
Menggunakan BigQuery DataFrames di dbt
dbt (alat build data) adalah framework command line open source yang dirancang untuk transformasi data dalam data warehouse modern. dbt memfasilitasi transformasi data modular melalui pembuatan model berbasis SQL dan Python yang dapat digunakan kembali. Alat ini mengatur eksekusi transformasi ini dalam data warehouse target, dengan berfokus pada langkah transformasi pipeline ELT. Untuk mengetahui informasi selengkapnya, lihat dokumentasi dbt.
Di dbt, model Python adalah transformasi data yang ditentukan dan dieksekusi menggunakan kode Python dalam project dbt Anda. Alih-alih menulis SQL untuk logika transformasi, Anda menulis skrip Python yang kemudian diatur dbt untuk dijalankan dalam lingkungan data warehouse. Model Python memungkinkan Anda melakukan transformasi data yang mungkin kompleks atau tidak efisien untuk dinyatakan dalam SQL. Hal ini memanfaatkan kemampuan Python sekaligus tetap mendapatkan manfaat dari fitur struktur project, orkestrasi, pengelolaan dependensi, pengujian, dan dokumentasi dbt. Untuk mengetahui informasi selengkapnya, lihat Model Python.
Adaptor dbt-bigquery
mendukung menjalankan kode Python yang ditentukan di
BigQuery DataFrames. Fitur ini tersedia di
dbt Cloud dan
dbt Core.
Anda juga bisa mendapatkan fitur ini dengan meng-clone versi terbaru adaptor
dbt-bigquery.
Sebelum memulai
Untuk menggunakan adaptor dbt-bigquery, aktifkan API berikut di project Anda:
- BigQuery API (
bigquery.googleapis.com) - Cloud Storage API (
storage.googleapis.com) - Compute Engine API (
compute.googleapis.com) - Dataform API (
dataform.googleapis.com) - Identity and Access Management API (
iam.googleapis.com) - Vertex AI API (
aiplatform.googleapis.com)
Peran yang diperlukan untuk mengaktifkan API
Untuk mengaktifkan API, Anda memerlukan peran IAM Service Usage Admin
(roles/serviceusage.serviceUsageAdmin),
yang berisi izin serviceusage.services.enable. Pelajari cara memberikan
peran.
Peran yang diperlukan
Adaptor dbt-bigquery mendukung autentikasi berbasis OAuth dan berbasis akun layanan. Bagian berikut menjelaskan peran yang diperlukan, bergantung pada
cara Anda berencana melakukan autentikasi.
OAuth
Jika Anda berencana untuk mengautentikasi ke adaptor dbt-bigquery menggunakan OAuth, minta administrator Anda untuk memberi Anda peran berikut:
- Peran Pengguna BigQuery
(
roles/bigquery.user) di project - Peran BigQuery Data Editor
(
roles/bigquery.dataEditor) di project atau set data tempat tabel disimpan - Peran Pengguna Colab Enterprise
(
roles/colabEnterprise.user) di project - Peran Storage Admin
(
roles/storage.admin) di bucket Cloud Storage staging untuk kode dan log staging
Akun layanan
Jika Anda berencana untuk mengautentikasi adaptor dbt-bigquery menggunakan akun layanan di project Anda, minta administrator untuk memberikan peran berikut ke akun layanan yang akan Anda gunakan:
- Peran Pengguna BigQuery
(
roles/bigquery.user) - Peran BigQuery Data Editor
(
roles/bigquery.dataEditor) - Peran Pengguna Colab Enterprise
(
roles/colabEnterprise.user) - Peran Storage Admin
(
roles/storage.admin)
Jika Anda melakukan autentikasi menggunakan akun layanan, pastikan juga Anda telah diberi
peran Pengguna Akun Layanan
(roles/iam.serviceAccountUser) untuk akun layanan yang akan Anda gunakan.
