
BigQuery の概要
BigQuery は、ML、検索、地理空間分析、ビジネス インテリジェンスなどの組み込み機能を使用してデータの管理と分析を支援する、フルマネージドの AI 対応データ プラットフォームです。 BigQuery のサーバーレス アーキテクチャを使用すると、SQL や Python などの言語を使用して、インフラストラクチャ管理なしで組織の最も大きな課題に対応できます。
BigQuery は、構造化データと非構造化データの両方を使用するための統一的な方法を提供するものであり、Apache Iceberg、Delta、Hudi などのオープン テーブル形式をサポートしています。BigQuery ストリーミングは、継続的なデータの取り込みと分析をサポートしています。BigQuery のスケーラブルな分散型分析エンジンを使用すると、数テラバイトのデータであれば数秒、数ペタバイトのデータであれば数分でクエリを実行できます。
BigQuery のアーキテクチャは、データを取り込み、保存、最適化するストレージ レイヤと、分析機能を提供するコンピューティング レイヤの 2 つの部分で構成されています。これらのコンピューティング レイヤとストレージ レイヤは、レイヤ間の必要な通信を可能にする Google のペタビット規模のネットワークにより、相互に独立して効率的に動作します。
一般的に以前のデータベースでは、読み取り / 書き込みオペレーションと分析オペレーションでリソースを共有する必要があります。これによりリソースの競合が発生し、データがストレージに書き込まれるとき、またはストレージから読み込まれるときにクエリが遅くなる可能性があります。権限の割り当てや取り消しなど、データベース管理タスクにリソースが必要な場合、共有リソースプールの負荷はさらに増大します。BigQuery では、コンピューティング レイヤとストレージ レイヤが分離されているため、他方のレイヤのパフォーマンスや可用性に影響を与えることなく、各レイヤでリソースを動的に割り当てることができます。
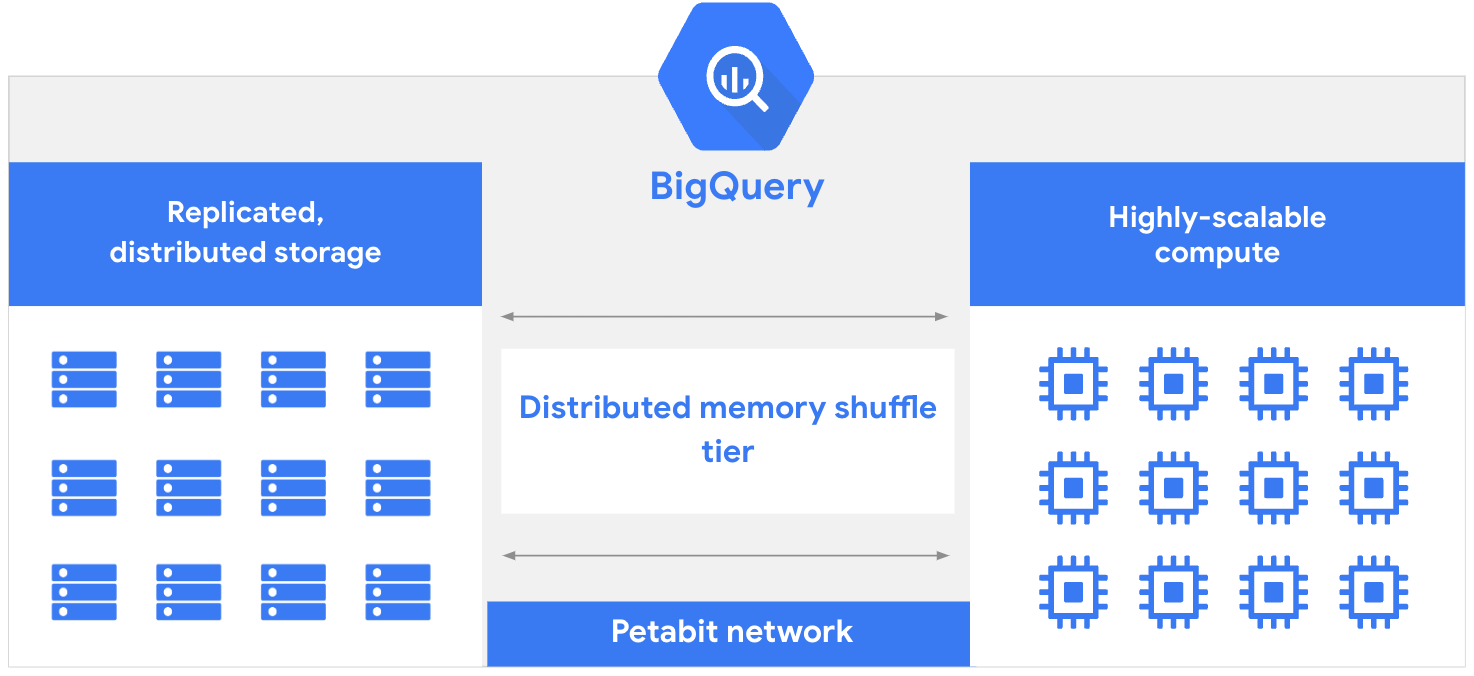
この分離原則により、BigQuery はダウンタイムやシステム パフォーマンスへの悪影響なしに、ストレージとコンピューティングの改善を個別にデプロイできるため、より迅速にイノベーションを実現できます。また、BigQuery エンジニアリング チームが更新とメンテナンスを処理するフルマネージド サーバーレス データ ウェアハウスを提供することも不可欠です。結果として、リソースのプロビジョニングや手動スケーリングを行う必要がないため、従来のデータベース管理タスクではなく、価値の提供に集中できます。
BigQuery インターフェースには、 Cloud de Confiance コンソール インターフェースと BigQuery コマンドライン ツールが含まれます。デベロッパーやデータ サイエンティストは、Python、Java、JavaScript、Go などの使い慣れたプログラミング言語でクライアント ライブラリを使用することも、BigQuery の REST API と RPC API でデータを変換、管理することもできます。ODBC ドライバと JDBC ドライバにより、サードパーティのツールやユーティリティなどの既存のアプリケーションとやり取りできるようになります。
データ アナリスト、データ エンジニア、データ ウェアハウス管理者、またはデータ サイエンティストであれば、BigQuery は、データを読み込み、処理、分析して、重要なビジネス上の意思決定を支援します。
BigQuery を使ってみる
BigQuery は数分で使い始めることが可能です。
- Cloud de Confiance コンソール クイックスタート: BigQuery Studio の機能に慣れるようにします。
BigQuery を詳しく見る
