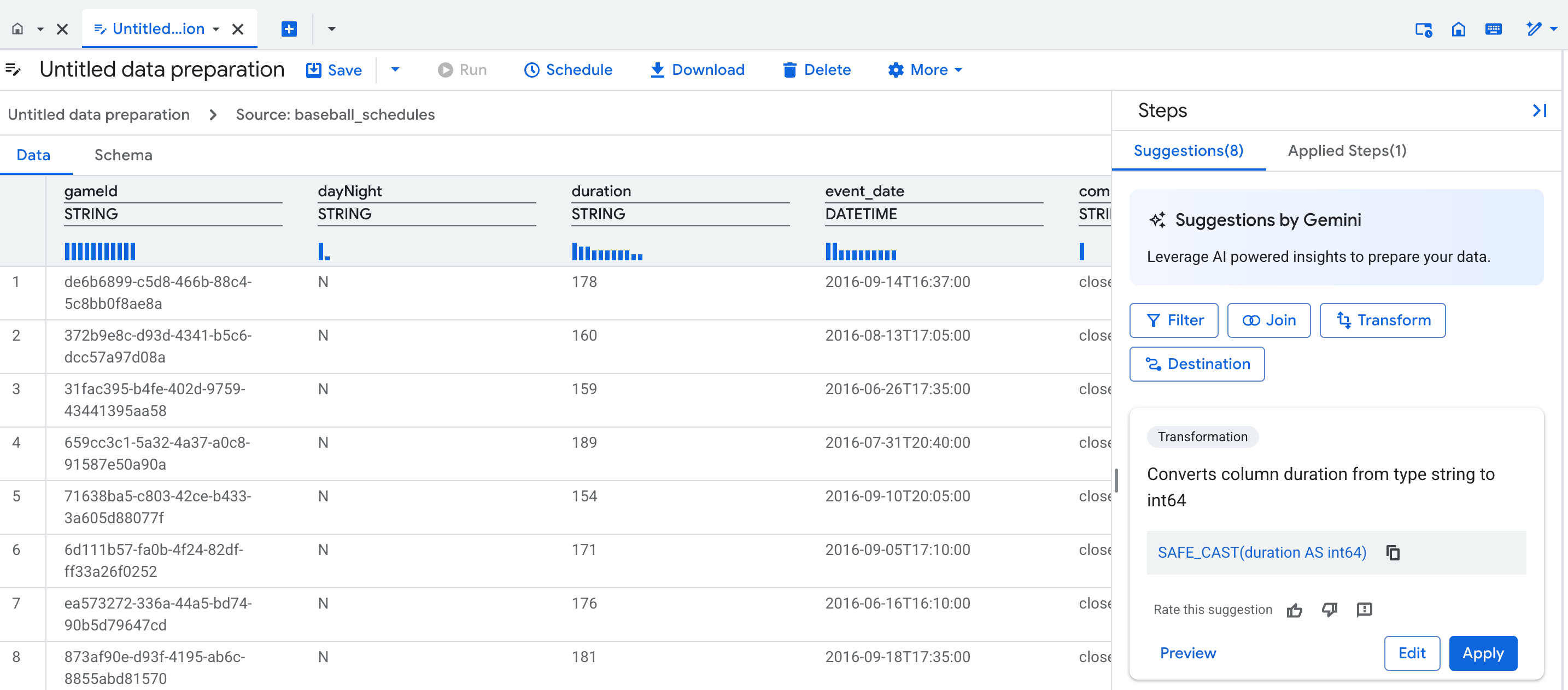
Gemini による候補をデータ準備のステップとして適用する手順は次のとおりです。
- データビューで、列名または特定のセルをクリックします。Gemini は、データのフィルタリングと変換の候補を生成します。
省略可: 候補を改善するには、表の 1~3 個のセルの値を編集して、列の値の表示形式を指定します。たとえば、すべての日付の形式を指定する日付を入力します。Gemini は、変更内容に基づいて新しい候補を生成します。
次の図は、Gemini が提案したステップを改善するために値を編集する方法を示しています。
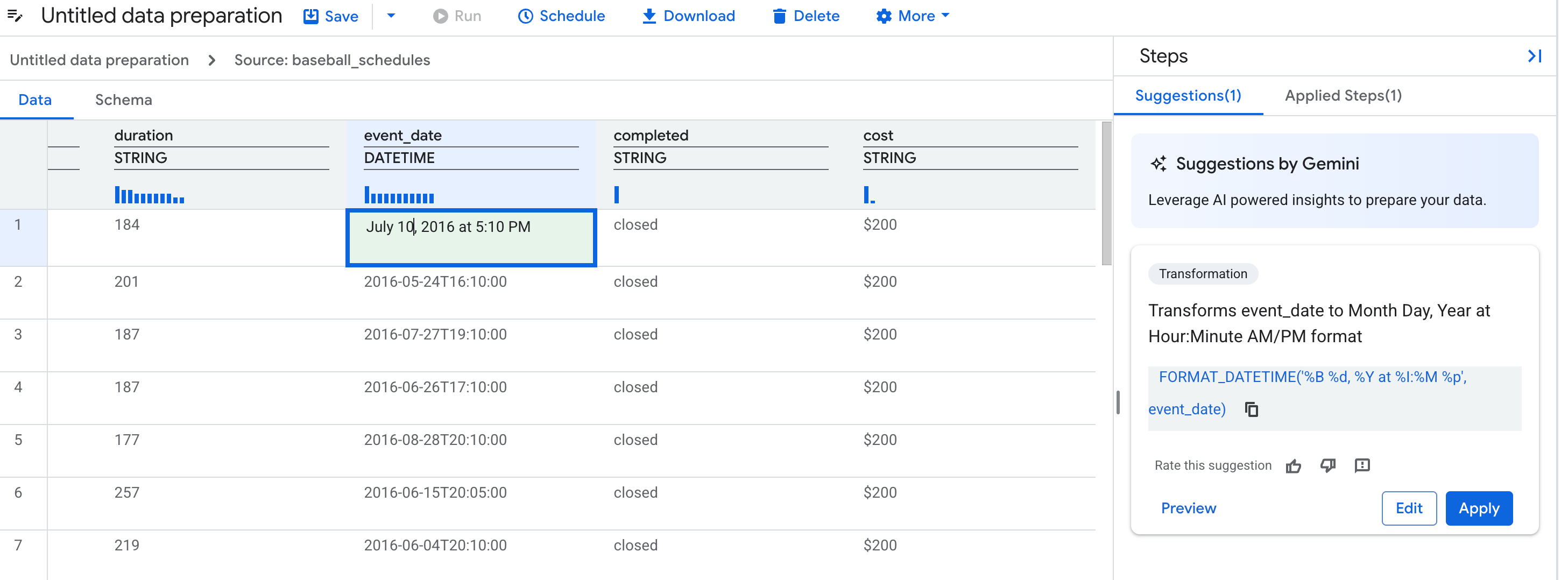
候補カードを選択します。
- 省略可: 候補カードの結果をプレビューするには、[プレビュー] をクリックします。
- 省略可: 自然言語を使用して候補カードを変更するには、[編集] をクリックします。
[適用] をクリックします。
自然言語または SQL 式を使用してステップを追加する
既存の候補がニーズに合わない場合は、ステップを追加します。列またはステップタイプを選択し、自然言語を使用して目的を説明します。
変換を追加する
- データビューまたはスキーマビューで、[変換] オプションを選択します。Gemini がデータ変換を理解できるように、列を選択したり、例を追加することもできます。
- [説明] フィールドにプロンプト(
Convert the state column to uppercaseなど)を入力します。 send [送信] をクリックします。
Gemini は、プロンプトに基づいて SQL 式と新しい説明を生成します。
[ターゲット列] リストで、列名を選択するか入力します。
省略可: SQL 式を更新するには、プロンプトを修正して send [送信] をクリックするか、SQL 式を手動で入力します。
省略可: [プレビュー] をクリックして、ステップを確認します。
[適用] をクリックします。
JSON 列をフラット化する
Key-Value ペアへのアクセスと分析を容易にするには、JSON 列をフラット化します。たとえば、country と device_type のキーを含む user_properties という名前の JSON 列がある場合、この列をフラット化すると、country と device_type が独自の最上位列に抽出され、分析で直接使用できるようになります。
Gemini for BigQuery は、JSON の最上位レベルからのみフィールドを抽出するオペレーションを提案します。抽出されたフィールドに複数の JSON オブジェクトが含まれている場合は、追加の手順でそれらをフラット化して、その内容にアクセスできます。
- JSON ソーステーブルのデータビューで、列またはセルを選択します。
- [平坦化] をクリックして、候補を生成します。
- 省略可: SQL 式を更新するには、SQL 式を手動で入力します。
- 省略可: [プレビュー] をクリックして、ステップを確認します。
- [適用] をクリックします。
フラット化は次のように動作します。
- JSON を含むセルまたは列を選択すると、データビューに [平坦化] オプションが表示されます。[ステップを追加] をクリックしても、デフォルトでは表示されません。
- 選択した行に JSON キーが存在しない場合、生成された候補にはそのキーが含まれません。この問題により、データがフラット化されるときに一部の列が除外される可能性があります。