Peniruan akun layanan
Jika Anda berencana untuk mengautentikasi ke adaptor dbt-bigquery menggunakan OAuth, tetapi ingin pemrosesan data dan eksekusi notebook terjadi dengan identitas akun layanan dalam project yang sama dengan tempat tugas dijalankan, minta administrator Anda untuk memberi Anda peran berikut:
- Peran Service Account Token Creator
(
roles/iam.serviceAccountTokenCreator) - Service Account User
(
roles/iam.serviceAccountUser)
Akun layanan yang ditiru identitasnya juga harus memiliki semua peran yang diperlukan untuk autentikasi.
Akun layanan lintas project
Jika Anda berencana untuk melakukan autentikasi ke adaptor dbt-bigquery menggunakan akun layanan di project lain, project kredensial, tempat tugas dijalankan, project eksekusi, minta administrator Anda untuk melakukan hal berikut:
- Nonaktifkan batasan
constraints/iam.disableCrossProjectServiceAccountUsagedi project kredensial. Selain semua peran yang diperlukan untuk autentikasi akun layanan, berikan peran berikut ke akun layanan dalam project kredensial:
- Peran Agen Layanan Vertex AI
(roles/aiplatform.serviceAgent) ke
service-PROJECT_NUMBER@gcp-sa-aiplatform.s3ns-system.iam.gserviceaccount.com - Peran Agen Layanan Colab Vertex AI
(roles/aiplatform.colabServiceAgent) ke
service-PROJECT_NUMBER@gcp-sa-vertex-nb.s3ns-system.iam.gserviceaccount.com - Peran Agen Layanan Compute Engine
(roles/compute.serviceAgent) ke
service-PROJECT_NUMBER@compute-system.s3ns-system.iam.gserviceaccount.com
- Peran Agen Layanan Vertex AI
(roles/aiplatform.serviceAgent) ke
Jika Anda berencana untuk mengautentikasi adaptor dbt-bigquery menggunakan OAuth, tetapi ingin pemrosesan data dan eksekusi notebook terjadi dengan identitas akun layanan dalam project yang berbeda dari tempat tugas dijalankan, minta administrator Anda untuk melakukan hal berikut:
- Ikuti langkah-langkah yang dijelaskan sebelumnya untuk akun layanan lintas project untuk akun layanan di project lain.
- Memberi Anda dan akun layanan peran yang diperlukan untuk peniruan identitas akun layanan
VPC Bersama
Jika Anda menggunakan Colab Enterprise di lingkungan VPC Bersama, minta administrator Anda untuk memberikan peran dan izin berikut:
Izin
compute.subnetworks.use: Berikan izin ini ke akun layanan yang digunakan oleh runtime Colab Enterprise di project host atau subnet tertentu. Izin ini disertakan dalam peran Compute Network User (roles/compute.networkUser).Izin
compute.subnetworks.get: Berikan izin ini ke akun layanan yang digunakan oleh runtime Colab Enterprise di project host atau subnet tertentu. Izin ini disertakan dalam peran Compute Network Viewer (roles/compute.networkViewer).Peran Compute Network User (
roles/compute.networkUser): Berikan peran ini kepada agen layanan Gemini Enterprise Agent Platform,service-PROJECT_NUMBER@gcp-sa-aiplatform.s3ns-system.iam.gserviceaccount.com, di project host VPC Bersama.Peran Compute Network User (
roles/compute.networkUser): Jika fitur tugas eksekusi notebook sedang digunakan, berikan peran ini kepada agen layanan Colab Enterprise,service-PROJECT_NUMBER@gcp-sa-vertex-nb.s3ns-system.iam.gserviceaccount.com, di project host VPC Bersama.
Untuk mengetahui informasi selengkapnya tentang pemberian peran, lihat Mengelola akses ke project, folder, dan organisasi.
Anda mungkin juga bisa mendapatkan izin yang diperlukan melalui peran khusus atau peran bawaan lainnya.