BigQuery のサーバーレス インフラストラクチャを使用すると、リソース管理ではなくデータに集中できます。BigQuery は、クラウドベースのデータ ウェアハウスと強力な分析ツールを組み合わせたものです。
BigQuery ストレージ
BigQuery は、分析クエリに最適化されたカラム型ストレージ形式でデータを保存します。BigQuery はデータをテーブル、行、列に表示し、データベース トランザクション セマンティクス(ACID)を完全にサポートします。高可用性を実現するため、BigQuery ストレージは複数のロケーションに自動的に複製されます。
- データ ウェアハウスとデータマートで BigQuery リソースを整理するための一般的なパターンについて確認します。
- BigQuery のテーブルとビューの最上位コンテナであるデータセットについて学習します。
- 次の機能を使用して、BigQuery にデータを読み込みます。
- Storage Write API を使用してデータをストリーミングします。
- Avro、Parquet、ORC、CSV、JSONなどの形式でローカル ファイルまたは Cloud Storage から、データをバッチ読み込みします。
詳細については、BigQuery の料金の概要をご覧ください。
BigQuery による分析
ビジネス インテリジェンス、アドホック分析、地理空間分析、ML では記述的分析、処方的分析を使用できます。 BigQuery に保存されたデータに対してクエリを実行することも、Cloud Storage などの外部テーブルや連携クエリを使用して、外部テーブルのデータに対するクエリを実行することもできます。
- ANSI 標準 SQL クエリ(SQL:2011 遵守)は、結合、ネスト、繰り返しのフィールド、分析関数と集計関数、マルチステートメント クエリ、地理空間分析(地理情報システム)などのさまざまな空間関数をサポートします。
- ビューを作成して分析を共有します。
- BigQuery 用の Simba ODBC ドライバと JDBC ドライバを使用するサードパーティ ツールを含む、ビジネス インテリジェンス ツールのサポート
- BigQuery ML は、ML と予測分析を提供します。
- BigQuery Studio を使用すると、BigQuery でデータ分析と ML のワークフローを簡単に完了できます。
- 外部テーブルを使用して、BigQuery の外部でデータをクエリします。
詳細については、BigQuery の分析の概要をご覧ください。
BigQuery の管理
BigQuery では、データとコンピューティング リソースの一元管理が可能であり、Identity and Access Management(IAM)では、 Cloud de Confiance by S3NS全体で使用されるアクセスモデルにより、これらのリソースを保護できます。
- データ セキュリティとガバナンスの概要では、データ ガバナンスと、BigQuery リソースの保護に必要な制御について確認できます。
- ジョブとは、データの読み込み、エクスポート、クエリ、コピーなど、ユーザーに代わって BigQuery が走行するアクションのことです。
- Reservations では、オンデマンド料金と容量ベースの料金を切り替えることができます。
詳細については、BigQuery の管理の概要をご覧ください。
BigQuery リソース
次の BigQuery リソースを利用できます。
- リリースノート。機能、変更、非推奨の変更履歴が記載されています。
- Stack Overflow。BigQuery を使用するデベロッパーとアナリストのコミュニティがホストされています。
- Google BigQuery: Definitive Guide: Data Warehousing, Analytics, and Machine Learning at Scale(Valliappa Lakshmanan、Jordan Tigani 著)。BigQuery の仕組みについて解説し、サービスの使用方法に関するエンドツーエンドのチュートリアルを提供しています。