- フラット化中に列名が競合すると、繰り返される列名の末尾は
_<i>の形式になります。たとえば、addressという名前の列がすでに存在する場合、新しいフラット化された列名はaddress_1になります。 - フラット化された列名は、BigQuery の列の命名規則に従います。
- JSON キーフィールドを空のままにすると、デフォルトの列名形式は
f<i>_になります。
RECORD 列または STRUCT 列をフラット化する
ネストされたフィールドにアクセスして分析しやすくするには、RECORD または STRUCT データ型の列をフラット化します。たとえば、timestamp フィールドと action フィールドを含む event_log レコードがある場合、このレコードをフラット化すると、timestamp と action が独自の最上位列に抽出され、直接変換できるようになります。
このプロセスでは、レコードから最大 10 レベルの深さまでネストされたすべての列が抽出され、それぞれに新しい列が作成されます。新しい列名は、親列の名前とネストされたフィールド名をアンダースコアで区切って組み合わせることで作成されます(例: PARENT-COLUMN-NAME_FIELD-NAME)。元の列は削除されます。元の列を保持するには、[適用されたステップ] リストから [列を削除] ステップを削除します。
レコードをフラット化する手順は次のとおりです。
- ソーステーブルのデータビューで、レコード列を選択します。
- [平坦化] をクリックして、候補を生成します。
- 省略可: SQL 式を更新するには、SQL 式を手動で入力します。
- 省略可: [プレビュー] をクリックして、ステップを確認します。
- [適用] をクリックします。
配列をネスト解除する
ネスト解除では、配列内の各要素が独自の行に展開され、他の元の列の値が各新しい行に複製されます。このアクションは、API レスポンスのリストなど、要素の数が可変の配列を含む列を分析する場合に便利です。
次の列タイプはネスト解除できます。
ARRAYデータ型: 配列の基本型の要素にネスト解除します。たとえば、ARRAY<STRUCT<...>>のネスト解除では、STRUCT型の要素が生成されます。JSON列: 列内の JSON 配列をJSON型の要素にネスト解除します。
配列のネストを解除すると、ネスト解除された要素を含む新しい列が作成されます。デフォルトでは、元の配列の列は削除されます。元の列を保持するには、[適用されたステップ] リストから [列を削除] ステップを削除します。
配列のネストを解除する手順は次のとおりです。
- ソーステーブルのデータビューで、
ARRAY列を選択します。 - [Unnest] をクリックして、候補を生成します。
- 省略可: SQL 式を更新するには、SQL 式を手動で入力します。
- 省略可: [プレビュー] をクリックして、ステップを確認します。
- [適用] をクリックします。
行のフィルタ処理
行を削除するフィルタを追加する手順は次のとおりです。
- データビューまたはスキーマビューで、[フィルタ] オプションを選択します。Gemini がデータフィルタを理解できるように、列を選択することもできます。
- [説明] フィールドにプロンプト(
Column ID should not be NULLなど)を入力します。 - [生成] をクリックします。Gemini は、プロンプトに基づいて SQL 式と新しい説明を生成します。