Lingkungan eksekusi Python
Adaptor dbt-bigquery menggunakan
layanan eksekutor notebook Colab Enterprise
untuk menjalankan kode Python BigQuery DataFrames. Notebook Colab Enterprise akan otomatis dibuat dan dieksekusi oleh adaptor dbt-bigquery untuk setiap model Python. Anda dapat memilih projectCloud de Confiance untuk menjalankan notebook. Notebook menjalankan kode Python dari model, yang dikonversi menjadi SQL BigQuery oleh library BigQuery DataFrames. SQL BigQuery kemudian
dijalankan dalam project yang dikonfigurasi. Diagram berikut menunjukkan alur
kontrol:
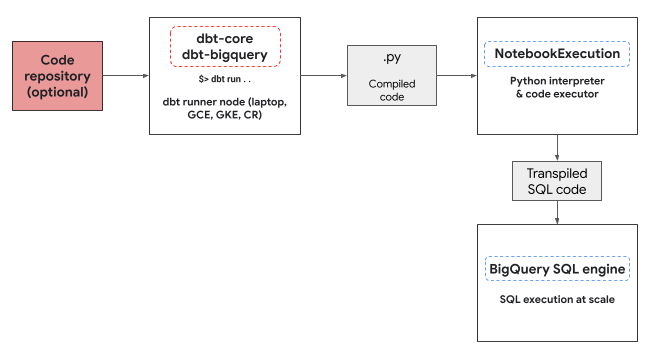
Jika belum ada template notebook yang tersedia di project dan pengguna yang
mengeksekusi kode memiliki izin untuk membuat template, adaptor dbt-bigquery akan
otomatis membuat dan menggunakan template notebook default. Anda juga dapat menentukan template notebook yang berbeda menggunakan
konfigurasi dbt.
Eksekusi notebook memerlukan bucket Cloud Storage staging untuk menyimpan kode dan log. Namun, adaptor dbt-bigquery menyalin log ke
log dbt, sehingga Anda tidak perlu
melihat-lihat bucket.
Fitur yang didukung
Adaptor dbt-bigquery mendukung kemampuan berikut untuk model dbt Python yang menjalankan BigQuery DataFrames:
- Memuat data dari tabel BigQuery yang ada dengan makro
dbt.source(). - Memuat data dari model dbt lain dengan makro
dbt.ref()untuk membangun dependensi dan membuat grafik asiklik terarah (DAG) dengan model Python. - Menentukan dan menggunakan paket Python dari PyPi yang dapat digunakan dengan eksekusi kode Python. Untuk mengetahui informasi selengkapnya, lihat Konfigurasi.
- Menentukan template runtime notebook kustom untuk model BigQuery DataFrames Anda.
Adaptor dbt-bigquery mendukung strategi perwujudan berikut:
- Materialisasi tabel, tempat data dibangun ulang sebagai tabel pada setiap operasi.
- Materialisasi inkremental dengan strategi penggabungan, di mana data baru atau yang diperbarui ditambahkan ke tabel yang ada, sering kali menggunakan strategi penggabungan untuk menangani perubahan.
Menyiapkan dbt untuk menggunakan DataFrame BigQuery
Jika Anda menggunakan
dbt Core,
Anda harus menggunakan file profiles.yml untuk digunakan dengan BigQuery DataFrames.
Contoh berikut menggunakan metode oauth:
your_project_name:
outputs:
dev:
compute_region: us-central1
dataset: your_bq_dateset
gcs_bucket: your_gcs_bucket
job_execution_timeout_seconds: 300
job_retries: 1
location: US
method: oauth
priority: interactive
project: your_gcp_project
threads: 1
type: bigquery
target: dev
Jika Anda menggunakan
dbt Cloud,
Anda dapat
terhubung ke platform data
langsung di antarmuka dbt Cloud. Dalam skenario ini, Anda tidak memerlukan file
profiles.yml. Untuk mengetahui informasi selengkapnya, lihat
Tentang profiles.yml
Berikut adalah contoh konfigurasi tingkat project untuk file dbt_project.yml:
# Name your project! Project names should contain only lowercase characters
# and underscores. A good package name should reflect your organization's
# name or the intended use of these models.
name: 'your_project_name'
version: '1.0.0'
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the config(...) macro.
models:
your_project_name:
submission_method: bigframes
notebook_template_id: 7018811640745295872
packages: ["scikit-learn", "mlflow"]
timeout: 3000
# Config indicated by + and applies to all files under models/example/
example:
+materialized: view
Beberapa parameter juga dapat dikonfigurasi menggunakan metode dbt.config
dalam kode Python Anda. Jika setelan ini bertentangan dengan file
dbt_project.yml Anda, konfigurasi dengan dbt.config akan
diprioritaskan.