API、ツール、リファレンス
BigQuery のデベロッパーとアナリスト向けの参考資料:
- BigQuery API とクライアント ライブラリには、BigQuery の機能と用途の概要が記載されています。
- DMLの構文により、BigQuery データの管理と変換を行うことができます。
- bq コマンドライン ツール リファレンス。
bqCLI インターフェース用の構文、コマンド、フラグ、引数が記載されています。 - ODBC / JDBC の統合。これにより、BigQuery が既存のツールやインフラストラクチャに接続されます。
BigQuery のロールとリソース
BigQuery は、次の役割と責任にわたってデータ プロフェッショナルのニーズに対応しています。
データ アナリスト
次の操作が必要な場合に役立つタスク ガイダンス。
- SQL クエリ構文を使用してインタラクティブ クエリまたはバッチクエリで BigQuery データにクエリを実行する。
- SQL の関数、演算子、条件式を参照して、データをクエリする
Google スプレッドシートなどのツールを使用して、BigQuery データを分析、可視化する。
地理空間分析を使用して、BigQuery の地理情報システムで地理空間データを分析および可視化する。
次の機能を使用して、クエリ パフォーマンスを最適化する。
- パーティション分割テーブル: 時間または整数の範囲に基づいて、大きなテーブルをプルーニングする。
- マテリアライズド ビュー: キャッシュに保存されたビューを定義して、クエリの最適化や、永続的な結果の提供を行う。
データ管理者
次の操作が必要な場合に役立つタスク ガイダンス。
- Reservations で費用を管理し、オンデマンドと容量ベースの料金のバランスをとる。
- データ セキュリティとガバナンスを把握して、データセット、テーブル、列、行、ビューごとにデータを保護する。
- テーブルのスナップショットでデータをバックアップして、特定の時点でのテーブルのコンテンツを保存する。
- BigQuery INFORMATION_SCHEMA を表示して、データセット、ジョブ、アクセス制御、Reservations、テーブルなどのメタデータについて把握する。
- ジョブを使用して、ユーザーの代わりに BigQuery がデータの読み込み、エクスポート、クエリ、コピーなどのアクションを行う。
- ログとリソースをモニタリングして、BigQuery とワークロードを把握する。
詳細については、BigQuery の管理の概要をご覧ください。
データ サイエンティスト
BigQuery ML の機械学習で次の操作が必要な場合に役立つタスク ガイダンス。
- 機械学習モデルのエンドツーエンドのユーザー ジャーニーを理解する。
- BigQuery ML のアクセス制御を管理する。
- 以下を含む BigQuery ML モデルを作成してトレーニングする。
- 線形回帰予測
- 2 項ロジスティック回帰と多項ロジスティック回帰分類
- データ セグメンテーション用の K 平均法クラスタリング
- Arima+ モデルを使用した時系列予測
データ デベロッパー
次の操作が必要な場合に役立つタスク ガイダンス。
- 以下を使用して BigQuery にデータを読み込む:
次のようなコードサンプル ライブラリを使用する:
Cloud de Confiance サンプル ブラウザ(BigQuery を対象とする)
次のステップ
- BigQuery ストレージの概要については、BigQuery ストレージの概要をご覧ください。
- BigQuery クエリの概要については、BigQuery 分析の概要をご覧ください。
- BigQuery の管理の概要については、BigQuery の管理の概要をご覧ください。
- BigQuery セキュリティの概要については、データ セキュリティとガバナンスの概要をご覧ください。