- 省略可: SQL 式を更新するには、プロンプトを修正して send [送信] をクリックするか、SQL 式を手動で入力します。
- 省略可: [プレビュー] をクリックして、ステップを確認します。
- [適用] をクリックします。
フィルタ式の形式
フィルタの SQL 式は、指定された条件に一致する行を保持します。これは SELECT … WHERE SQL_EXPRESSION ステートメントと同じです。
たとえば、列 year が 2000 以上であるレコードを保持するには、条件は year >= 2000 です。
式は、WHERE 句の BigQuery SQL 構文に従っている必要があります。
データの重複を排除する
データから重複する行を削除する手順は次のとおりです。
- データビューまたはスキーマビューで、[重複除去] オプションを選択します。Gemini は、重複除去の最初の候補を提示します。
- 省略可: 候補を絞り込むには、新しい説明を入力して send [送信] をクリックします。
- 省略可: 重複除去ステップを手動で構成するには、次のオプションを使用します。
- [レコードを選択] リストで、次のいずれかの戦略を選択します。
- 最初: この戦略では、重複除去キーの値が同じ行の各グループについて、
ORDER BY式に基づいて最初の行を選択し、残りの行を削除します。 - 最後: この戦略では、重複除去キーの値が同じ行の各グループについて、
ORDER BY式に基づいて最後の行を選択し、残りの行を削除します。 - 任意: この戦略では、同じ重複除去キー値を持つ行のグループごとに、そのグループから任意の行を選択し、残りの行を削除します。
- Distinct: テーブルのすべての列で重複する行をすべて削除します。
- 最初: この戦略では、重複除去キーの値が同じ行の各グループについて、
- [重複除去キー] フィールドで、重複する行を特定する列または式を 1 つ以上選択します。このフィールドは、レコード選択戦略が「最初」、「最後」、または「任意」の場合に適用されます。
- [並べ替え式] フィールドに、行の順序を定義する式を入力します。たとえば、最新の行を選択するには、「
datetime DESC」と入力します。名前のアルファベット順で最初の行を選択するには、last_nameなどの列名を入力します。式は、BigQuery の標準のORDER BY句と同じルールに従います。このフィールドは、レコード選択戦略が「最初」または「最後」の場合にのみ適用されます。
- [レコードを選択] リストで、次のいずれかの戦略を選択します。
- 省略可: [プレビュー] をクリックして、ステップを確認します。
- [適用] をクリックします。
列を削除する
データ準備から 1 つ以上の列を削除する手順は次のとおりです。
- データビューまたはスキーマビューで、削除する列を選択します。
- [ドロップ] をクリックします。削除された列に新しい適用ステップが追加されます。
Gemini で結合オペレーションを追加する
データ準備で 2 つのソースの間に結合オペレーション ステップを追加する手順は次のとおりです。
- データ準備のノードのデータビューで、[候補] リストに移動し、[結合] オプションをクリックします。
- [結合を追加] ダイアログで、[参照] をクリックし、結合オペレーションに関連するほかのテーブル(結合の右側)を選択します。
- 省略可: 実行する結合オペレーションのタイプ(内結合など)を選択します。
次のフィールドで、Gemini によって生成された結合キー情報を確認します。