Untuk mengetahui informasi selengkapnya, lihat Konfigurasi model dan dbt_project.yml.
Konfigurasi
Anda dapat menyiapkan konfigurasi berikut menggunakan metode dbt.config di model Python Anda. Konfigurasi ini menggantikan konfigurasi
tingkat project.
| Konfigurasi | Wajib | Penggunaan |
|---|---|---|
submission_method |
Ya | submission_method=bigframes |
notebook_template_id |
Tidak | Jika tidak ditentukan, template default akan dibuat dan digunakan. |
packages |
Tidak | Tentukan daftar tambahan paket Python, jika diperlukan. |
timeout |
Tidak | Opsional: Perpanjang waktu tunggu eksekusi tugas. |
Contoh model Python
Bagian berikut menyajikan contoh skenario dan model Python.
Memuat data dari tabel BigQuery
Untuk menggunakan data dari tabel BigQuery yang ada sebagai sumber di model Python, Anda harus menentukan sumber ini terlebih dahulu dalam file YAML. Contoh
berikut ditentukan dalam file source.yml.
version: 2
sources:
- name: my_project_source # A custom name for this source group
database: bigframes-dev # Your Google Cloud project ID
schema: yyy_test_us # The BigQuery dataset containing the table
tables:
- name: dev_sql1 # The name of your BigQuery table
Kemudian, Anda membangun model Python, yang dapat menggunakan sumber data yang dikonfigurasi dalam file YAML ini:
def model(dbt, session):
# Configure the model to use BigFrames for submission
dbt.config(submission_method="bigframes")
# Load data from the 'dev_sql1' table within 'my_project_source'
source_data = dbt.source('my_project_source', 'dev_sql1')
# Example transformation: Create a new column 'id_new'
source_data['id_new'] = source_data['id'] * 10
return source_data
Mereferensikan model lain
Anda dapat membuat model yang bergantung pada output model dbt lain, seperti yang ditunjukkan dalam contoh berikut. Hal ini berguna untuk membuat pipeline data modular.
def model(dbt, session):
# Configure the model to use BigFrames
dbt.config(submission_method="bigframes")
# Reference another dbt model named 'dev_sql1'.
# It assumes you have a model defined in 'dev_sql1.sql' or 'dev_sql1.py'.
df_from_sql = dbt.ref("dev_sql1")
# Example transformation on the data from the referenced model
df_from_sql['id'] = df_from_sql['id'] * 100
return df_from_sql
Menentukan dependensi paket
Jika model Python Anda memerlukan library pihak ketiga tertentu seperti MLflow atau Boto3, Anda dapat mendeklarasikan paket dalam konfigurasi model, seperti yang ditunjukkan dalam contoh berikut. Paket ini diinstal di lingkungan eksekusi.
def model(dbt, session):
# Configure the model for BigFrames and specify required packages
dbt.config(
submission_method="bigframes",
packages=["mlflow", "boto3"] # List the packages your model needs
)
# Import the specified packages for use in your model
import mlflow
import boto3
# Example: Create a DataFrame showing the versions of the imported packages
data = {
"mlflow_version": [mlflow.__version__],
"boto3_version": [boto3.__version__],
"note": ["This demonstrates accessing package versions after import."]
}
bdf = bpd.DataFrame(data)
return bdf
Menentukan template non-default
Untuk kontrol lebih besar atas lingkungan eksekusi atau untuk menggunakan setelan yang telah dikonfigurasi sebelumnya, Anda dapat menentukan template notebook non-default untuk model BigQuery DataFrames, seperti yang ditunjukkan dalam contoh berikut.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# ID of your pre-created notebook template
notebook_template_id="857350349023451yyyy",
)
data = {"int": [1, 2, 3], "str": ['a', 'b', 'c']}
return bpd.DataFrame(data=data)
Mewujudkan tabel
Saat menjalankan model Python, dbt perlu mengetahui cara menyimpan hasilnya di data warehouse Anda. Hal ini disebut materialisasi.
Untuk materialisasi tabel standar, dbt membuat atau mengganti sepenuhnya tabel di
gudang data Anda dengan output model setiap kali dijalankan. Hal ini dilakukan
secara default, atau dengan menetapkan properti materialized='table' secara eksplisit, seperti
yang ditunjukkan dalam contoh berikut.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# Instructs dbt to create/replace this model as a table
materialized='table',
)
data = {"int_column": [1, 2], "str_column": ['a', 'b']}
return bpd.DataFrame(data=data)
Materialisasi inkremental dengan strategi penggabungan memungkinkan dbt memperbarui tabel Anda hanya dengan baris baru atau yang diubah. Hal ini berguna untuk set data besar karena membangun ulang tabel sepenuhnya setiap saat dapat menjadi tidak efisien. Strategi penggabungan adalah cara umum untuk menangani pembaruan ini.
Pendekatan ini secara cerdas mengintegrasikan perubahan dengan melakukan hal berikut:
- Memperbarui baris yang ada yang telah berubah.
- Menambahkan baris baru.
- Opsional, bergantung pada konfigurasi: Menghapus baris yang tidak ada lagi di sumber.
Untuk menggunakan strategi penggabungan, Anda harus menentukan properti unique_key yang dapat digunakan dbt untuk mengidentifikasi baris yang cocok antara output model dan tabel yang ada, seperti yang ditunjukkan dalam contoh berikut.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
materialized='incremental',
incremental_strategy='merge',
unique_key='int', # Specifies the column to identify unique rows
)
# In this example:
# - Row with 'int' value 1 remains unchanged.
# - Row with 'int' value 2 has been updated.
# - Row with 'int' value 4 is a new addition.
# The 'merge' strategy will ensure that only the updated row ('int 2')
# and the new row ('int 4') are processed and integrated into the table.
data = {"int": [1, 2, 4], "str": ['a', 'bbbb', 'd']}
return bpd.DataFrame(data=data)
Pemecahan masalah
Anda dapat mengamati eksekusi Python di log dbt.
Selain itu, Anda dapat melihat kode dan log (termasuk eksekusi sebelumnya) di halaman Eksekusi Colab Enterprise.
Buka Eksekusi Colab Enterprise
Penagihan
Saat menggunakan adaptor dbt-bigquery dengan DataFrame BigQuery, ada biaya dari hal berikut: Cloud de Confiance by S3NS
Eksekusi notebook: Anda dikenai biaya untuk eksekusi runtime notebook. Untuk mengetahui informasi selengkapnya, lihat Harga runtime Notebook.
Eksekusi kueri BigQuery: Di notebook, BigQuery DataFrames mengonversi Python ke SQL dan menjalankan kode di BigQuery. Anda akan ditagih sesuai dengan konfigurasi project dan kueri Anda, seperti yang dijelaskan untuk harga BigQuery DataFrames.
Anda dapat menggunakan label penagihan berikut di konsol penagihan BigQuery untuk memfilter laporan penagihan eksekusi notebook dan eksekusi BigQuery yang dipicu oleh adaptor dbt-bigquery:
- Label eksekusi BigQuery:
bigframes-dbt-api
Langkah berikutnya
- Untuk mempelajari lebih lanjut dbt dan BigQuery DataFrames, lihat artikel Menggunakan BigQuery DataFrames dengan model Python dbt.
- Untuk mempelajari lebih lanjut model Python dbt, lihat Model Python dan Konfigurasi model Python.
- Untuk mempelajari lebih lanjut notebook Colab Enterprise, lihat Membuat notebook Colab Enterprise menggunakan Cloud de Confiance konsol.
- Untuk mempelajari lebih lanjut partner, lihat Cloud de Confiance by S3NS Ready - BigQuery Partners. Cloud de Confiance by S3NS