- 結合の説明: 結合オペレーションの SQL 式の自然言語の説明。この説明を編集して [送信] 送信をクリックすると、Gemini が新しい SQL 結合条件を提案します。
結合条件: 結合オペレーションの
ON句内の SQL 式。L修飾子とR修飾子を使用して、左側と右側のソーステーブルをそれぞれ参照できます。たとえば、左側のテーブルのcustomer_id列を右側のテーブルのcustomer_id列に結合するには、L.customerId = R.customerIdと入力します。これらの修飾子では大文字と小文字は区別されません。
省略可: Gemini からの候補を絞り込むには、[結合説明] フィールドを編集し、[送信] [送信] をクリックします。
省略可: データ準備の結合オペレーションの設定をプレビューするには、[プレビュー] をクリックします。
[適用] をクリックします。
結合オペレーションのステップが作成されます。選択したソーステーブル(結合の右側)と結合オペレーションが、適用されたステップのリストと、データ準備のグラフビューのノードに反映されます。
データを集計する
- データビューまたはスキーマビューで、[集計] オプションを選択します。
- [説明] フィールドにプロンプト(
Find the total revenue for a regionなど)を入力します。 [送信] をクリックします。
Gemini は、プロンプトに基づいてグループ化キーと集計式を生成します。
省略可: 必要に応じて、生成されたグループ化キーまたは集計式を編集します。
省略可: グループ化キーと集計式を手動で追加できます。
- [グループ化キー] フィールドに、列名または式を入力します。空白のままにすると、結果のテーブルには 1 行が含まれます。式を入力する場合は、別名(
AS句)が必要です(例:EXTRACT(YEAR FROM order_date) AS order_year)。重複は許可されません。 - [Aggregation expressions] フィールドに、エイリアス(
AS句)を含む集計式(例:SUM(quantity) AS total_quantity)を入力します。複数の式をカンマ区切りで入力できます。重複は許可されません。サポートされている集計式の一覧については、集計関数をご覧ください。
- [グループ化キー] フィールドに、列名または式を入力します。空白のままにすると、結果のテーブルには 1 行が含まれます。式を入力する場合は、別名(
省略可: [プレビュー] をクリックして、ステップを確認します。
[適用] をクリックします。
エラーテーブルを構成して検証ルールを追加する
検証ルールを作成するフィルタを追加して、エラーをエラーテーブルに送信、またはデータ準備の実行を失敗させることができます。
エラーテーブルを構成する
エラーテーブルを構成する手順は次のとおりです。
- データ準備エディタで、ツールバーに移動し、[その他] > [エラーテーブル] をクリックします。
- [エラーテーブルを有効にする] をクリックします。
- テーブルのロケーションを定義します。
- 省略可: エラーの保持期間の上限を定義します。
- [保存] をクリックします。
検証ルールを追加する
検証ルールを追加する手順は、次のとおりです。
- データビューまたはスキーマビューで、[フィルタ] オプションをクリックします。Gemini がデータフィルタを理解できるように、列を選択することもできます。
- ステップの説明を入力します。
WHERE句の形式で SQL 式を入力します。- 省略可: SQL 式を検証ルールとして機能させる場合は、[検証に失敗した行をエラーテーブルに送信する] チェックボックスをオンにします。データ準備ツールバーで、[その他] > [エラーテーブル] をクリックして、フィルタを検証に変更することもできます。
- 省略可: [プレビュー] をクリックして、ステップを確認します。
- [適用] をクリックします。
宛先テーブルを追加または変更する
データ準備を実行またはスケジュールするには、宛先テーブルが必要です。データ準備の出力の宛先テーブルを追加または変更する手順は次のとおりです。
- データビューまたはスキーマビューで、[候補] リストの [宛先] をクリックします。
- 宛先テーブルが保存されているプロジェクトを選択します。
- いずれかのデータセットを選択するか、新しいデータセットを読み込みます。
- 宛先テーブルを入力します。テーブルが存在しない場合、データ準備は最初の実行時に新しいテーブルを作成します。詳細については、書き込みモードをご覧ください。
- データセットを宛先データセットとして選択します。
- [保存] をクリックします。
適用されたステップのデータサンプルとスキーマを確認する
データ準備の特定のステップでサンプルとスキーマの詳細を表示する手順は次のとおりです。
- データ準備エディタで、[ステップ] リストに移動し、[適用されたステップ] をクリックします。
- ステップを選択します。[データ] タブと [スキーマ] タブが表示され、そのステップのデータサンプルとスキーマが表示されます。
適用されたステップを編集する
適用されたステップを編集するには、次の操作を行います。
- データ準備エディタで、[ステップ] リストに移動し、[適用されたステップ] をクリックします。
- ステップを選択します。
- ステップの横にある more_vert (メニュー)> [編集] をクリックします。
- [適用されたステップを編集] ダイアログで、次の操作を行います。
- ステップの説明を編集します。
- 説明を編集して send(送信)をクリックすると、Gemini から候補が表示されます。
- SQL 式を編集します。
- [ターゲット列] フィールドで、列を選択します。
- 省略可: [プレビュー] をクリックして、ステップを確認します。
- [適用] をクリックします。
適用されたステップを削除する
適用された手順を削除するには、次の操作を行います。
- データ準備エディタで、[ステップ] リストに移動し、[適用されたステップ] をクリックします。
- ステップを選択します。
- more_vert(メニュー)> [削除] をクリックします。
データ準備を実行する
データ準備ステップを追加し、宛先を構成して検証エラーを修正したら、データのサンプルでテスト実行を実行するか、ステップをデプロイしてデータ準備実行をスケジュールできます。詳細については、データ準備をスケジュールするをご覧ください。
データ準備のサンプルを更新する
サンプル内のデータは自動的に更新されません。データ準備のソーステーブルのデータが変更されたにもかかわらず、その変更が準備のデータサンプルに反映されていない場合は、[その他 > サンプルを更新] をクリックします。
次のステップ
- データ準備をスケジュールする方法を学習する。
- データ準備の管理について学習する。
- Gemini in BigQuery の割り当てと上限について学習する。
- Gemini in BigQuery の料金を学習する。